WP11210 h1hwinj1 configuration and reboot test
Keith R, Keith T, Erik, Dave:
We have put h1hwinj1 under puppet configuration control. Monit is being used to monitor the status of psinject (CW hardware injector), and will restart it if it is missing. Systemd is used to start/stop the processes, via scripts which ramp the GAIN of the CAL_INJ_CW_EXC filter module over 10 seconds. To test the system works when h1h1inj1 is rebooted, this morning I rebooted using "systemctl reboot". Systemd correctly ramped the CW gain to zero before shutting down psinject. After the reboot monit started psinject correctly.
WP11211 Replace failing ADC h1seih16
Fil, TJ, Jim, Erik, Dave:
Fil replaced the second ADC in h1seih16. It had been raising ADC errors with increasing frequency (lately several times per day).
Procedure was: Jim safed the system, Dave fenced from Dolphin, stopped the models and powered down the computer. Fil powered down the AI chassis, then removed the old ADC and installed the new. Fil powered the IO Chassis up, Dave powered the computer up, Fil then powered the AI chassis up.
| Old card (removed - faulty) | 110124-06 |
| New card (installed - good) | 211109-31 |
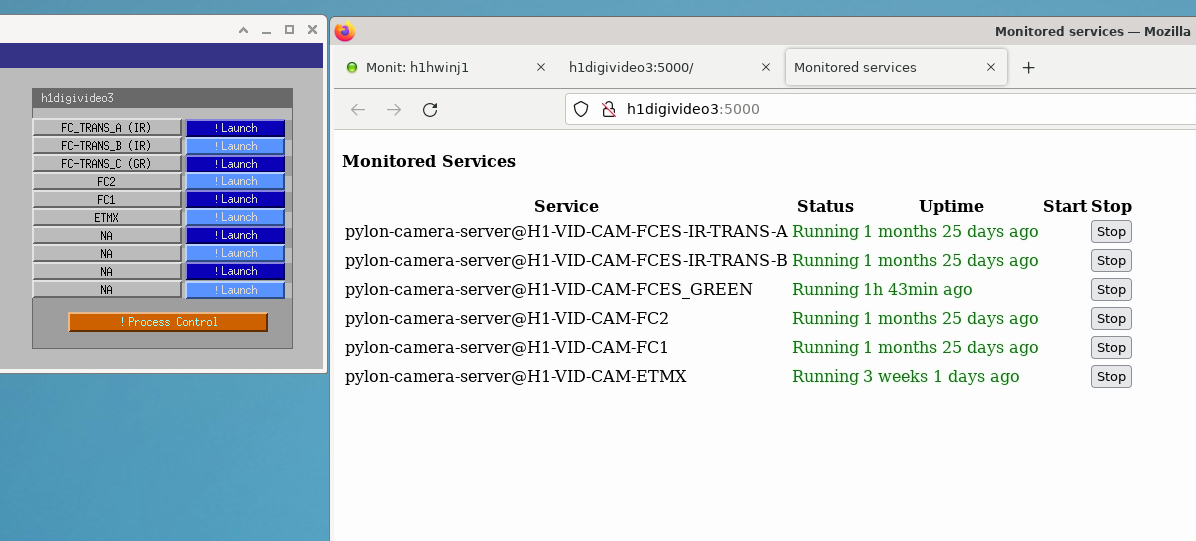
WP11205 Restart all digital video camera servers via monit web page
Jonathan, Patrick, Dave:
To test recent monit configuration changes, all the cameras on h1digivideo[0,1,2] were restarted using their monit web page controls.
Procedure was: open the camera image, via monit press the RESTART button, verify camera image goes blue-screen, then returns to original image.
Test was successful for all cameras on h1digivideo[0,1,2]
The camera control web page for the new camera servers on h1digivideo3 was added to the MEDM (see attachment). It was noted that the camera order on the web page did not match that on the MEDM, and that the STOP button did not work.
Jonathan made several fixes and improvements: Camera order matches, STOP/START buttons work, web page shows camera uptime (similar to monit web page).
WP11208 h1daqframes-0 ZPOOL Scrub
Dave:
I started a ZPOOL SCRUB on h1daqframes-0 at the start of maintenance. So far, so good. It is scheduled to complete early Sat.
scan: scrub in progress since Tue May 23 09:58:19 2023
18.7T scanned at 1.46G/s, 6.88T issued at 550M/s, 184T total
0B repaired, 3.75% done, 3 days 21:32:05 to go
WP11219 Replace Dolphin IX Adapter card h1cdsrfm
EJ, Erik, Jonathan, Dave, TJ, Jim, Jeff, Control Room:
Last night we had to reboot several corner station systems because h1cdsrfm glitched the corner Dolphin fabric when reporting a problem with the IX card installed in its local chassis (i.e. not in End Station Adnaco mini-chassis). This had happened before in August 2022. We elected to replace this card as preventative maintenance before O4.
