Haocun, Terry, Sheila, Rob Ward (spiritually), Nutsinee
In this alog I'd like to try to answer three questions: 1) Can we lock at relatively high green power input to the OPO? 2) Is the loss different as we change power? 3) What happen when you scan fast enough so that the crystal doesn't have enough time to heat up (if the asymmetry is really caused by crystal absorption)?
After we looked at error signal at different power on Tuesday, on Wedsday I went and moved the crystal position left and right just to see if there're any difference in the green trans/refl/error signal. After that I moved the crystal back towards the left edge and was able to lock there while getting the nlg of 5.6 out. The day before we just couldn't lock at all at the peak of green transmission (when the crystal position was roughly around the center). What's changed?
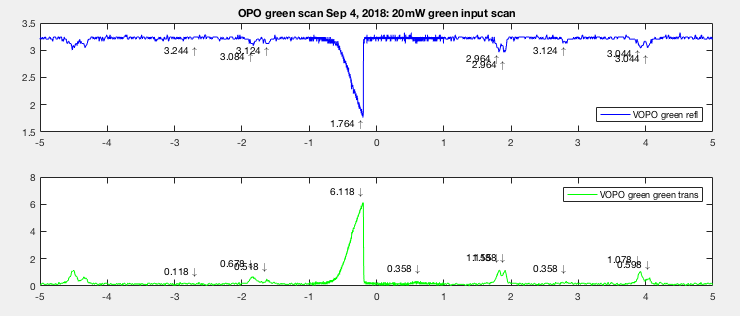
Here's the error signal between the two days. The blue circle indicate where would have been an optimal lock point (around the deepest refl dip and highest trans peak). On Sep 4th we struggled to lock on resonance. The error signal (red) seems nonlinear around the peak and it didn't take a lot of offset to throw the OPO out of resonance once you're there. We often adjusted the OPO offset just by looking at pump refl on StripTool. A lot of times it's difficult to tell if we're really on the resonance and keep moving the offset hoping to see trans becomes lower (or refl become less dippy). But in this case it would just go straight back to off resonance. Temperature change in crystal will throw OPO off resonance too.
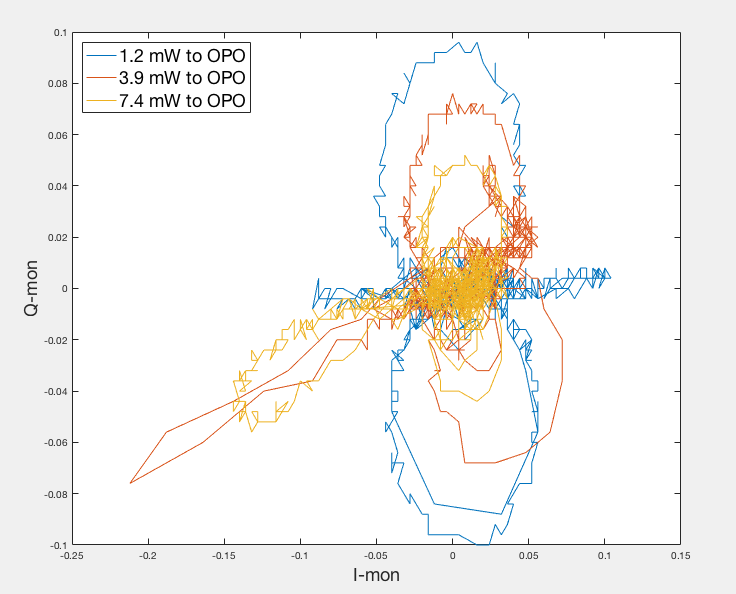
Note that 20mw green input is to the coupler. What refl is seeing is a factor of 2.7 down. So 7.4mW actually went into the OPO. The y-axis is oscilloscope Volt.
