louis.dartez@LIGO.ORG - posted 11:16, Thursday 26 September 2024 - last comment - 10:18, Monday 25 August 2025(80291)
Procedural issues in LHO Calibration this week
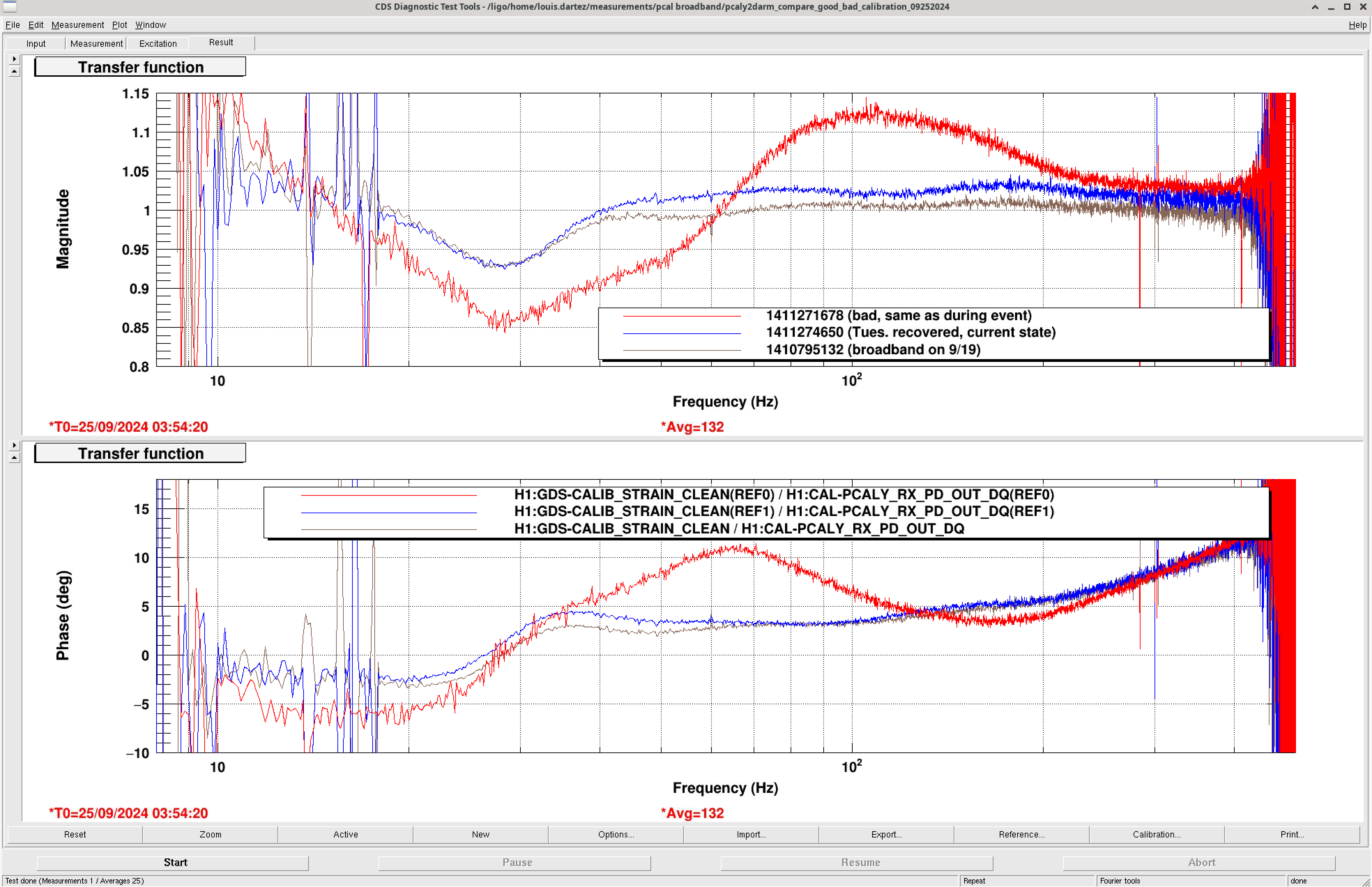
In the past few weeks have seen rocky performance out of the Calibration pipeline and its IFO-tracking capabilities. Much, but not all, of this is due to [my] user error. Tuesday's bad calibration state is a result of my mishandling of the recent drivealign L2L gain changes for the ETMX TST stage (LHO:78403, LHO:78425, LHO:78555, LHO:79841). The current practice adopted by LHO with respect to these gain changes is the following: 1. Identify that KAPPA_TST has drifted from 1 by some appreciable amount (1.5-3%), presumably due to ESD charging effects. 2. Calculate the necessary DRIVEALIGN gain adjustment to cancel out the change in ESD actuation strength. This is done in the DRIVEALIGN bank so that it's downstream enough to only affect the control signal being sent to the ESD. It's also placed downstream of the calibration TST excitation point. 3. Adjust the DRIVEALIGN gain by the calculated amount (if kappaTST has drifted +1% then this would correspond to a -1% change in the DRIVEALIGN gain). 3a. Do not propagate the new drivealign gain to CAL-CS. 3b. Do not propagate the new drivealign gain to the pyDARM ini model. After step 3 above it should be as if the IFO is back to the state it was in when the last calibration update took place. I.e. no ESD charging has taken place (since it's being canceled out by the DRIVEALIGN gain adjustments). It's also worth noting that after these adjustments the SUS-ETMX drivealign gain and the CAL-CS ETMX drivealign will no longer be the copies of each other (see image below). The reasoning behind 3a and 3b above is that by using these adjustments to counteract IFO changes (in this case ESD drift) from when it was last calibrated, operators and commissioners in the control room could comfortably take care of performing these changes without having to invoke the entire calibration pipeline. The other approach, adopted by LLO, is to propagate the gain changes to both CAL-CS and pyDARM each time it is done and follow up with a fresh calibration push. This approach leaves less to 'be remembered' as CAL-CS, SUS, and pyDARM will always be in sync but comes at the cost of having to turn a larger crank each time there is a change.Somewhere along the way I updated the TST drivealign gain parameter in the pyDARM model even though I shouldn't have. At this point, I don't recall if I was confused because the two sites operate differently or if I was just running a test and left this parameter changed in the model template file by accident and subsequently