daniel.vander-hyde@LIGO.ORG - posted 23:08, Monday 03 December 2018 - last comment - 17:44, Tuesday 04 December 2018(45673)
ITMX HWS adjustments (More picoing and 800nm bandpass added)
Dan B. , Danny V.
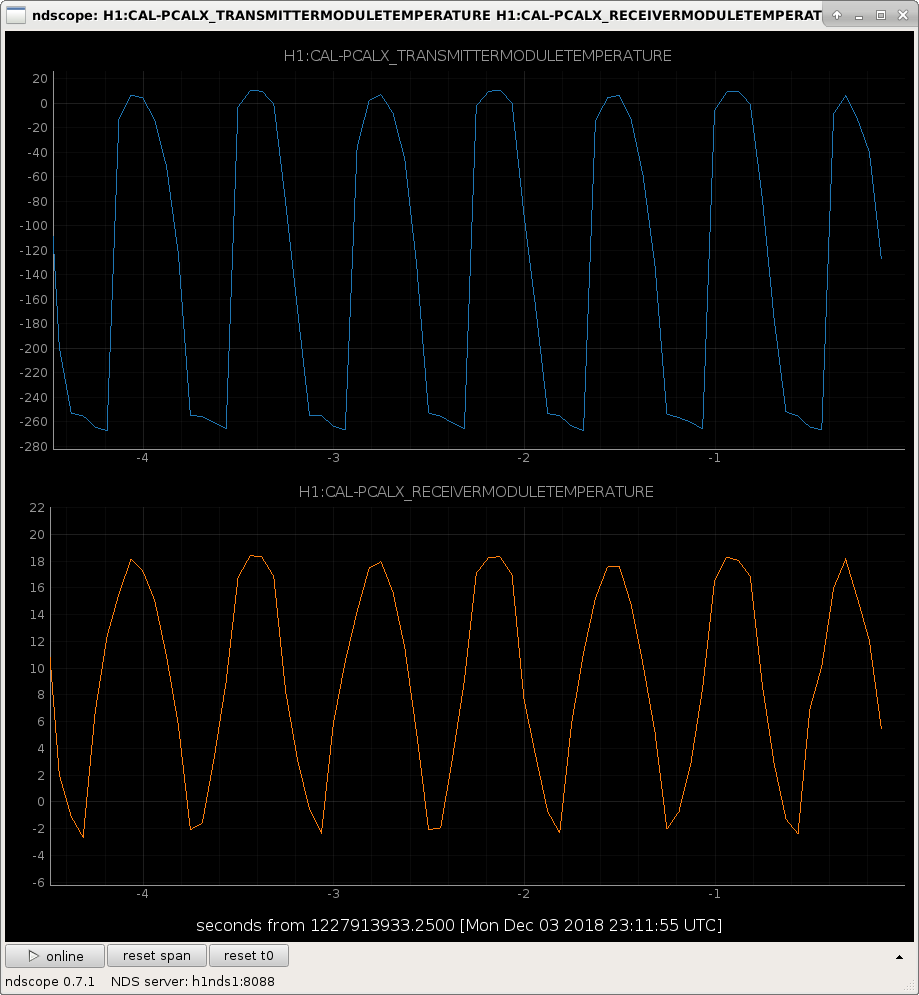
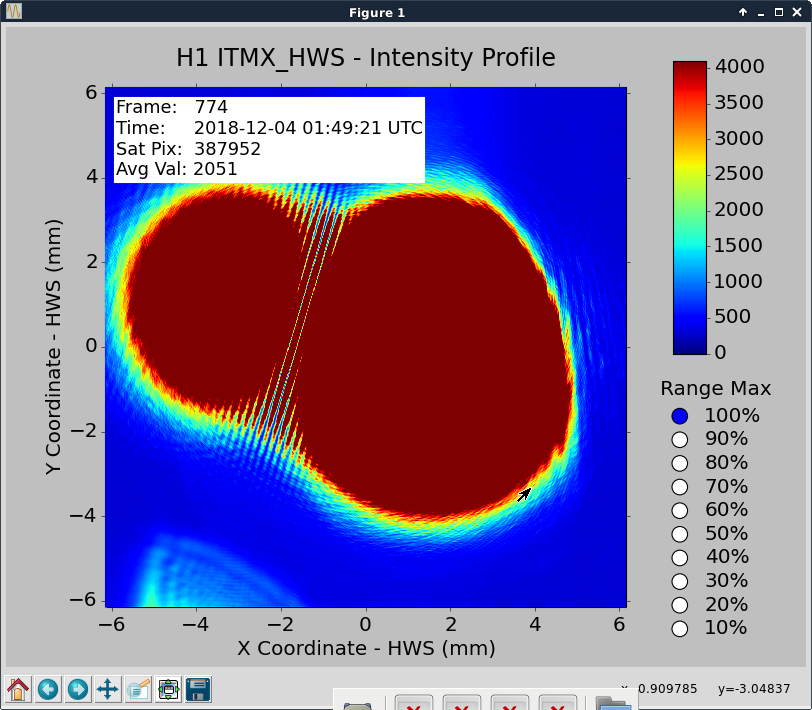
- The first time powering up to 30 W the ITMX Hartmann beam profile seemed resonable and showed a semi-circular profile.
