Here is a summary of some results from the open loop gain measurements of DHARD Y and CHARD Y, and the implementation of a new CHARD P low pass:
DHARD Y
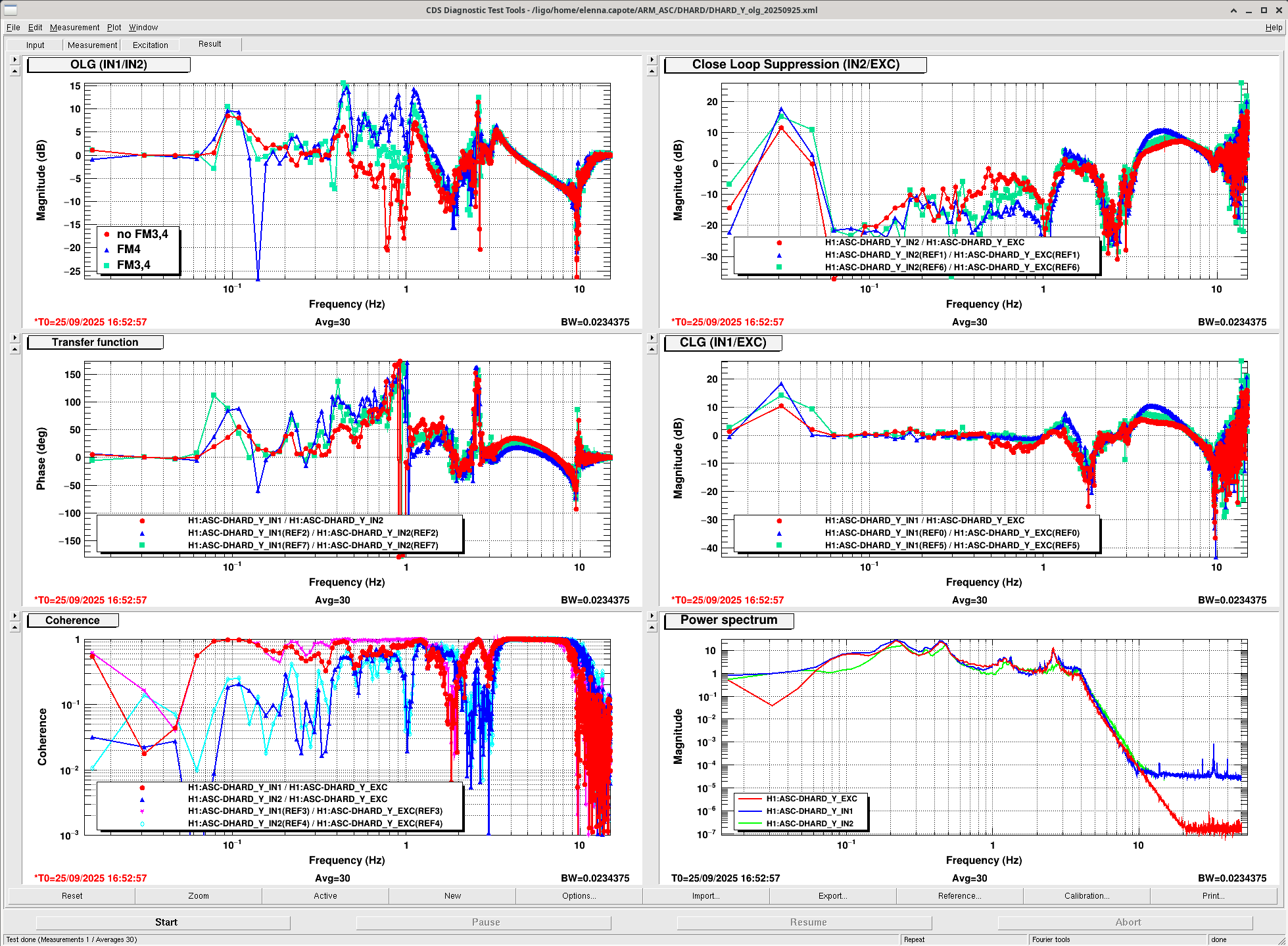
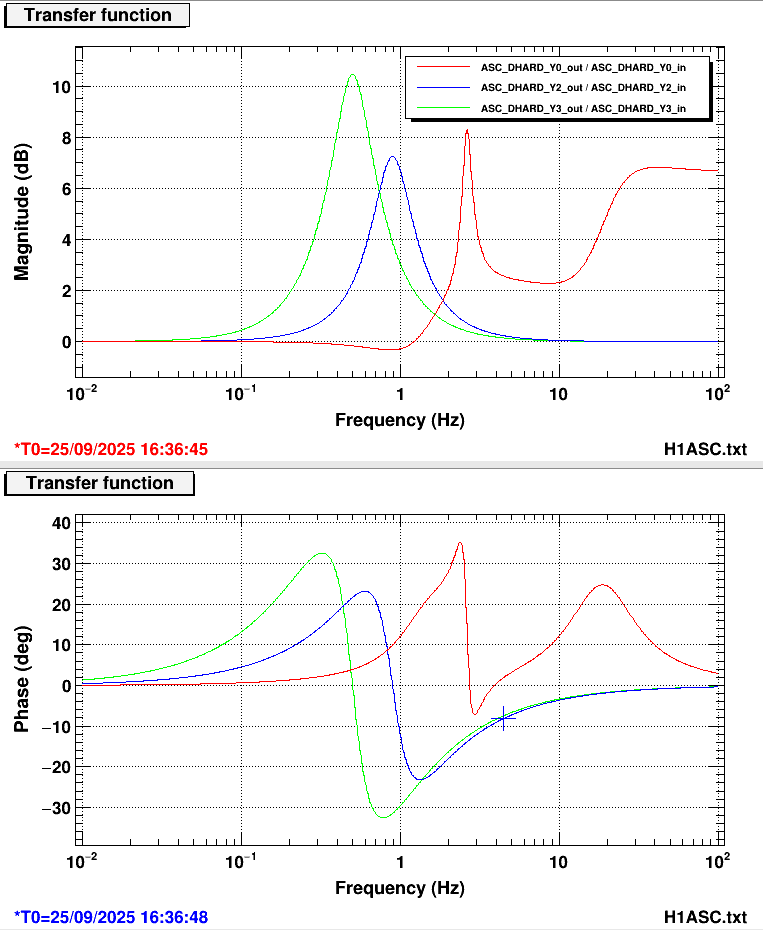
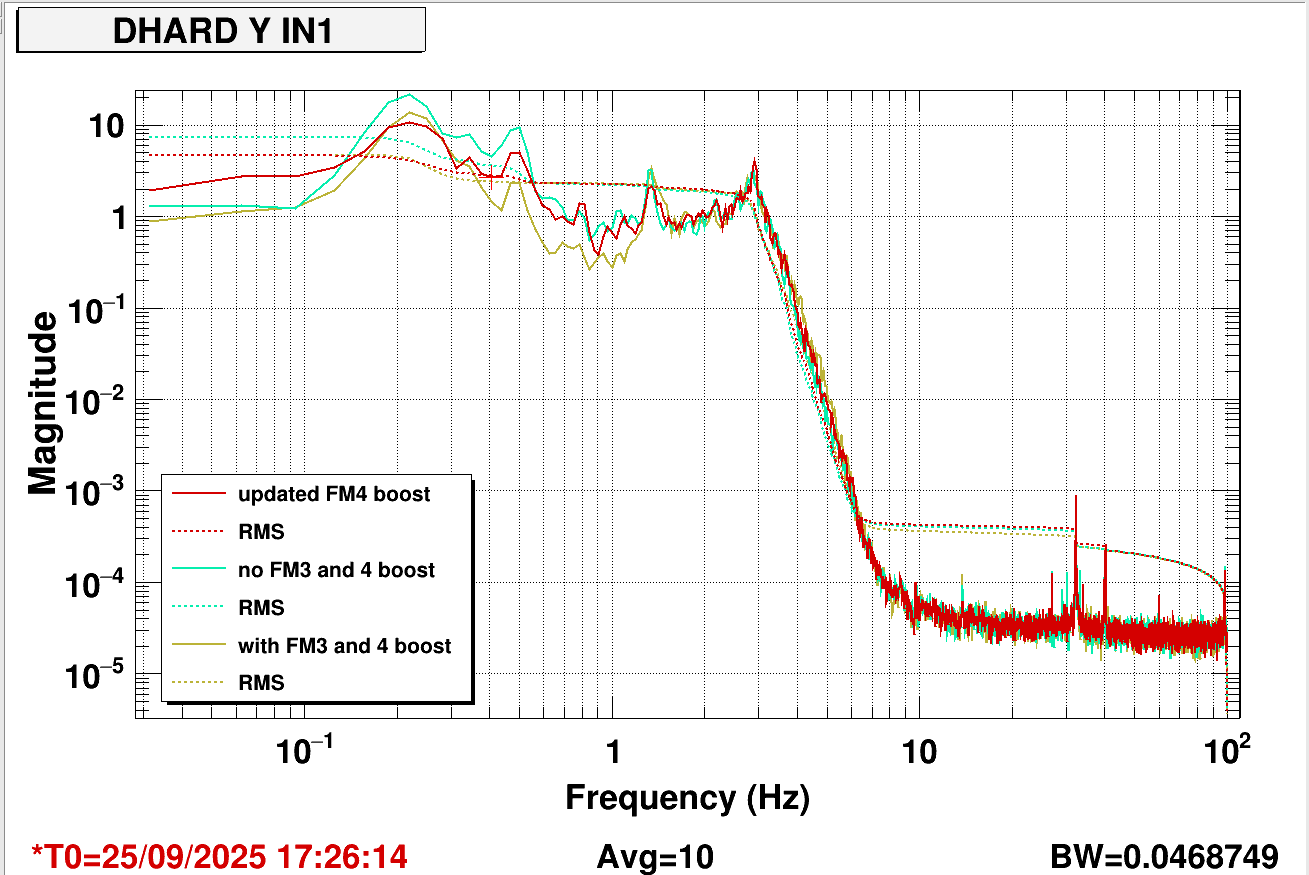
I measured the DHARD Y open loop gain, results shown here. The dark blue trace shows the original measurement, showing 17 degrees of phase margin and gain peaking