Rolf, Richard, Jeff, Betsy, Travis, Filiburto, Carlos, Jonathan, Greg, Sudarshan, Dave
Front Ends
All IOCs and front end computers were power cycled. Recovery of Dolphin systems was delayed due to fault in h1seiex, which needed a second reboot to clear. (Jeff requests the split of the single Dolphin master into three be bumped up in priority).
Some IOP models went into "negative" IRIG range for a few minutes. Some corner station systems went into the high positive range and took several hours to come down to operational range. At time of this report, only SEIH45 has an IRIG error.
Yesterday I checked that there were no partial filter module loads or modified files, so the restart should not have loaded any new filters.
Hartman Wavefront Sensors
Elli restarted the HWS code at both EX and EY. The EDCU alerted us that this was not running, EDCU is now GREEN.
DAQ
The DAQ rode through the outage and recovery with no problems. I have cleared the accumulated CRC errors between the FECS and the DAQ concentrator due to the restarts.
DMT
Greg reports all DMT systems are fully recovered.
PCAL camera
Sudarshan and Carlos brought the PCAL camera systems back online.
SDF
All systems are now using their OBSERVE.snap files for their SDF reference.
Restart log
The full restart log is attached. The filtermodule DAQ restart strings shows the last start times for each model alphabetically

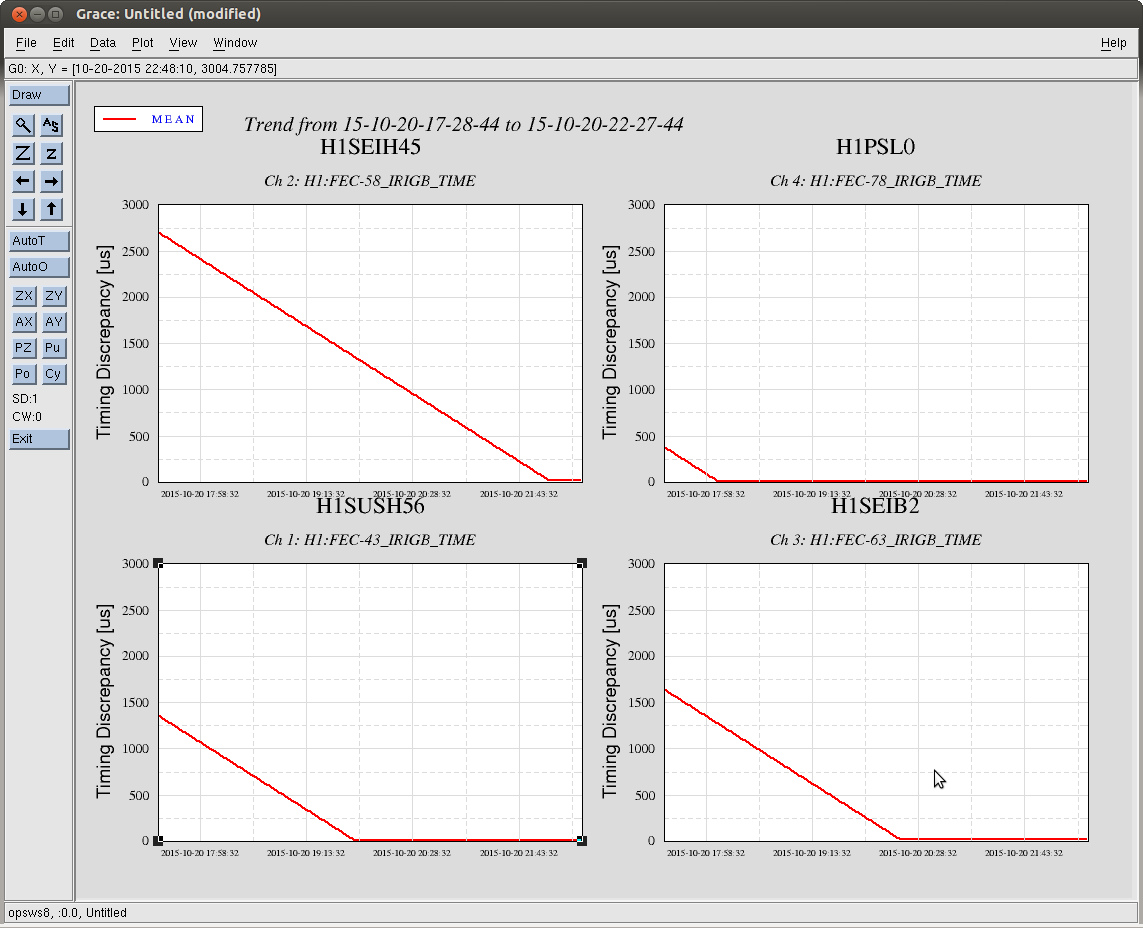
After clearing problems with the dolphin network, and untripping all watchdogs, there remained incosequential IRIG-B Timing Errors present on the CDS State Word on several front-ends, h1sush56 h1seih45 h1seib2 h1psl0 These errors are a result of the IRIG-B system not starting up in sync with the 1 PPS timing signal. They eventually go away after some time as the IRIG-B slowly begins to synchronize, as it did in this case. I document it just for future reference that these errors are not-surprising, and have little-to-no impact on recovery.
J. Kissel, B. Weaver, J. Driggers, H. Radkins When all front-ends die and restart, they come back pointing to their SAFE.snap SDF file. Once front end computers up, running, and mostly happy and we began to *use* the front-ends to recover the IFO, we began to change all of the SAFE.snaps to the nominal OBSERVE.snaps to help us continue to figure out what settings were out of place. This is a pretty tedious task, but once through, we reverted everything and requested the ISC guardians to run their DOWN states. This worked out quite well, but we really could use a script that switches all FE's SDF tables from SAFE.snap to OBSERVE.snap.
J. Kissel, K. Thorne, D. Barker, R. Bork, J. Hanks, R. Blair Since it was unclear where to find the recovery process for the front-ends given how interwoven they are, I outline the process that Keith had suggested and we ended up following once Dave got in: Depending on the length of the power outtage some front-end computers may or may not survive the outtage. However, again, given the interwoven systems, we've found it best to perform a systematic shut-down such that all computers and their interactions can be brought up in a controlled fashion. With the current setup of the dolphin network, the power-down and power-up procedure should be performed at the end-stations first, because the corner-station computers won't start until the end-station dolphin network is up and functional. As Dave mentions, I've requested that LHO adopt LLO's splitting of the dolphin fabrics, such that one can truely exercise the end stations independently of the corner. Power-down and power-up procedure - Power down all front end computers in the MSR (for corner station) or Entrance Lobby (for end stations). This is done by holding down the power button for ~5 [sec]. - Power down all I/O Chassis in the CDS Highbays. The rocker switches on the front panels don't always work, so you may have to use the rocker switch on the back of the chassis above where the +/- 24 [V] comes in. - Power cycle DC power supplies (recommended by LLO, unclear whether Richard did this before we got in in the morning. We did *not* do this systematically when we ran this power-down power-up procedure today) - Power up I/O chassis - Wait for timing slaves to be happy (relatively quick, but be sure to check) - Turn on front-end computers Once you turn on front-end computers, they will automatically start turning on the front-end processes. Recall that for SUS front-ends it may look (from the GDS-TP screens and the CDS overview) that the SUS computers are not coming back, but it's merely because they're running through the 18-bit DAC auto calibration, which takes ~3 to 5 minutes. This happens once the IOP model is started up, so from the CDS overview screen, it'll look like the IOP model came up dead, and the user models didn't start. Give it a few minutes before you get sad and go to restart the front-end processes by hand.