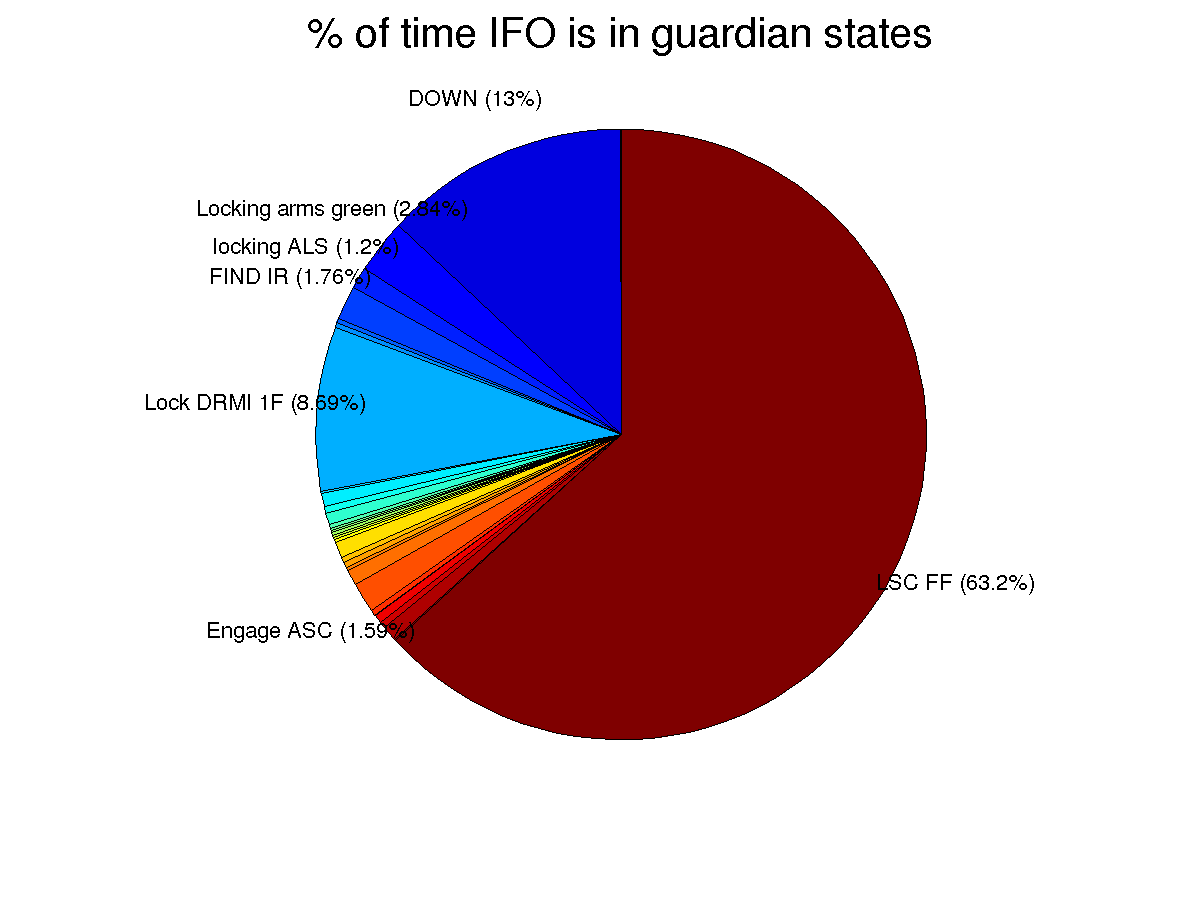
I've taken a look at guardian state information from the last week, with the goal of getting an idea of what we can do to improve our duty cycle. The main messages is that we spent 63% of our time in the nominal low noise state, 13% in the down state, (mostly because the DOWN state was requested), and 8.7% of the week trying to lock DRMI.