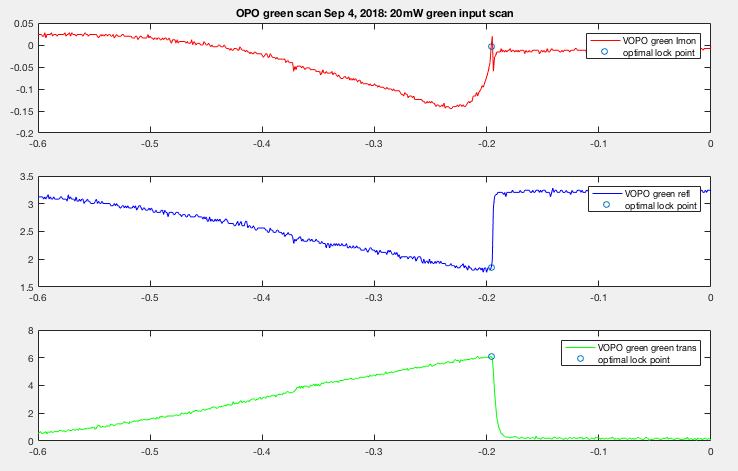
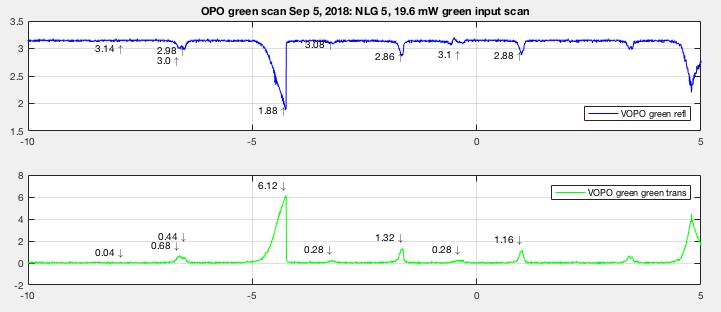
While the signal on Sep 5th seems a bit more linear around the peak transmission. Here we were able to see dip/trans signal become less optimal once I passed the optimal point to the right. This allowed us to go back and lock where we knew we had a resonance. And because of the error signal cutoff wasn't as extreme this allowed room for temperature change, which allowed us to measure high NLG before the OPO is thrown off resonance.
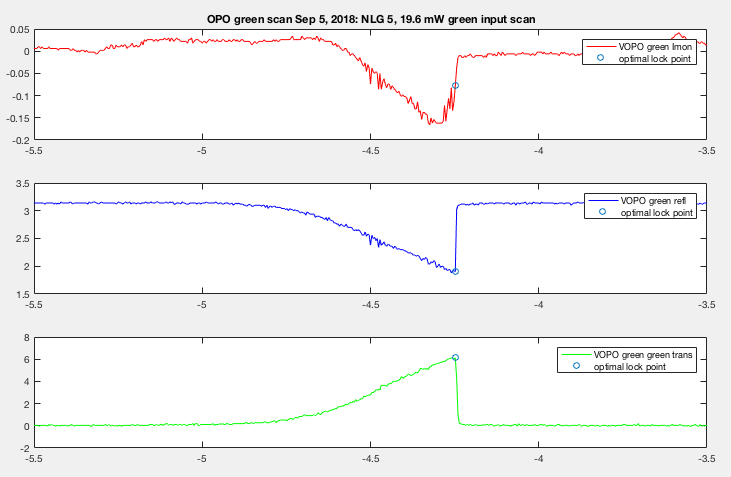
The estimated power loss from Sep 4th was 0.74% (50.89% mode matched), and the estimated power loss from Sep 5 was 0.46% (66.7% mode matched). So somehow on Sep 5 we have a slightly better mode matched compared to Sep 4th but less loss (more power in but less absorption? at this point I assume it comes from crystal absorption). The loss calculation has already taken higher order modes into account.
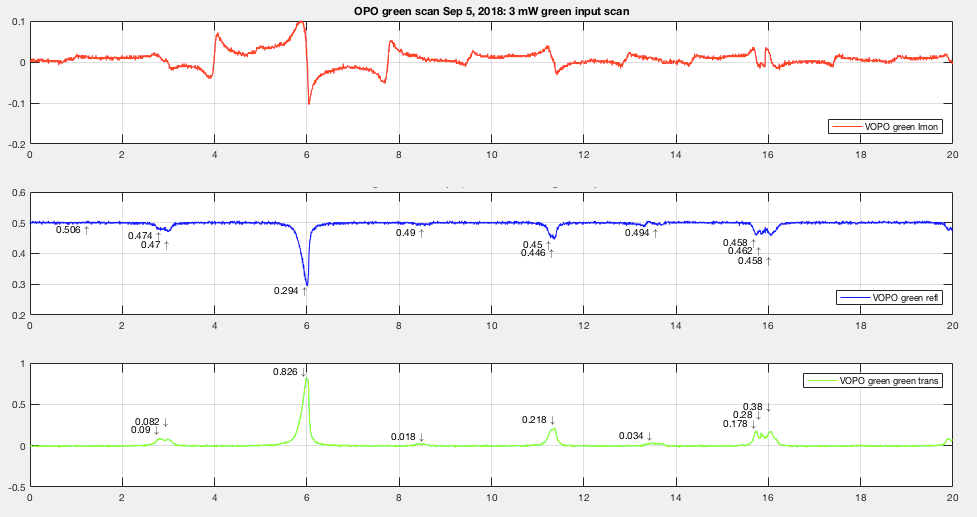
For 1.2mW input to the OPO (3mW input to the coupler) on Sep 5th I got 0.87% loss. There're higher order modes that can't be resolved at higher power so when I calculated loss for lower power I took into account the same number of higher order mode peaks just to be consistent even though more MM peaks became clearly visible. The mode match might actually be worse. I might also have taken into account the sideband which I already included in my code for rloss calculation (I just realized that after did all the calculation). This gives the loss calculation uncertainty another +-.01%. And for 3.9mW input to the OPO (10mW input to cpl) I got 0.57% loss. For how I calculated the loss, see alog43601.
