Peter K, Fil, Danny, TVo
TCS Electronics block diagram: E1100892
Yesterday's trouble with the CO2Y led us to investigating the RF signal chain for the laser. Fil checked that the signal coming from the function generator in the chiller mezzanine is giving us a clean ~40.6 MHz sine wave all the way to the table. However, once it reached a Pulse Research Lab comparator that turns the sine wave into a TTL square wave (or close to one), we found the signal did not match CO2Xs' RF signal and was an odd shape as well, it looked more like a wave packet shape instead of a square wave like we'd expect.
So we pulled the PRL comparator as well as the RF splitter/amplifier box from Access to test the units in the EE lab. In the LVEA, the signals looked terrible but once we tested it in the lab, they seemed to do what was expected. Then we hooked everything back up at the CO2 table and the RF signals looked a lot cleaner, even though we haven't really made any changes!. At this point we decided to try to test out the laser out again but there were still no lasing, unfortunately.
The next steps we're going to try to debug is the RF Driver outputs to the laser, however, there isn't a lot of documentation on how this driver actually works and I'm not sure what we should expect as far as power out but we can try to compare the signals to CO2X for reference and try to narrow down what could be wrong. The drivers and lasers are paired together so if either are broken, we'll need to swap both and re-align the table.
Note to self: We can try to measure the control signals that enable the RF Drive, usually it's controlled by our TCS Controller box via a DB15 cable but we can test that the interlocks and gates are properly enabled with a breakout board directly at the RF driver.










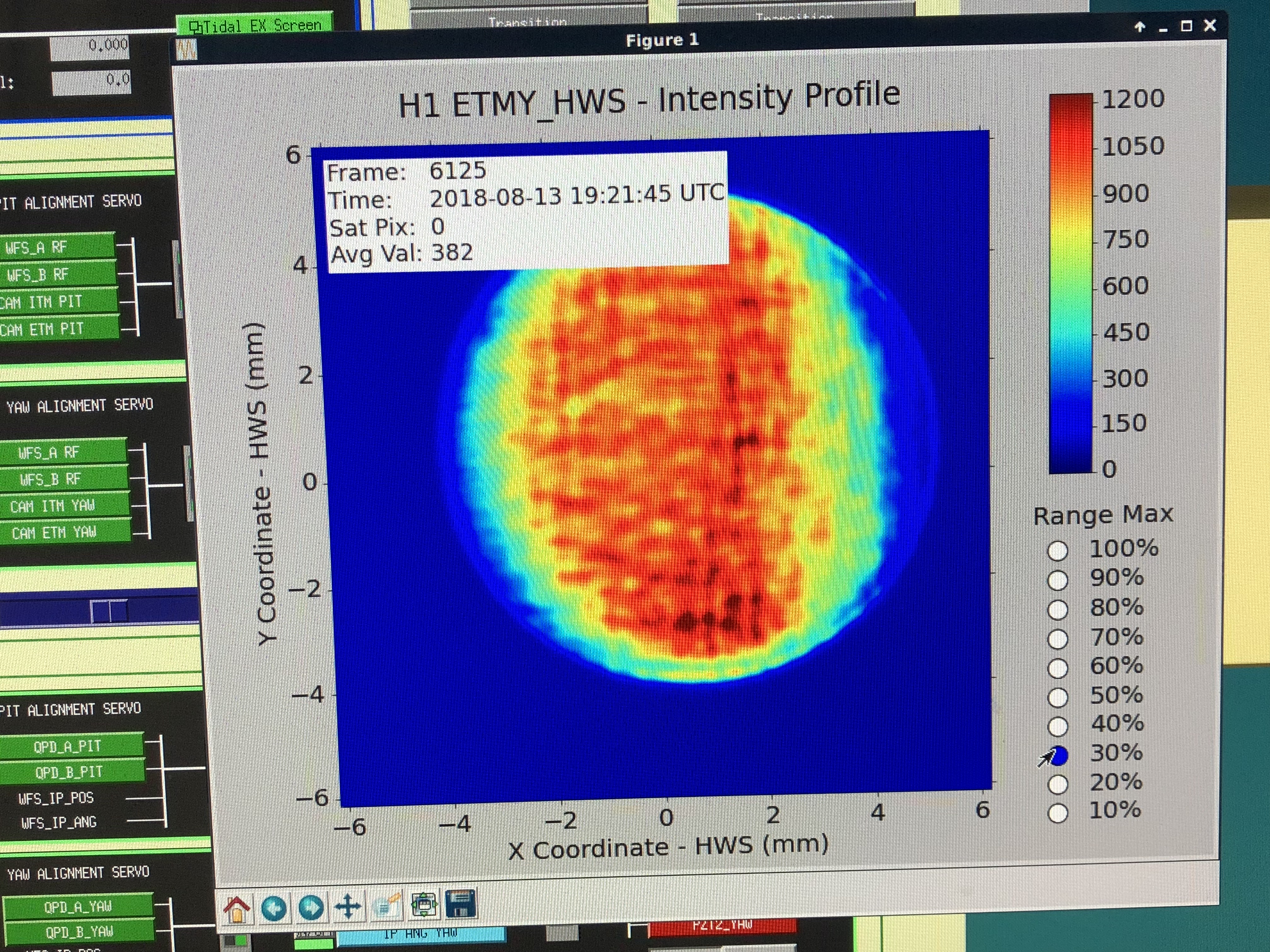
Alastair sent me an email saying that the RF driver and lasers are paired for optimal performance but it will work for the short term in order to diagnose where the issue might be stemming from (laser or driver). Although we're not sure the duration of "short term" in this case but we'll cross that bridge when we get there.
Alastair sent me an email saying that the RF driver and lasers are paired for optimal performance but it will work for the short term in order to diagnose where the issue might be stemming from (laser or driver). Although we're not sure the duration of "short term" in this case but we'll cross that bridge when we get there.