Details
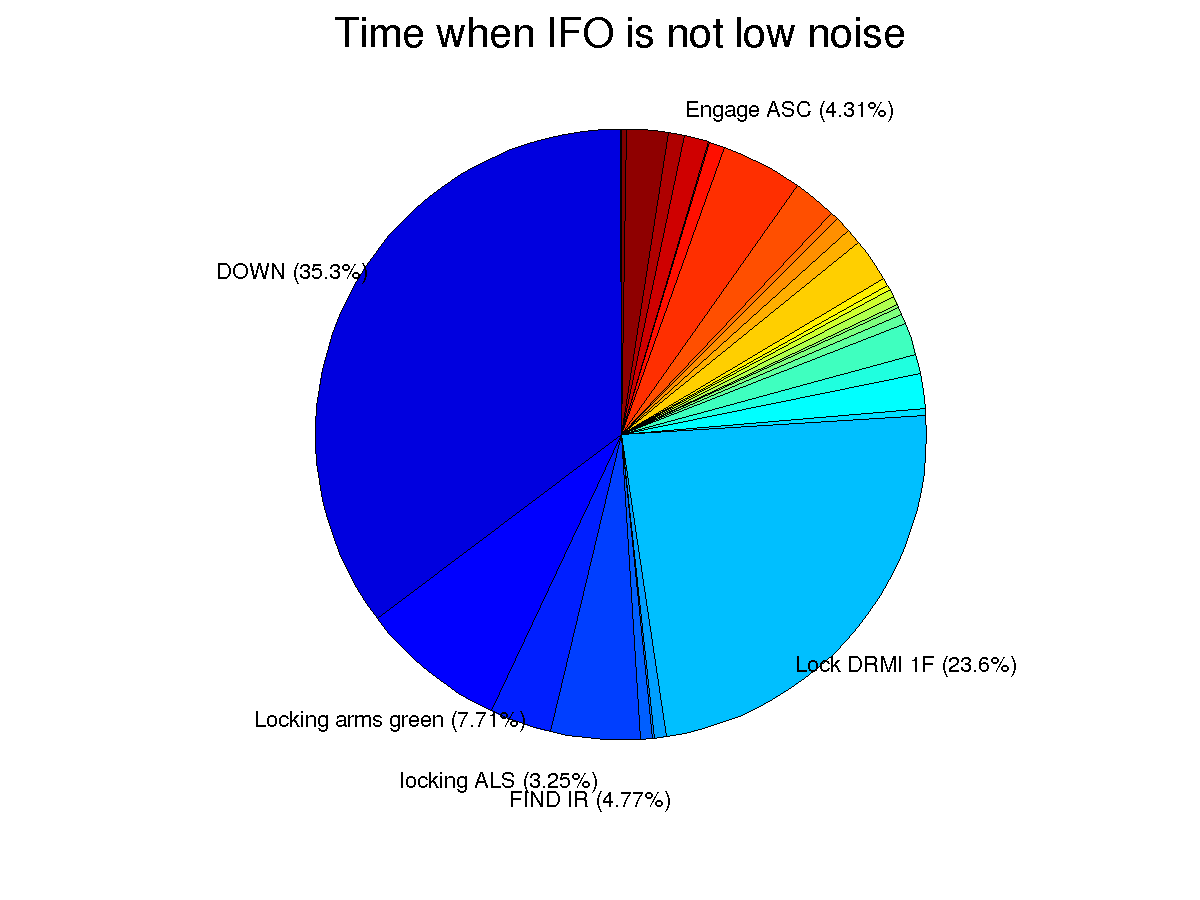
I have not taken into account if the intent bit was set or not during this time, I'm only considering the guardian state. These are based on 7 days of data, starting at 19:24:48 UTC on June3rd. The first pie chart shows the percentage of the time during the week the guardian was in a certain state. For legibility states that took up less than 1% of the week are unlabeled, some of the labels are slightly in the wrong position but you can figure out where they should be if you care. The first two charts show the percentage of the time during the week we were in a particular state, the second chart shows only the unlocked time.
DOWN as the requested state
We were requesting DOWN for 12.13% of the week, or 20.4 hours. Down could be the requested state because operators were doing initial alignment, we were in the middle of maintainece (4 hours ), or it was too windy for locking. Although I haven't done any careful study, I would guess that most of this time was spent on inital alingment.
There are probably three ways to reduce the time spent on initial alignment:
- reducing the number of times that we do initial alignment. We don't really know how often we need to be doing this, and we might be able to do some offloading in full lock before powering up and see if that gives us an alignment that is good for lock acquisition.
- There are a few improvements to the ALIGN_IFO guardian that might help a little.
- Last, as the operators get more experience with the alignment procedure it should become faster.
Bounce and roll mode damping
We spent 5.3% of the week waiting in states between lock DRMI and LSC FF, when the state was already the requested state. Most of this was after RF DARM, and is probably because people were trying to damp bounce and roll or waiting for them to damp. A more careful study of how well we can tolerate these modes being rung up will tell us it is really necessary to wait, and better automation using the monitors can probably help us damp them more efficiently.