of 10 dB. Looking at the loop design, there are three different boost filters applied to DHARD Y, compared here. These boosts in combination seem to be destroying all the phase of the loop. I took a measurement with the 0.9 Hz boost disengaged (FM3), which is shown in the green trace. Then, I disengaged the 0.5 Hz boost (FM4) and remeasured, shown in the red trace. This improved the phase margin to 32 degrees. This obviously resulted in less microseismic suppression. I adjusted the 0.5 Hz boost (FM4) and decided we should operate without the boost in FM3. This plot compares the original loop error signal and RMS with all three boosts (gold), the error signal and RMS without FM3 and FM4 boosts (green) and then error signal and RMS with the updated FM4 boost (red). The RMS increased 50% without both boosts on, the improved boost returns the RMS to that value. There is now more phase margin in the loop. Updated in guardian and ASC high gain script, SDFed (1,2).
CHARD Y
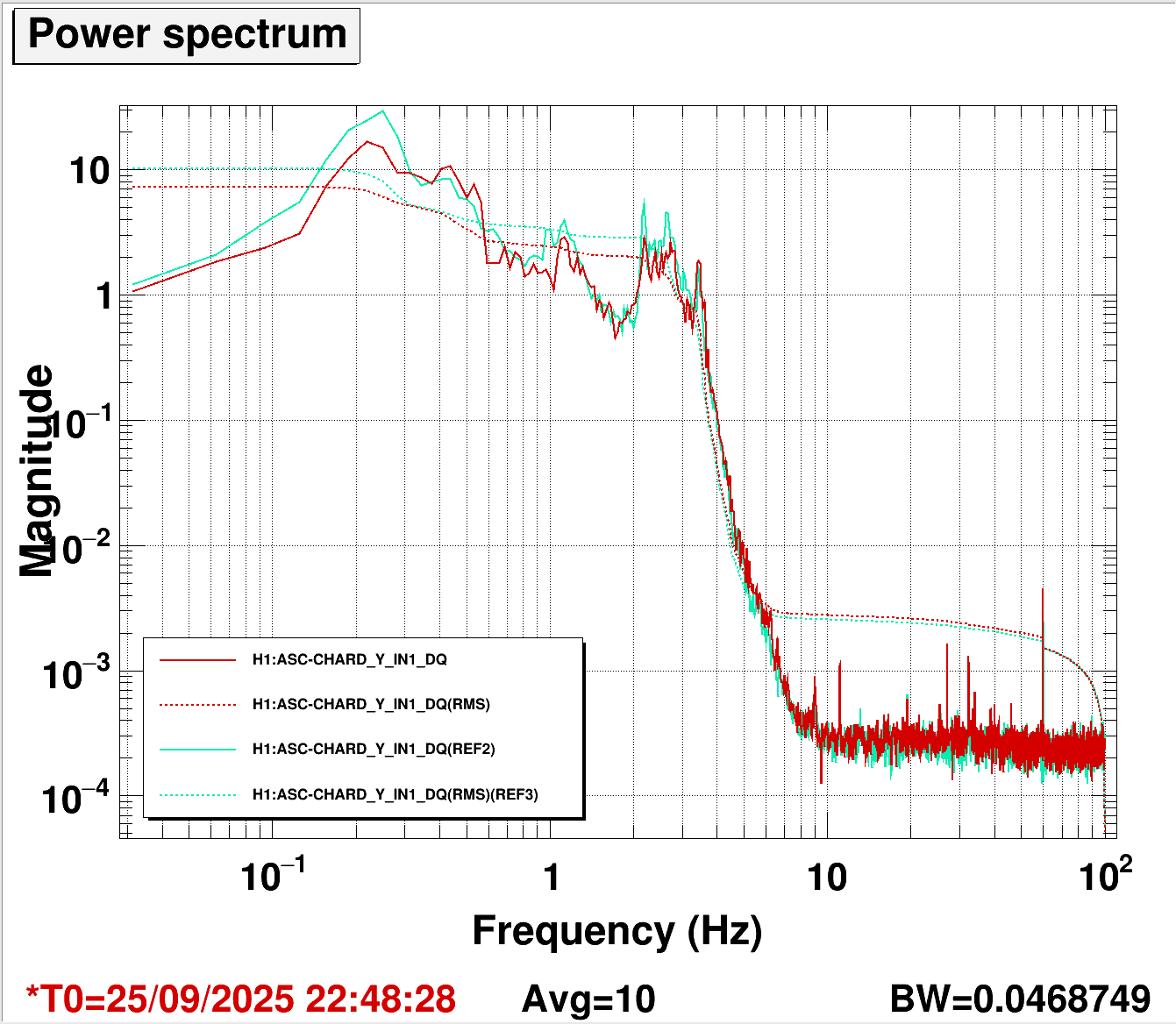
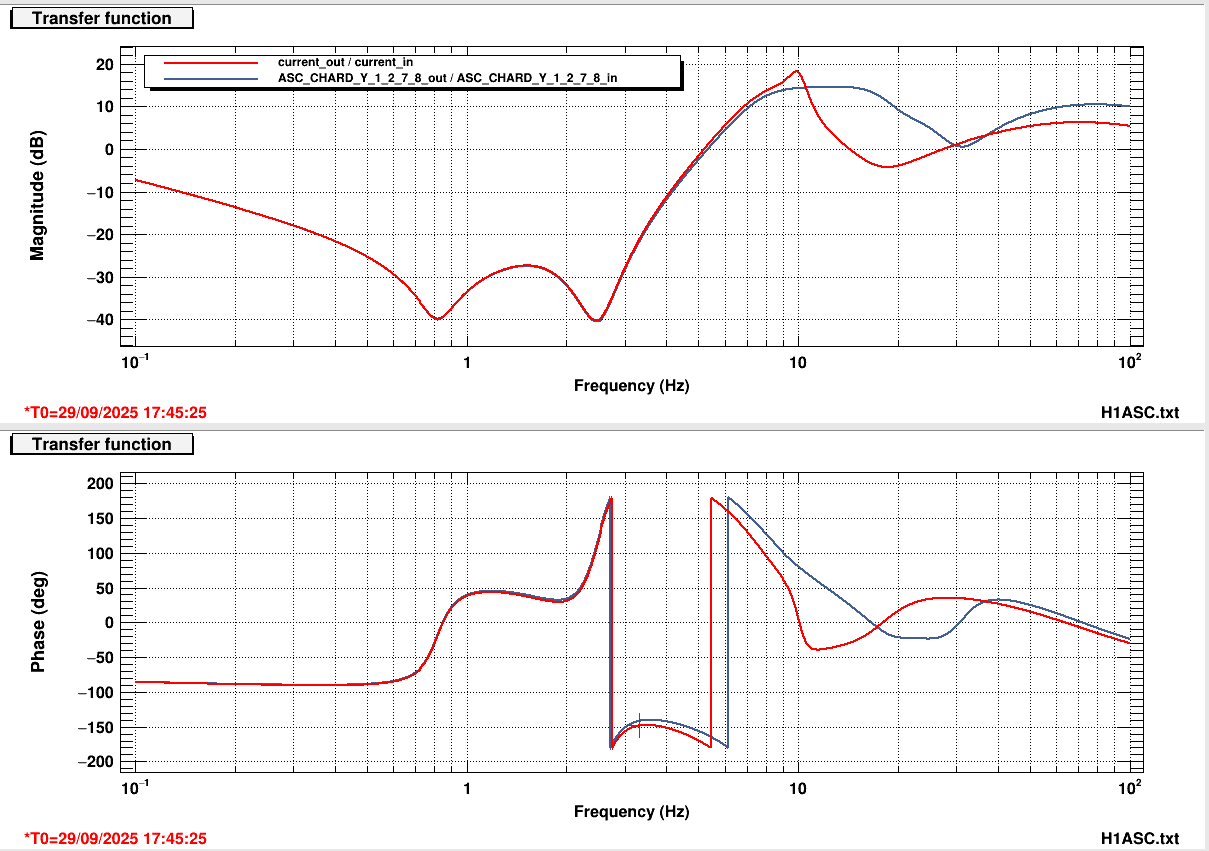
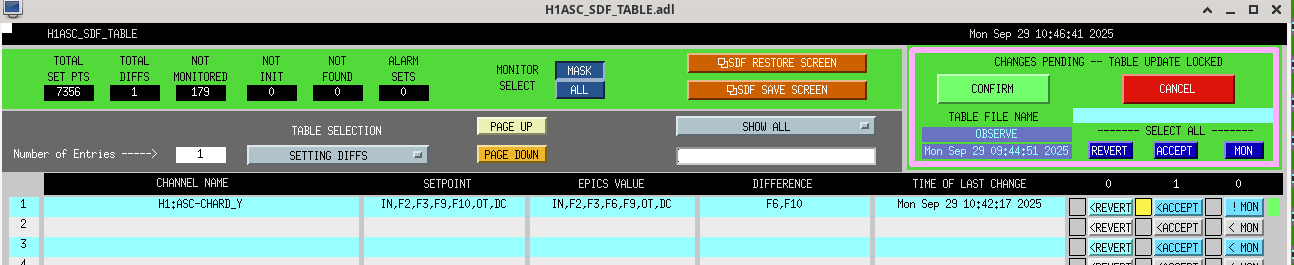
I measured the CHARD Y open loop gain, results shown here. The file had an old reference trace from 2023, shown in bluegreen in the reference. The gray trace shows the first measurement I made today of CHARD Y. The gain appeared to be way too low. I raised the gain to match the old reference, which was a gain increase of 6 dB. Here is a comparison of the RMS of CHARD Y from 14 hours ago (bluegreen reference) and now (red live). The microseism level is the same between these two measurements. Overall, this reduces the RMS of the loop, so I think this is a good adjustment. This is updated in the guardian and ASC high gain script, also SDFed.
