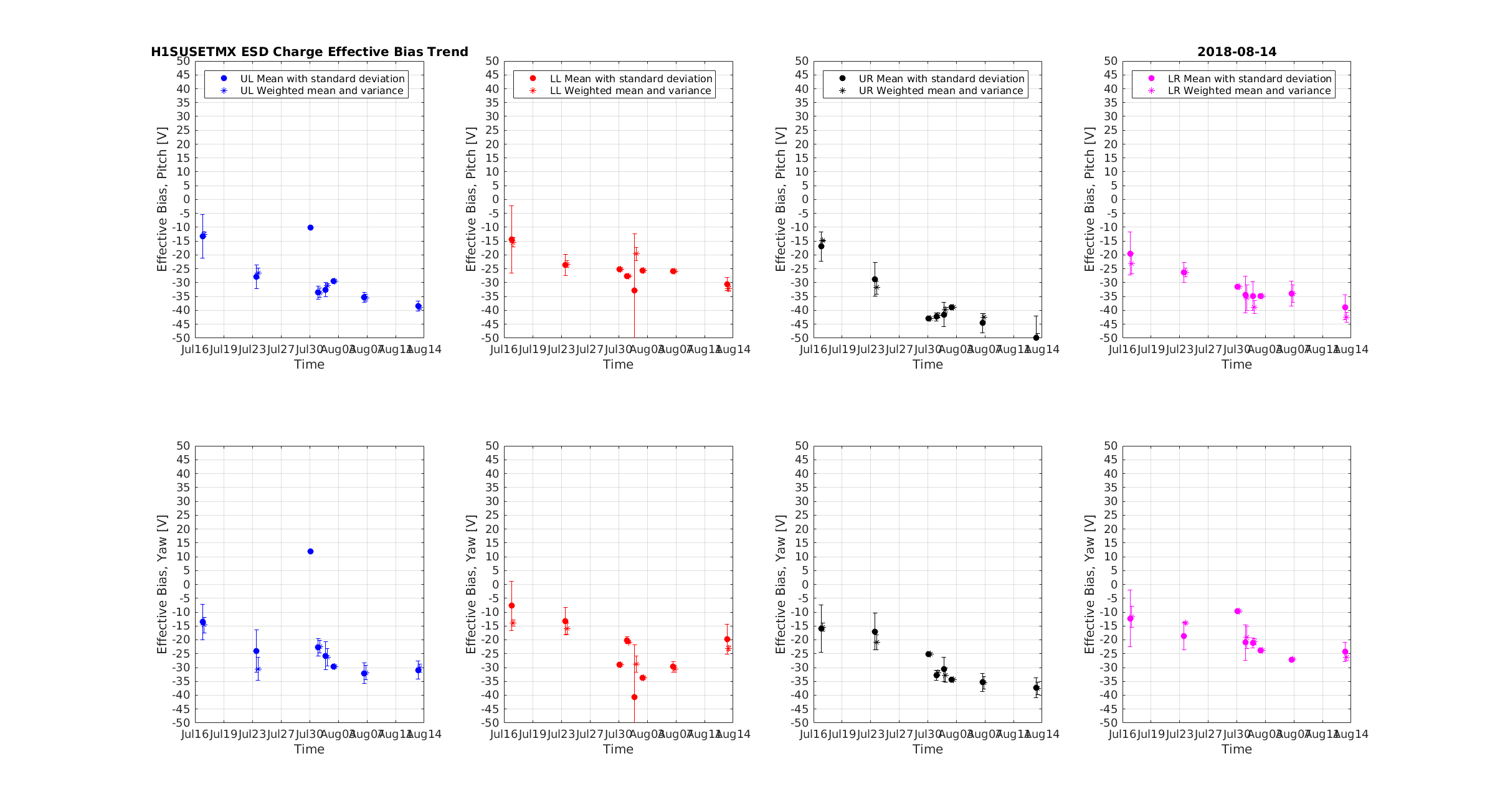
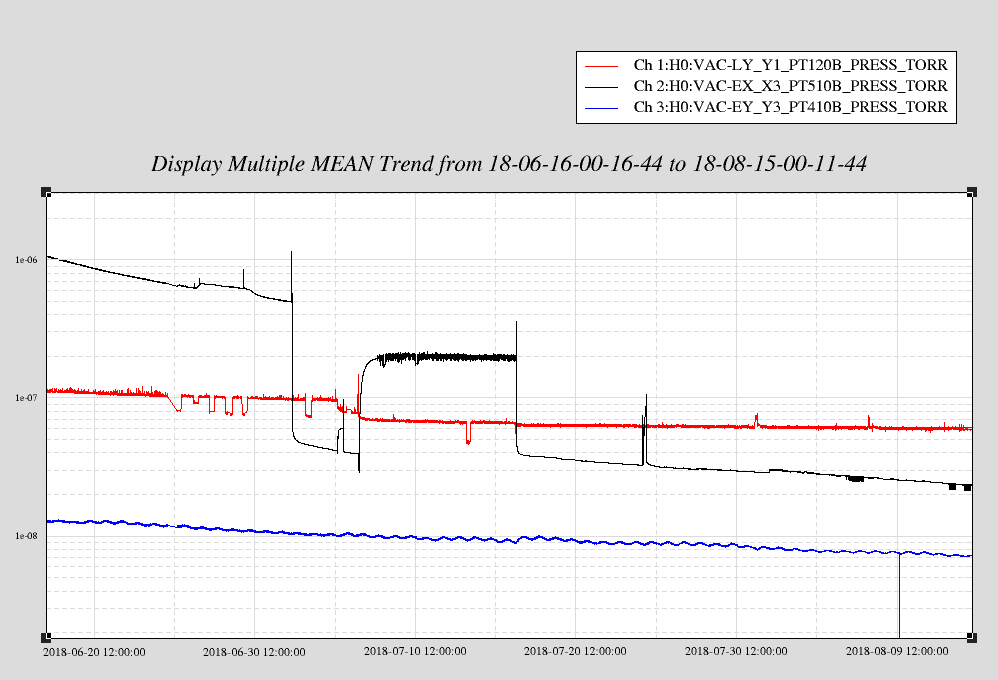
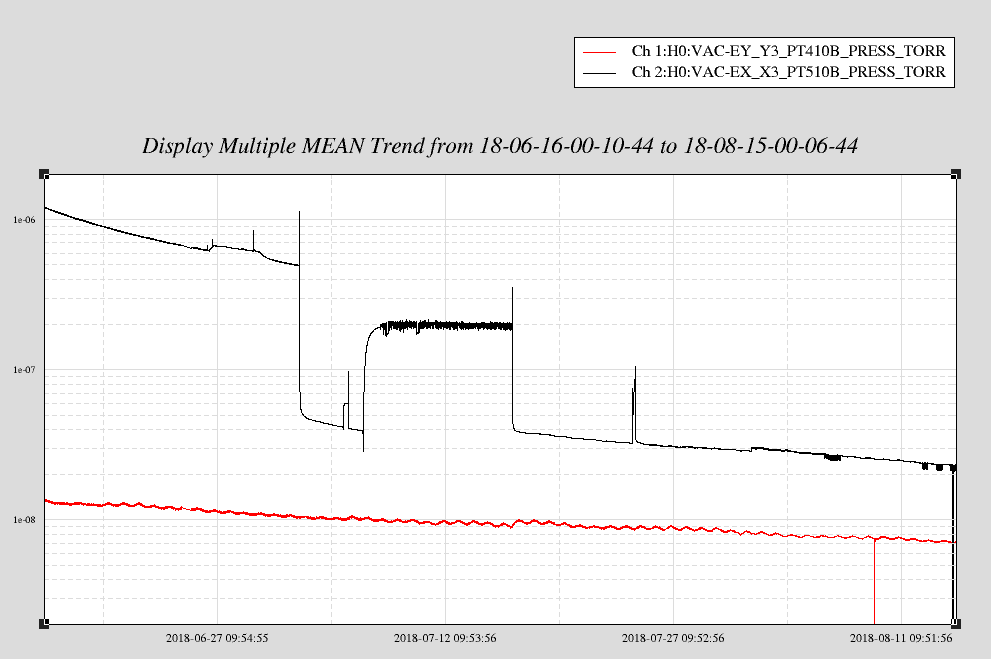
sheila.dwyer@LIGO.ORG - posted 22:19, Tuesday 14 August 2018 - last comment - 10:31, Wednesday 15 August 2018(43433)
fiber polarization box
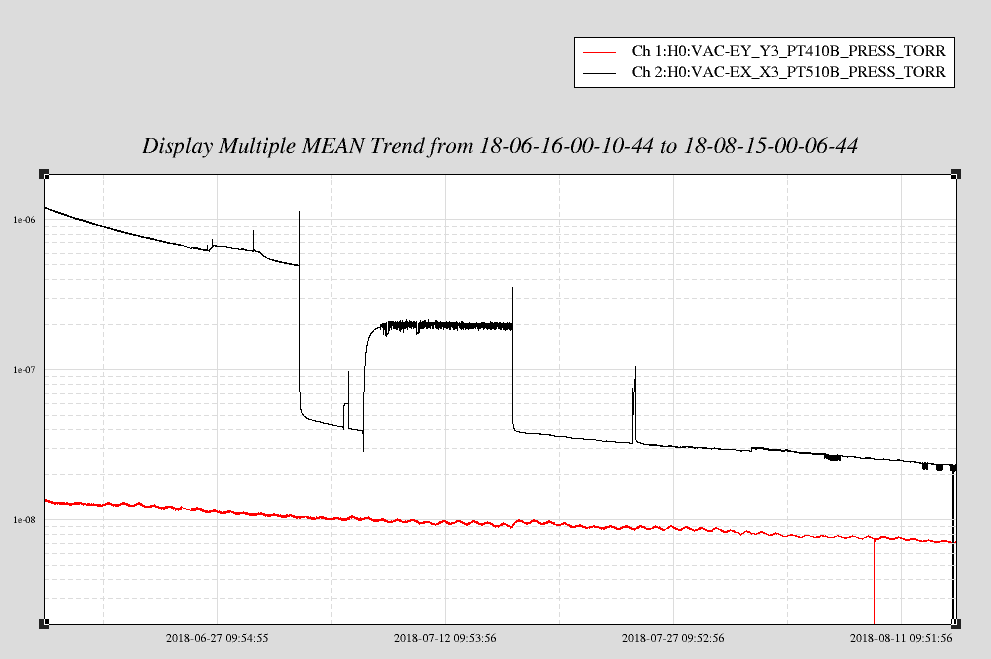
The ALS fiber polarization remote control changes the fiber polarization when it is turned on. In the attached plot you can see the behavior, the box was turned on at the time of the first large step.
I have also had difficulty correcting the polarization using the box.
Also, some of the channel names with it seem to not be in the DAQ (or for some other reason I can't find them in dataviewer). One example is H1:CDS-PULIZZI_ACPWRCTRL_MSR0_OUTLET_1_STATUS
Images attached to this report

Comments related to this report
my bad, I had created the ini file for the remote power channels (H1EDCU_CDSACPWR.ini) but forgot to add it to the DAQ master. It has now been added and will go into effect on the next DAQ restart.
I believe the issue on power up is that it is returning to the last position it was manually set to. From the manual: "When any waveplate is moved manually at the front panel, the MPC1 commits the position to memory within 3ms, thereby, automatically enabling the angular position of all waveplates to be reset on the next power-up. This short interval provides adequate time for the user’s angular settings to be saved in all but the most severe power failure conditions. It is important to note that this memory functionality does not exist, however, when motion commands are invoked via remote control, user entered pre-set programs, or the scramble mode. The resolution is also not saved in memory – on power-up it will be set to the default 0.15° per tick." This is not immediately seen on the medm screen because the position is not periodically polled. It is only polled after a remote positioning command is sent or if the 'Update' button on the medm screen is clicked.
I chose not to have it periodically poll the positions of the paddles, because there is no way for the software to know if the MPC is powered off, and if the MPC is powered off then the periodic polling would constantly report a communication timeout error.