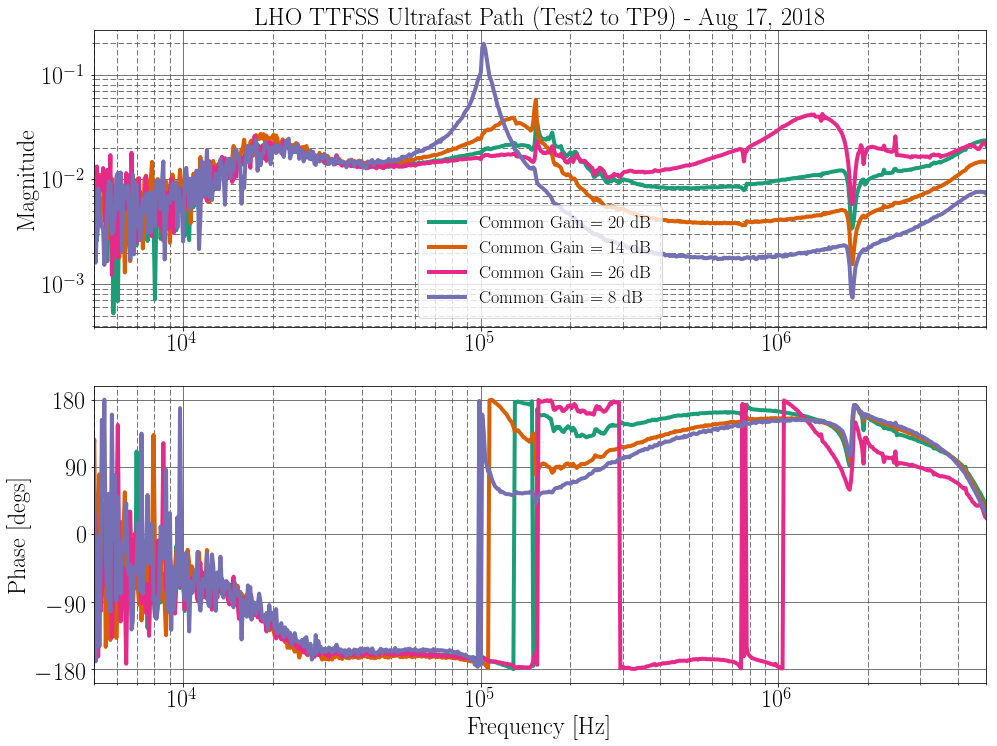
Summary: Previously we detected no contamination of ADC channels by fans or from magnetic fields from the on-board power supply, but saw drifting lines. After powering I/O and AA chassis with linear supplies, the drifting lines were much reduced. There are three remaining more subtle issues: 1) Coherence between blank ADC channels in a 0.94 Hz comb, produced by a flashing LED that indicates link state, 2) A 1.000 Hz comb in the duotone channel that is coherent with some blank ADC channels, 3) An occasional drifting line, that produces coherence between blank channels, suggesting a rouge oscillator in the AA or I/O chassis.
A previous log noted that the new I/O chassis has much lower contamination from fans and power supply magnetic fields than previously tested I/O chassis, but that there were drifting intermodulation peaks, possibly associated with the 24V power from a Sorenson switching power supply ( https://alog.ligo-wa.caltech.edu/aLOG/index.php?callRep=42907 ).
