jeffrey.kissel@LIGO.ORG - posted 16:13, Monday 31 August 2015 (21057)
SR3 Guardian Locked Up and Unresponsive This Morning
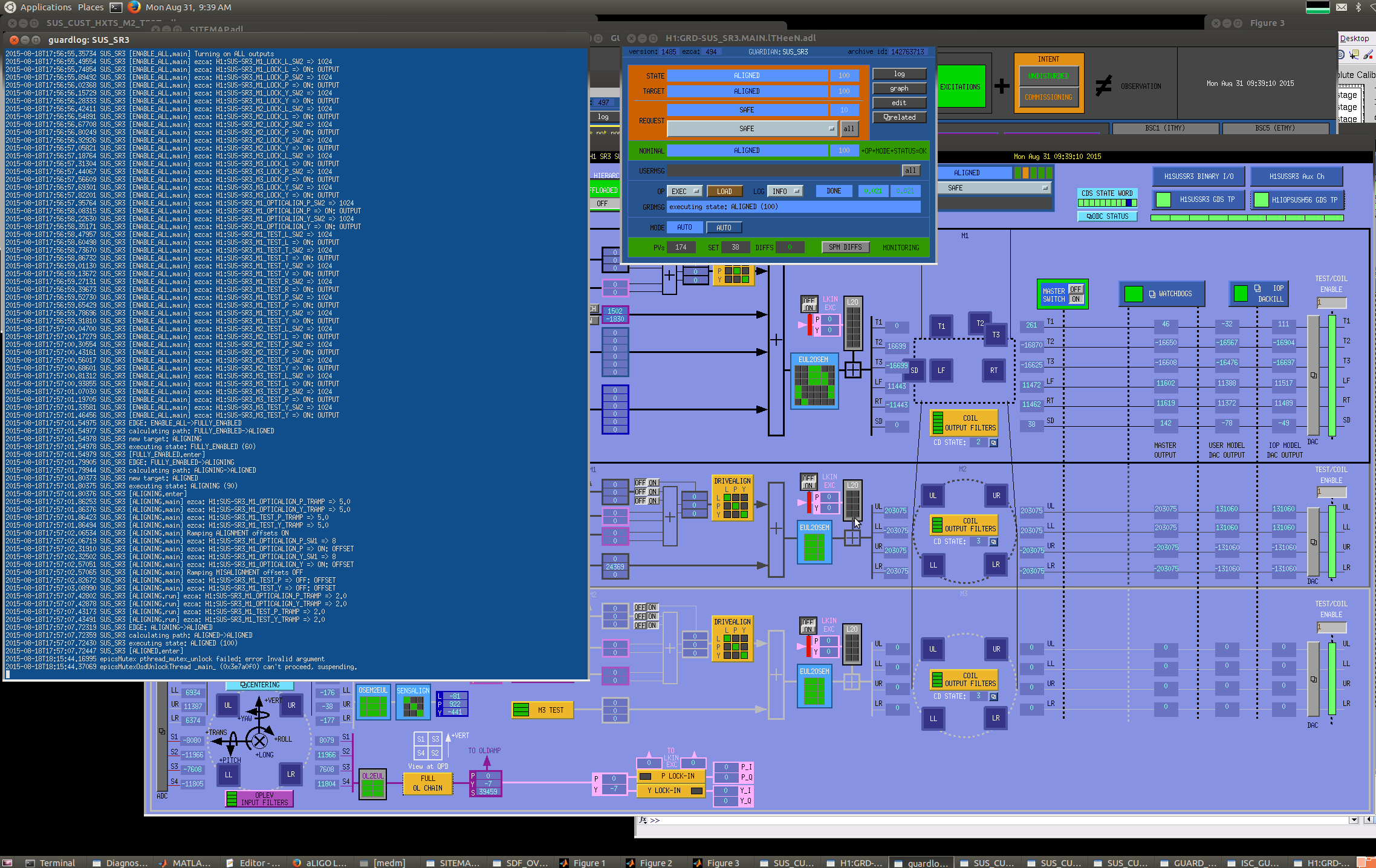
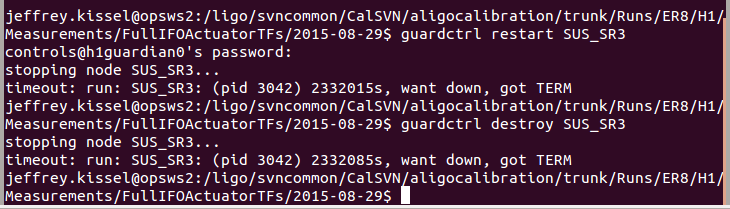
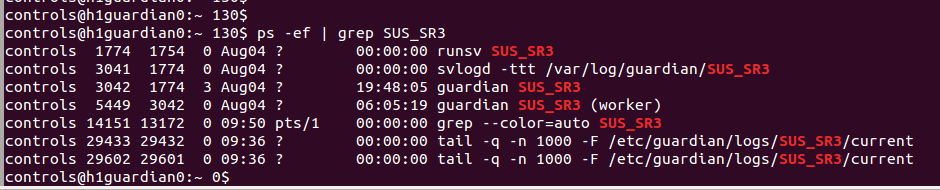
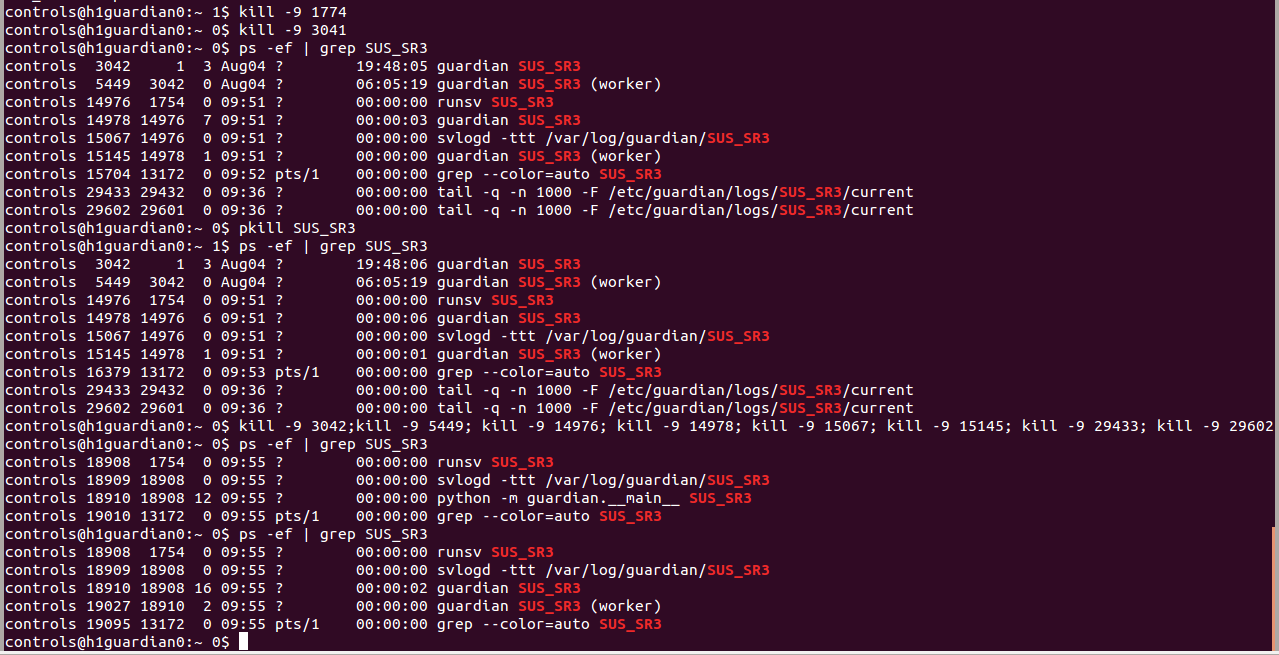
J. Kissel, K. Izumi, S. Dwyer, N. Kijbunchoo While trying to being the h1sush56 SUS (SR3, SRM, and OMC) to safe for DAC calibration of all cards in that chassis (see LHO aLOG 21048), we had great trouble with the SUS_SR3 guardian node. This node is not managed, but it was entire unresponsive to requests to change its state, to load, to pause, to stop, anything. Sadly, this was all true and the guadian node screen did *not* turn red indicating its in error. Looking at the guardian log, there was a message: epicsMutex pthread_mutex_unlock failed: error Invalid argument epicsMutexOsdUnlockThread _main_ (0x3e7a0f0) can't proceed, suspending. This is after requesting the ISC_LOCK guardian to DOWN. Note, we also had the SR3_CAGE_SERVO guardian still running, because, though this is managed by the ISC_LCOK guardian, it does not turn it OFF in the DOWN state. Probably not the issue, but it gathered our attention because it had gone nuts and was driving the M2 stage into constant saturation. See first attachment for screenshot of the broken situation. For the record this has happened on a smattering of guardian nodes in the past, see LHO aLOGs 17154 and 16967. ----------------------- Here's what we did to solve the problem: - Tried to restart the guardian node from a work station, guardctrl restart SUS_SR3 No success. - Tried to destroy the guardian node from a work station, guardctrl destroy SUS_SR3 No success. Both report stopping node SUS_SR3... timeout: run: SUS_SR3: (pid 3042) 23232015s, want down, got TERM (see second attachment). - Tried logging into guardian machine, h1guardian0, and began to kill process IDs sound on the machine related to SUS_SR3, (see third attachment). - Curiously, as I killed the first two processess, runsv SUS_SR3 and svlogd -ttt /var/log/guardian/SUS_SR3 as soon as I killed the latter, the guardian log came alive again, and the the SUS_SR3 node became responsive. - At Kiwamu's recommendation, I killed all processes simultaneously, destroyed the node, and restarted the node, just to make sure that all bad joojoo had been cleared up. ---------------- The problem is now solved, and we've moved on. Unsure what to do about this one in the future other than the same successively agressive restarting techniques...
Images attached to this report