Good thing:
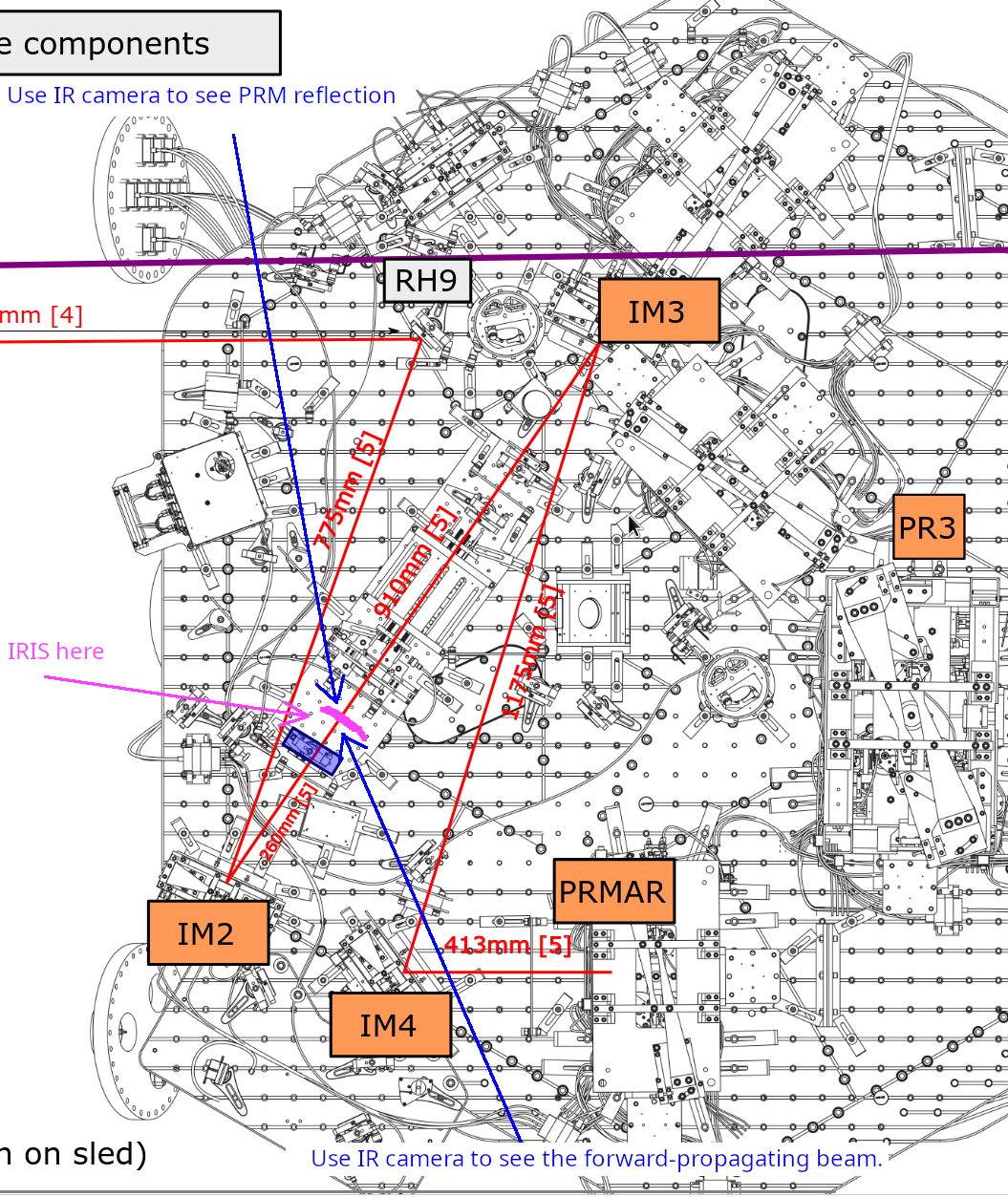
In the morning, we placed an iris placed between the IFI input baffle and the IFI HWP baffle (irisposition.png). We used an IR sensitive DSLR as a viewer to center the iris for the forward-going beam, and observed the back side of the iris using the same camera to see the PRM reflection.
