- After the last lockloss from last night, the EY Senscor gain became bad. After the earthquake this morning, I requested MORE_WINDY seismic conf (winds were ~30 mph) and this fixed EY.
- I locked the Y arm after 5 hours.
-- 3 hours of earthquake
-- 1 hour of getting through INITIAL_ALIGNMENT
-- 1 hour of getting a decent arm and TMS alignment after earthquake.
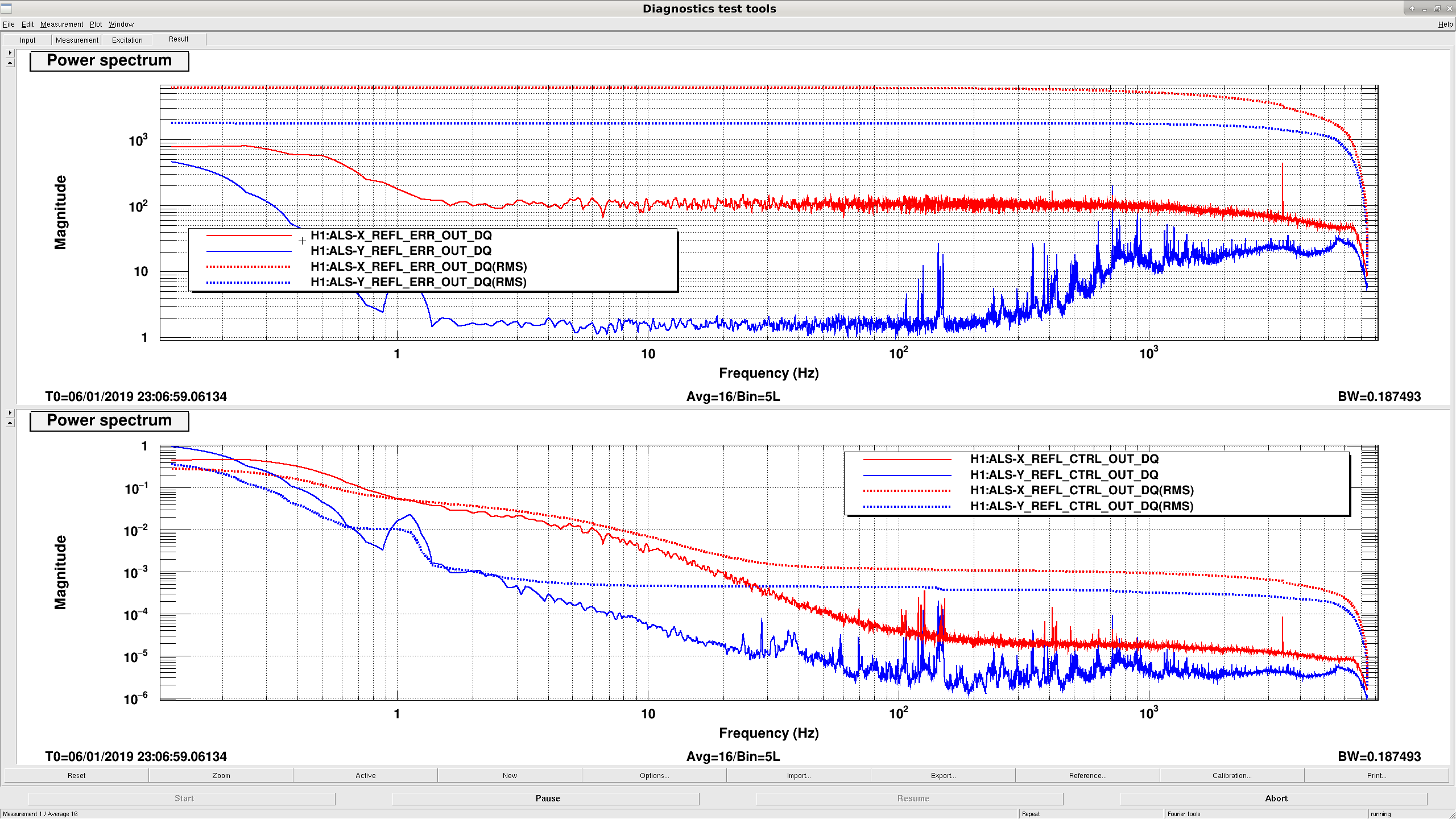
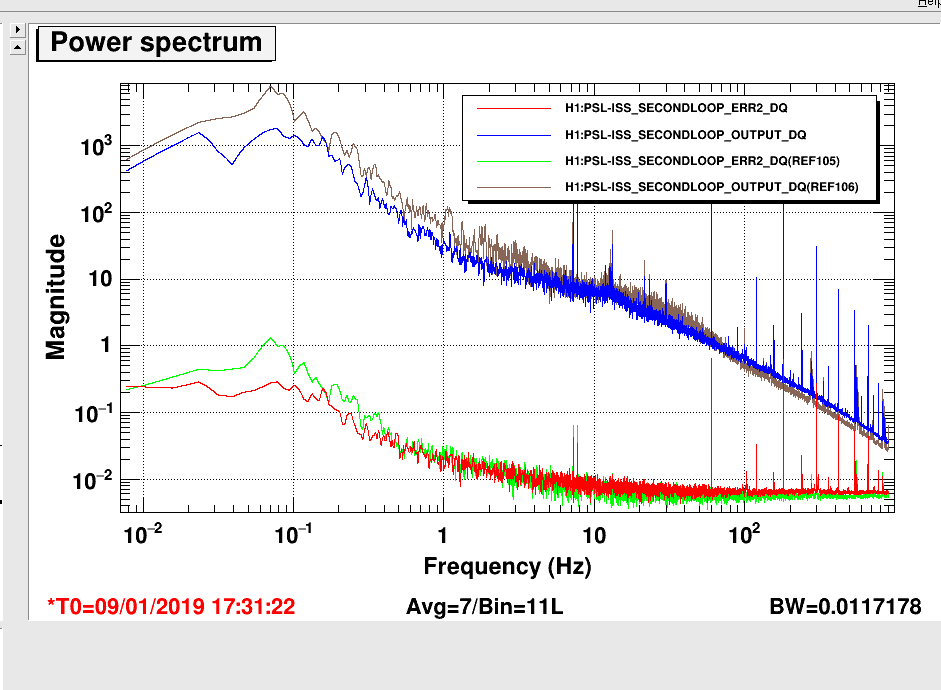
-- Attachment 1 shows a 60 Hz peak on the ALS Y REFL B LF spectrum. I don't think ALS REFL B is used for locking, but this huge peak could find it's way into the Y locking loop somehow.
-- Attachment 2 shows the ALS X and Y Arm PDH Spectra after locking today. The ctrl signals are calibrated into um.
-- The Y arm is known to be extremely sensitive to misalignment, and prone to flashing though higher order modes even when well-aligned. Watching the X and Y arm error and ctrl time series, the Y error signal saturates at a much lower value than the X arm (the ctrl signal for Y can only go to +-1 um away from 0 before the controller runs out of range, while the X arm can go up to +-4 um). Then again, the X arm RMS is far higher.