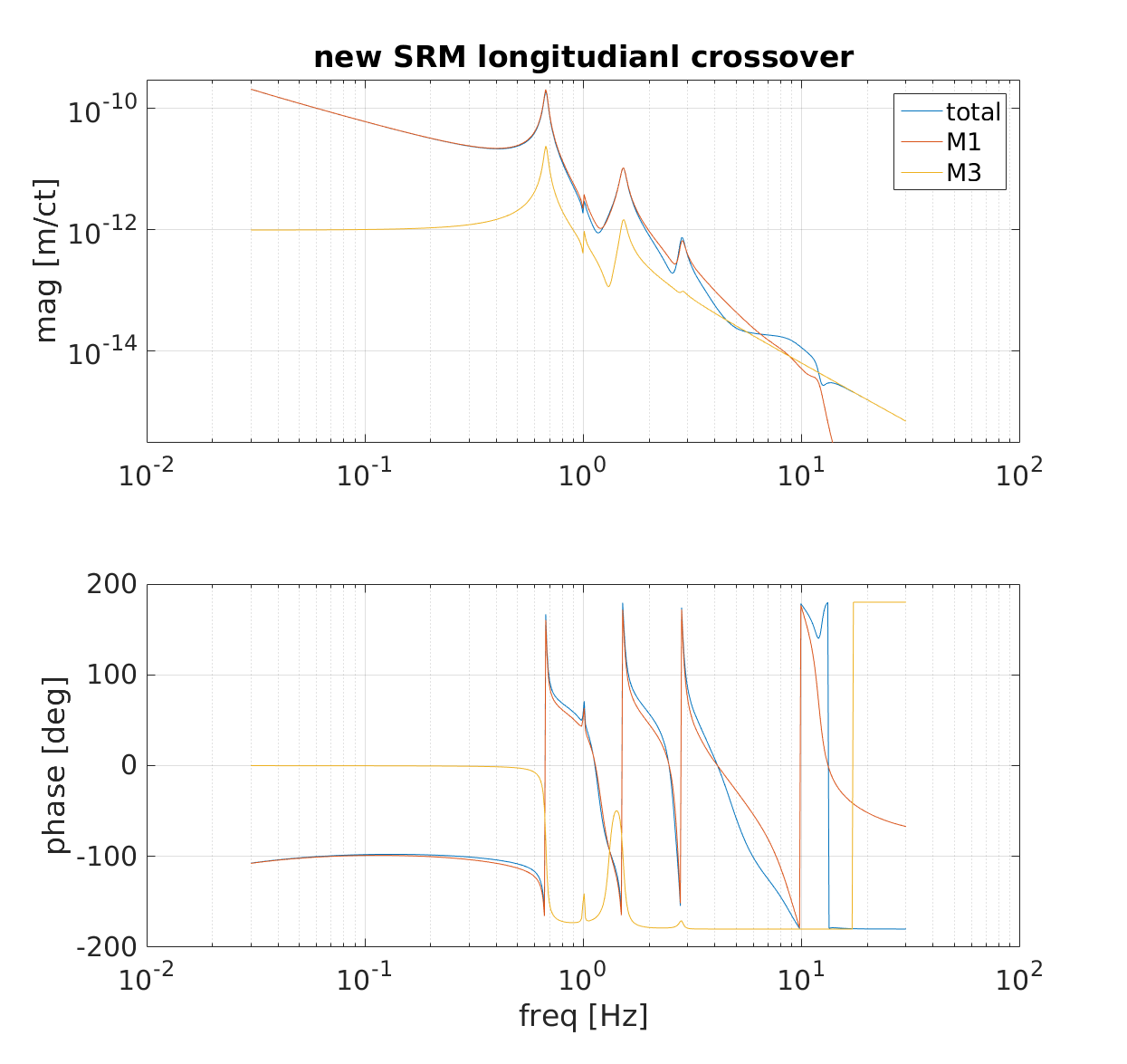
During the DetChar f2f, we powered the I/O chassis with a linear supply and found that the drifting peak features were mostly gone. I have since been looking into more subtle features in the blank channels of the I/O chassis. Figure 1 shows that the blank channel spectra are smoother (no evidence of drifting peaks) and the coherence between channels is significantly less than it was before replacement of the 24V switching supply (compare Figure 1 to https://alog.ligo-wa.caltech.edu/aLOG/uploads/42907_20180715170051_Figure4-CoherenceBetweenEmptyADCChannels.pdf ). But Figure 1 also shows that there are features associated with LED flashes.
The odd harmonic series in the magnetometer signal of Figure 1 appears more strongly in the magnetometer signal when the magnetometer is near to flashing LEDs (link indicators) on the ADNACO-R1BP1B board (photos are also included in Figure 1). The coherence at LED frequencies between the magnetometer and the blank ADC channels reaches 0.1. The blank ADC channels are coherent with each other at the LED frequencies even when there is no magnetometer connected, so the signal on the blank channels isn’t cross talk, and is probably associated with the periodic load on the power supply.
Dave B. notes that if the system were working as expected, the link LEDs should not be flashing.
