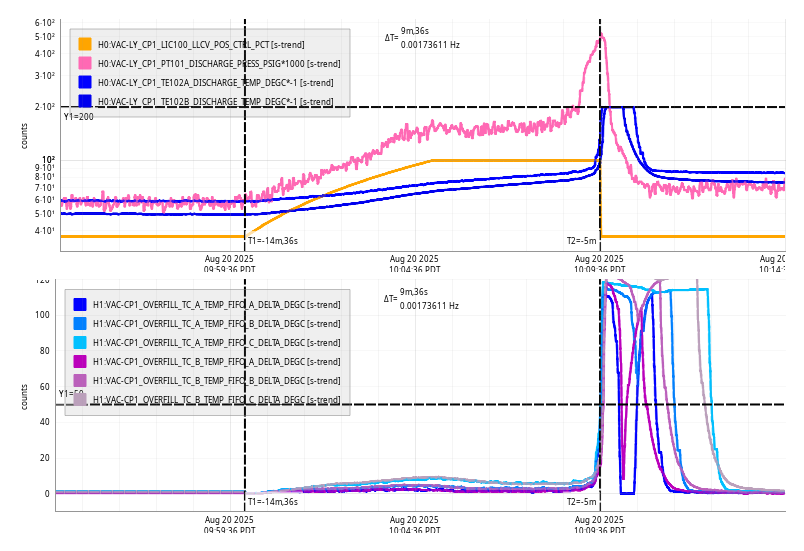
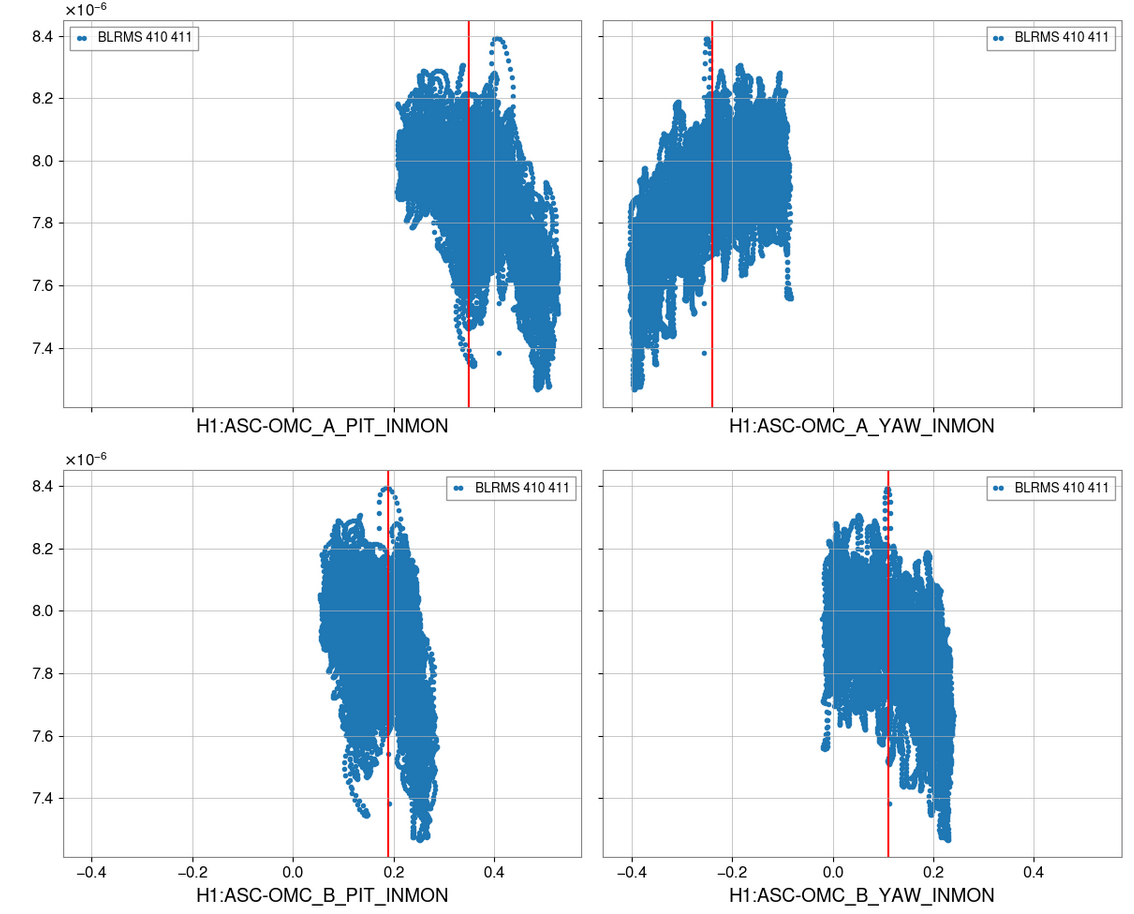
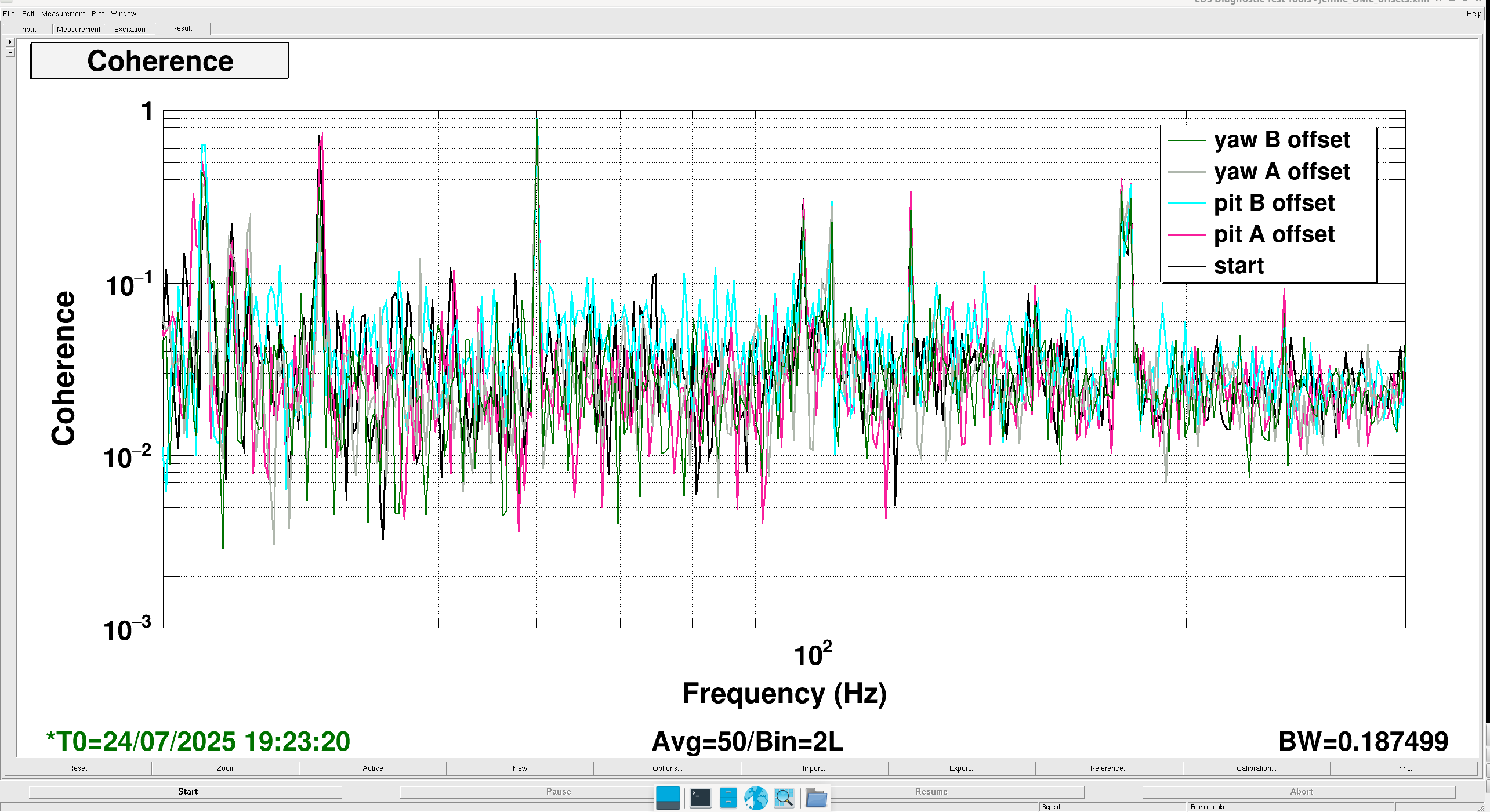
Summary: I didn't see any conclusive difference that showed we could get an improvement from a change in a particular direction. Since the optical gain moves around so much its hard to see the effect of small or quick changes. It might be worth doing a longer test were we step these offsets in sets of three different values per dof (3*4 steps) and do each for five mins (~ 1 hour).