Locking DRMI
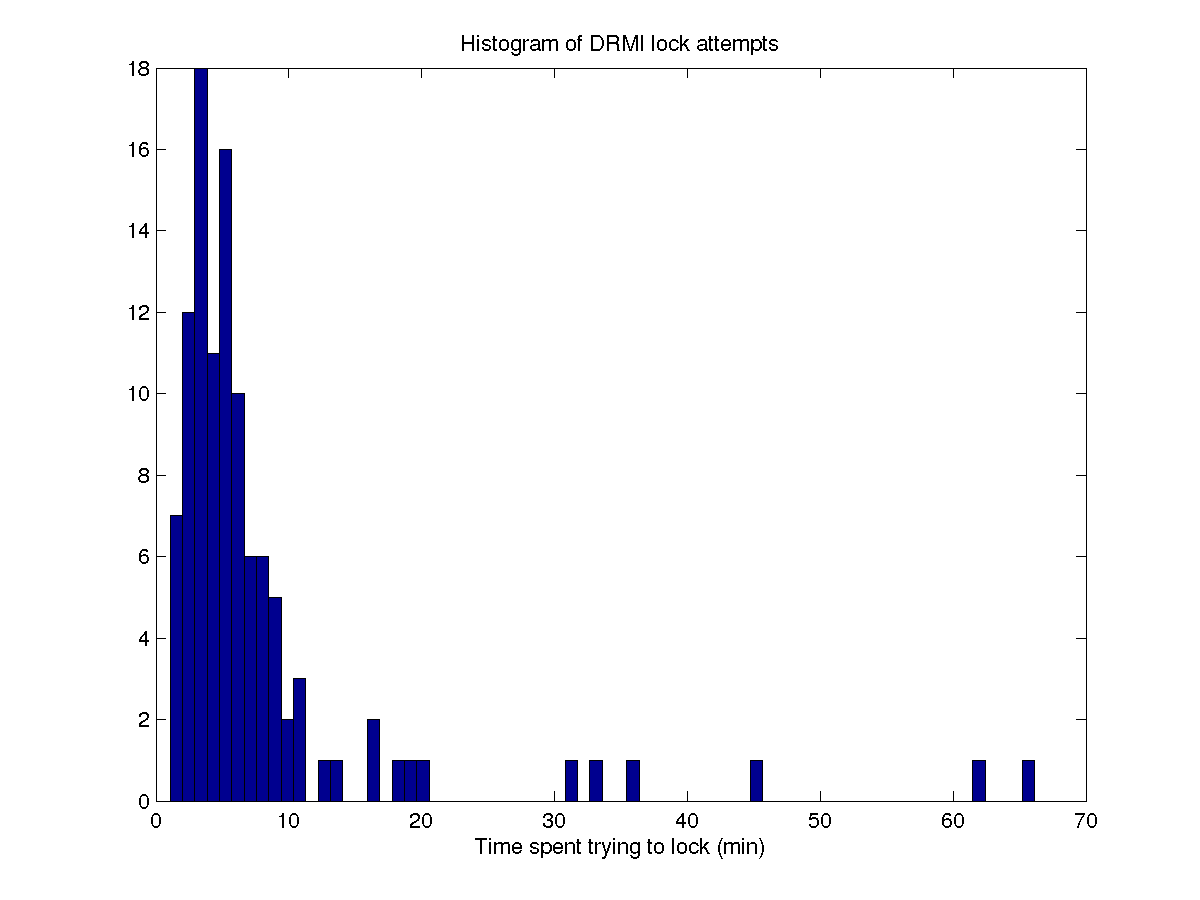
we spent 8.7% of the week locking DRMI, 14.6 hours. During this time we made 109 attempts to lock it, (10 of these ended in ALS locklosses), and the median time per lock attempt was 5.4 minutes. From the histogram of time for DRMI locking attempts(3rd attachment), you can see that the mean locking time is increased by 6 attempts that took more than a half hour, presumably either because DRMI was not well aligned or because the wind was high. It is probably worth checking if these were really due to wind or something else. This histogram includes unsuccessful as well as successful attempts.
Probably the most effective way to reduce the time we spend locking DRMI would be to prevent locklosses later in the lock acquisition sequence, which we have had many of this week.