Because the card's serial number had changed, the Dolphin network manager had to be restarted on h1vmboot1. Unfortunately, as seen before, this caused h1susex, h1susey, h1seiey and h1iscey to hard lockup, requiring IPMI resets to reboot them. These system had to be recovered from their reboots by CDS and OPS.
WP11193 Upgrade DC power supplies in CER
Marc, Fil, Dave:
Marc and Fil continued the DC power supply upgrades in the CER. This required the power down of h1omc0, h1asc0 and h1lsc0 front ends because their IO Chassis were powered down.
The procedure was: fence FE from Dolphin, stop all models, power down computer.
Prior to this I had installed the new h1ascsqzifo and h1sqz models, so then ASC and LSC came back they were running the new code.
WP11206 ADD ADS block to SQZ
Daniel, Vicky, Dave:
New h1ascsqzifo and h1sqz models were installed on h1asc0 and h1lsc0 respectively. DAQ restart was required to add slow channels.
DAQ Restart
Dave:
The DAQ was restarted because of the sqz model changes detailed above.
fw0 restarted itself after running 6 minutes. We think this was a "standard" fw0 restart and not because of the ongoing scrub.
Both gds0 and gds1 needed restarts, this appears to be modus operandi these days.
For context and consequences of the WP11219 Replace Dolphin IX Adapter card h1cdsrfm replacement: Prep for potential Y-end station front end crashing: LHO:69826. Report of crash: LHO:69832 SDF system loop hole that this reboot exposed with the ISI system: LHO:69835
Tue23May2023
LOC TIME HOSTNAME MODEL/REBOOT
08:33:32 h1seih16 ***REBOOT*** <<< replace 2nd ADC
08:35:03 h1seih16 h1iopseih16
08:35:16 h1seih16 h1hpiham1
08:35:29 h1seih16 h1hpiham6
08:35:42 h1seih16 h1isiham6
11:13:36 h1asc0 ***REBOOT*** <<< IO Chassis power supply work
11:13:57 h1lsc0 ***REBOOT***
11:15:11 h1asc0 h1iopasc0
11:15:24 h1asc0 h1asc
11:15:33 h1lsc0 h1ioplsc0
11:15:37 h1asc0 h1ascimc
11:15:42 h1omc0 ***REBOOT***
11:15:46 h1lsc0 h1lsc
11:15:50 h1asc0 h1ascsqzifo <<< New model
11:15:59 h1lsc0 h1lscaux
11:16:12 h1lsc0 h1sqz <<< New model
11:16:25 h1lsc0 h1ascsqzfc
11:17:09 h1omc0 h1iopomc0
11:17:22 h1omc0 h1omc
11:17:35 h1omc0 h1omcpi
11:24:24 h1daqdc0 [DAQ] <<< DAQ-0 Restart for models
11:24:35 h1daqfw0 [DAQ]
11:24:35 h1daqtw0 [DAQ]
11:24:36 h1daqnds0 [DAQ]
11:24:44 h1daqgds0 [DAQ]
11:25:14 h1daqgds0 [DAQ] <<< 2nd GDS0
11:26:08 h1cdsrfm ***REBOOT*** <<< cdsrfm Dolphin card replacement
11:29:59 h1daqfw0 [DAQ] <<< FW0 restarted itself
11:37:16 h1susey ***REBOOT*** <<< Endstation recovery following Dolphin crash
11:37:59 h1seiey ***REBOOT***
11:38:15 h1susex ***REBOOT***
11:38:40 h1iscey ***REBOOT***
11:39:20 h1susey h1iopsusey
11:39:33 h1seiey h1iopseiey
11:39:33 h1susey h1susetmy
11:39:46 h1seiey h1hpietmy
11:39:46 h1susey h1sustmsy
11:39:59 h1seiey h1isietmy
11:39:59 h1susey h1susetmypi
11:40:24 h1iscey h1iopiscey
11:40:25 h1susex h1iopsusex
11:40:37 h1iscey h1pemey
11:40:38 h1susex h1susetmx
11:40:50 h1iscey h1iscey
11:40:51 h1susex h1sustmsx
11:41:03 h1iscey h1caley
11:41:04 h1susex h1susetmxpi
11:41:16 h1iscey h1alsey
11:43:31 h1daqdc1 [DAQ] <<< DAQ-1 restart for models
11:43:39 h1daqfw1 [DAQ]
11:43:39 h1daqtw1 [DAQ]
11:43:41 h1daqnds1 [DAQ]
11:43:49 h1daqgds1 [DAQ]
11:44:52 h1daqgds1 [DAQ] <<< 2nd GDS1 restart
202 slow channels add the DAQ frame, full list in attached file

We should look at mitigations for the end-station crash. There are at least two that we could try: * turning off the node-manager process on the end station machines * disabling the dolphin switch ports for the end station machines We should try one or both of these next time we do something.