CHARD P
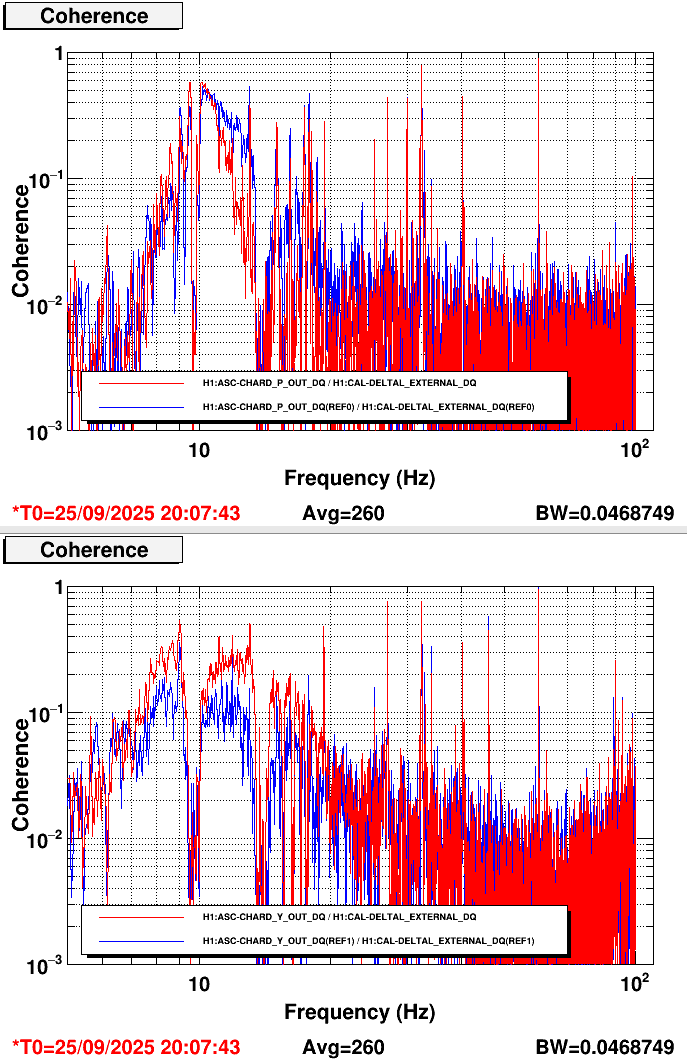
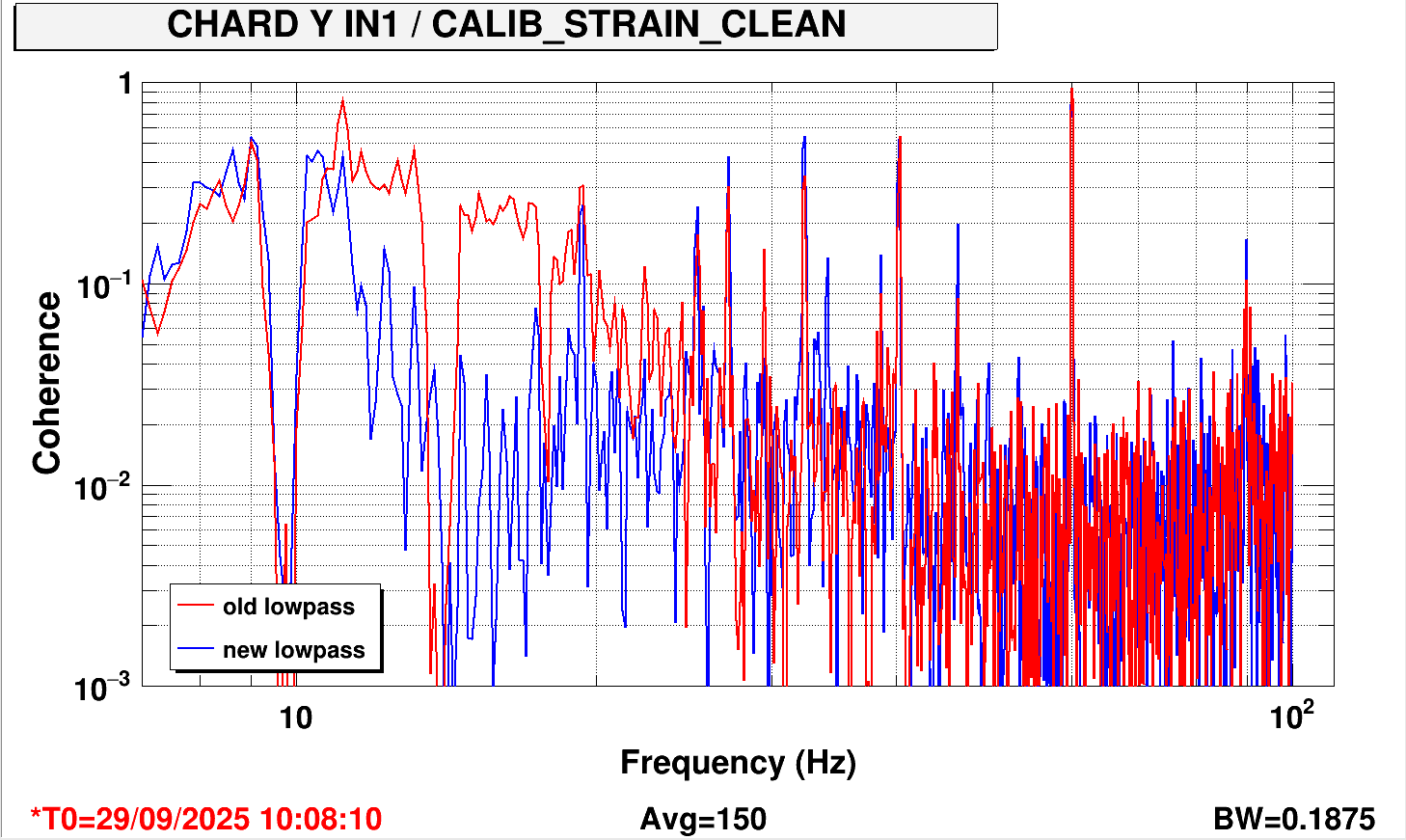
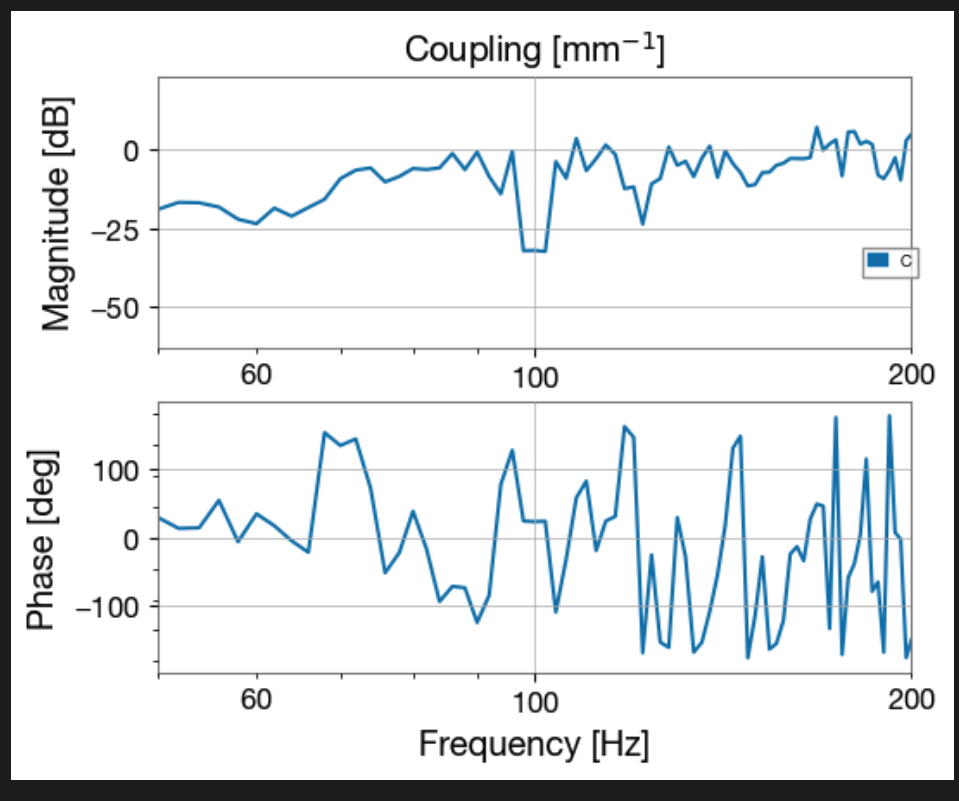
I implemented a new CHARD P low pass filter to reduce CHARD P coupling that is apparent in coherence measurements (example).