Locklosses
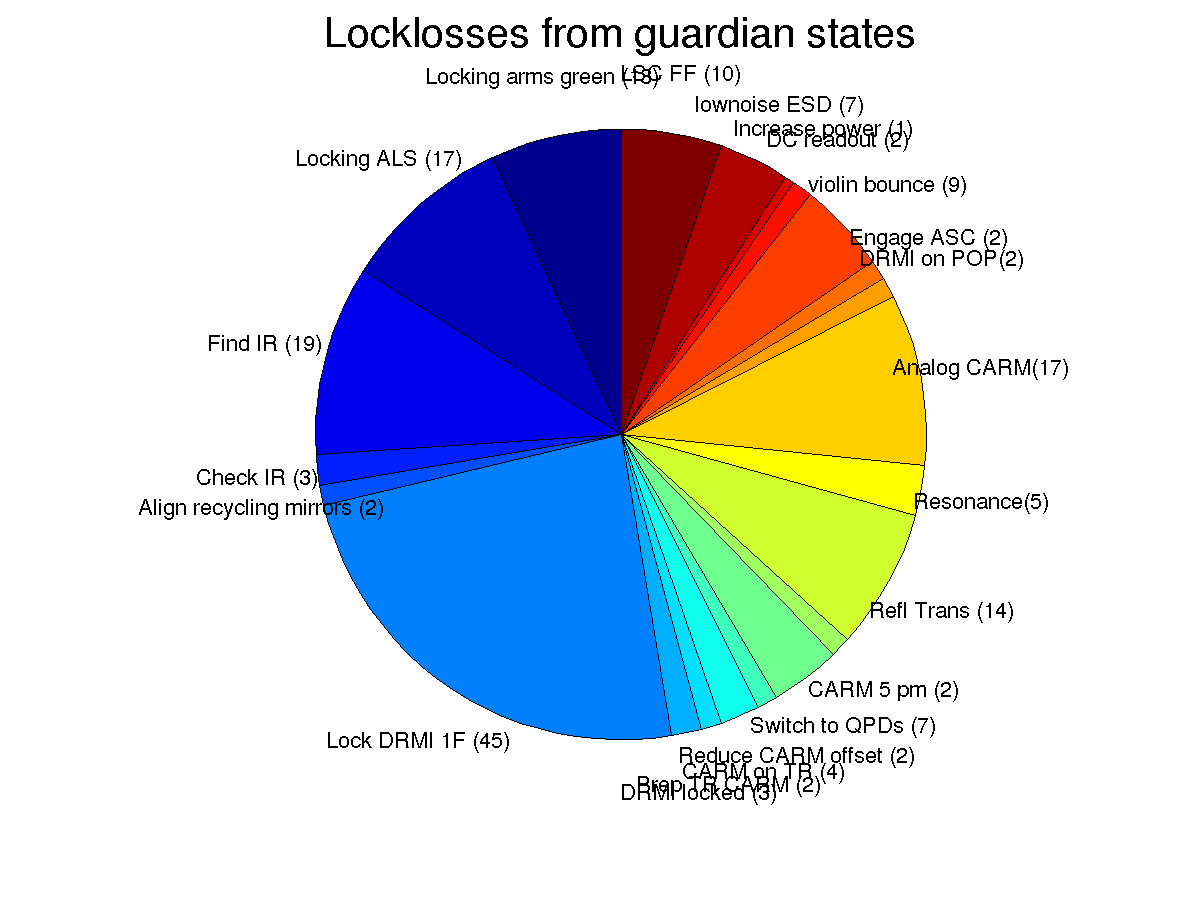
A more careful study of locklosses during ER7 needs to be done. The last plot attached here shows from which guardian state we lost lock, they are fairly well distributed throughout the lock acquisition process. The locklosses from states after DRMI has locked are more costly to us, while locklosses from the state "locking arms green" don't cost us much time and are expect as the optics swing after a lockloss.
