This morning LLO reported that their SEI nodes would crash when reloaded. Since we just had a big earthquake, we had time to test. I tried random nodes for the most part:
| ISI_HAM4 | OK |
| HPI_HAM4 | OK |
| SEI_HAM4 | OK |
| ISI_ETMY_ST1 | Crash |
| ISI_ETMY_ST2 | Crash |
| HPI_ETMY | Crash |
| SEI_ETMY | OK |
| ISI_HAM3 | Crash |
| HPI_HAM3 | Crash |
The chamber managers seemed to be okay, but the ISIs and HPIs would most likely crash. The crashes were all because of a 20sec watchdog timeout. Doing a guardctrl restart would bring the nodes back without issue.
It's odd that we are just seeing this now, Jim has reloaded ISI_ETMX_ST2 a few times and not had an issue. There are a few other nodes listed above that crashed today, but have been reloaded since the new Guardian update as well. This could just be because they got lucky and finished whatever they needed to just before the timeout.
Attached a small bit of the log.
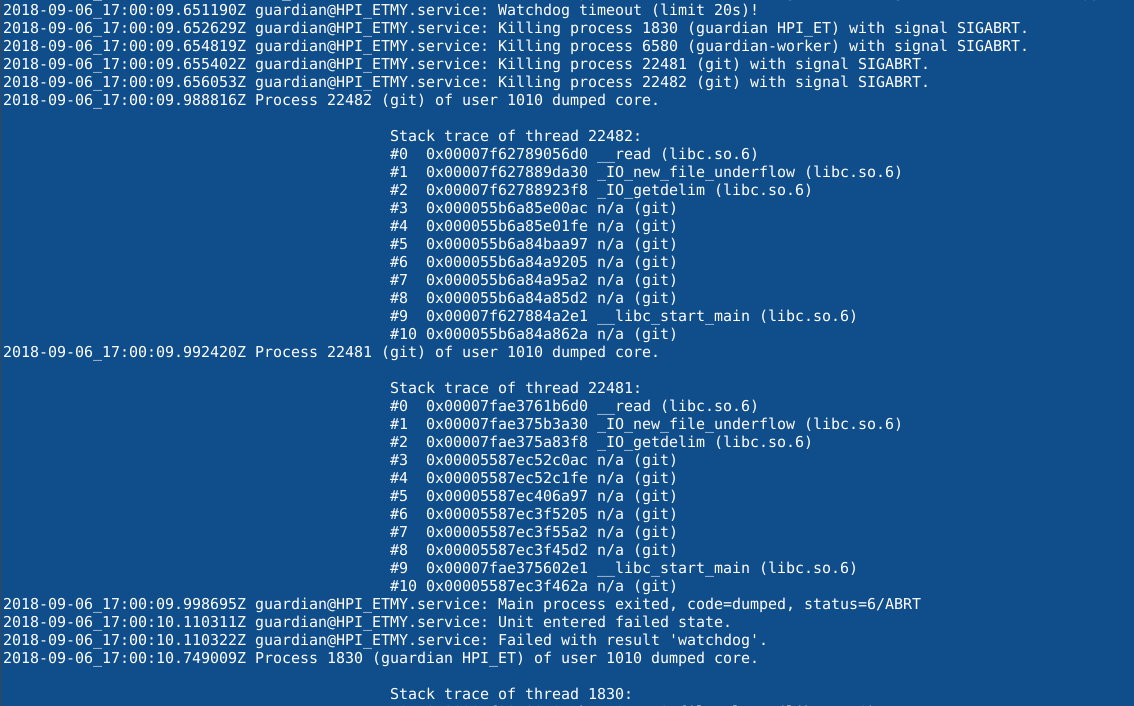
We are seeing the same problem at LLO LLO log 40575. Arnaud created a local FRS issue on this FRS 11410, but should be turned into an Integration Issue
When this was reported at LLO I suspected that this was a systemd watchdog timeout issue. Thank you for confirming, TJ. The work-around fix is trivial.
A relevant question though is why are the nodes taking so long to reload that they're tripping the timeout watchdog. The two "intensive" parts of the reload are reading all the code files from USERAPPS, and then committing them to the node archive. Both of those things involve NFS read/write. Could there be an issue with the NFS mount, either in general or specifically on h1guardian1?