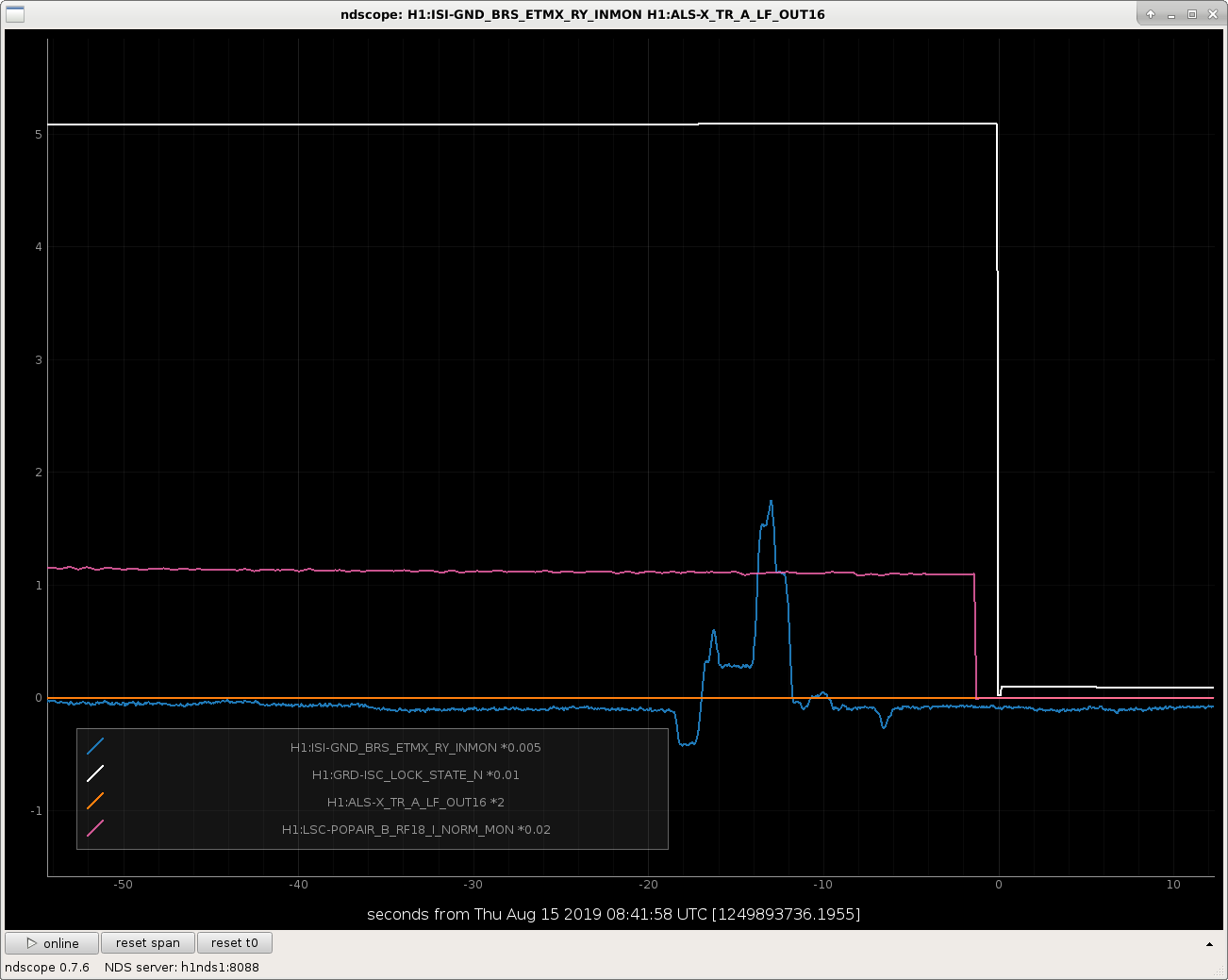
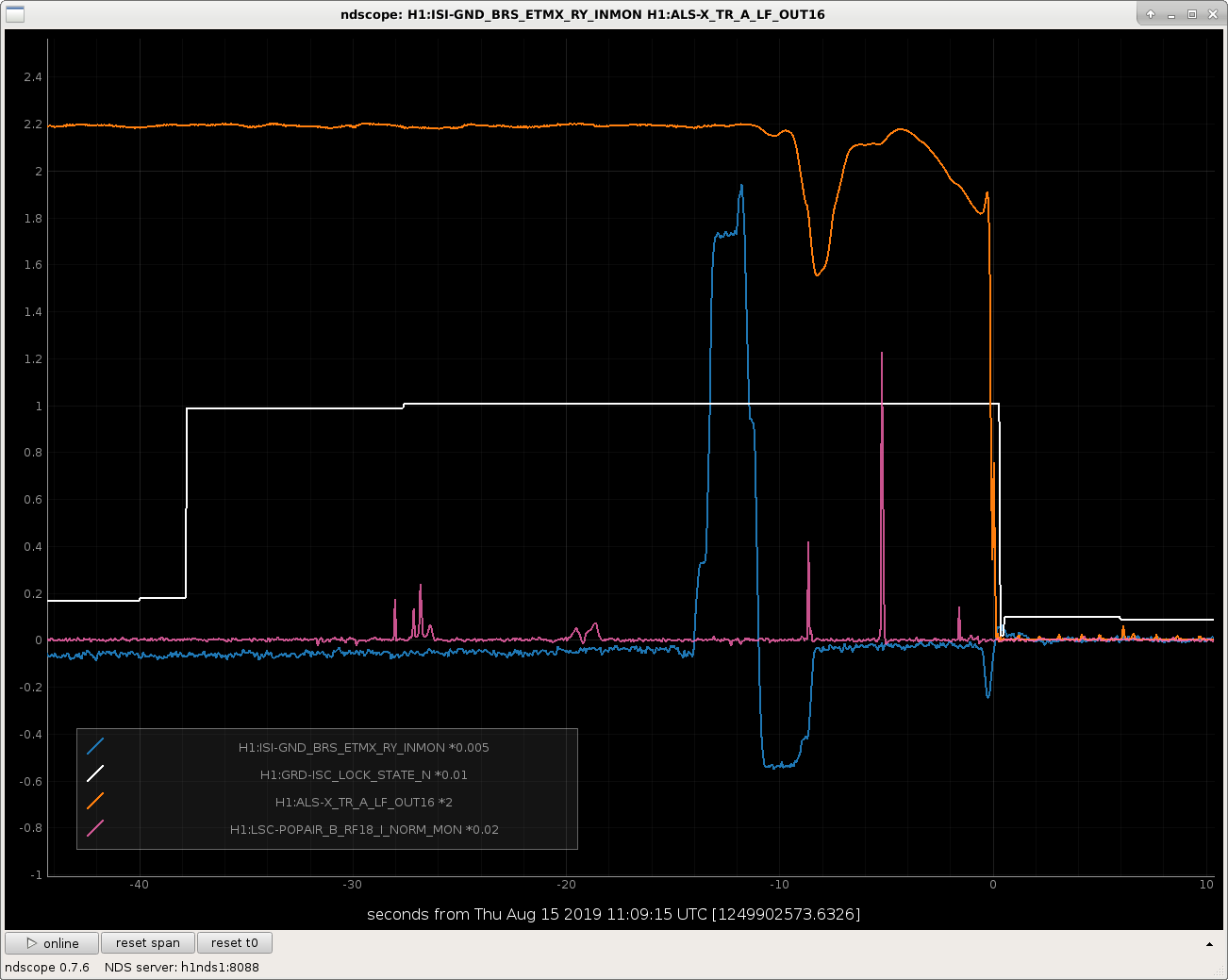
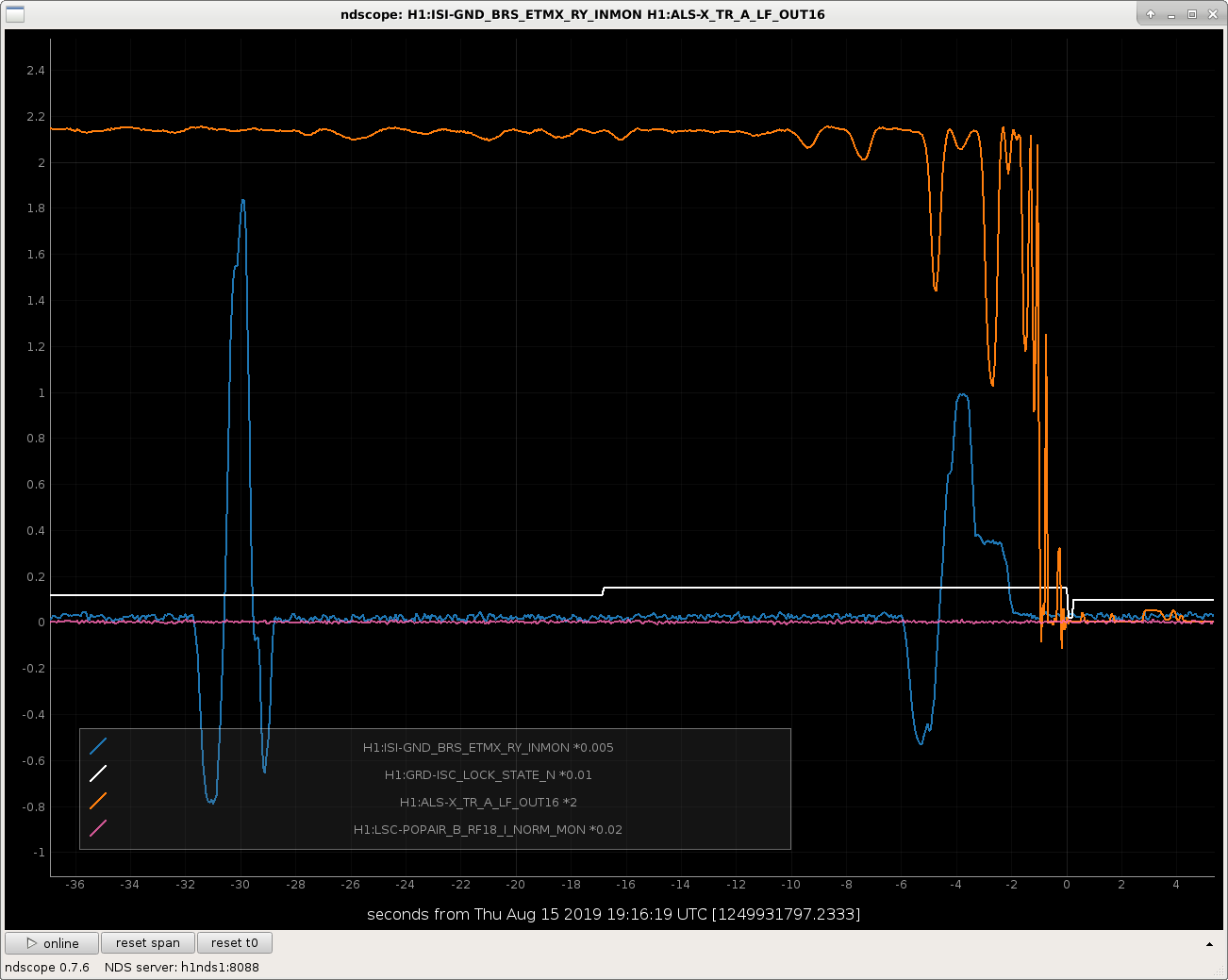
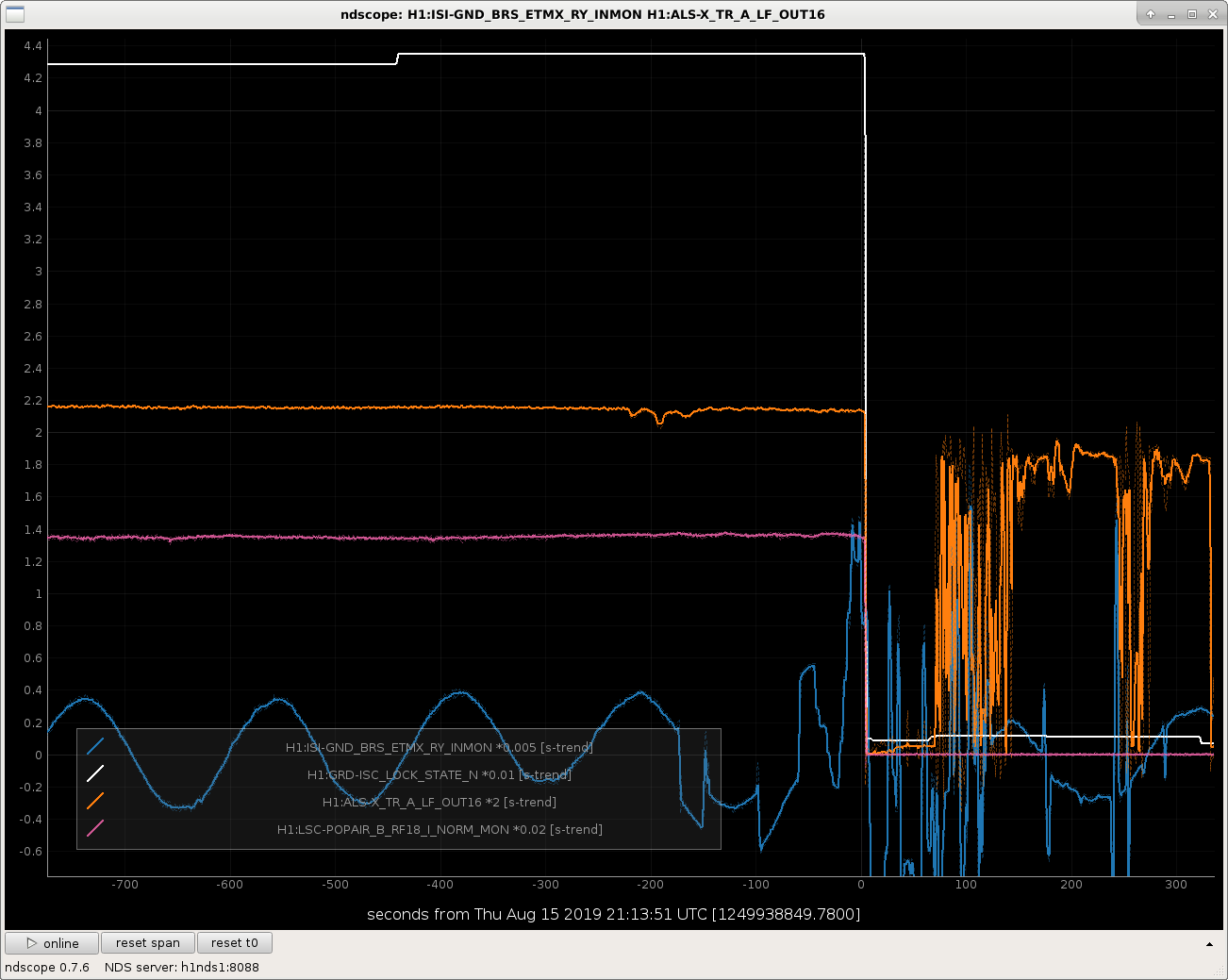
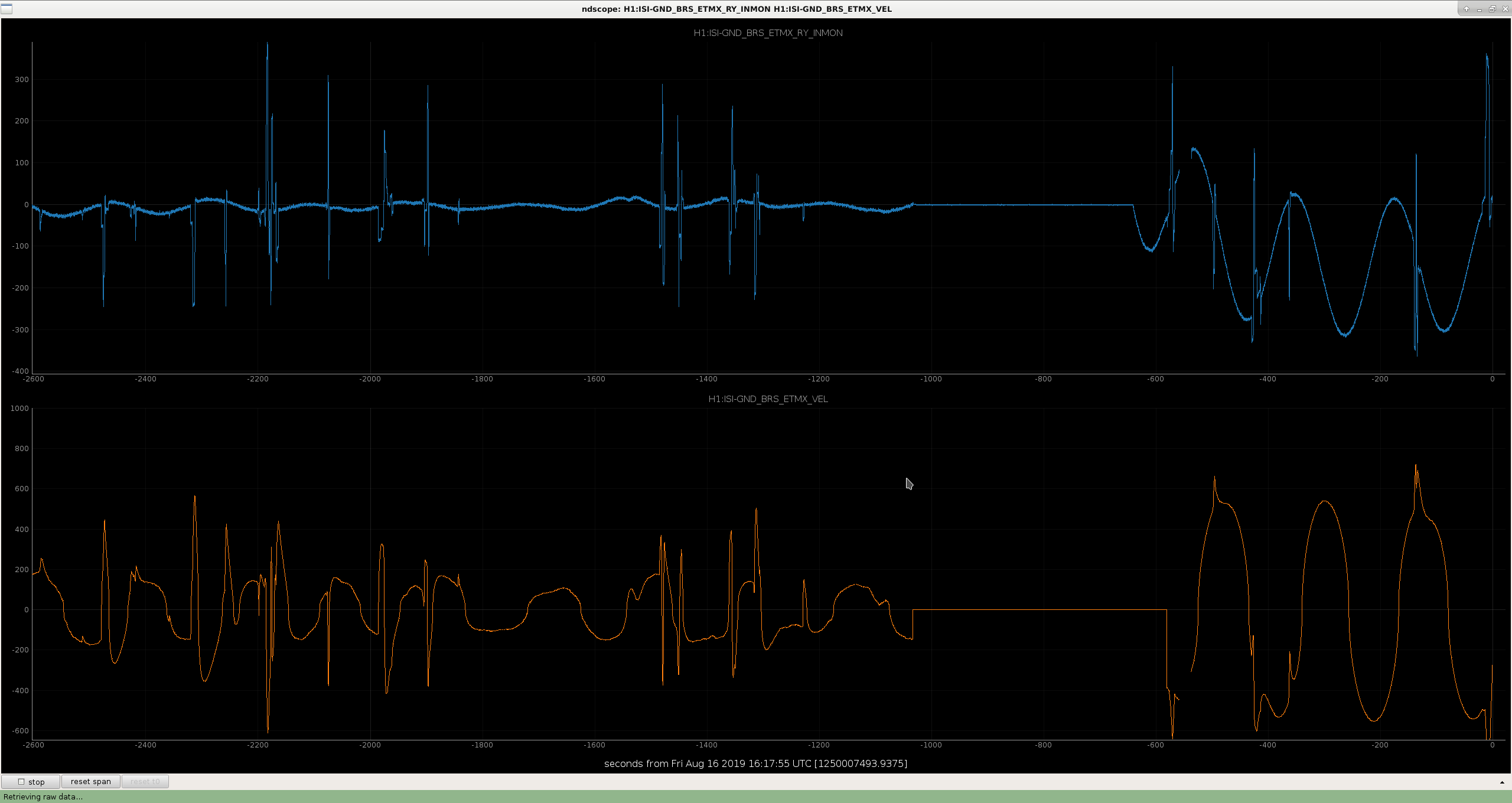
The BRS-corrected STS signal at X end looks different than the Y end, like it's got some jumps and discontinuities in it. Still looking, and I'm not 100% sure what channels I should be