forgot about it. In any case, the drivealign gain parameter change made its way through along with the actuation delay adjustments I made to compensate for both the new ETMX DACs and for residual phase delays that haven't been properly compensated for recently (LHO:80270). This happened in commit 0e8fad of the H1 ifo repo. I should have caught this when inspecting the diff before pushing the commit but I didn't. I have since reverted this change (H1 ifo commit 41c516). During the maintenance period on Tuesday, I took advantage of the fact that the IFO was down to update the calibration pipeline to account for all of the residual delays in the actuation path we hadn't been properly compensating for (LHO:80270). This is something that I've done several times before; a combination of the fact that the calibration pipeline has been working so well in O4 and that the phase delay changes I was instituting were minor contributed to my expectation that we would come back online to a better calibrated instrument. This was wrong. What I'd actually done was install a calibration configuration in which the CAL-CS drivealign gain and the pyDARM model's drivealign gain parameter were different. This is bad because pyDARM generates FIR filters that are used by the downstream GDS pipeline; those filters are embedded with knowledge of what's in CAL-CS by way of the parameters in the model file. In short, CAL-CS was doing one thing and GDS was correcting for another. -- Where do we stand? At the next available opportunity, we will be taking another calibration measurement suite and using it reset the calibration one more time now that we know what went wrong and how to fix it. I've uploaded a comparison of a few broadband pcal measurements (image link). The blue curve is the current state of the calibration error. The red curve was the calibration state during the high profile event earlier this week. The brown curve is from last week's Thursday calibration measurement suite, taken as part of the regularly scheduled measurements. -- Moving forward, I and others in the Cal group will need to adhere more strictly to the procedures we've already had in place: 1. double check that any changes include only what we intend at each step 2. commit all changes to any report in place immediately and include a useful log message (we also need to fix our internal tools to handle the report git repos properly) 3. only update calibration while there is a thermalized ifo that can be used to confirm that things will back properly, or if done while IFO is down, require Cal group sign-off before going to observing
Images attached to this report
Comments related to this report
Posting here for historical reference.