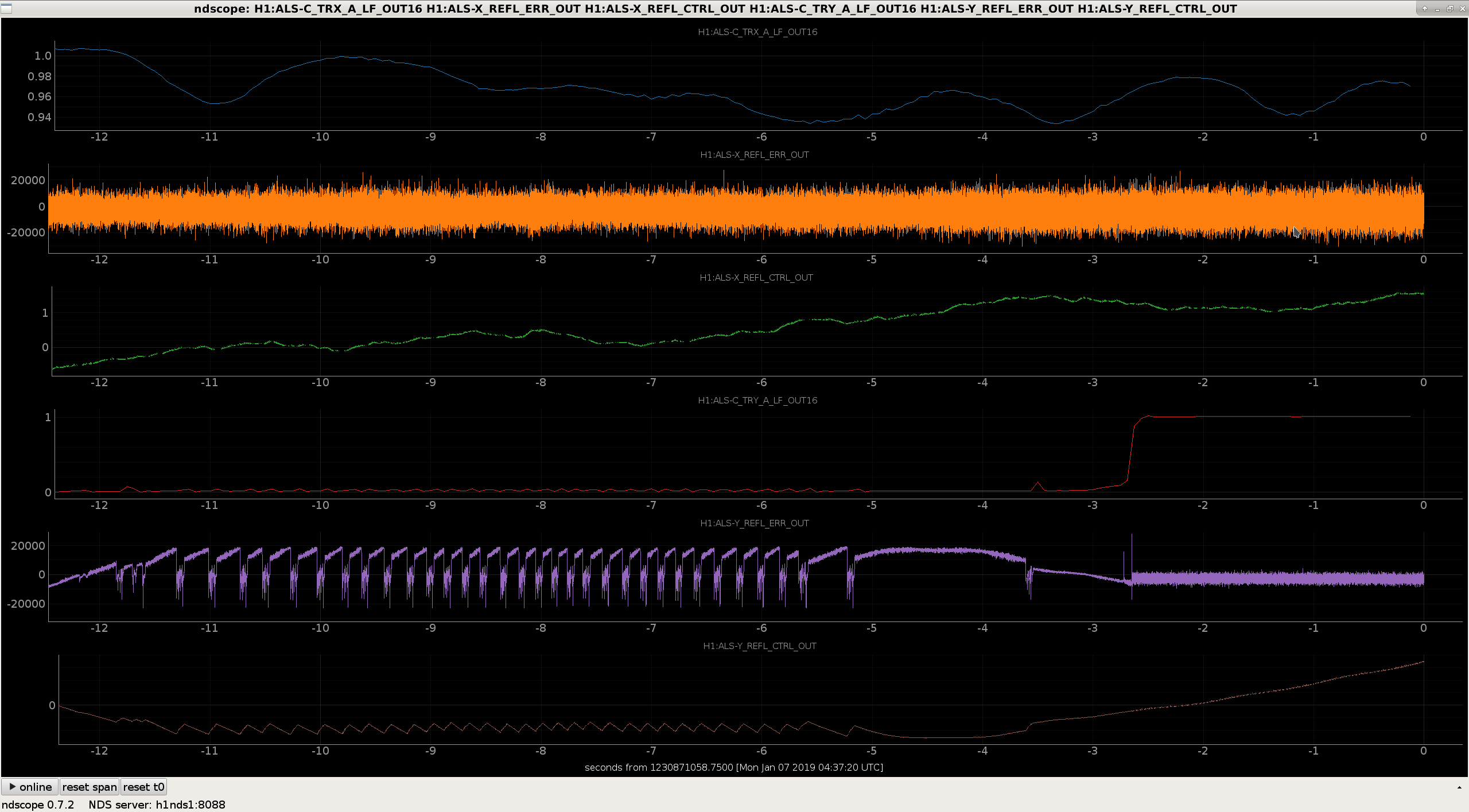
-- I included a screenshot of what the Y error and control signals are doing when Y acquires (attachment 4). Each error signal saturation is associated with the quick flashes we see in the control room. The Y arm seems to be swinging around too much, and the Y PDH can't keep up.
- Going through INITIAL_ALIGNMENT, the ACQUIRE_PRX state immediately railed the PRM M3 stage since we had fallen off the POP A QPD. I had to pitch PRM M0 manually to get PRX to lock. When it did lock and get through PRC_ALIGN, the alignment onto POP_A QPD was pitched to -1. Also had to manually align SRY.
