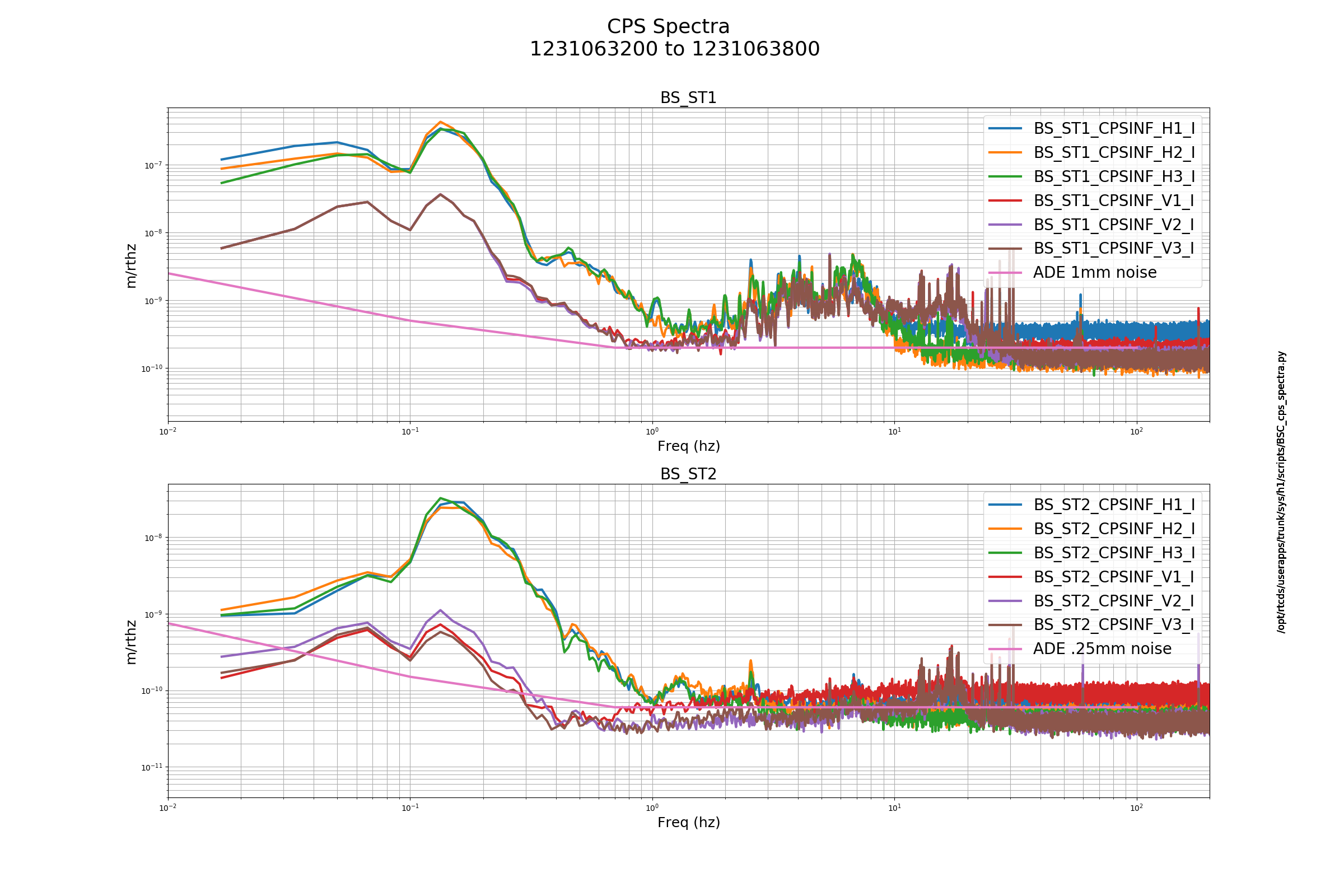
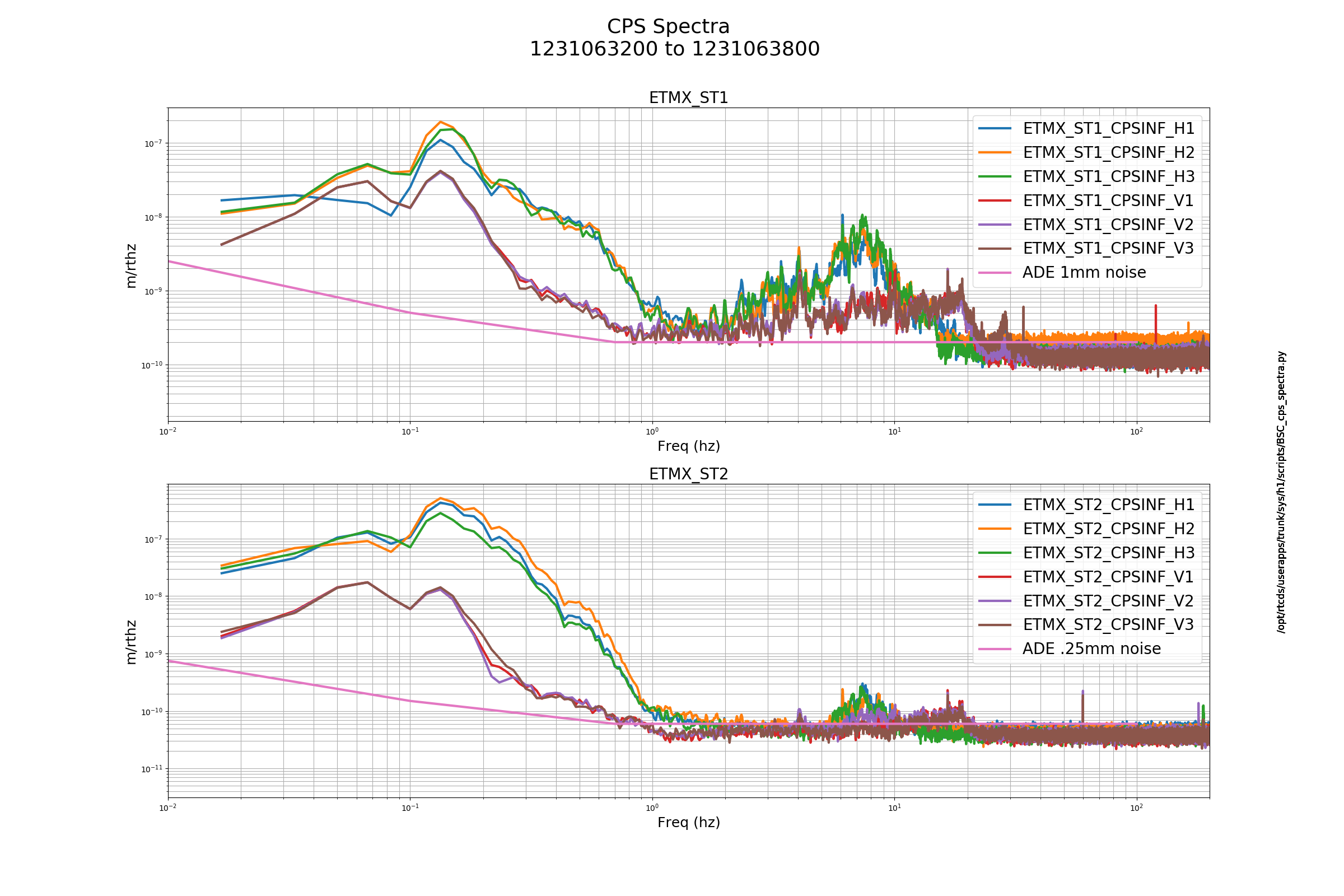
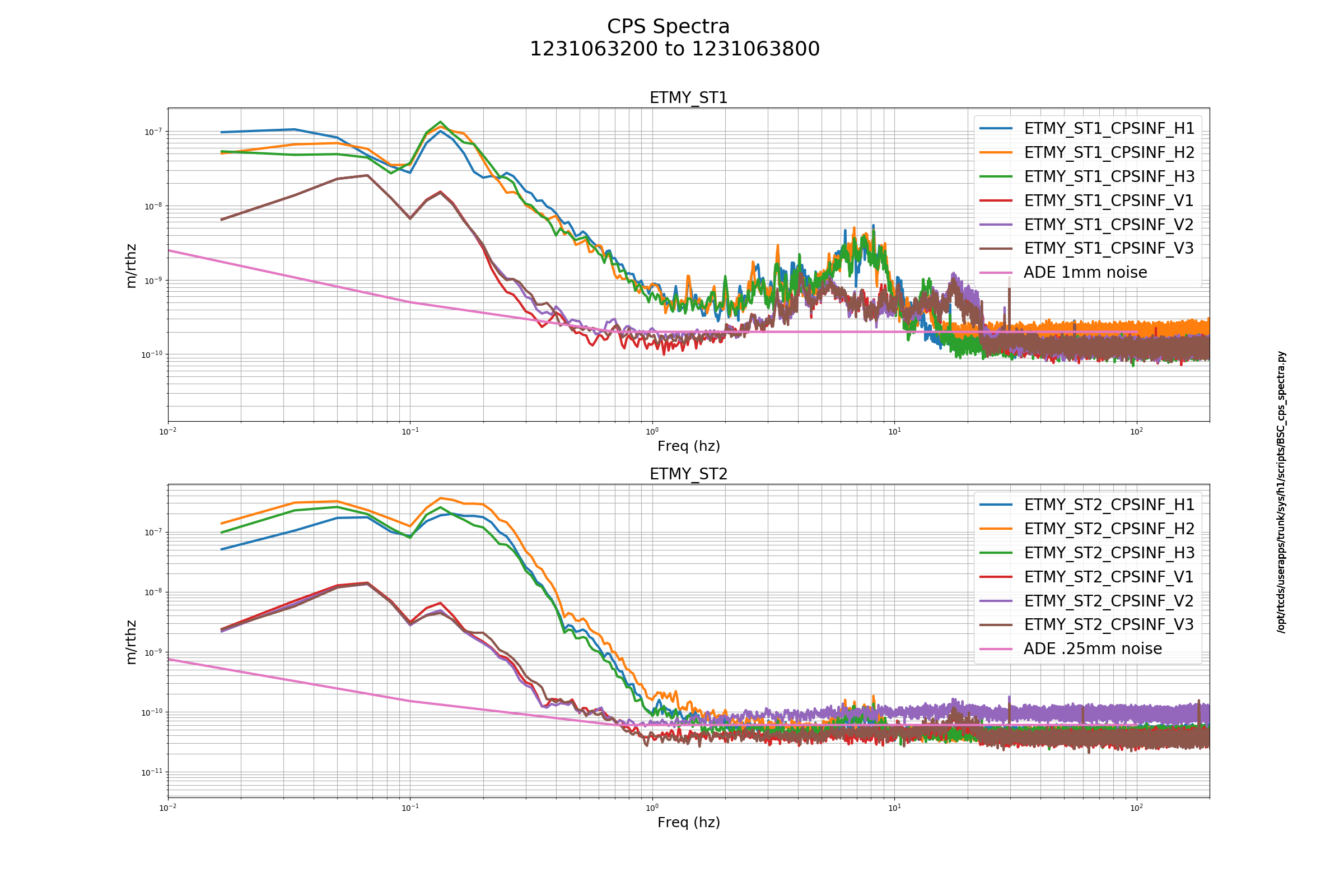
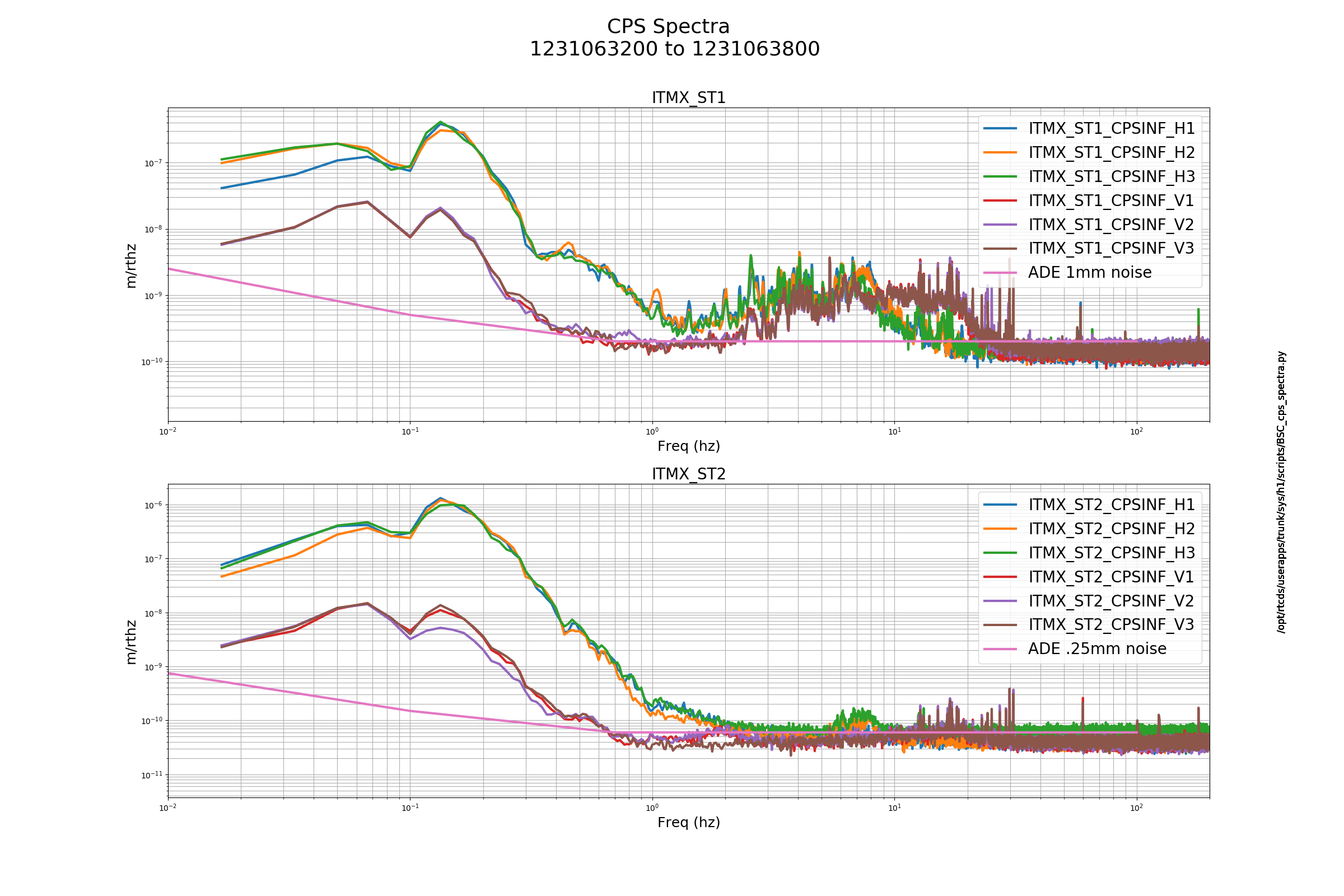
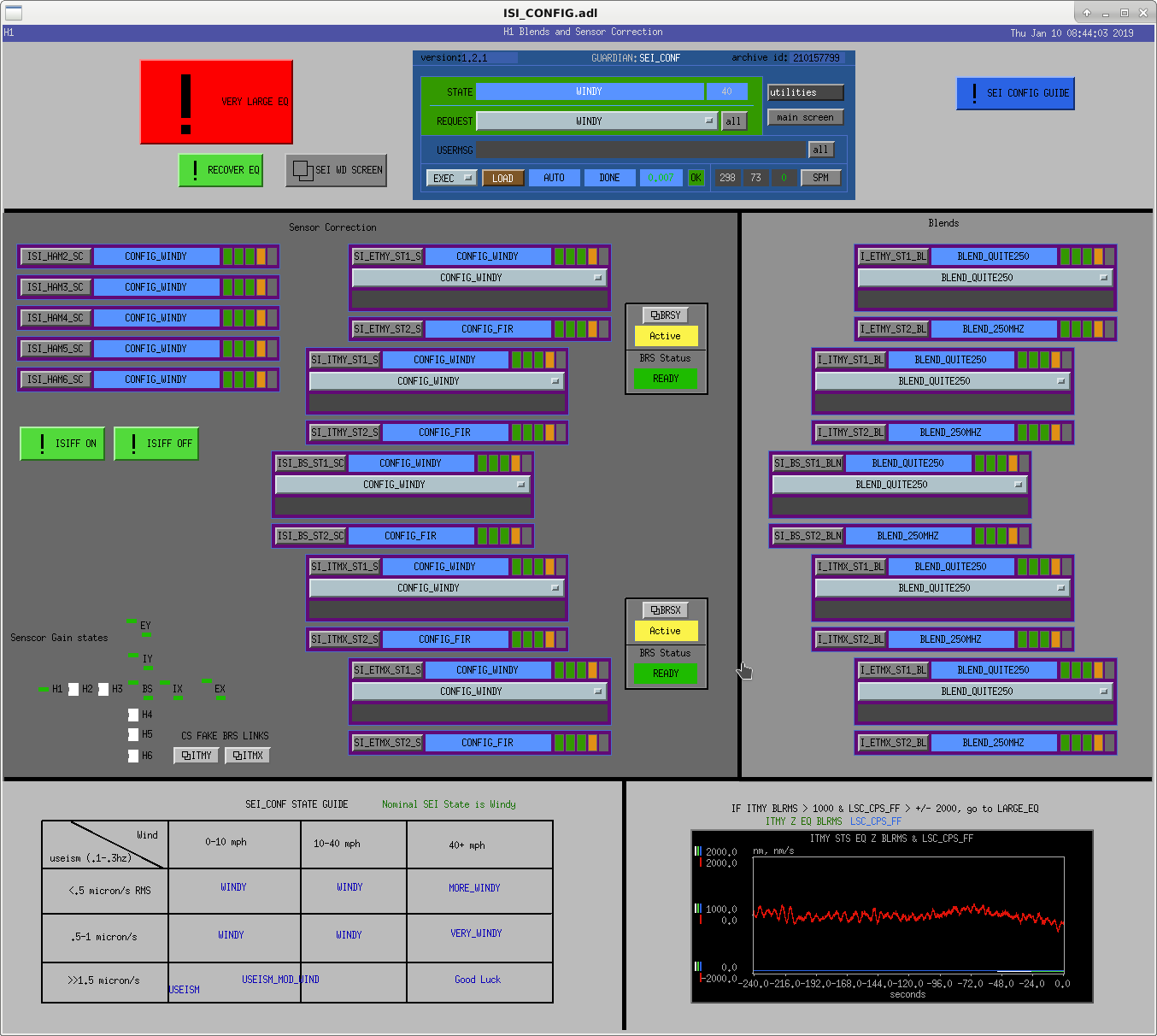
J. Driggers, S. Dwyer, J. Kissel, P. Thomas
Prior to yesterday's rebooting of most front-end machines (LHO aLOG 46288), Patrick, Jenne, Sheila, and I went through the SDF system and reconciled differences. I attach the highlights of what we accepted (into the SAFE.snap files -- OBSERVE.snap files were NOT reconciled). The highlights come mostly from the ISC systems that are infrequently maintained. This may (or may not) be useful as (a) a recovery aide today, and (b) a record / indication of the progress / changes in the global control system over the past few weeks and the holidays -- especially as some of the team responsible for the changes have left the site for good.
h1asc model:
- Accepted changes to the TR X/Y and A/B QPD to DHARD and DC5 to elements of the ASC input matrix. This reflects the changes made by Hang before the break to implement the radiation pressure compensation (RPC) stystem (e.g. LHO aLOG 43849). These elements of matrix were last changed in mid-December (e.g. Dec 14, 23, 26 , and 28)
- Several other Radiation Pressure Control TRAMPs were accepted as is.
- Accepted the reduction of the CHARD Y A gain from 1.4 to 1.35, and the turning OFF of the DHARD Y B loops by setting the gain to 0.0. This is something we don't necessarily want to keep, but was part of the spot position exploration vs. TMS drift on Monday night.
- Accepted the CHARD Y to ITMX element of the ASC output matrix at 0.87 (where it had been saved [accidentally] in December as 0.93, which everyone agreed is very wrong).