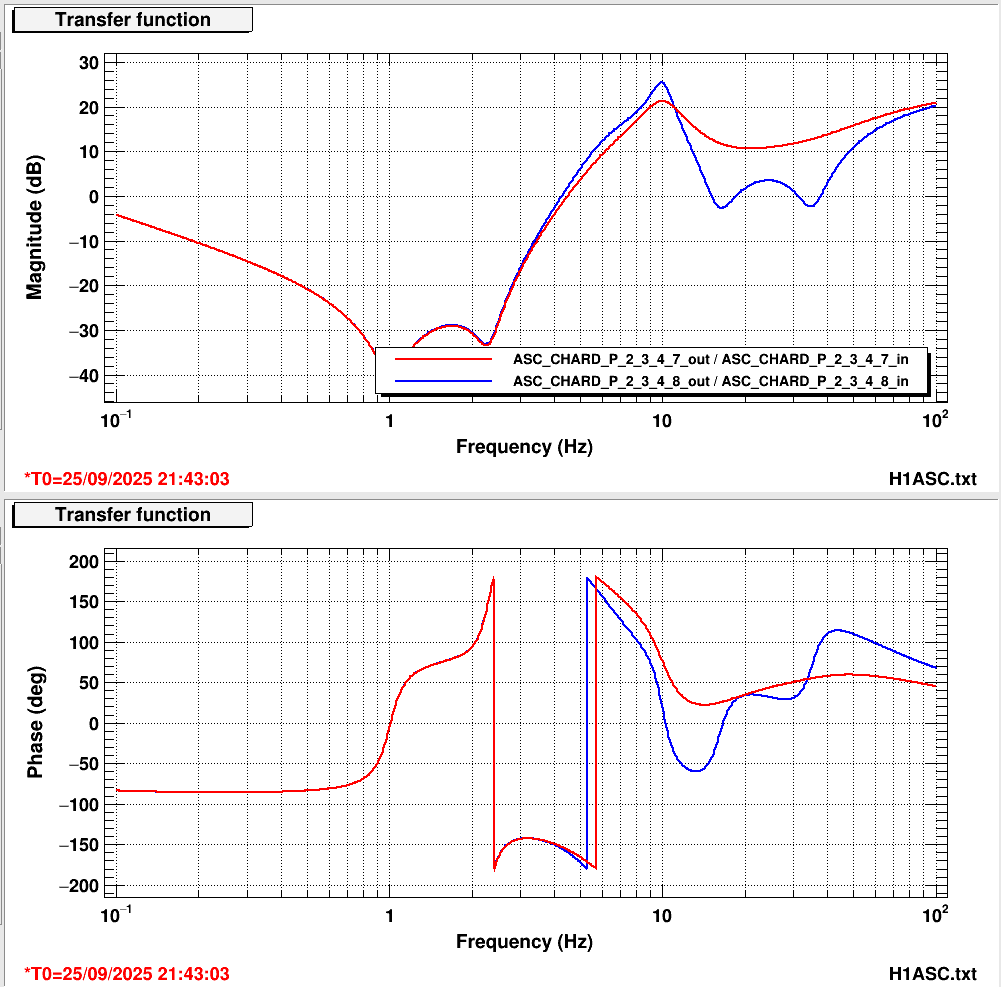
Here is a comparison of the old controller (red) with the new controller (blue). This replaces the lowpass filter in FM8 with the filter in FM9. I also disengaged the old 200 Hz lowpass that was previously in FM10, as it wasn't doing much. SDFs (1,2). Guardian code and ASC high gain script updated.
The coherence of DARM with CHARD P has reduced, as expected, and increased for CHARD Y, also as expected. I have since created a new lowpass for CHARD Y that should reduce the coherence and is ready for testing at the next opportunity (comparison).














{kind=link}
Jim put HEPI HAM6 into a safe state and we installed the new model at 08:40 PDT. No DAQ restart was required, I just had to clear the DAQ CRCs and DIAG_RESET the latched IPCs.
For a check, I was viewing the filter module MEDMs for WITNESS_P1 and 3DL4C_A_X. With the old code the witness was seeing around 700 counts and A_X zero, with the new code this was reversed, as expected.