-- I was unable to hold a DRMI lock for more than two minutes. and when I did POPAIR 18 was way down with good alignment (~50 cts). All last week we could get to 65 cts. Still cannot figure out why POPAIR18 is so low.
-- At least four times, I have acquired DRMI, sat in ENGAGE_DRMI_ASC for two minutes, then lost lock.
-- To see if it is MICH ASC that is unstable I requested TURN_ON_BS_STAGE_2. So far I've been locked for 15 minutes here, so the MICH ASC is likely causing DRMI locklosses.
-- The MICH ASC was causing locklosses, but only because the SRM alignment was very bad. Touching up the SRM alignment allowed us to stay at ENGAGE_DRMI_ASC indefinitely, but did not improve POPAIR18 levels.
-- TRANSITION_DRMI_TO_3F caused MICH Pitch to ring up with it's current gain of -0.25. I caught it without losing lock by changing the gain to -0.12.
-- Was unable to go past DHARD_WFS.
-- I checked the TCS settings, and while they aren't perfect (see below), there is no egregious problem (ring heaters and C02 are at at least close to their requested values, ITM spherical power is close to what it was yesterday)
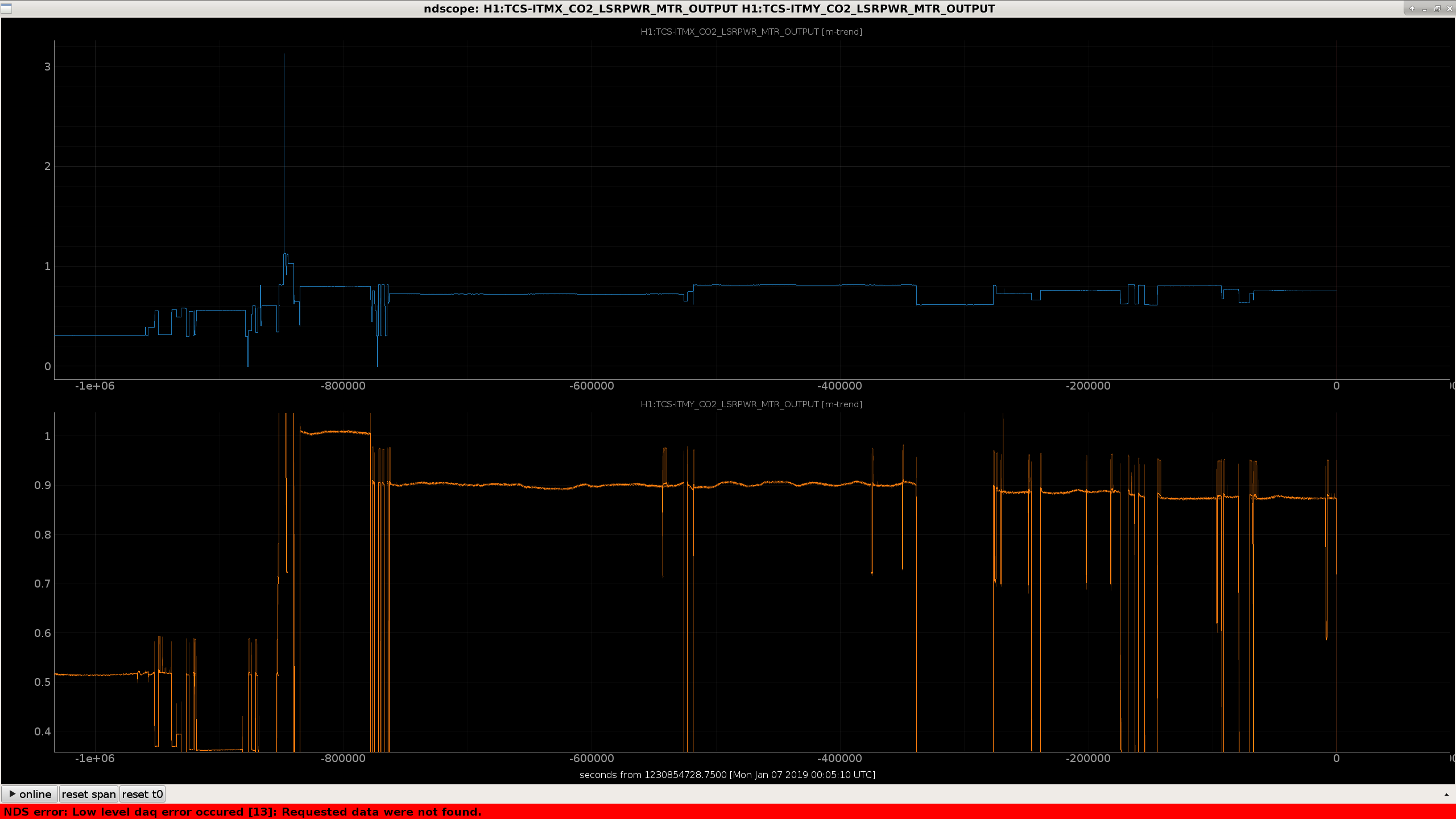
- The ITMY CO2 laser is not lasing at the power requested, causing the TCS_ITMY_CO2_PWR guardian to be broken. It wants to get to HOLD_POWER but keeps stalling in ADJUSTING_POWER.
-- The requested power for ITMY is 1.0 W, but the CO2 is only delivering 0.87. This is beyond the acceptable range of 0.08 W, so ADJUSTING_POWER continually requests ADJUSTING_POWER over and over, stalling every time.
-- Attachment 3 shows this changed occurred at Dec 28 2018 23:25:10 UTC, so it should not be a major problem for locking. More disturbing is the fact that the ITMY CO2 power appears to be decaying slightly.