- Accepted ASC_AS_A_RF45 I and Q individual segment filter gains as 1.0 instead of 1.413. These had accidentally been saved in the SAFE.snap because two weeks ago, we were reconciling SDFs in a state just before nominal low noise. That means we were *past* the state that reduces the RF45 modulation depth, and compensates that optical gain change by increasing the gain of the AS_A_RF45 sensor from 1.0 to 1.413, which we *do* want when we're in nominal low noise -- i.e. when we reconcile against the OBSERVE.snap -- but now when we're DOWN, or in low acquisition states -- which is what we want after computer reboots. Thus ACCEPT as 1.0.
- Accepted any and all ASC-ADS (alignment dither system) changes in filters, gains, limiters, tramps, oscillator frequencies, etc as is. These are all a part of the new dither alignment system mentioned above. Most were changed on Dec 21 with the system was installed (LHO aLOG 46136).
h1ascimc model:
- Accepted MC2 TRANS QPD SEG[1-4] FM9 filter = "+9dB" gain as OFF. This filter was originally installed in concert with a -9dB analog whitening gain in mid-December when Sheila found that we had saturated the QPD's ADC before a high-power lock loss on Dec 21 2018 LHO aLOG 46084. However, whether it be from settings loss or intentional, the analog whitening gain was restored to "nominal" +36 dB gain a day later, and then the compensating gain filter was turned OFF a few days after that. Somehow, in those three days, though, someone saved with compensating filter as ON in the SDF file. Since the analog whitening gain is no back to regularly being at +36 dB, there is no longer a need for this +9dB compensation filter to be on. It's been accepted as OFF.
h1lsc model:
- Accepted changes to the LSC output matrix elements for OSC 1 2 3 to PRM, SRM, and BS matrix as now regularly ON (with whatever values were present). This is the part of the new length dither line system to constantly monitor the length loop gains during power up. LHO aLOG 46082
- Reverted LSC PD DOF matrix (the DRMI 3f input sensing matrix) elements as ZERO. The safe.snap file correctly indicates that the DRMI 3f matrix elements should be zero when the IFO is down. The current EPICs values were non-zero because the last lock loss was during a DRMI 3f lock, and the elements hadn't been reset.
- Reverted the LSC TR X NORM OFFSET from -0.36 to 10. This offset (as far as we can tell) isn't used, but it's been 10.0 for a very long time prior to its change on Dec 21. Also the LSC TR Y NORM OFFSET is also 10. No findable aLOG, so we reverted.
h1lscaux model:
- blindly accepted all ~110 differences.
h1omc model:
- Accepted the change in filtering of the OMC-LSC_PD_IN bank -- the first filter bank on the way to the OMC length control that band-passes the OMC DCPDs. The OMC length dither line band pass was reduced from "BP4100" in FM5 = [4000 4200] Hz to "nBP4100" in FM7 = [4050 4150] Hz on Dec 31 -- see LHO aLOG 46197.
h1susbs model:
- Accepted FM10 = "BounceRoll" in the BS M2 LOCK L filter bank as OFF. This is the Beam Splitter's Bounc and Roll mode notch. It's unclear why it's off, but it's been this way for quite some time, so I accept it.
h1susitmpi model:
- Reverted all UPCONV output matrix elements to 0.0. This matrix last had values changed and populated while Sebastien and Terra were here getting Qs of test mass mechanical modes in early December 2018 (LHO aLOG 45812), and are no longer needed.
- Accepted all oscillator frequencies.