This allowed us to set the PRM angle in much better accuracy than using a card with a bigger-than-needed hole handheld at an inconvenient location and observe with naked eyes through the laser glasses. We had to close down HAM3 cover as well as one side of HAM2 so PRM quiets down, but the retro-reflection accuracy was like +-50 urad (rather than +-500urad of yesterday).
With this new PRM alignment ([P, Y]=[-1165, +750]), I was able to center REFL sensors despite that RM2 was so close to railing, RM2 YAW offset was -1800urad. (ASC_REFL_balanced_20260602_morning.png and ASC_REFL_balanced_but_RM2_close_to_railing_20260602_morning.png.)
Nice thing was, at this point the beam was much closer to the center of IFI input baffle, IFO REFL beam clipping-like thing observed on the IFI input baffle was completely gone as well as the clipping on IM4 baffle. So things looked better in general than they were yesterday.
Bad thing:
RM2 was so uncomfortably close to railing nobody should leave it like that before pumping down, so I decided to relieve RM2 by tilting IM1. (Calculation is in alog 90404.)
I thought RM2 should be rotated counter-clockwise seen from the top because that would mean the positive YAW offset, we added negative 100urad to IM1 YAW offset (i.e. from -887.1 to -987.1 urad) based on my calculation, expecting to shave off 300 or 400 urad from the RM2 YAW. We reset the iris position for the forward-going beam, then reset the PRM angle, fully opened the iris and started centering the REFL sensors. Disappointingly, we couldn't center them, RM2 railed.
What was wrong:
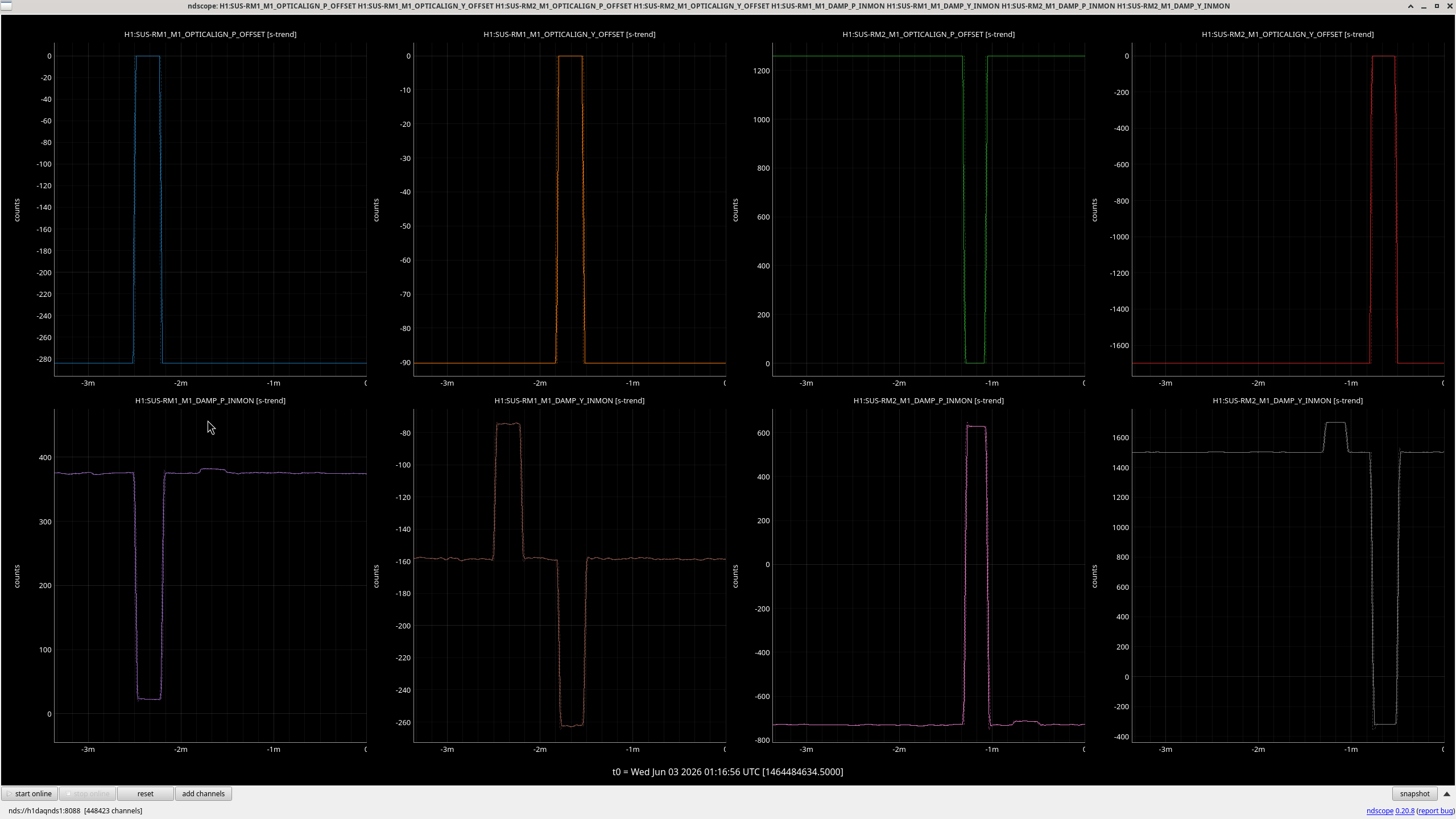
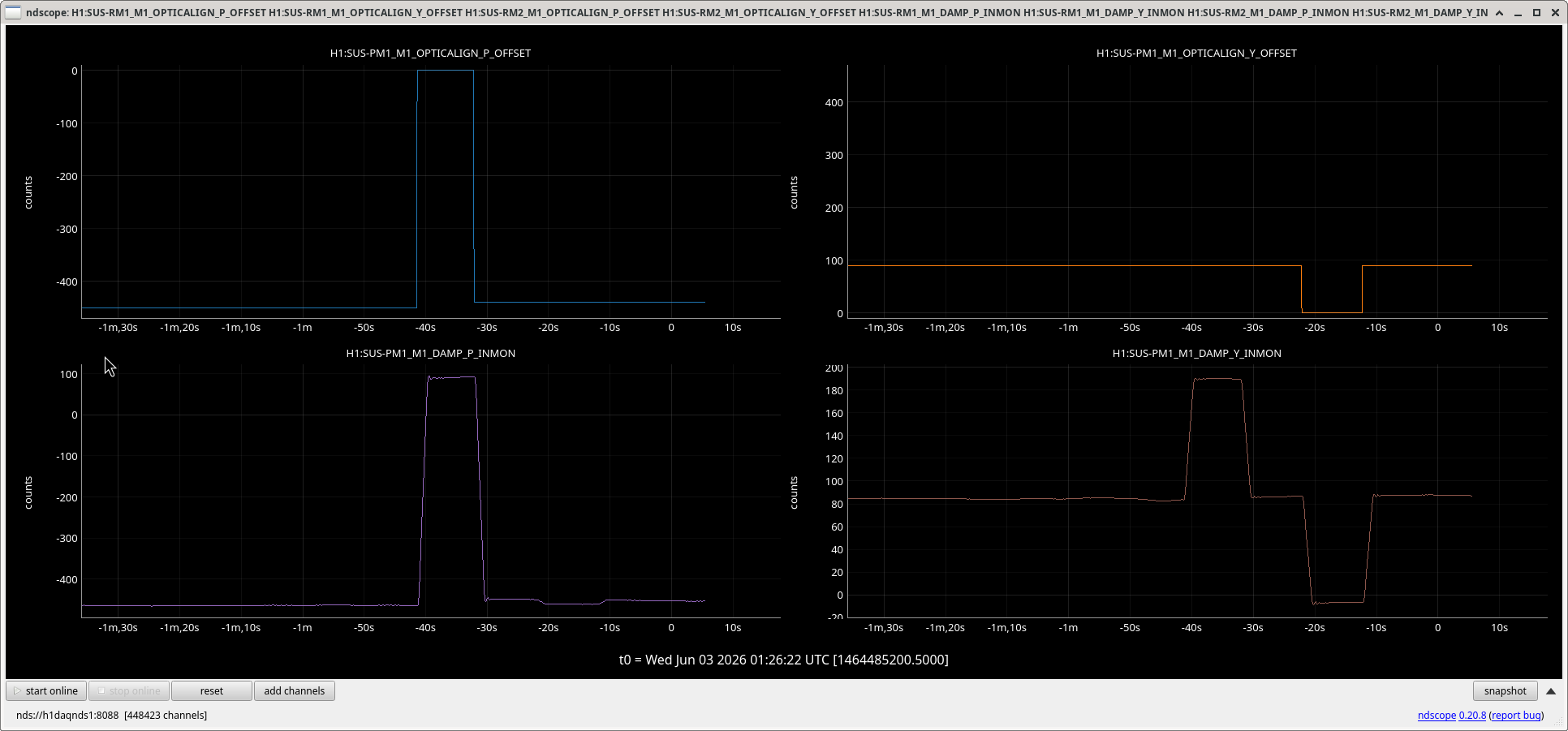
We wasted some time trying to somehow find a magic slider values for RMs and going through how the angle of IM1 propagates to RMs, but it turns out that RM alignment sliders seem to have the opposite sign than all other suspensions. As far as we believe that the OSEM sensor (not actuator) produces positive DAC output that is proportional to the number of photons, the conclusion is that the sign of the sliders is wrong for both RM1 and RM2.