using, so anyone with seismic expertise, please comment or call the control room if the attachments don't include the correct channels.
In the first attached figure, you can see that we lost the Xarm ALS transmission during the time of one of these jumps.
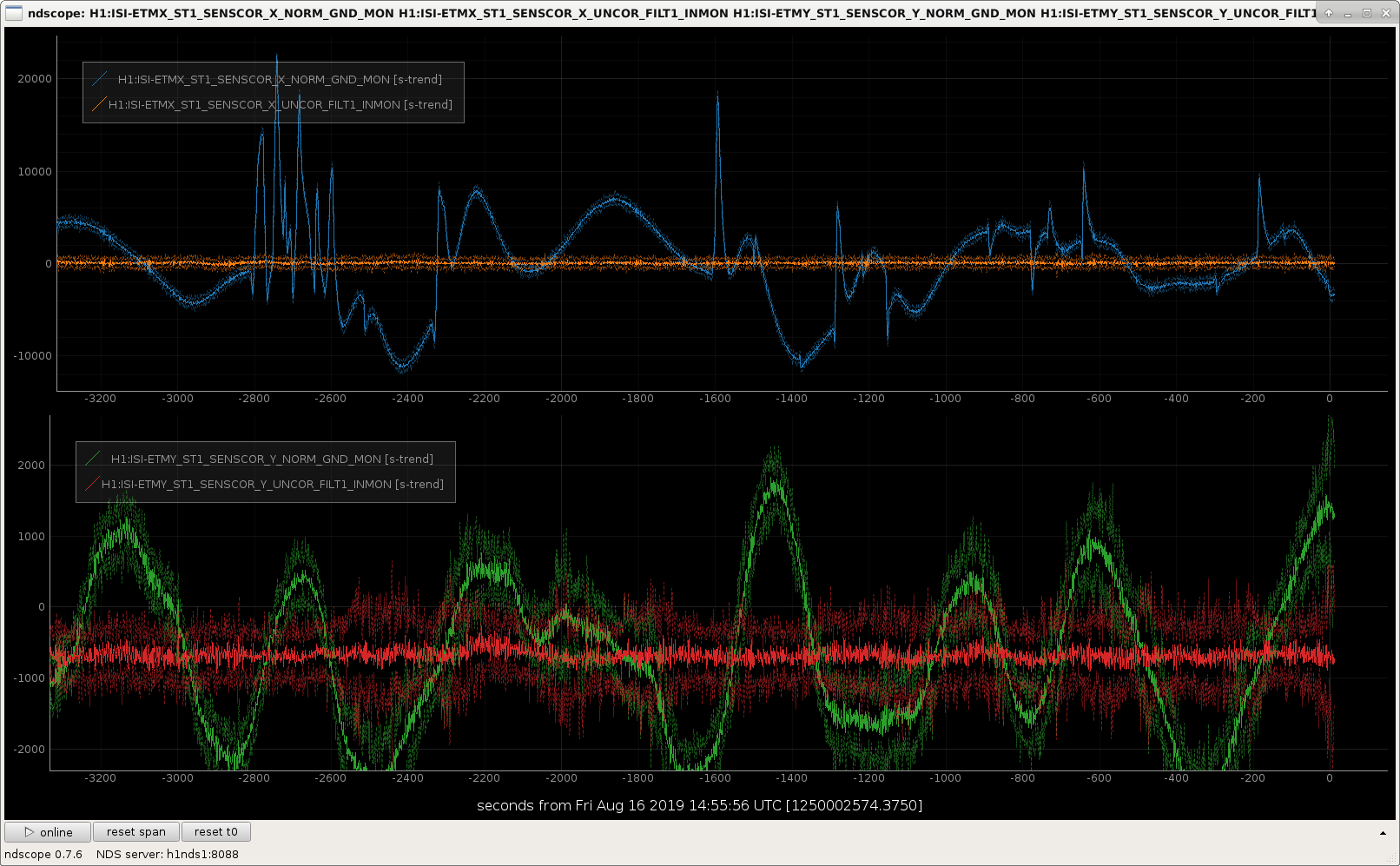
In the second attachment you can see a comparison of Xarm (top row) and Yarm (bottom row). The Xarm has these weird discontinuities, whereas the Yarm doesn't.
PeterK is working on the RefCav power right now (not that it's a blocker, but for lack of other ideas it seems good to fix things that need help....), but as soon as he's out I'll try locking without the Xarm BRS. Right now the wind is low, so we're probably not getting a lot of benefit from the BRS, so it should be fine to try.