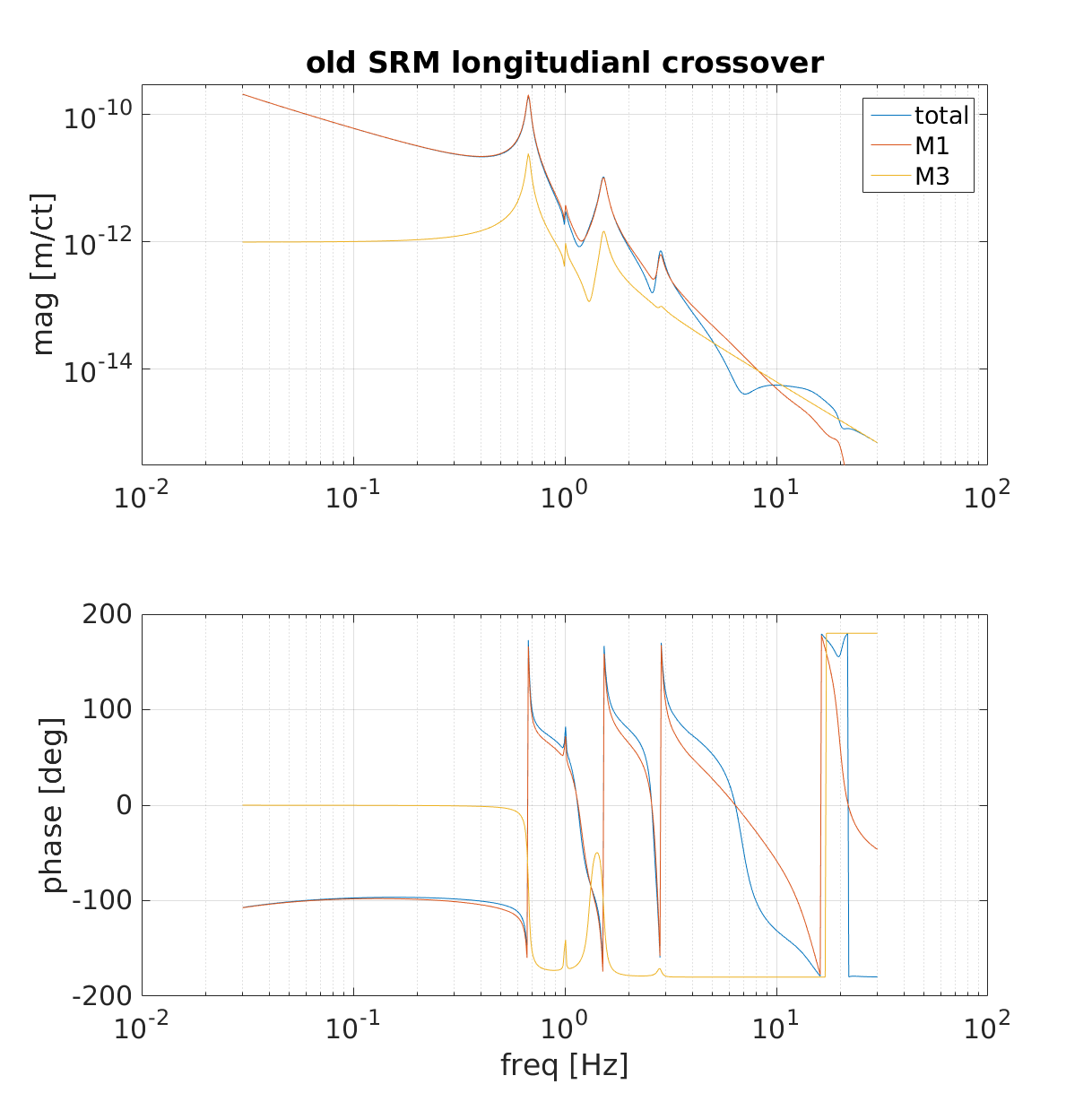
In addition to the near-1 Hz comb, there was also a 1.000 Hz comb. Figure 2 shows that a 1.000 Hz peak, appears strongly (1 count) in ADC channel 31 (the duotone channel), and less strongly in other ADC channels (coherence reaching 0.01). The LED flash peak is also apparent at 0.94 Hz in Figure 2, though all ADC channels are blank. Both peaks have an associated comb, odd harmonics for the LED peak and all harmonics for the 1 Hz peak.
The second page in Figure 2 shows that the duotone signals are at about 10^4 times the size of the 1 count peak at 1 Hz. The direct cross talk of the 960 and 961 Hz lines in, say, channel 15, visible in the power spectrum plot of the second page of Figure 2 at about 4e-2 counts, does not seem large enough to produce the 1 Hz comb in channel 15 through the same 1e-4-scale non-linear mechanism. It may be that the 1 Hz comb on other channels has a different source or mechanism. We might be able to modify the duotone, such as by avoiding the zero cross region, to further study this. Since search groups had problems with1.000 Hz and near-1.000 Hz combs in DARM during O2, I think it is important to understand/eliminate these peaks.
A final issue was that, although drifting peaks were reduced when the I/O and the AA chassis were placed on linear supplies, I found drifting peaks (Figure 3) in a couple of many spectra. I suppose that this peak could be associated with some rouge oscillator in the chassis.
Dave Barker, Sumeet Kulkarni, Philippe Nguyen, Robert Schofield