-- I don't know how to fix the CO2 laser to actually lase at the correct power output, so I changed the requested power to 0.87 W so that ISC_LOCK doesn't have to unstall TCS_ITMY_CO2_PWR every two seconds.
- It seems that I have been hoisted by my own petard. After initial alignment, I was given an significantly different alignment than usual. My manual alignment to get PRX and SRY to lock took us completely off the rails, too far for the initial alignment ASC loops to correct for.
-- I tried using wfsreliefpast.py at a time for Georgia's lock last night, but this took me too far off to lock at 2 W. I used my goToAlignment.py in /opt/rtcds/userapps/release/asc/common/scripts/ at GPS 1230783828 to move the sliders, this brought me close enough to get INITIAL_ALIGNMENT running again.
- Again, locking ALS Y has proven extraordinarily tedious (~1.5 hours of Y arm alignment).
-- I lowered the Y arm acquisition gain to -10 dB from -4 dB, this changed nothing.
-- For future reference, watching the height fast flashes of H1:ALS-C_TRY_A_LF_OUT_DQ on ndscope made actually aligning possible, since the Y arm likes to grab onto HOMs for 99% of the time, even with good alignment.
- Made to back to RESONANCE with POPAIR18 back to ~60 cts. ENGAGE_REFL_POP_WFS murdered the lock. ENGAGE_ASC_FOR_FULL_IFO murdered the next lock.
-- The next lock, I aligned CHARD by hand using Hang's move_ARM_dev.py script, then ran ENGAGE_ASC_FOR_FULL_IFO, which almost worked this time. PRC1 rung up late in the FULL IFO alignment.
-- After this lockloss I was unable to lock ALS DIFF anymore: three ringups killed three locks in a row.
-- The ALS_XARM guardian died (?), halting ISC_LOCK with Ezca connection issues. Restarted with guardctrl restart ALS_XARM.
It is in this regrettable state I must leave the interferometer: broken ALS Y, broken ALS arms to DIFF transition, poorly aligned, and ASC that cannot converge without killing the lock.









{kind=link}