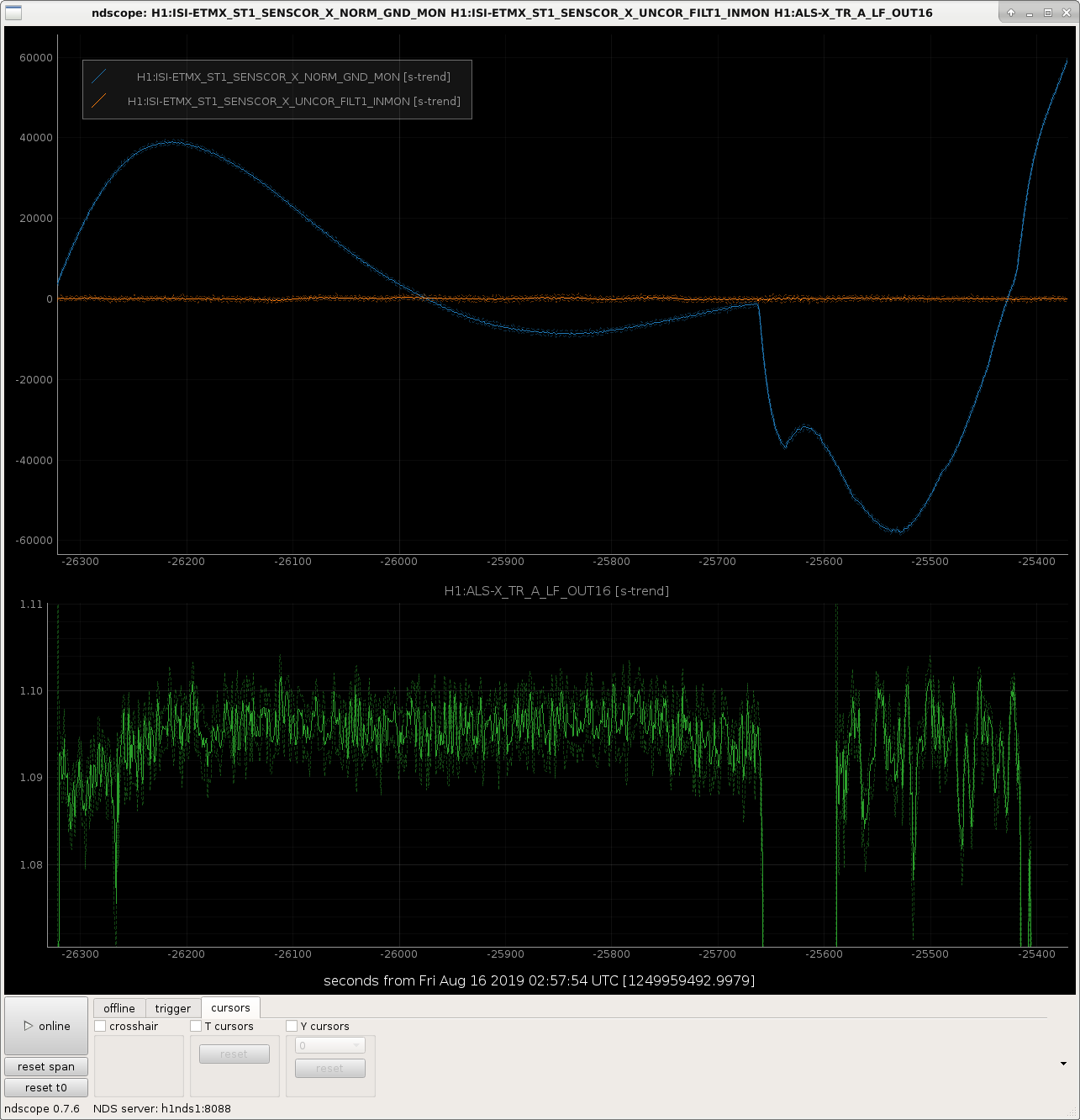
There is definitely a problem the BRSX. Attached screenshot shows the last 45 minutes or so, and the BRS is showing some weird glitches. Patrick and I tried restarting the Beckhoff (which is where the BRS signals go flat), but it doesn't seem to have fixed the BRS. I've emailed Michael at UW to see if he has any suggestions.
This will affect our use of the EARTHQUAKE state in the SEI_CONF guardian. If an earthquake comes in, it will be best to either leave the seismic system in the WINDY_NOBRSX state, or go to LARGE_EQ. If the eq state is used, that will send these glitches to all the platforms.
Now associated with FRS Ticket 13417.
In the attached figure, you can see that the glitching started during our last lock.
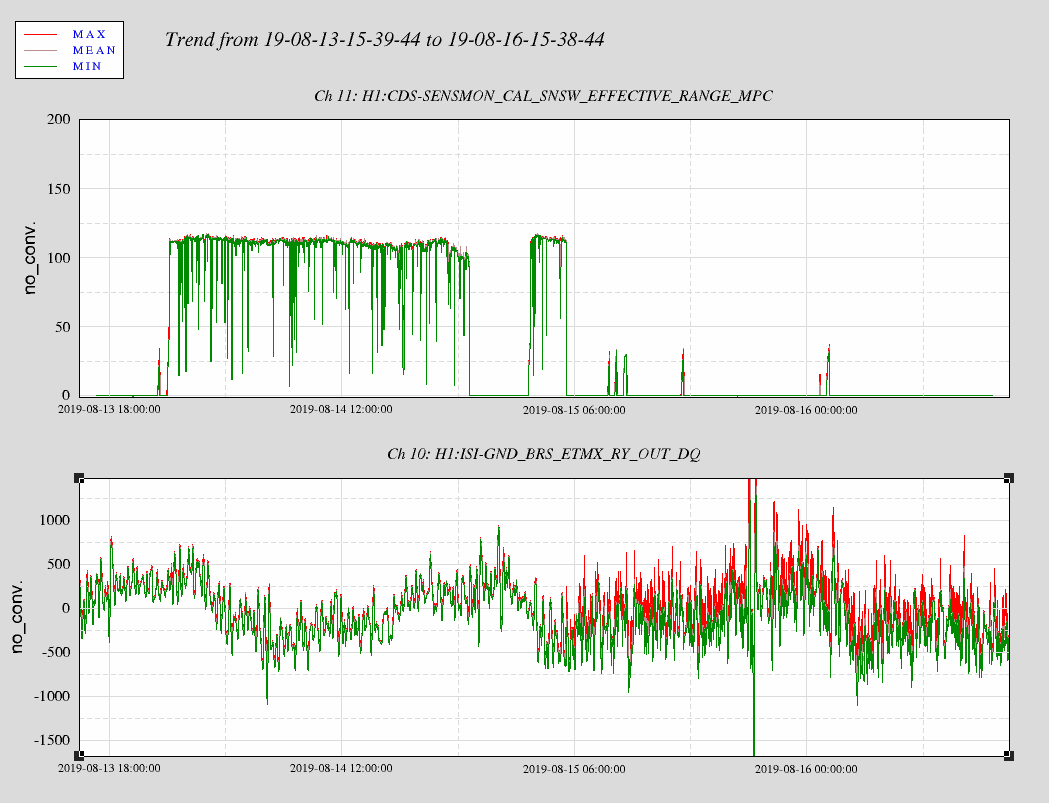
First glitch appears 2019-08-15 05:21 UTC, (Wednesday Night @ Aug 14 2019 22:21:00 PDT, 1249881678) -- exactly coincident with the last observational stretch of data... likely the cause of it.
However -- I hesitate to attribute *all* the observation time lost to just this one problem -- see
- Sheila's aLOG summarizing last night's efforts LHO aLOG 51307, and
- remember two night's ago when we found that the ALS DIFF beatnote was too low LHO aLOG 51280, and
- our continued attempts to battle the July-30 global alignment reference loss LHO aLOG 51275, and
- the squeezer laser's slow death LHO aLOG 51190 just repaired on Tuesday 8/13, and
- there have been large close Earthquakes in Mexico and Canada...
For future forensics of identifying the intermittent problem with the glitching BRS --
2019-08-15 19:57 UTC -- brief respot
20:55 UTC Big Single Glitch
21:10 UTC Resume regular glitching
2019-08-16 00:31 UTC -- brief respot
00:59 UTC -- resume regular glitching
02:34 UTC -- brief respot
02:57 UTC -- resume regular glitching
10:25 UTC -- brief respot
11:02 UTC -- resume regular glitching
13:32 UTC -- brief respot
14:09 UTC -- resume regular glitching
It looks like the glitches show up in the reference pattern (see attached) which would then contaminate the BRS output. The glitches appear to be discrete shifts which points to peaks of the reference pattern coming and going.
This looks very similar to the previous glitches that we saw in this device (40936) which, if I remember correctly, we narrowed down to being an insect walking along the surface of the CCD. The only way to confirm this without removing the camera would be to watch the patterns remotely. As the bug walks across the pattern single peaks should drop and then pop back up.