So to answer the first two questions:
1) yes, we can lock at relatively high green power but the offset has to be very precise. And by "can" I don't mean "good". Maybe we have to think of getting an OPO error signal from elsewhere?
2) Yes the loss does change with input power, but it seems to be counter intuitive. at 7.4mW input to the OPO I got .46% loss, for 3.9mW input I got .57% loss, and for 1.2mW input to OPO I got .87% loss. The input power I quoted here is before the MM correction.
I also looked at the data from scanning at the left edge, right edge, and center of the crystal position. At first it seems like we have less loss at either sides of the crystal, but that's just because the mode matching became bad so less power went into the OPO, which probably result in less absorption.
Rob suggested I scan the PZT fast enough just to see if the asymmetry effect goes away (if the asymmetry was caused by crystal heating, it should). Here's the data scanning at 100Hz. The trans PD couldn't respond fast enough but the refl clearly became more symmetry. Sadly the error signal still looks funny. The center of the linear part doesn't line up with the refl dip. We did play around with the phase, it didn't improve the error signal.
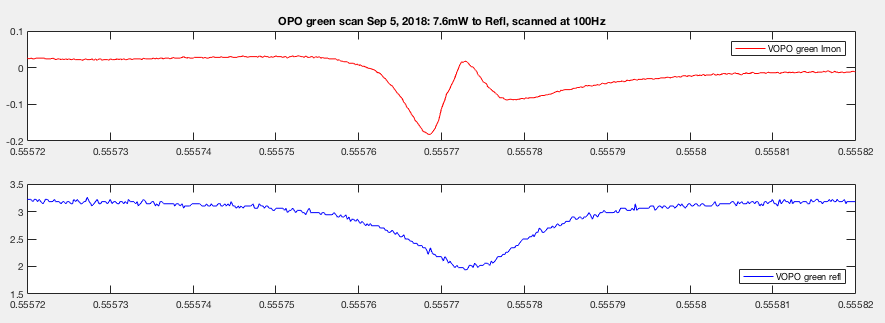
And if I calculate loss using this refl data, using 66.7% mode matched mentioned above, I got .4%, roughly agree with the previous calculation with asymmetry cutoff.
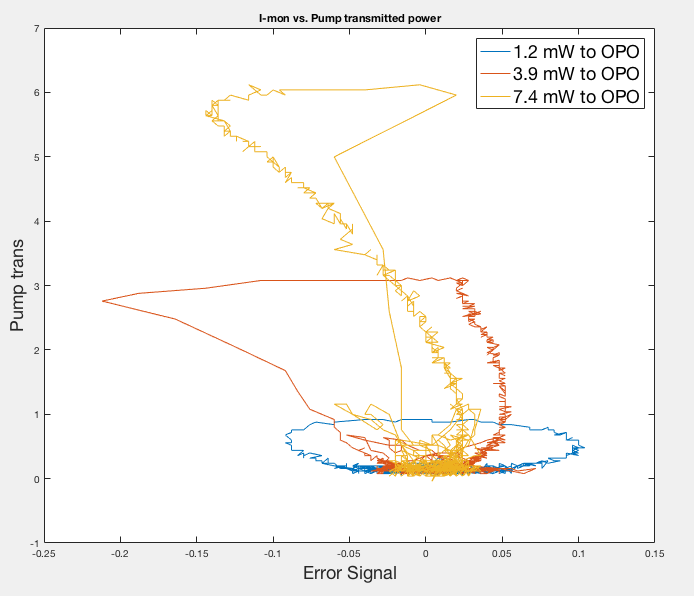
As Sheila requested, here's a plot of transmitted pump power vs. error signal, and IQ plot from Sep 4th data.


We should try a reboot of h1guardian1 on Tuesday.