I orginally was trying to use the results of our last injection (2025-06-16 20:41:15 UTC to2025-06-16 21:01:57 UTC ) to determine how to change the OMC ASC alignment.
Using /ligo/home/jennifer.wright/git/2025/OMC_Alignment/20250116_OMC_Alignment_EXC.xml we injected four low frequency lines into H1:OMC-ASC_{POS,ANG}_{X,Y}_EXC - these channels come after the filter banks (ASC-OMC_A_PIT_OFFSET, then ASC-OMC_B_PIT_OFFSET, then ASC-OMC_A_YAW_OFFSET, then ASC-OMC_B_YAW_OFFSET) where the nominal offsets are set. The injection is at four different frequencies (0.0113, 0.0107, 0.0097 and 0.0103 Hz).
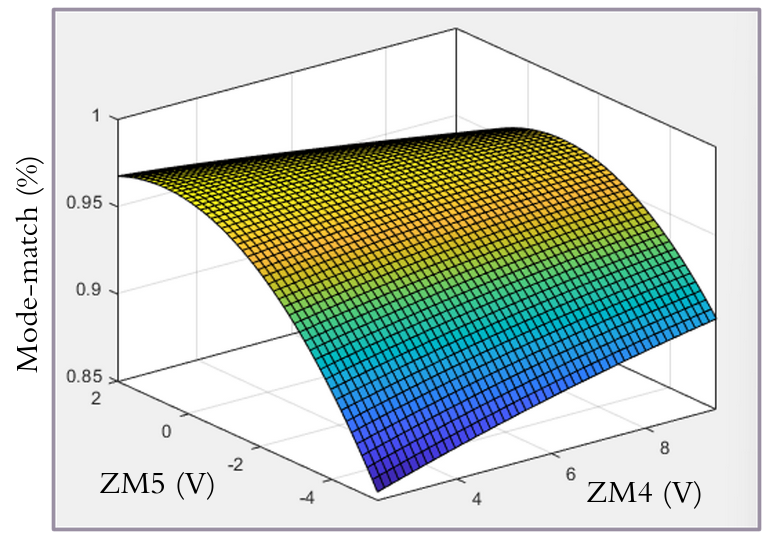
The analysis then involves looking at the 410 Hz line height on the OMC DCPD SUM to interpret the effect on optical gain.
However it is not clear from this plot that the full range of phase space has been looked at - ie we have not changed the offset with a large enough amplitude to check their current position is optimal.
Thus today I stepped ASC-OMC_A_PIT_OFFSET, then ASC-OMC_B_PIT_OFFSET, then ASC-OMC_A_YAW_OFFSET, then ASC-OMC_B_YAW_OFFSET - these filter banks are before the ones used above in the model and are the ones where the offset for the QPDs is set. In the
Towards the last three measurements we realised that we need to do larger changes ~0.04 counts to see a change in kappa C then wait for 3-4 mins. On the long term trend none of these changes seemed to produce any meausurable gain, but it would be good to repeat this measurement with longer times spent at each step and perhaps go in slightly larger steps.
The ndscope template is in /ligo/home/jennifer.wright/git/2025/OMC_Alignment/20250724_change _offsets_by_hand.yaml