This is clearly shown in wrongsign.png where slider offsets of RMs were zero-ed one by one (top row) while the OSEM sensors in Euler bassis (bottom) were observed. Ignore the cross coupling from P actuation to Y sensing. In a suspension that follows the LIGO sign convention, the slider and the sensors move in the same direction roughly by the same amount. RM is the opposite of that, sensors move in the opposite direction of the sliders. We have done the same test for RMs, PM1 (see PM_is_good.png), OM1 (because they're all tip-tilts) and IM1 (because we touched it today) and confirmed that RMs are an exception.
If you're not sure about the rotation convention of LIGO optics, positive YAW rotation means counter-clockwise seen from the top. This will increase the light power on RIGHT OSEM sensors and decrease it on the LEFT. Given that the ADC reports positive voltage (i.e. positive counts), and given that usually OSEM YAW signal is proportional to voltage(RIGHT)-voltage(LEFT), positive physical YAW rotation will produce positive OSEM YAW change. See my cartoon (LIGO_YAW_sign_convention.jpg).
Now, RM1, RM2 and PM1 sensing look identical to me (osemsensors_look_good.png).
All OSEMs produce positive numbers for all three suspensions, there's no sign flip in the filters, filter output sign is only determined by whether or not the input is bigger or smaller than the mid-point offset, they all use identical OSEM2EULER matrix as well as SENSALIGN matrix, and the sign of DAMP_P as well as DAMP_Y are all according to the filter outputs and these matrices. So the sensors for RM1 and RM2 are working in the same way as PM1, they're fine.
The conclusion to me is that somehow the actuation sign is wrong for RM1 and RM2.
Rahul told me that the magnet polarity was wrong for RM1 or RM2 and people spent some time to address that issue. But that sounds like the actuation side issue which should NOT affect the validity of the sensors. Unless people tell me that somehow the physical UL/UR/LL/LR sensors are wired to the LR/LL/UR/Ul channel or something, we just believe the OSEM sensors and assume that the sign of sliders is flipped.
Tomorrow:
Regardless of the reason of the sign flip, we'll proceed to move IM1 in the opposite direction, i.e. somewhere between this morning and Friday.
FYI below is the history of IM1 YAW offset in the past week. The change made on Monday was motivated by the "need" to relieve RM2, but now that we know that the PRM retroreflection accuracy matters, I'm not sure if it would have been impossible to center REFL ASC sensors on Friday if we used the iris technique to align PRM.
| |
Friday last week |
Monday |
Monday |
This morning |
This afternoon |
| IM1 YAW slider |
-387urad |
-887urad |
-887urad |
-887 |
-987 |
| PRM retroreflection |
questionable |
questionable (YAW offset = 1000urad) |
questionable (YAW offset = 700 urad) |
better (YAW offset = 750)
|
better (YAW offset = 1000) |
| REFL ASC centered |
No (RM2 rails) |
No (RM2 rails) |
yes |
yes (RM2 close to railing) |
no (RM2 rails) |



























{kind=link}
{kind=link}