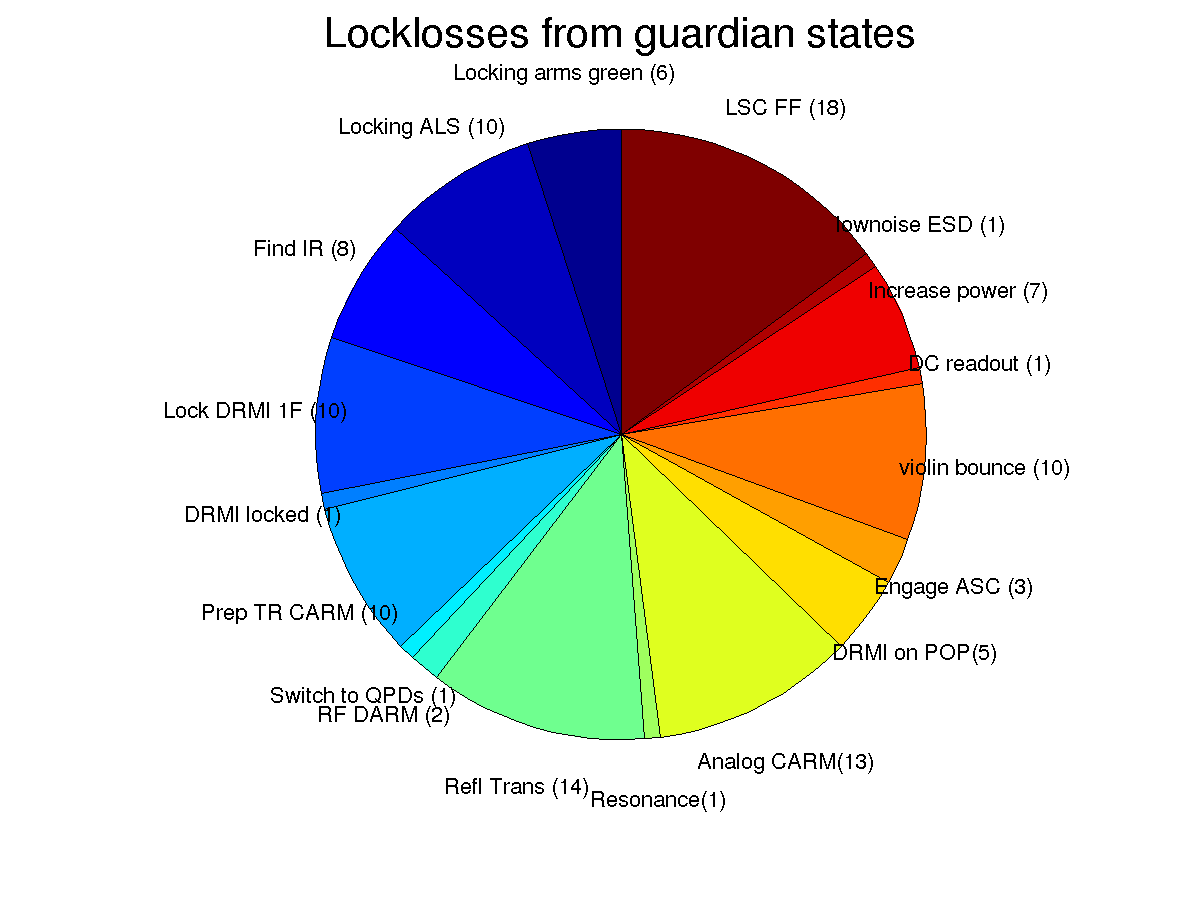
I used the channel H1:GRD-ISC_LOCK_STATE_N to identify locklosses in to make the pie chart of locklosses here, specifcally I looked for times when the state was lockloss or lockloss_drmi. However, this is a 16 Hz channel and we can move through the lockloss state faster than 1/16th of a second, so doing this I missed some of the locklosses. I've added 0.2 second pauses to the lockloss states to make sure they will be recorded by this 16 Hz cahnnel in the future. This could be a bad thing since we should move to DOWN quickly to avoid ringing up suspension modes, but we can try it for now.
A version of the lockloss pie chart that spans the end of ER7 is attached.
I'm bothered that you found instances of the LOCKLOSS state not being recorded. Guardian should never pass through a state without registering it, so I'm considering this a bug.
Another way you should be able to get around this in the LOCKLOSS state is by just removing the "return True" from LOCKLOSS.main(). If main returns True the state will complete immediately, after only the first cycle, which apparently can happen in less than one CAS cycle. If main does not return True, then LOCKLOSS.run() will be executed, which defaults to returning True if not specified. That will give the state one extra cycle, which will bump it's total execution time to just above one 16th of a second, therefore ensuring that the STATE channels will be set at least once.
reported as Guardian issue 881
Note that the corrected pie chart includes times that I interprerted as locklosses that in fact were times when the operators made requests that sent the IFO to down. So, the message is that you can imagine the true picture of locklosses is somewhere intermediate between the firrst and the second pie charts.
I realized this new mistake because Dave asked me for an example of a gps time when a lockloss was not recorded by the channel I grabbed from nds2, H1:GRD-ISC_LOCK_STATE_N. An example is
1117959175
I got rid of the return True from the main and added run states that just return true, so hopefully next time around the channel that is saved will record all locklosses.