- Next two lock sequences, the ITMX HWS was outputting nonsense. We were convinced that this could be attributed to the new ifo alignment but after heavy picoing we didn't have much luck.
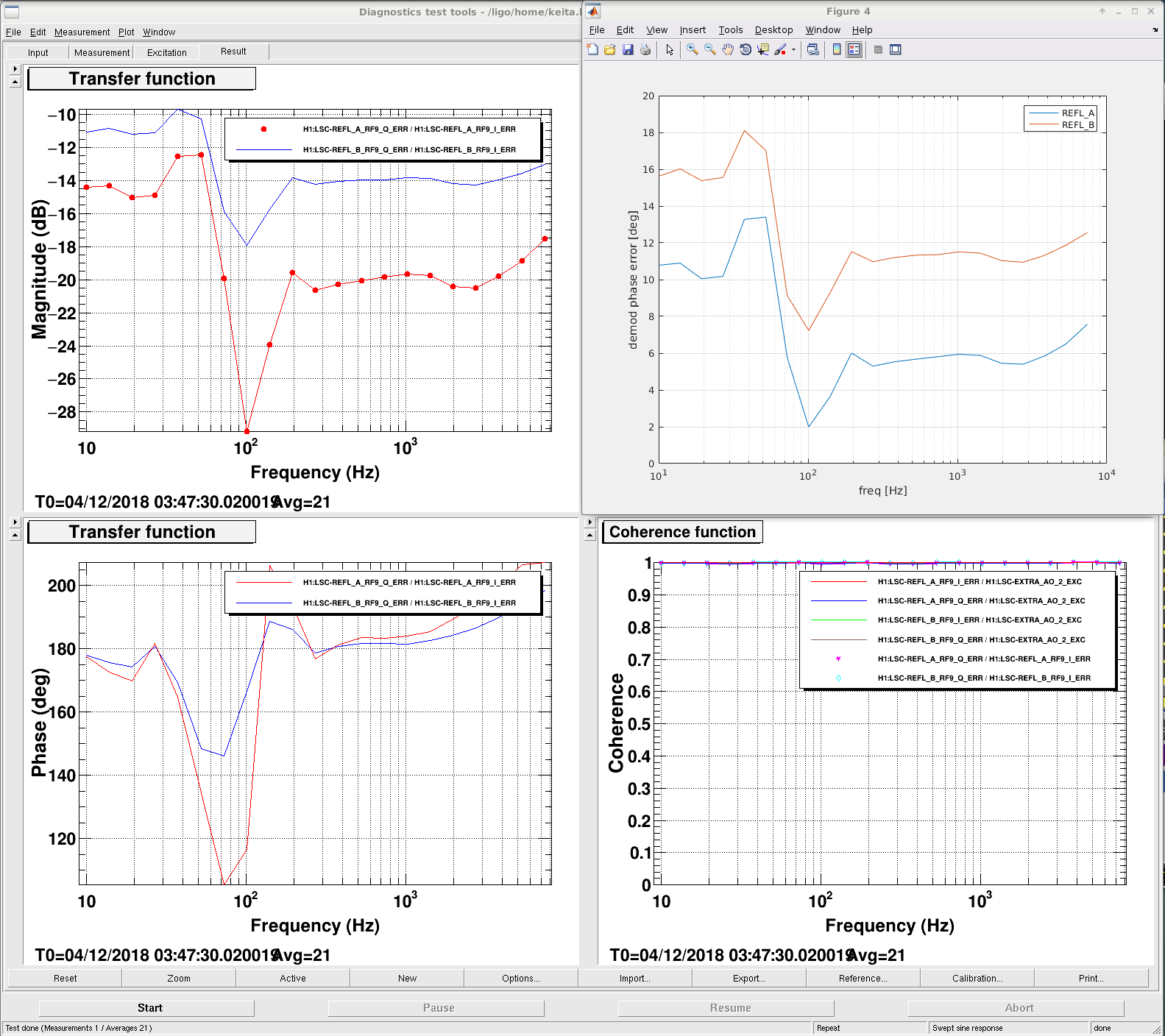
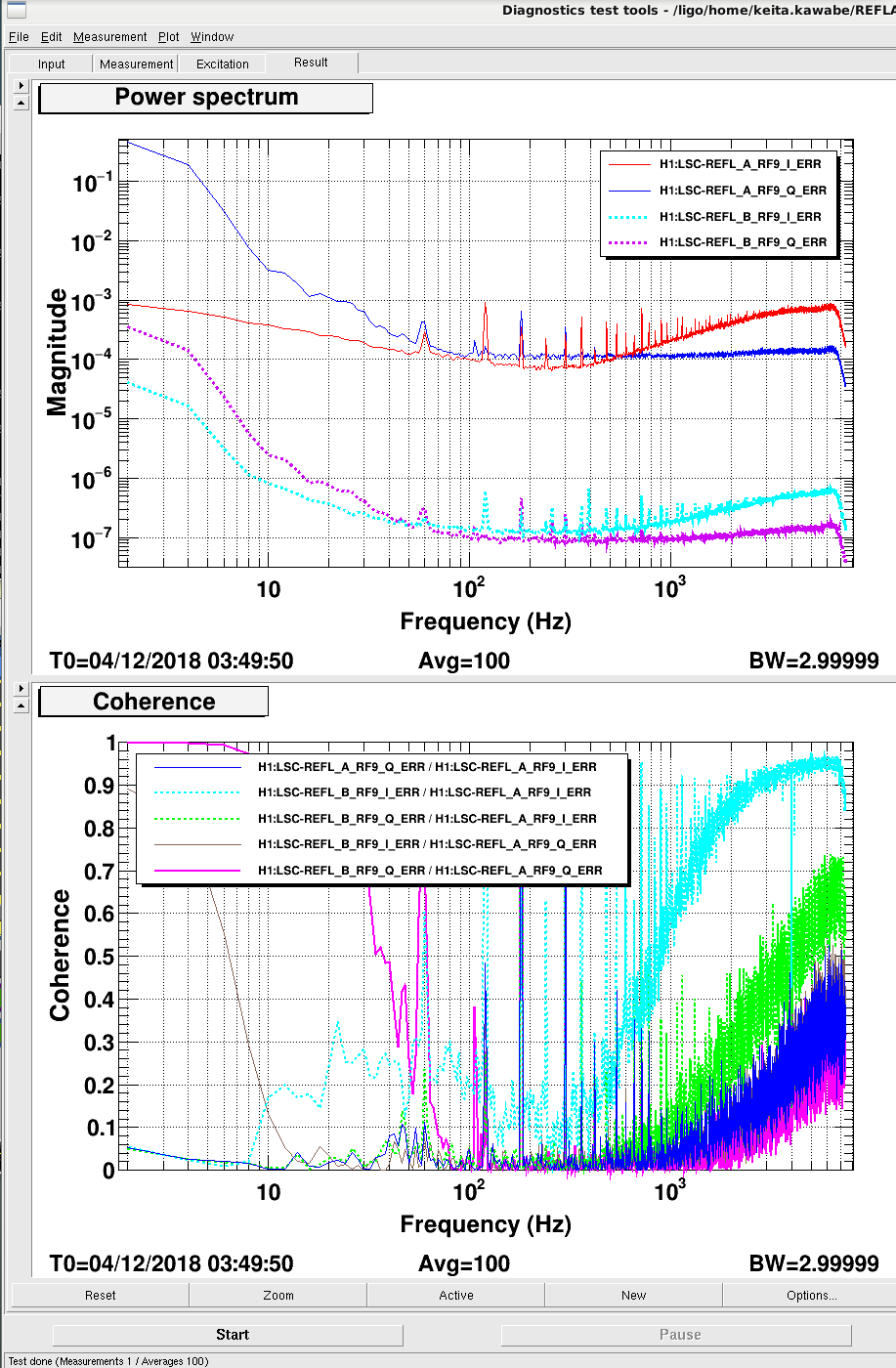
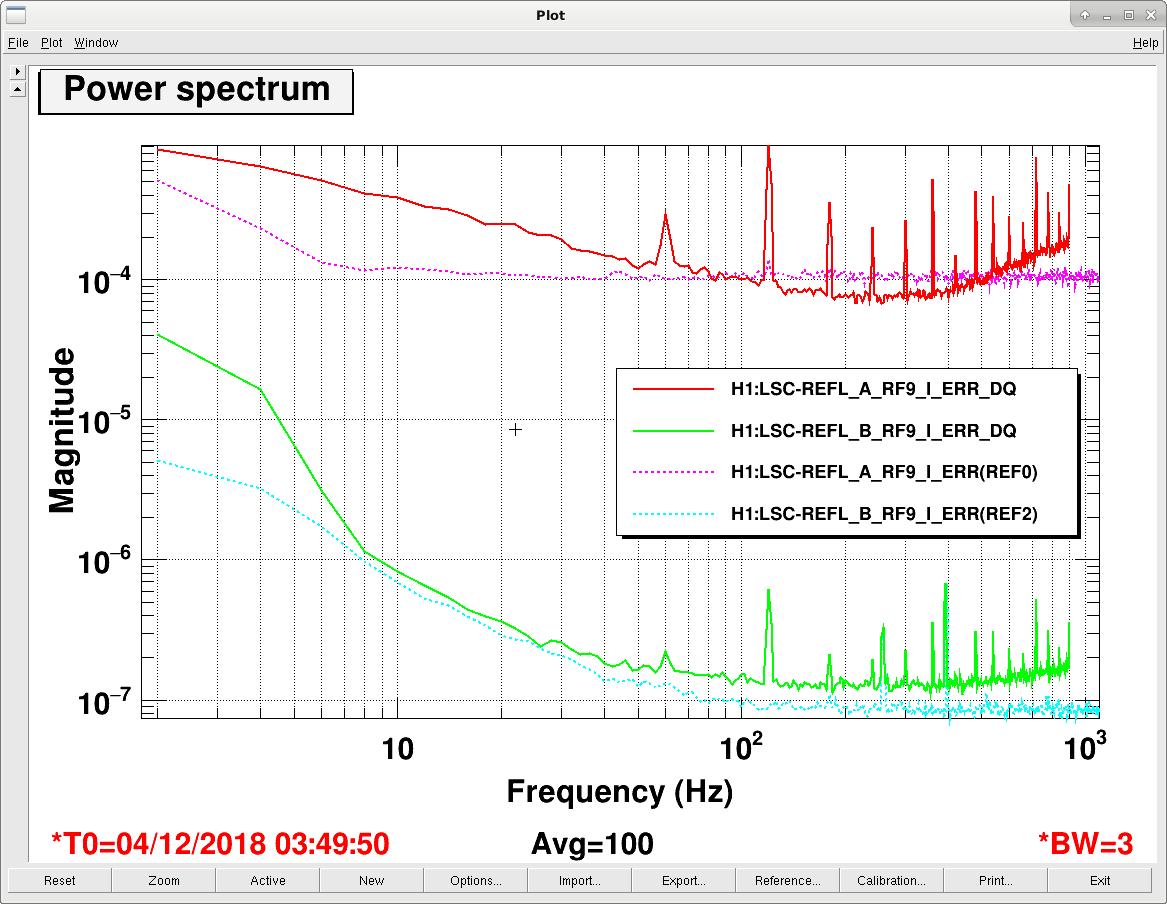
- We checked the ITMX Hartmann beam with both Hartmann plate and
