jeffrey.kissel@LIGO.ORG - posted 09:39, Tuesday 17 July 2018 - last comment - 10:46, Tuesday 17 July 2018(42929)
H1 SUS ITM Hardware Watchdog (HWWD) LEDs Glitching, No excess motion on ITMs
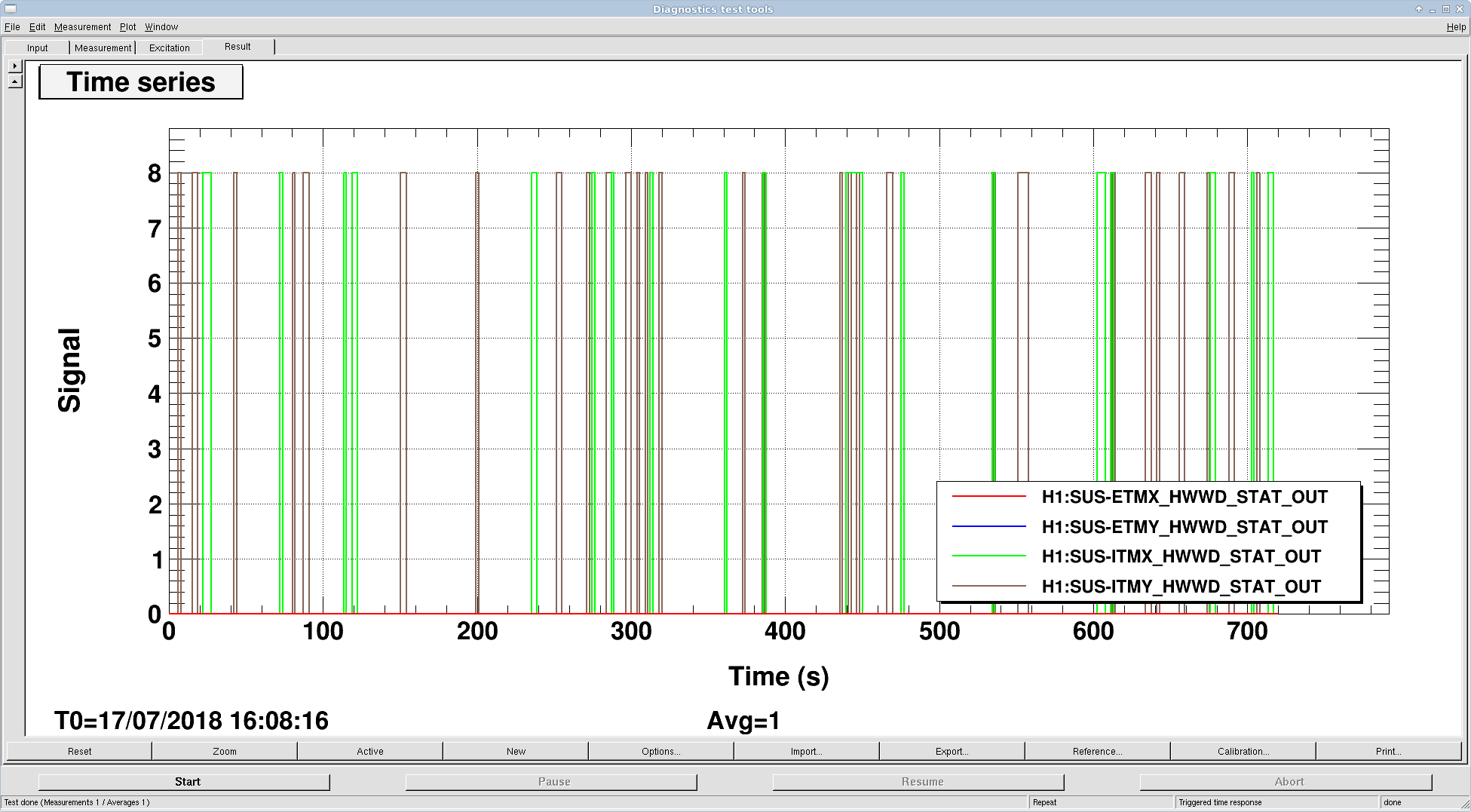
J. Kissel, E. Merilh While I was reconciling the QUAD SDF screens, I would occasionally see a channel from the Hardware Watchdogs (HWWDs) pop in and out of difference. Digging deeping into the MEDM screen for it, we found both ITMX and ITMY would flash the "LED" value red for a ~few seconds (H1:SUS-ITM[X/Y]_HWWD_STAT_OUT), start the countdown for shut down (H1:SUS-ITM[X/Y]_HWWD_TTF_MIN and H1:SUS-ITM[X/Y]_HWWD_TTF_SEC), and then flip back to green and happy. The glitching seems to have been going on all morning (see attached DTT time series of some 12 minutes taken while I was writing this aLOG). The channels appear to be a bit word, but I'm not sure what the meaning of 8 (or 2^3, or the third least significant bit) means. Of course, we had to check whether the QUADs were moving at all -- no dice. The trigger signals for the HWWD on equivalent Independent Software Watchdog (SWWD) screens -- RMS signals of the main chain (M0) top mass OSEMs -- are hovering around their usual ~0.1-0.3 mV RMS, which is WELL below the 110 mV threshold. Manually inspecting the ITM overview screens for excess motion, we see none. BSC-ISIs are happily in FULLY ISOLATED, SUS-ITMs in a DAMPED state, ALS green slowly / peacefully flashing. All sensors (and there are LOTS) report that it's all quiet on the LVEA front. Seeing no evidence for excess motion (even with Hugh inspecting HEPI for inventory around the ITM BSC chambers), we suspect something's awry with the electronics. Watching the GDS TP screens, the brief red status doesn't appear to coincide with any timing errors or IPC miscommunications. This may be a repeat of what we saw during O2, where the watchdog STATE (not STAT_OUT?) popped up to 8: Event 1: Aug 2017, LHO aLOG 37971, FRS Ticket 8666 and just after they were installed, Event 2: Oct 2016, just after install LHO aLOG 30467 although there's other instances where it has popped up to 16, Event 3: LHO aLOG 38160. Also found this: Event 4: May 2016 FRS Ticket 5240 which reports "bogus LED failure happens when the coils are being driven vigorously, only on ITM suspensions presumably due to longer monitor cables." But no coils are being driven "vigorously" though I'm not sure what that means quantitatively.