The propagation of the correction of incorrect calibration was in an email thread between myself, Joseph Betzwieser, Aaron Zimmerman, Colm Talbot.
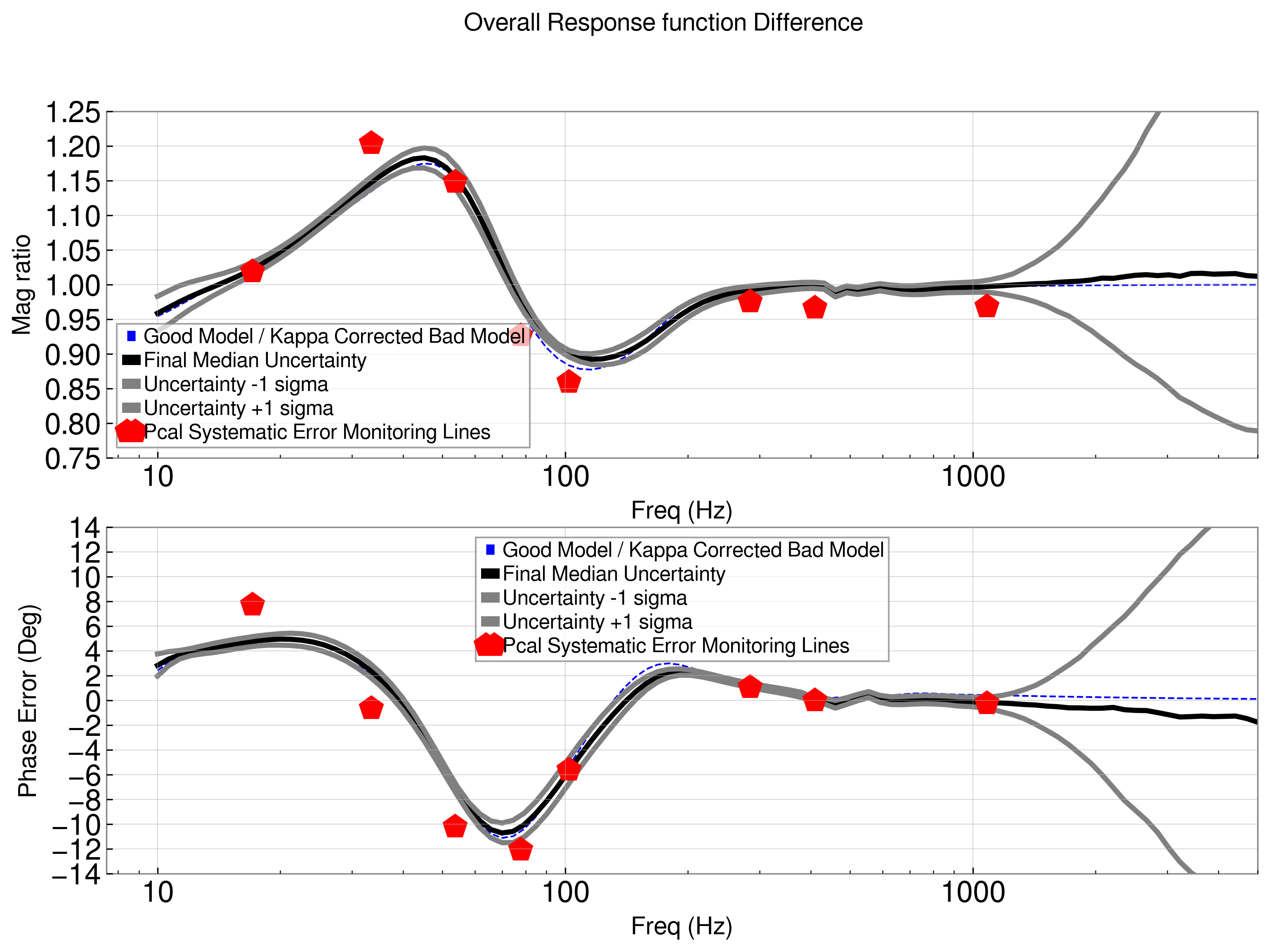
I had produced a calibration uncertainty with necessary correction that would account for the effects of this issue attached here as a text file, and as an image showing how it compares against our ideal model (blue dashed) and the readouts of the calibration monitoring lines at the time (red pentagons).