Generic Things Across Models:
"QPD Offsets"
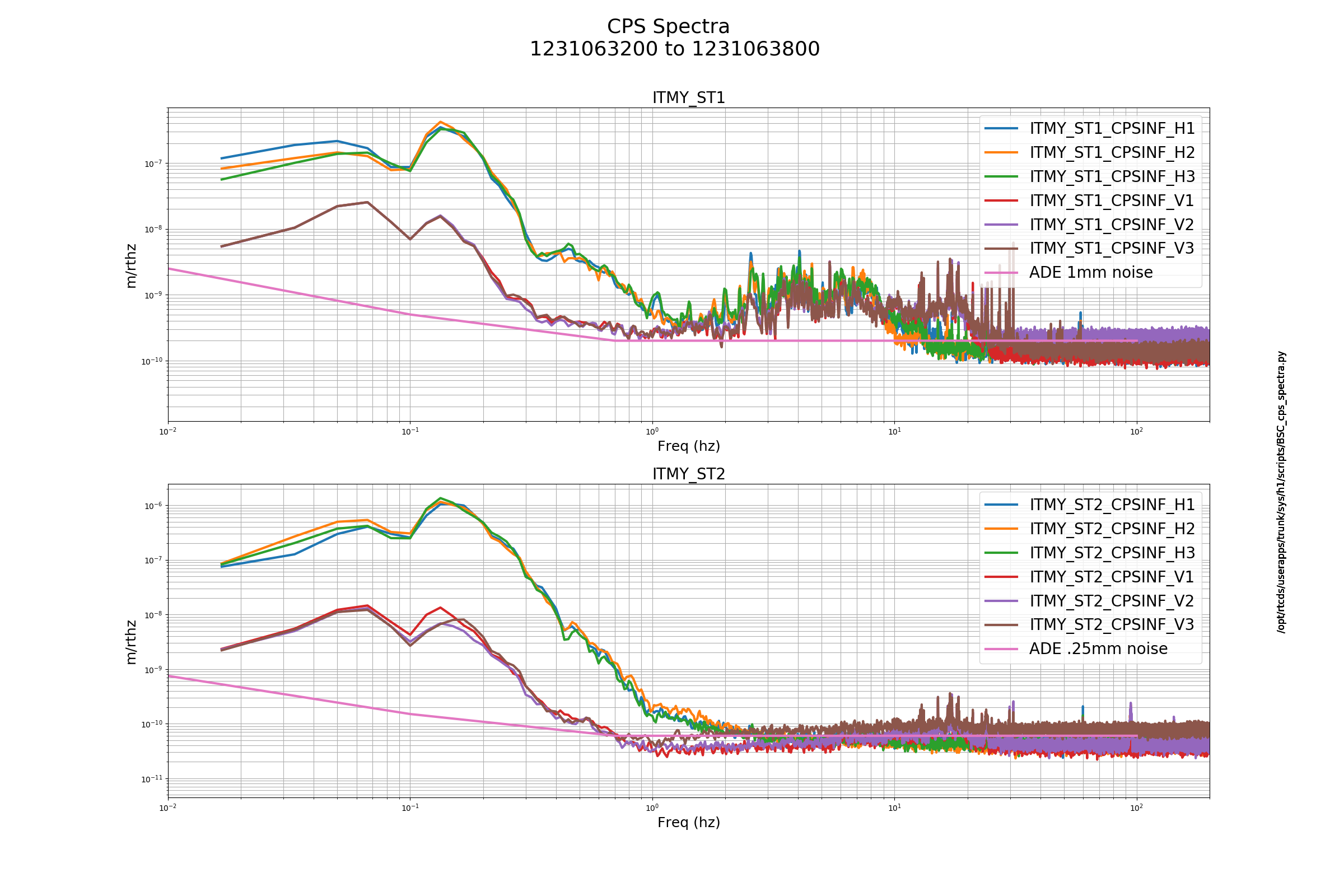
- Any and all QPD and WFS OFFSETs have been accepted as is in h1asc, h1ascimc, h1omc, h1alsex, h1alsex, h1iscex, and h1iscey. As we're continuing to explore and find the optimal spot position for the interferometer -- especially after we've switched to an ETM alignment dither system (see e.g. LHO aLOG 46272) -- these will be occasionally updated.
"A2L gains"
- these DRIVEALIGN P2L and Y2L gains across many globally controlled suspensions (like h1susetmx, h1susetmy, itmx, itmy, even h1susmc2) are coupled with the above mentioned exploration of spot positions. Jenne says, theoretically, with the new ASC dither system, we should no longer be regularly updating these, so we've accepted them as is.
"Not28Hz" filters
- in h1asc model, accepted DC 1 and 2 "Not28Hz" filters (FM9 for P and FM5 for Y) as ON. The crowd didn't have a satisfying answer for this resonant feature that intermittantly gives us problems, moves around in frequency, and/or may be solved -- according to a Dec 19th LHO aLOG 46084 after some commissioning of ASC loops.
- in h1susbs and h1susetmx models, accepted 28.75 Hz filters as OFF.
We should probably go on a campaign of removing these filters now that the problem has been solved.