1064 nm notch800 nm bandpass filter removed and adjusted the picomotors to co-align stray 1064 light and ALS to the SLED beam. (please see the images 3-5) - After witnessing some fringing in the Hartmann images, which we have previously attributed to stray 1064 light passing through an on-table beamsplitter (alog 45022,alog 45074), we suspected that the current
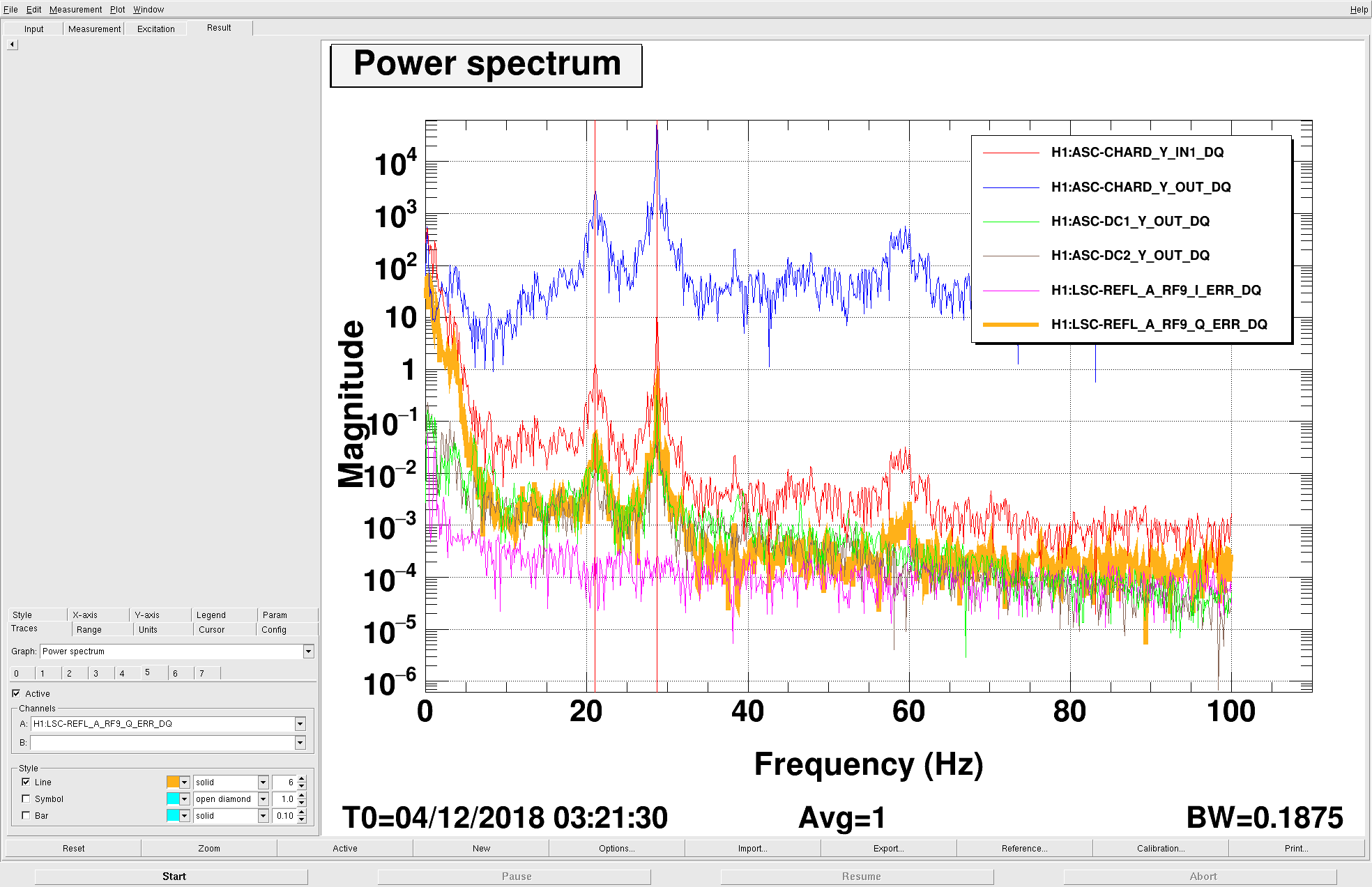
1064 notch filter800 nm bandpass in place may be leaking some IR light to the ITMX Hartmann sensor. In response, we placed the1064 filter as well as the 800nm bandpass filter from ITMY HWS1064 filter from the ITMY HWS path in the ITMX HWS beam path in series with the 800 nm bandpass. The last attached image shows the state of the ITMX Hartmann sensor after these changes. - I'm not convinced that the result is much better than the first 30 W power up of the day.
- Investigations on what happened to the SLED beams after this first power up are pending.
Images attached to this report





Comments related to this report
Can you add the product number of the bandpass filter than you've added?
Hey Aidan,
Bandpass product number: FB800-40
1064nm notch filter product number: NF1064-44