Ultimately the PE team used the inverse of what I post here, since as a result of this incident it was discovered that PE was ingesting uncertainly in an inverted fashion up to this point.
Images attached to this comment
Non-image files attached to this comment

I am also posting the original correction transfer function (the blue dashed line in Vlad's comment's plot) here from Vlad for completeness. It was created by calculating the modeled response of the interferometer that we intended to use at the time (R_corrected), over the response of the interferometer that was running live at the time (R_original) corrected for online correction (i.e. time dependent correction factors such as Kappa_C, Kappa_TST, etc). So to correct, one would take the calibrated data stream at the time: bad_h(t) = R_original (t) * DARM_error(t) and correct it via: corrected_h(t) = R_original(t) * DARM_error(t) * R_corrected / R_original(t)
Non-image files attached to this comment
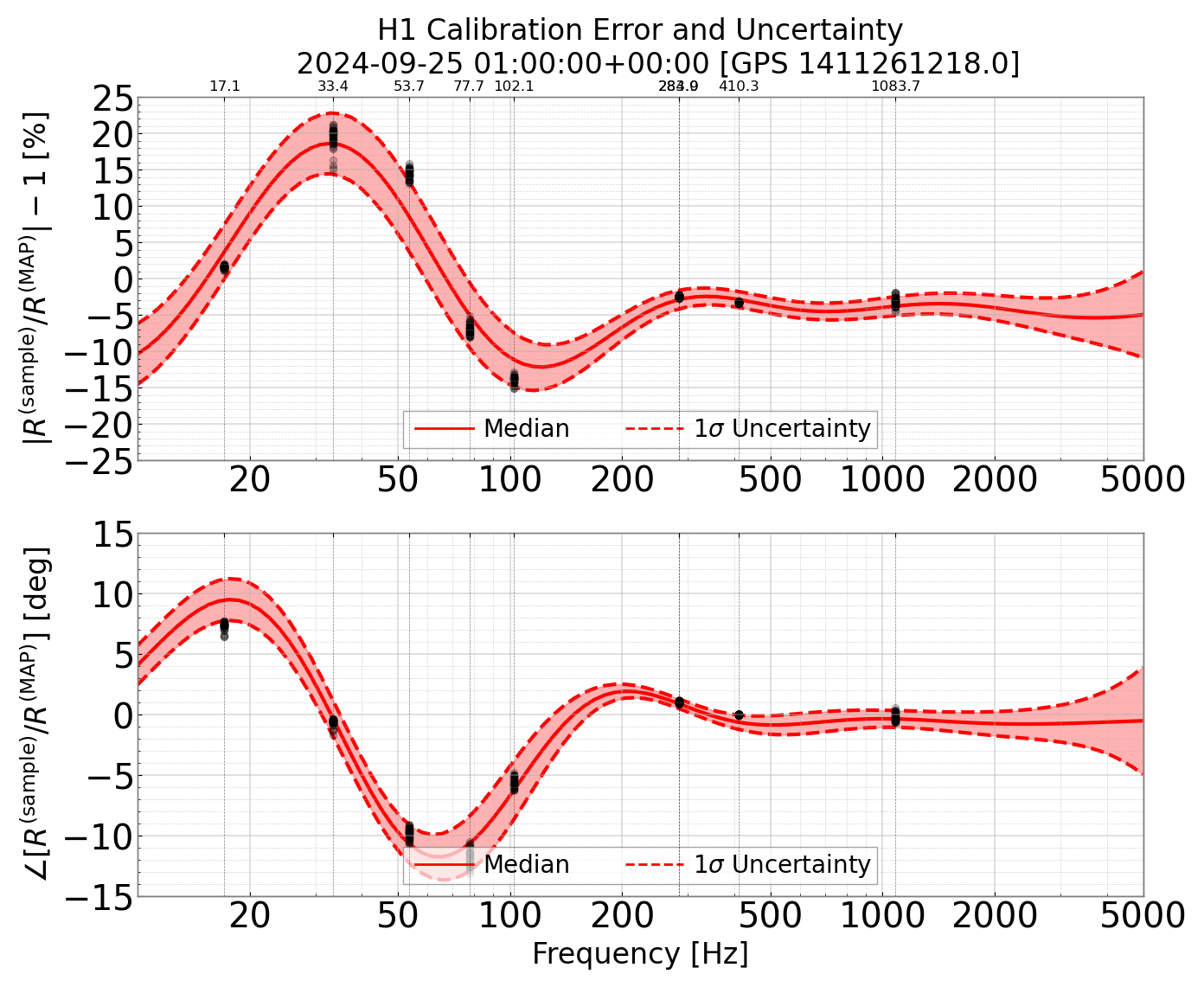
So our understanding of what was wrong with the calibration around September 25th, 2024 00:00 UTC has improved significantly since then. We had 4 issues in total. 1) The above mentioned drivealign gain mismatch issue between model, h1calcs, the interferometer and GDS calibration pipeline. 2) The ETMX L1 stage rolloff change that was not in our model (see LHO alog 82804) 3) LHO was not applying the measured SRC detuning to the front end calibration pipeline - we started pushing it in February 2025 (see LHO alog 83088). 4) The fact that pydarm doesn't automatically hit the load filters button for newly updated filters means sometimes humans forget to push that button (see for example LHO alog 85974). Turns out that night the optical gain filter in the H1:CAL-DARM_ERR filter bank had not been updated. Oddly enough, the cavity pole frequency filter bank had been updated, but I'm guessing the individual load button was pressed In the filter archive (/opt/rtcds/lho/h1/chans/filter_archive/h1calcs/), specifically H1CALCS_1411242933.txt has an inverse optical gain filter of 2.9083e-07, which is the same value as the previous file's gain. However, the model optical gains did change (3438377 in the 20240330T211519Z report, and 3554208 