Something happened at lock loss and the IFO did not reach the defined DOWN state.
Symptoms:
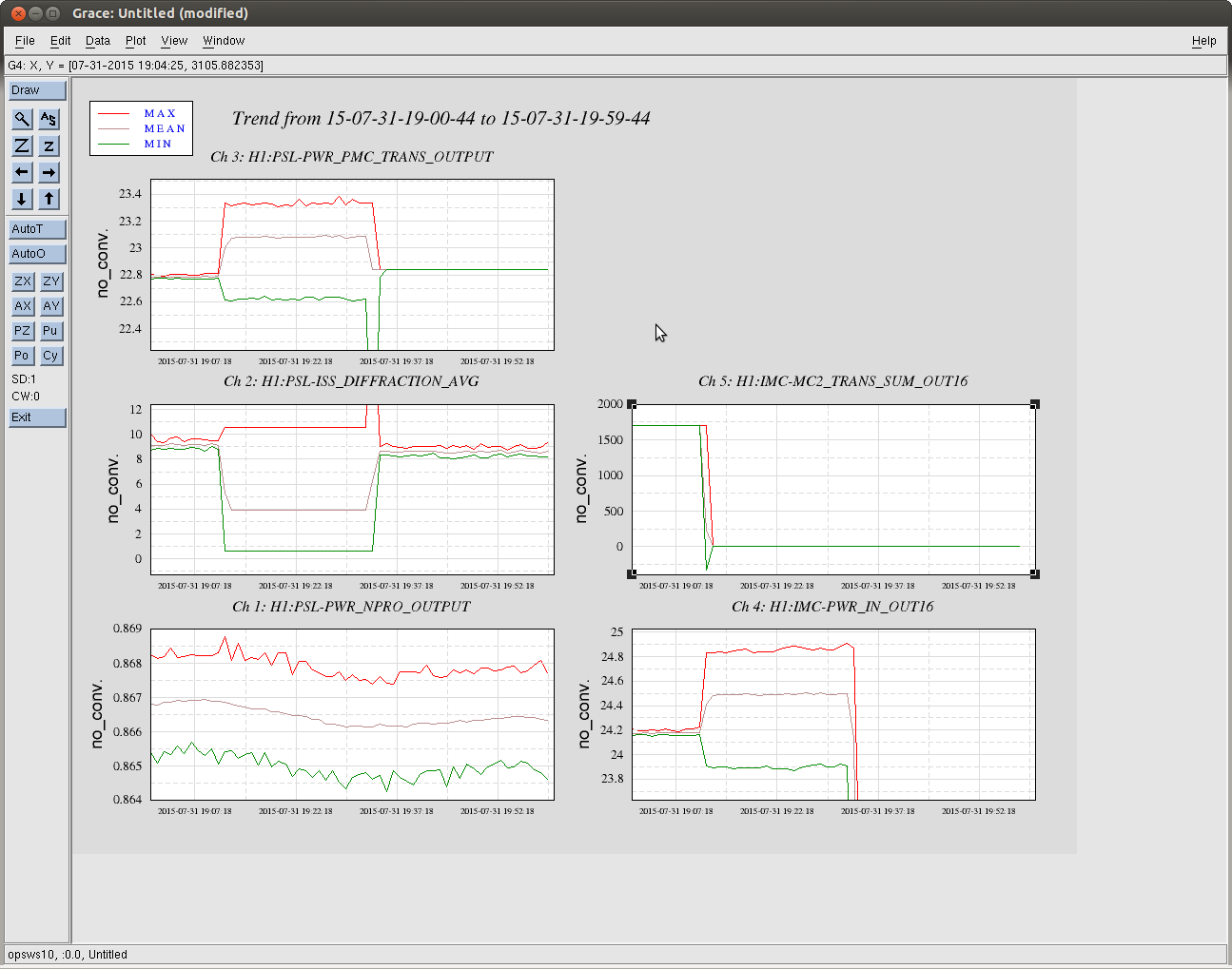
- SUS: ITMX, ITMY, ETMY - driven and rung up, watchdogs tripped, I had to adjust the RMS limit on ETMY from 8000 to 10000 to reset watchdog
- SEI: ITMY ISI tripped - Jim rest
- IO: MC WFS left pushing optics to a bad place and needed to be cleared by hand
- PSL: ISS and FSS in oscillation - outer loop on while IMC was unlock, throwing inner loop into oscillation
- GRD: ISC_LOCK - red for a while, cleared after INIT
Dave, Jaime, Sheila, operators, and others are investigating.