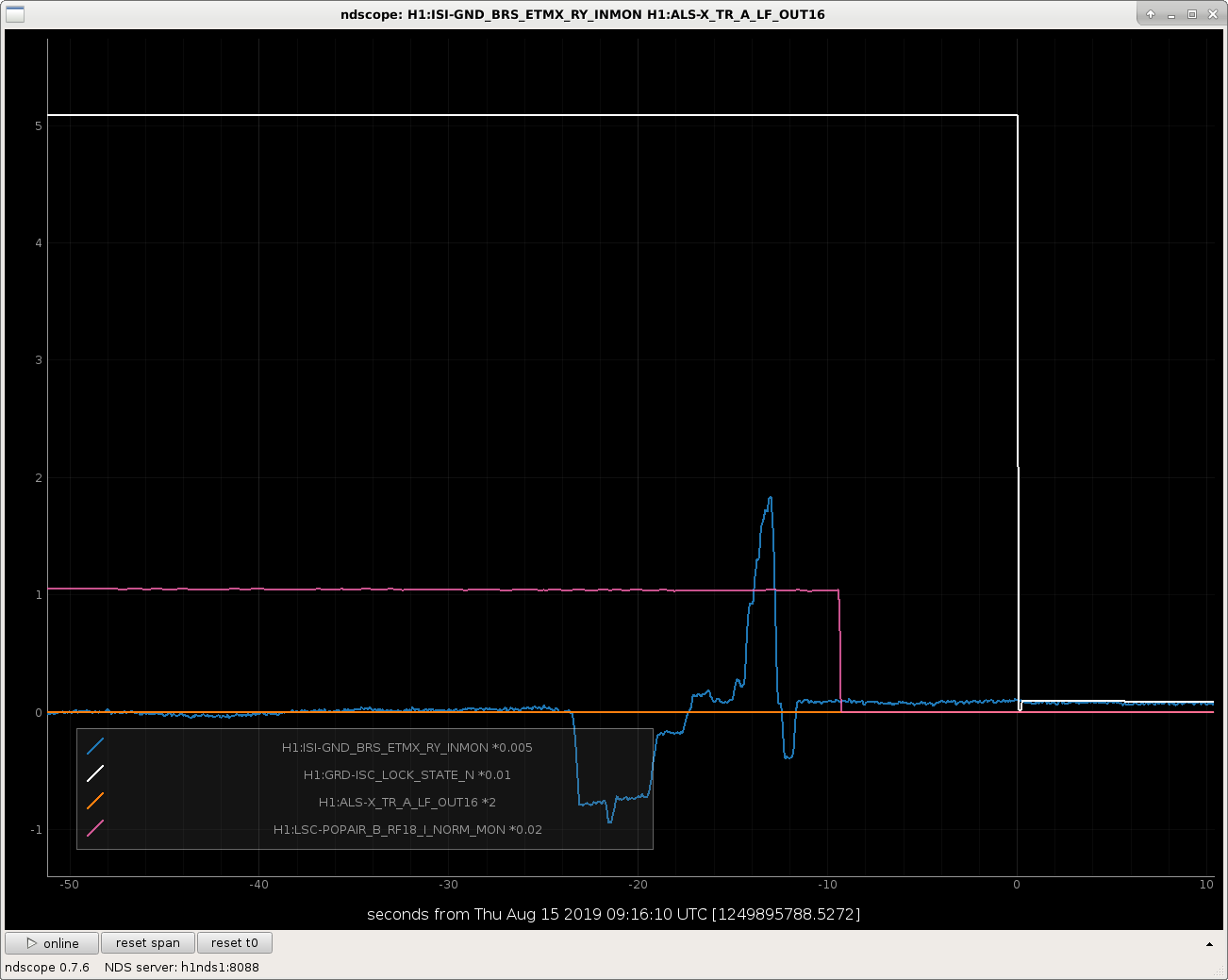
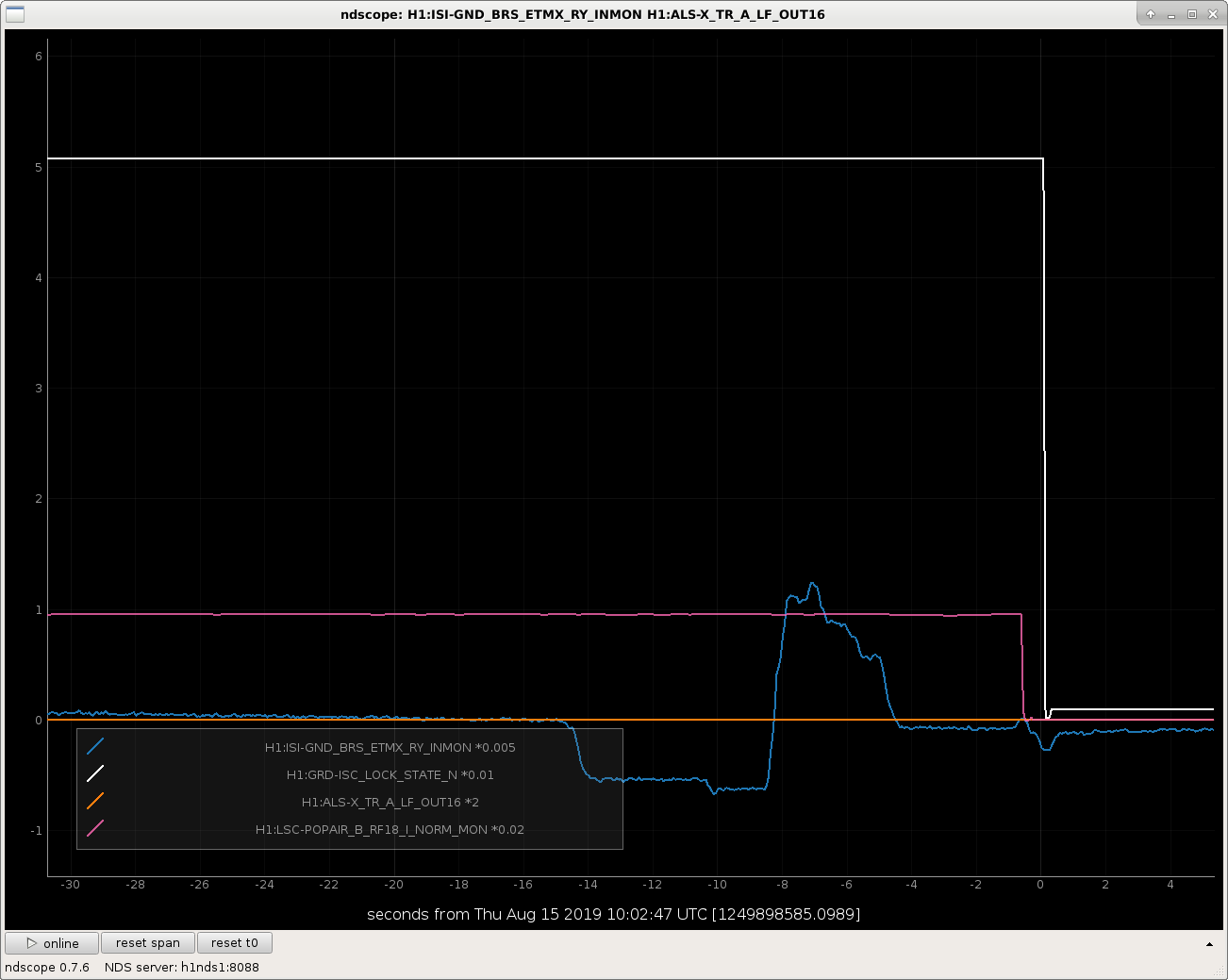
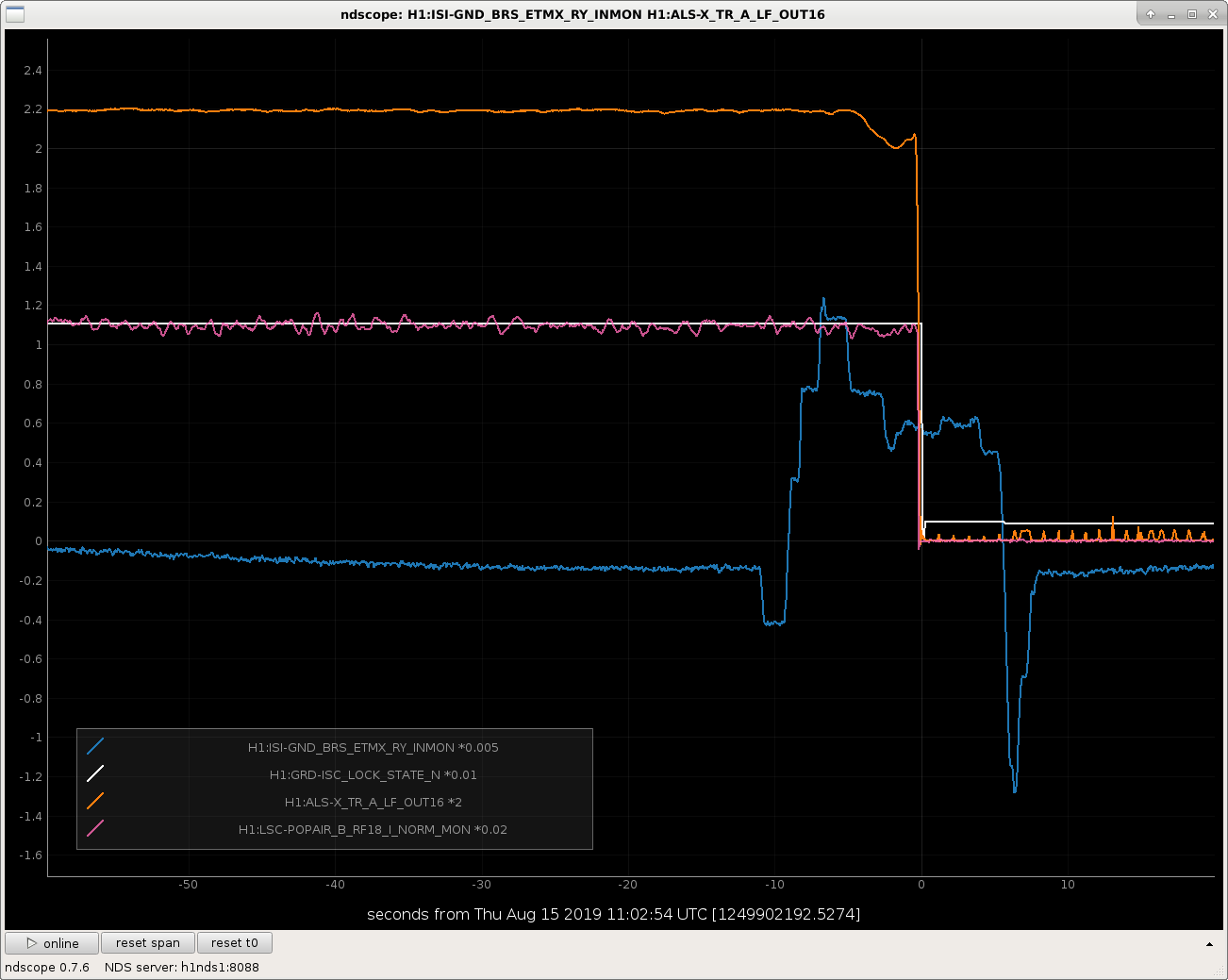
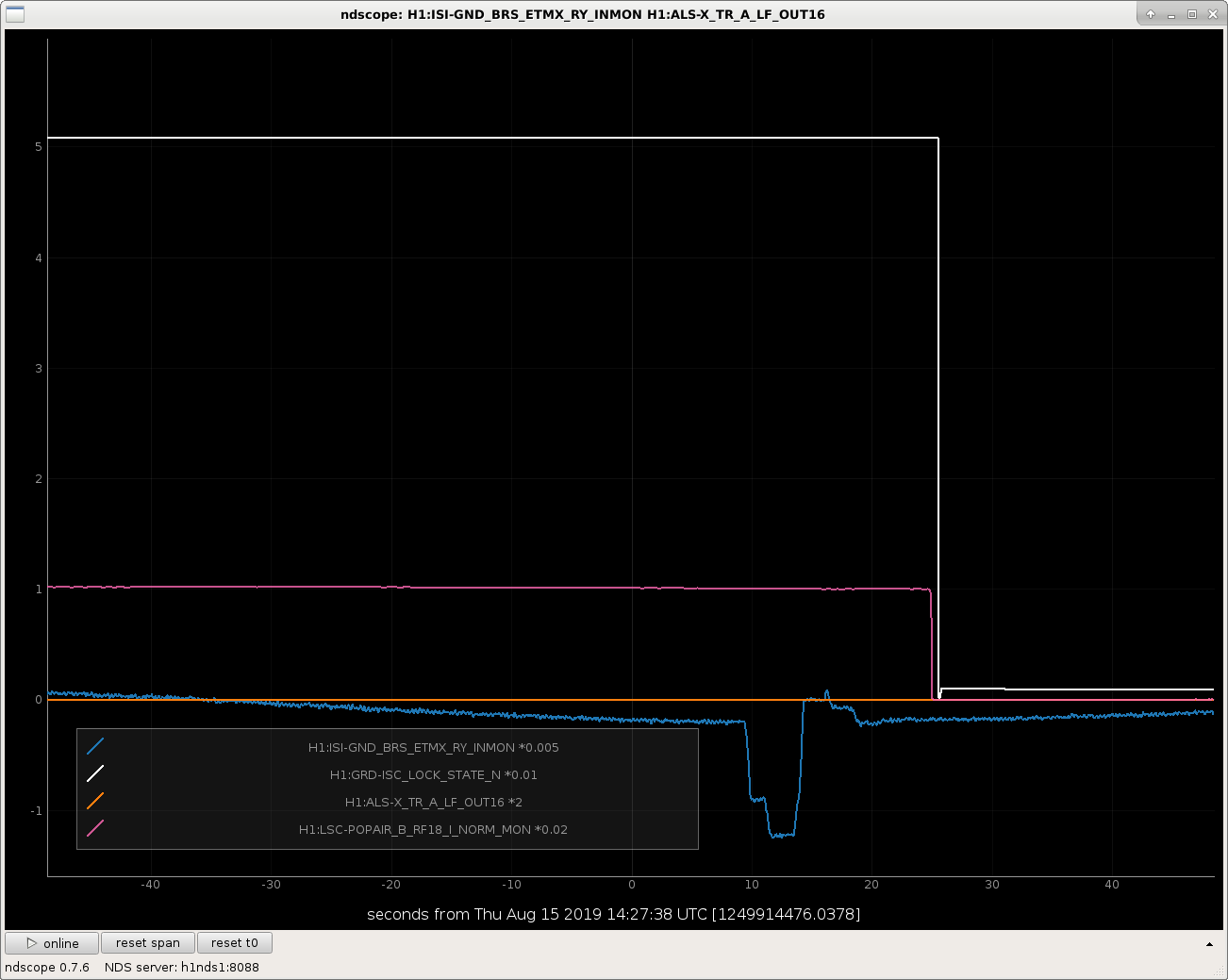
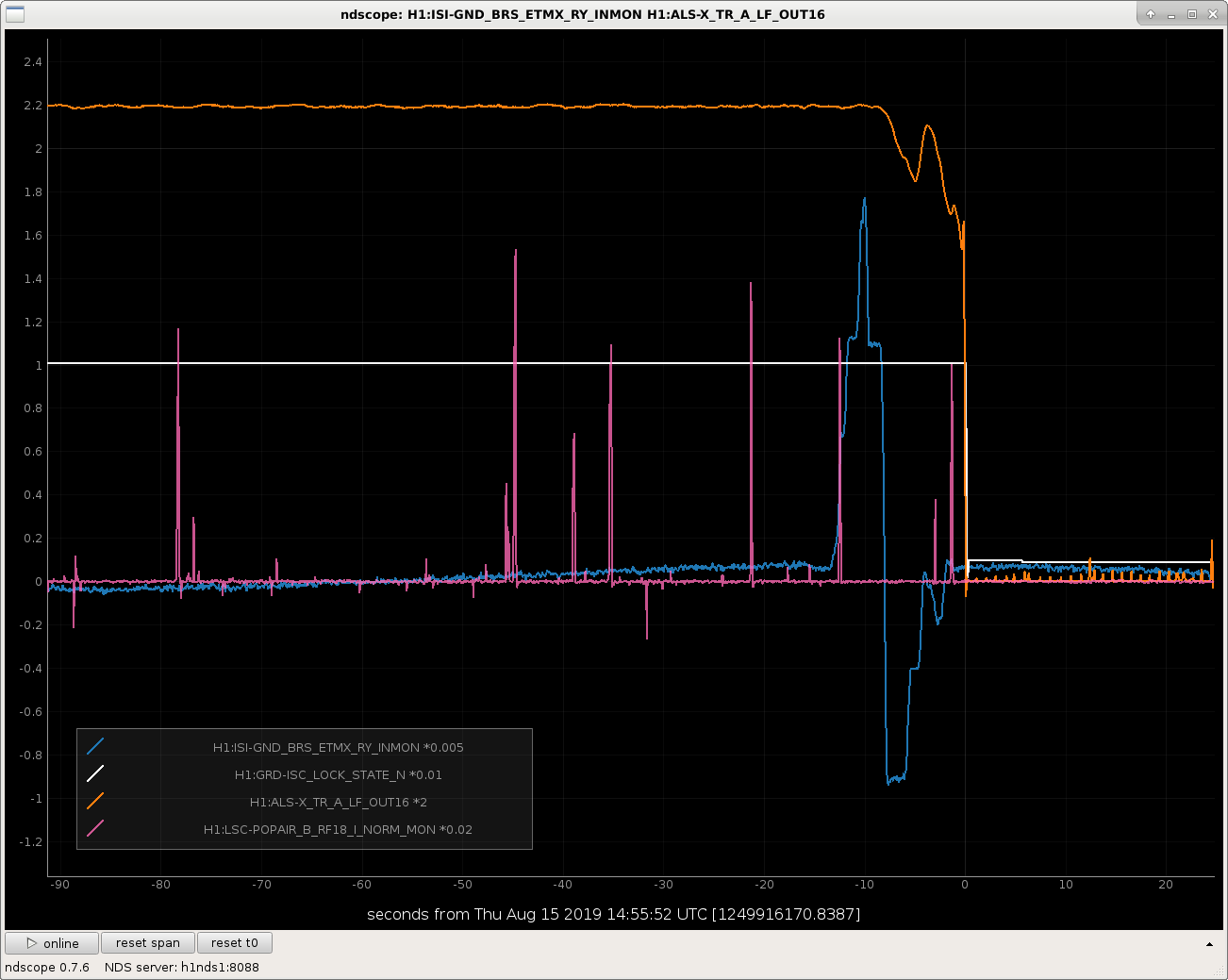
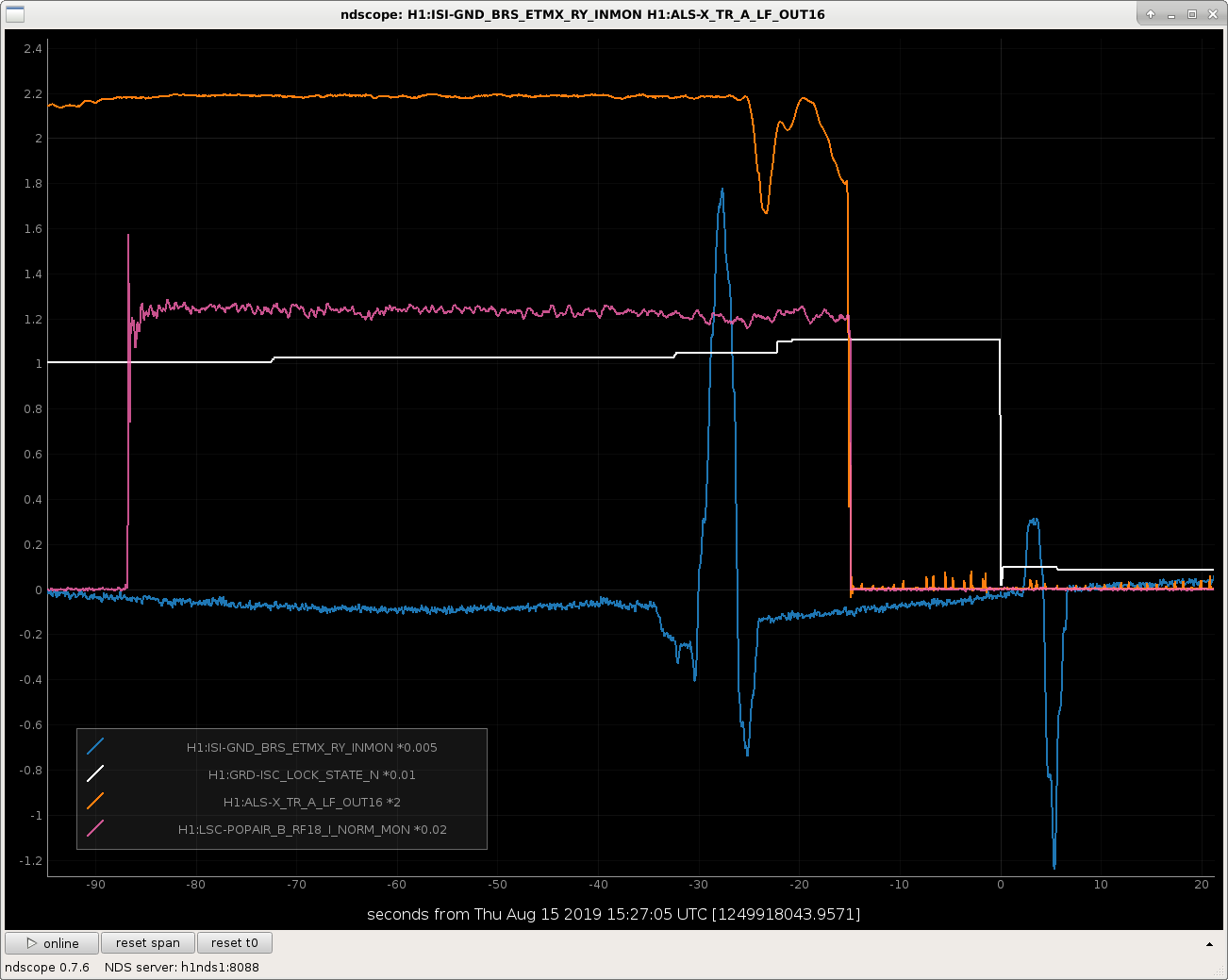
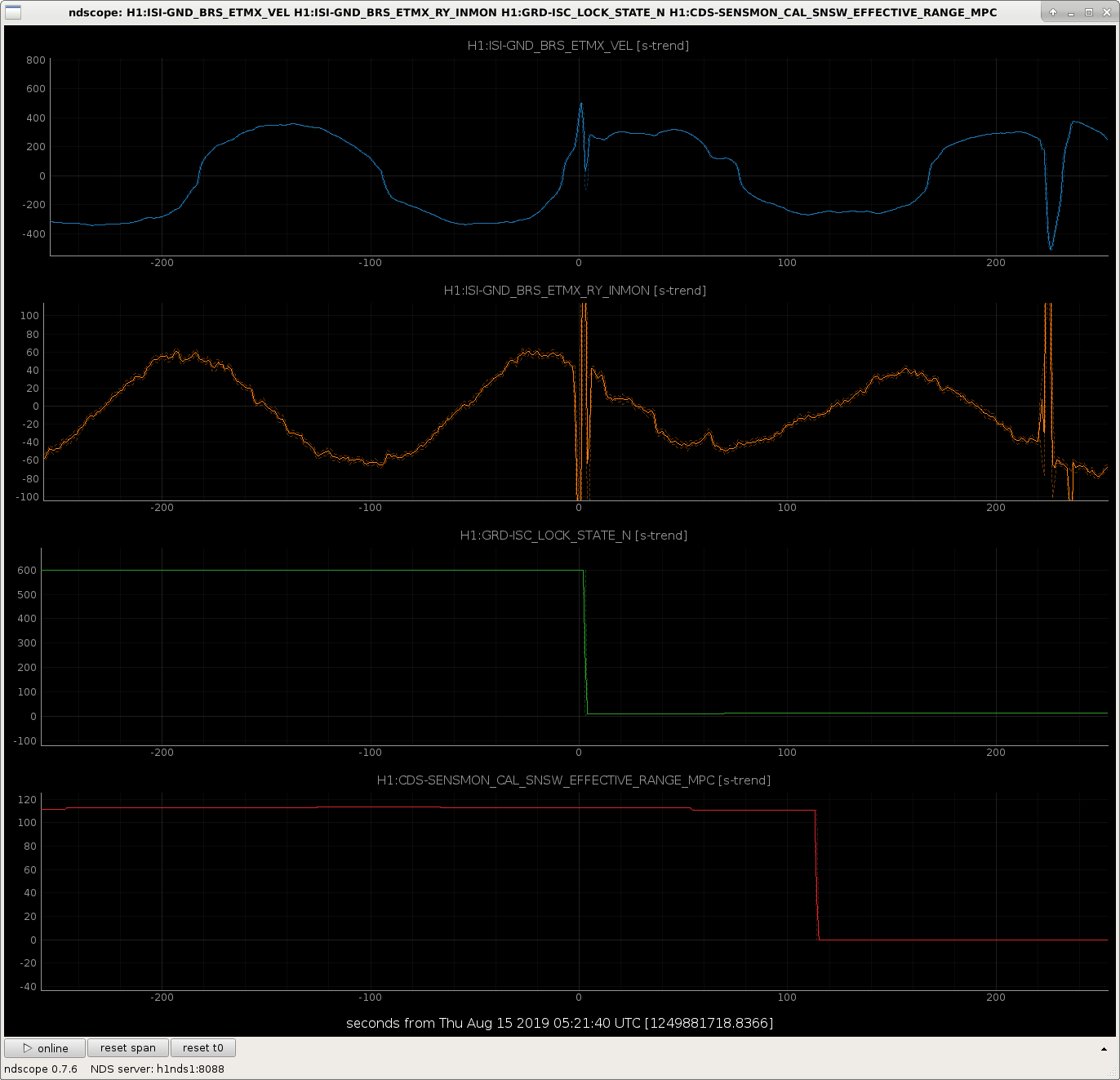
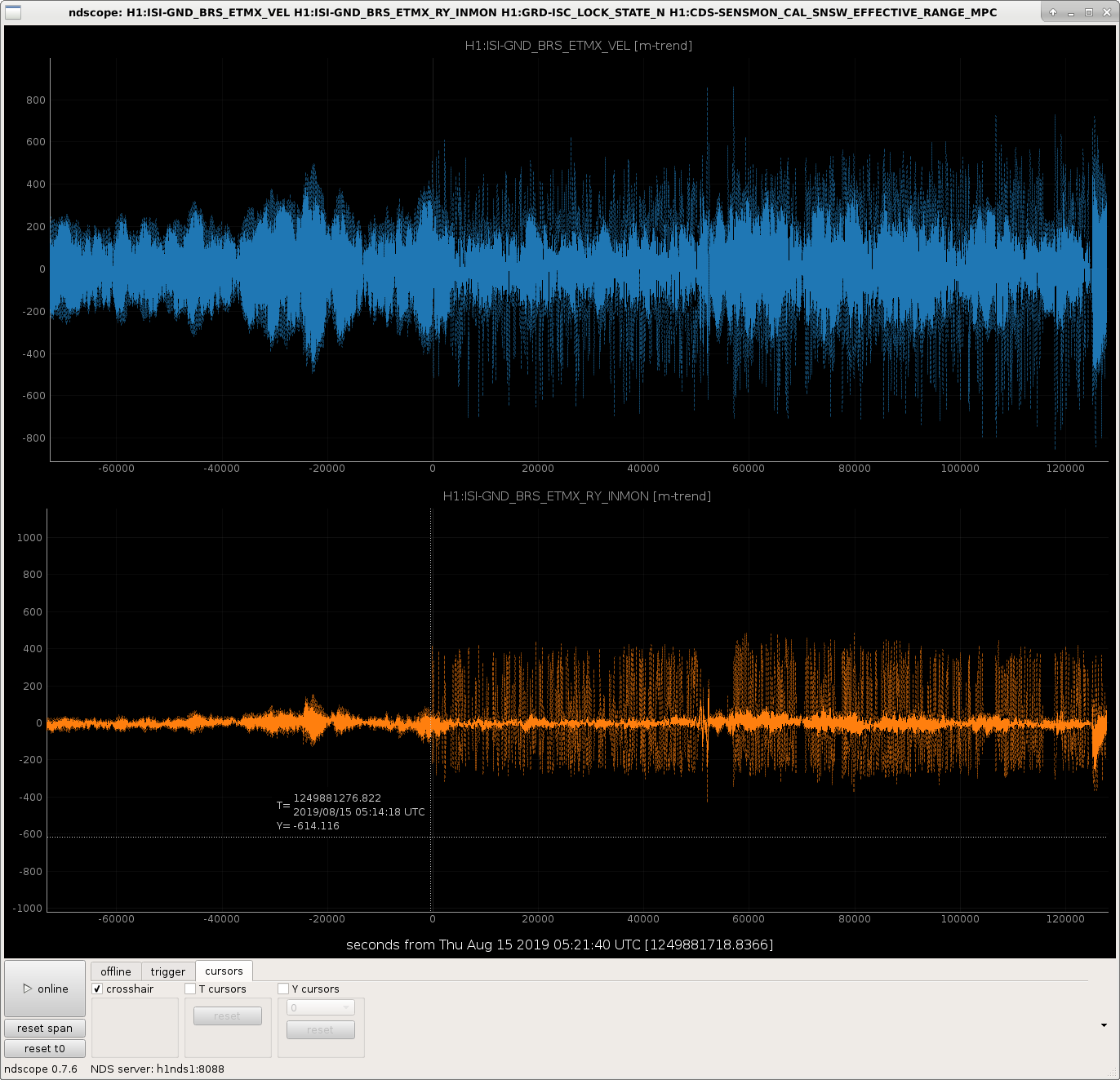
I attach some examples of lock losses related to the BRS glitching at various points in the IFO lock acquisition sequence.
I've scaled all the signals in such a way that they're clearly all visible on the plot, so the units (they all started out as counts anyways) are meaningless, but I've divided the guardian state by an even 100, so one can see the major acquisition steps as
6 = NOMINAL LOW NOISE,