in the bad report that was pushed, 20240919T153719Z). The epics for the kappa generation were updated, so we had a mismatch between the kappa_C value that was calculated, and to what optical gain it applied - similar to the actuation issue we had. It should have changed by a factor of 0.9674 (3554208/3438377). This resulted in the monitoring lines showing ~3.5% error at the 410.3 Hz line during this bad calibration period. It also explains why there's a mistmatch between monitoring lines and the correction TFs we provided that night at high frequency. Normally the ratio between PCAL and GDS is 1.0 at 410.3 Hz since the PCAL line itself is used to calculated kappa_C at that frequency and thus matches the sensing at that frequency to the line. See the grafana calibration monitoring line page. I've combined all this information to create an improved TF correction factor and uncertainty plot, as well as more normal calibration uncertainty budgets. So the "calibration_uncertainty_H1_1411261218.png" is a normal uncertainty budget plot, with a correction TF from the above fixes applied. The "calibration_uncertainty_H1_1411261218.txt" is the associated text file with the same data. "H1_uncertainty_systematic_correction.txt" is the TF correction factor that I applied, calculated with the above fixes. Lastly, "H1_uncertainty_systematic_correction_sensing_L1rolloff_drivealign.pdf", is the same style plot Vlad made earlier, again with the above fixes. I'll note the calibration uncertainty plot and text file was created on the LHO cluster, with /home/cal/conda/pydarm conda environment, using command: IFO=H1 INFLUX_USERNAME=lhocalib INFLUX_PASSWORD=calibrator CAL_ROOT=/home/cal/archive/H1/ CAL_DATA_ROOT=/home/cal/svncommon/aligocalibration/trunk/ python3 -m pydarm uncertainty 1411261218 -o ~/public_html/O4b/GW240925C00/ --scald-config ~cal/monitoring/scald_config.yml -s 1234 -c /home/joseph.betzwieser/H1_uncertainty_systematic_correction.txt I had to modify the code slightly to expand out the plotting range - it was much larger than the calibration group usually assumes. All these issues were fixed in the C01 version of the regenerated calibration frames.
Images attached to this comment
Non-image files attached to this comment
