At 05:11 UTC the IFO dropped out of observing when the LASER_PWR guardian node went into error. At the same time the centroid calculations for at least two of the digital video cameras froze (see attached) and the EDCU lost connection to ~357 PSL channels. The following is from the log of the LASER_PWR guardian. 2019-11-30_05:11:19.568166Z CA.Client.Exception............................................... 2019-11-30_05:11:19.568166Z Warning: "Virtual circuit unresponsive" 2019-11-30_05:11:19.568166Z Context: "h1pslctrl0.cds.ligo-wa.caltech.edu:5064" 2019-11-30_05:11:19.568166Z Source File: ../tcpiiu.cpp line 947 2019-11-30_05:11:19.568166Z Current Time: Fri Nov 29 2019 21:11:19.567809882 2019-11-30_05:11:19.568166Z .................................................................. 2019-11-30_05:11:19.580550Z LASER_PWR [POWER_38W.run] USERMSG 0: CONNECTION ERRORS. see SPM DIFFS for dead channels 2019-11-30_05:11:19.648744Z LASER_PWR EZCA CONNECTION ERROR. attempting to reestablish... 2019-11-30_05:11:19.649386Z LASER_PWR CERROR: State method raised an EzcaConnectionError exception. 2019-11-30_05:11:19.649386Z LASER_PWR CERROR: Current state method will be rerun until the connection error clears. 2019-11-30_05:11:19.649386Z LASER_PWR CERROR: If CERROR does not clear, try setting OP:STOP to kill worker, followed by OP:EXEC to resume. 2019-11-30_05:16:48.637175Z Unexpected problem with CA circuit to server "h1pslctrl0.cds.ligo-wa.caltech.edu:5064" was "Connection reset by peer" - disconnecting 2019-11-30_05:16:48.637662Z CA.Client.Exception............................................... 2019-11-30_05:16:48.637662Z Warning: "Virtual circuit disconnect" 2019-11-30_05:16:48.637662Z Context: "h1pslctrl0.cds.ligo-wa.caltech.edu:5064" 2019-11-30_05:16:48.637662Z Source File: ../cac.cpp line 1223 2019-11-30_05:16:48.637662Z Current Time: Fri Nov 29 2019 21:16:48.637156550 2019-11-30_05:16:48.637662Z .................................................................. 2019-11-30_05:16:53.643095Z LASER_PWR connections reestablished

Opened FRS13893
Outage from 05:10:42 UTC to 05:16:38 UTC (21:10 - 21:16 PST).
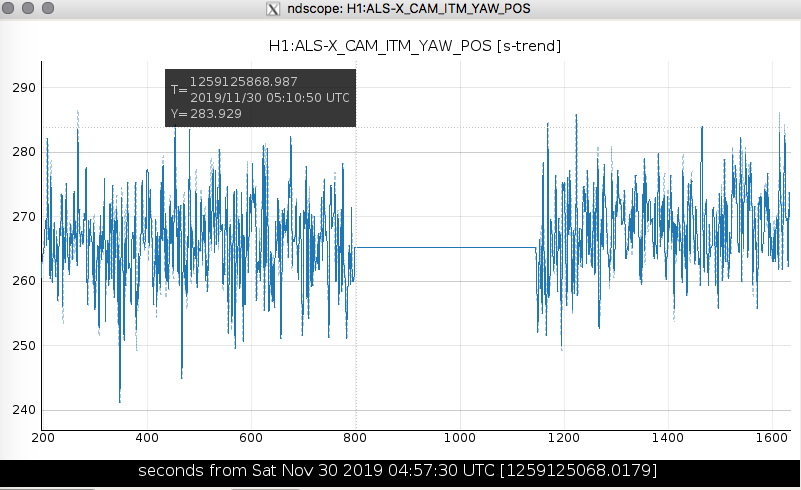
Evidence is now very strong that this was a freeze up of the Cisco network switch in the CER. This switch serves the PSL Diode Room (Beckhoff computer), the PSL LVEA enclosure Axis cameras and all the digital video cameras. All three systems exhibited a network error between 21:10 and 21:16. The digital video centroids are not directly trended by the DAQ, but some are copied to the end station and the received data shows the freeze (see plot).
Keita, Patrick, Dave:
What to do if this happens again and does not come back after 6 minutes.
The big question is if this were to happen again, with the PSL network down, H1 locked out of OBSERVE and the network not quickly coming back. Keita has agreed that we can make a guardian execption to remove the PSL Diode IOC from the OBSERVE veto and clear any associated SDFs. Patrick is looking at the code to see how that can be achieved. This will only be used it the network is down for at least 30 mins.
In the case of another network outage lasting more than 10 minutes I would like the operator to:
1) try to ping the switch (ping sw-lvea-aux) to see if it is running.
2) go into the CER and take a photograph of the switch, seeing if its error LEDs are lit. The switch is the Cisco with the WAP ethernet port. Only do this if it can be done safely (e.g. using LLO ops for budy).
I think we would need to add "LASER_PWR" to the EXCLUDE_NODES list in /opt/rtcds/userapps/release/sys/h1/guardian/IFO_NODE_LIST.py and reload the IFO node. The IFO node can be accessed from the 'GRD IFO' button at the very top left of the GUARD_OVERVIEW medm screen.
If the LASER_PWR node is in error, then ISC_LOCK will not have its OKAY channel as True since ISC_LOCK manages LASER_PWR. I don't think that then placing ISC_LOCK on the exclude list is a good idea.