5 = DC READOUT (Fully Resonant on Red, All FULL IFO ASC Engaged at 2W, ALS Not in Use),
~4.3 = PREP_ASC_FOR_FULL_IFO (Fully Resonant on Red at 2W, only some critical Full IFO ASC on [e.g. DHARD WFS], ALS no longer in use)
~1 = DRMI either locking or locked (ALS in use to park arms off red resonance)
~0.15 = Locking Green Arms, ALS and finding red resonance
I've also put the state at which the IFO lost lock in the screen cap's file name.
It's not a complete list of locklosses due the BRS glitching, and it's no where near a plot of all the channels that are needed to show exact what went wrong, but after scanning this trend of a few channels, you can get a feel that when the BRSX glitches, it moves the ISI, which blows locks either because
- it's too much for ALSX to handle (the arm power drops) and thus all of ALS fails whenever it's in use -- even through the acquisition of DRMI and a bit in to the CARM reduction
- OR it blows the lock when we're in full resonance and the Full IFO red ASC can't handle the jolt.
Without spending days trying to come up with a quantitative estimate of the observation time lost (OTL) by, for example,
- finding ratios of time spent commissioning other problems,
- accounting for whether we include things like initial alignment and going through the normal lock acquisition sequence
- finding the consistent sequence of events and then finding every lockloss that was directly attributed to it
I'll just use my educated guess based on all of the trends I browsed through to say the OTL is something like 70% of time that we were actively trying to lock and understand what was going wrong, and 90% of the time when it was just operators here. That's roughly 5 eight hour shifts since late Wednesday Night 8/14 -- in which 2-3 of them we were actively trying to commission other things -- puts us at
( 2.5 active commissioning shifts ) (0.7) + (2.5 inactive operating shifts) (0.9)
( 20 ) (0.7) + ( 20 ) (0.9) = 32 hours
so let's mark the Observation Time Lost at 30 hours and call it good.
I think the biggest lesson learned is that we need to somehow make the sensor correction system's health more obviously findable, since it took us a few days to figure out that the BRSX was glitching.