Images attached to this report
Comments related to this report
Now associated with FRS Ticket 11096 for this instance of the problem. Spoiler alert: I've spoken with Dave, and he confirms what's reported in FRS Ticket 5240: "The LED channel is measuring the voltage proportional to the current on the M0/Top Mass OSEM LEDs. The long cable runs in the corner station result in the following: - the coil drivers supply power to the satellite amplifiers, which is where the measurement of the LED current happens, which is then read out by the HWWD. The long cable runs bring the reported measured voltage *near* the HWWD's threshold. - a requested drive from the *coil drivers* (which power the *satellite amplifiers*) drops the voltage supplied to the sat amp just enough that it drops the voltage on the LED measurement even lower, now occasionally surpassing the threshold and briefly, errantly, reports badness. This doesn't happen at the end stations because the cable run is short enough to not cause enough additional voltage drop to bring the signal near threshold. Dave suggests that the fix requires a change in hardware, where we increase the threshold for reported badness and/or increase the amount of time that the signal is below voltage before an under-voltage is reported. He also confirms that "vigorously" is an exaggeration -- the under-voltage happens essentially any time the coil drivers are driven. He also reports that this has been intermittently happening since they've been installed. The bigger issue: these channels are monitored by the SDF system, so they're going to "trip" the OBSERVATION READY bit when we go back into observation. They should do so, if there *is* actually a wolf, so setting the channels to "NOT MONITORED" is not an option. So we must stop these boyish channels from crying wolf.
One suggestion for improvement is to change such read-backs that travel very long cables from voltage to 4-20mA current-loop. These do not suffer degradation over long cable runs. Typically one does not get as much resolution on current-loop readout, but might be fine in this case. Also, one can employ the vacuum system readout trick of placing a resistor across the current loop (near the digitizer) to convert to voltage.