Let me try to give a slightly more detailed narrative as we were able to reconstruct it:
- At around 11:55, Dave initiated a DAQ restart. At this point the IFO was locked in NOMINAL_LOW_NOISE.
- The DAQ restart came with a restart of the NDS server being used by Guardian.
- The IMC_LOCK guardian node was in ISS_ON, which utilizes cdsutils.avg(), which is an NDS call. When the NDS server went away, the cdsutils.avg() threw a CdsutilError which caused the IMC_LOCK node to go into ERROR where it waits for operator reset (bug number 1).
- The ISC_LOCK guardian node, which manages the IMC_LOCK node, noticed that the IMC_LOCK node had gone into ERROR and itself threw a notification.
- No one seemed to notice that a) the IMC_LOCK node was in error and b) that the ISC_LOCK node was complaining about it (bug number 2)
- At about 12:12 the IFO lost lock.
- The ISC_LOCK guardian node relies on the IMC_LOCK guardian node to report the lock losses. But since the IMC_LOCK node was in error it wasn't doing anything, which of course includes not checking for lock losses. Consequently the ISC_LOCK node didn't know the IFO had lost lock, it didn't repond and didn't reset to DOWN, and all the control outputs were left on. This caused the ISS to go into oscillation, and it drove multiple suspensions to trip.
So what's the take away:
bug number 1: guardian should have caught the NDS connection error during the NDS restart and gone into a "connection error" (CERROR) state. In that case, it would have continually checked the NDS connection until it was re-established, at which point it would have continued normal operation. This is in contrast to the ERROR state where it waits for operator intervention. I will work on fixing this for the next release.
bug number 2: The operators didn't know or didn't repond to the fact that the IMC_LOCK guardian had gone into ERROR. This is not good, since we need to respond quickly to these things to keep the IFO operating robustly. I propose we set up an alarm in case any guardian node goes into ERROR. I'll work with Dave et. al to get this setup.
As an aside, I'm going to be working over the next week to clean up the guardian and SDF/SPM situation to eliminate all the spurious warnings. We've got too many yellow lights on the guardian screen, which means that we're now in the habit of just ignoring them. They're supposed to be there to inform us of problems that require human intervention. If we just leave them yellow all the time they end up having zero affect and we're left with a noisy alarm situation that everyone just ignores.
A series of events lead to the ISC_LOCK Gaurdian to not understand that there was a lockloss.
- ISC_LOCK was brought to DOWN after realizing the confusion.
- A series of events lead to the ISC_LOCK Gaurdian to not understand that there was a lockloss.
- ISC_LOCK was brought to DOWN after realizing the confusion.
- DAQ restart by Dave at 11:55 PST
- IMC_LOCK went into Error with a "No NDS server available" from the DAQ restart
- This was not seen by the operator, or was dismissed as a result of the restart.
- Lockloss at 12:12 PST
- ISC_LOCK did not catch this lock because IMC_LOCK was still in Error.
- Since the ISC_LOCK thought it was still in full lock, it was still actuating on many suspensions and trip some watchdogs (like Daves alog20111)
- ISC_LOCK was brought to DOWN after realizing the confusion.
To prevent this from happening in the future, Jamie will have Guardian continue to wait for the NDS server to reconnect, rather than stopping and waiting for user intervention before becoming active again. I also added a verbal alarm for Guardian nodes in Error to alert Operators/Users that action is required.
(If i missed something here please let me know)