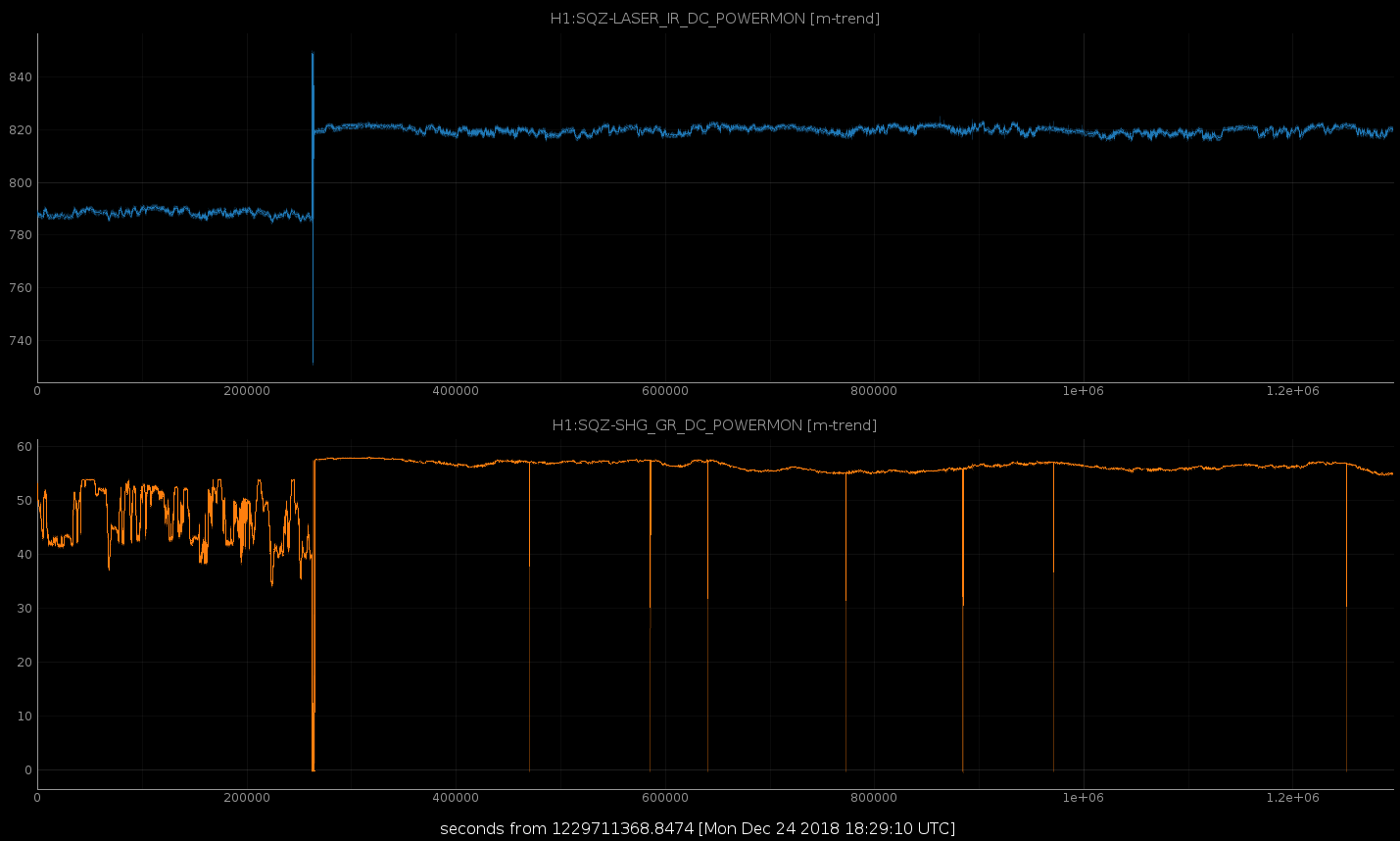
The AC units in the PSL were both run at 24C, and while Jason and I exited the PSL more than 3 hours ago, the temperature in the PSL remains elevated, which has effected the Reference Cavity, and caused us to have to adjust the ALS temperature at EX, and until the PSL/REF Cav temperatures recover, the squeezer is unable to lock.
The history is that we have been running both PSL AC units at 23C, and this cools the PSL to a level that means there is a noticeable recovery
At some point a few months ago I ran one AC unit at 23C and one unit at 24C, to try and prevent the large excursion in temperature, and this seemed to be better.
Since then there's been a change of running both AC units set to 24C, as they were today, and from trends this appears to have changed November 8th.
PSL persons had the best intentions, and recognize the need to revisit the strategies for minimizing the effect of working in the PSL on the rest of the interferometer.
Attachment 1, 2, and 3: shows TABLE North and TABLE South temperature sensors, over 24 hours, for three different Maintenance Days.
- both AC units 24C: today, where and one can see that we worked in the PSL, and where the residue heat from our activities has remained in the enclosure, which has added heat to the PSL components.
- both AC units 23C: October 10th, 2018, where the PSL temperature also had not recovered from the cooling during Maintenance. This represents that issue we've observed, where the PSL is cooled off and doesn't recover until roughly the next day.
- both AC units 23C: October 30th, 2018, where the PSL temperature recovered more quickly
Attachment 4: shows 120 days for TABLE North and TABLE South temperature sensors, and on the left one can see that Tuesday Maintenance temperature changes drop in temperature more than the Tuesdays we've worked in the PSL on the right side of the plot.