sheila.dwyer@LIGO.ORG - posted 20:25, Friday 25 May 2018 - last comment - 14:35, Tuesday 29 May 2018(42197)
More PRMI work
Thomas, Sheila, Jenne, Keita
We locked PRMI tonight, and we think that we are satisfied enough with the rephasing to move on. Fixing the phasing means that we no longer have an unexplained drop in the PRCL optical gain.
- Yesterday afternoon Betsy came to talk to us about the alignment of ITMX. Betsy had used the optical lever as a reference to align ITMX to before and after the AMD installation. We looked at trends and saw that she had changed the pitch alignment bias by -320 urad to get the same pointing on the oplev after the AMD installation as before. We are currently locking PRMI with the ITMX‌ slider -315 urad compared to what it was after the X arm peak in Feb, but this is probably within the precision of how well we have kept the reference. (Alignment screenshot attached)
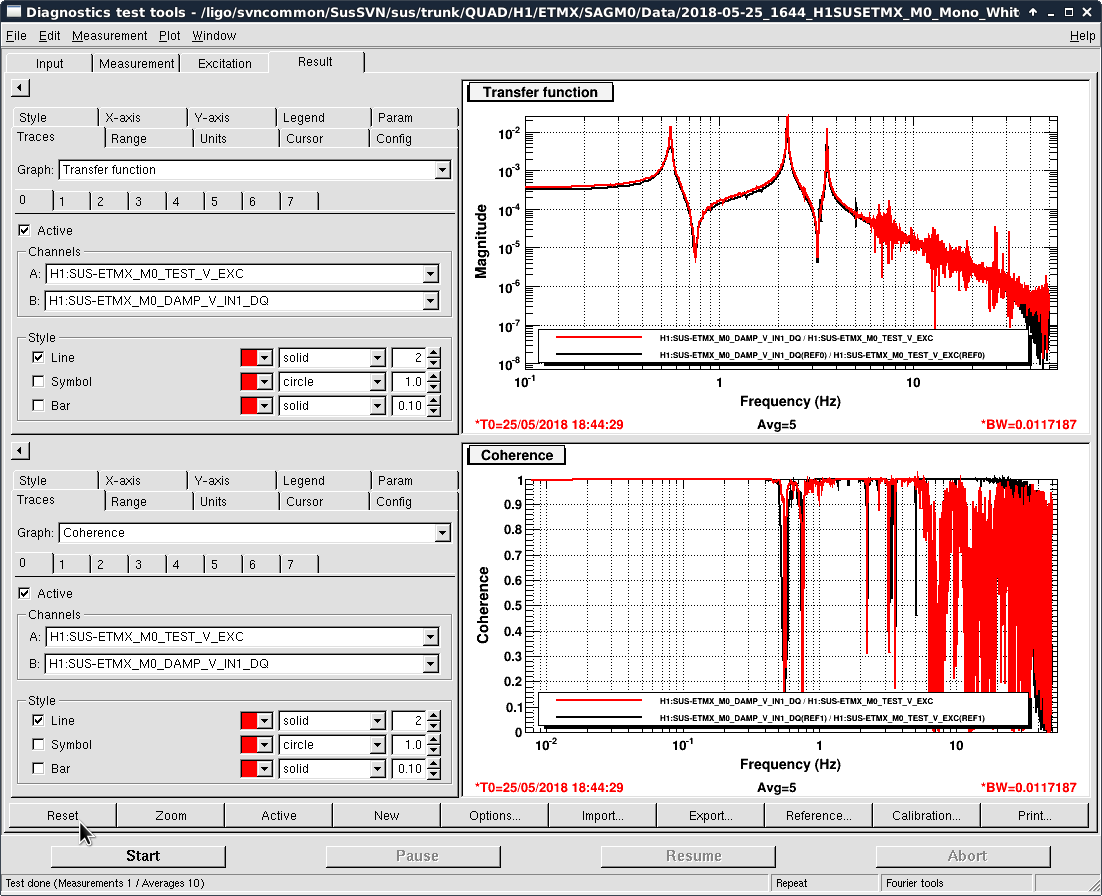
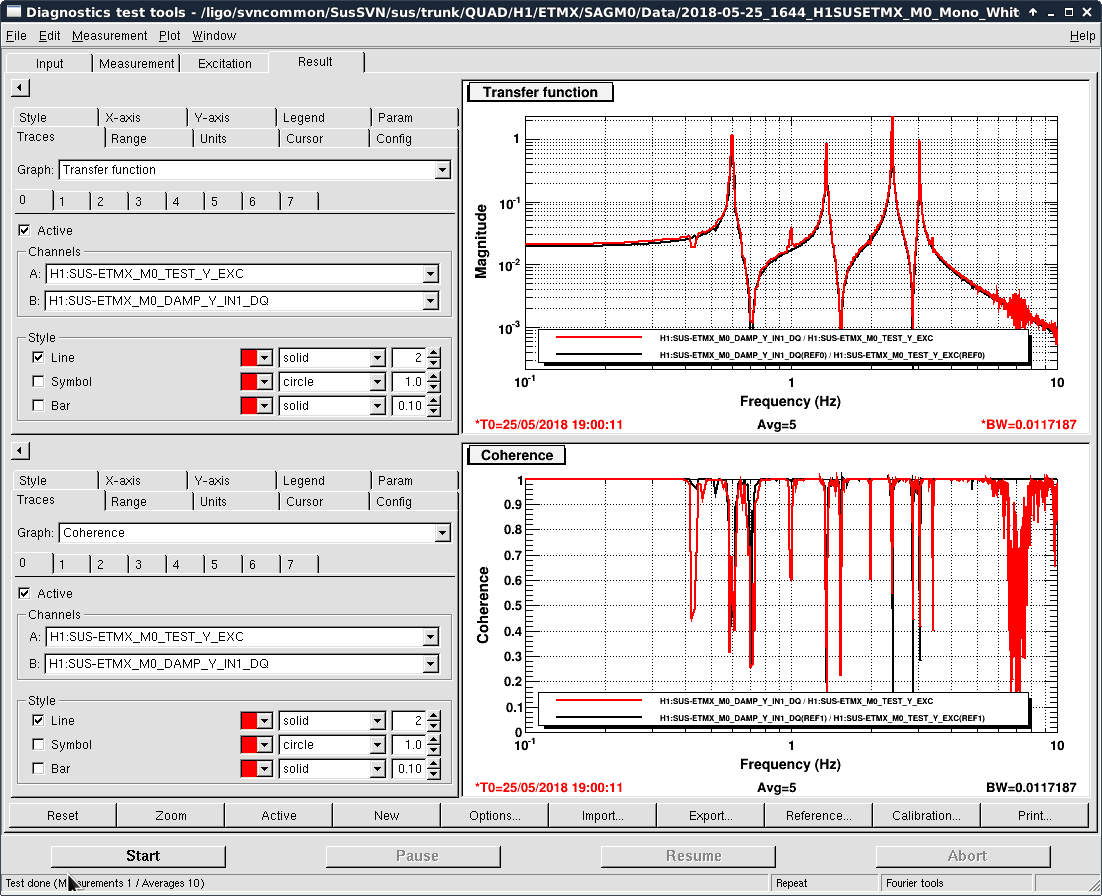
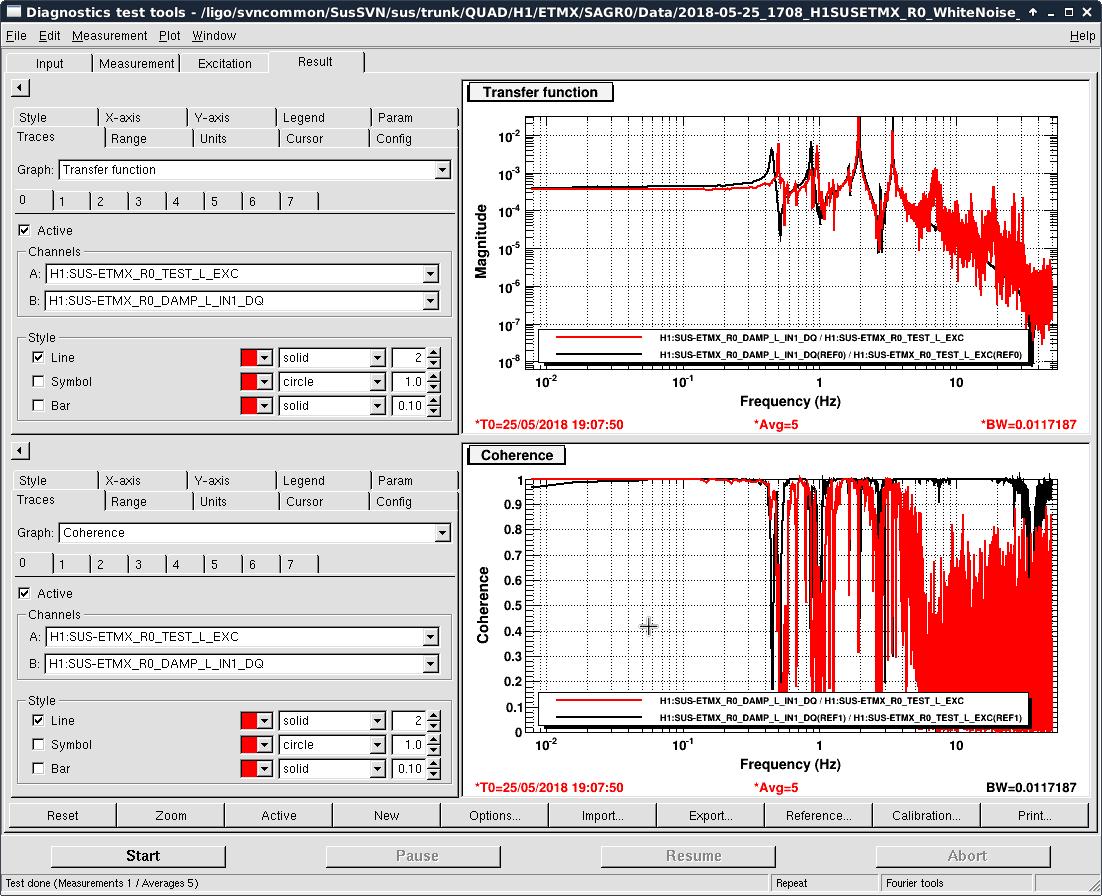
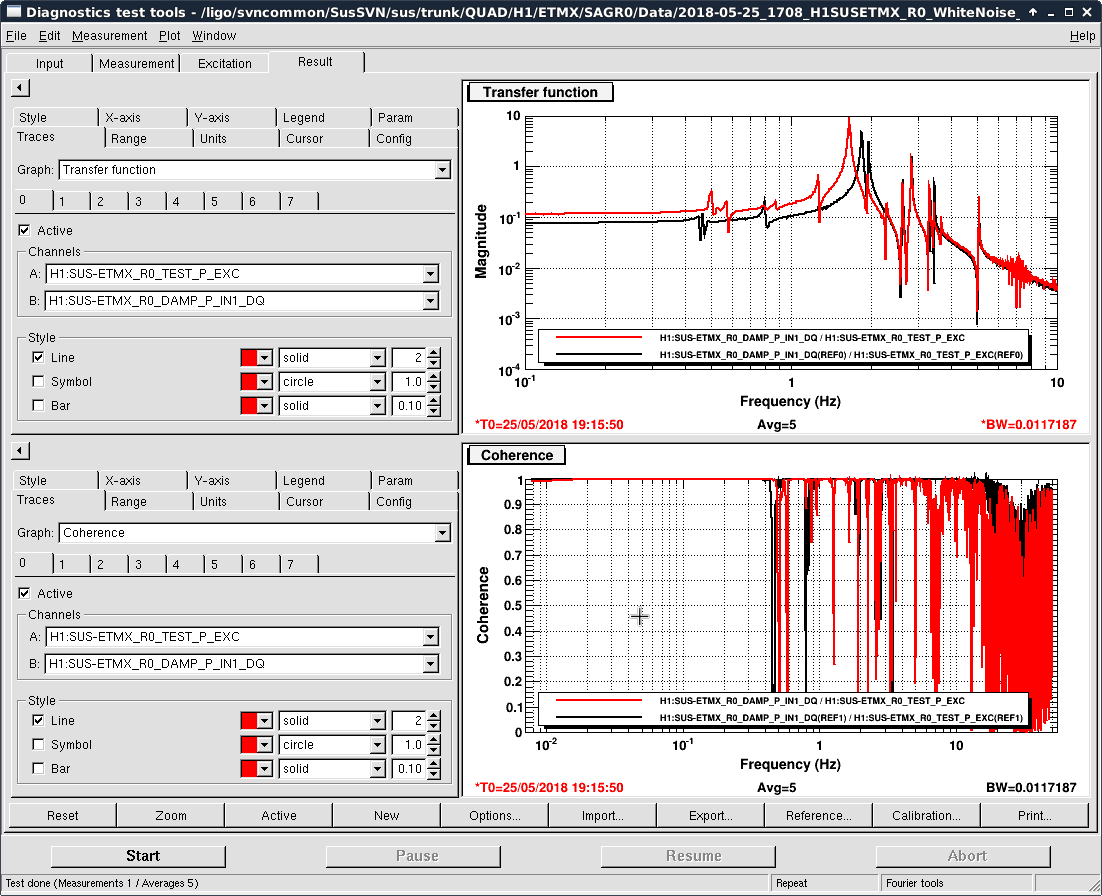
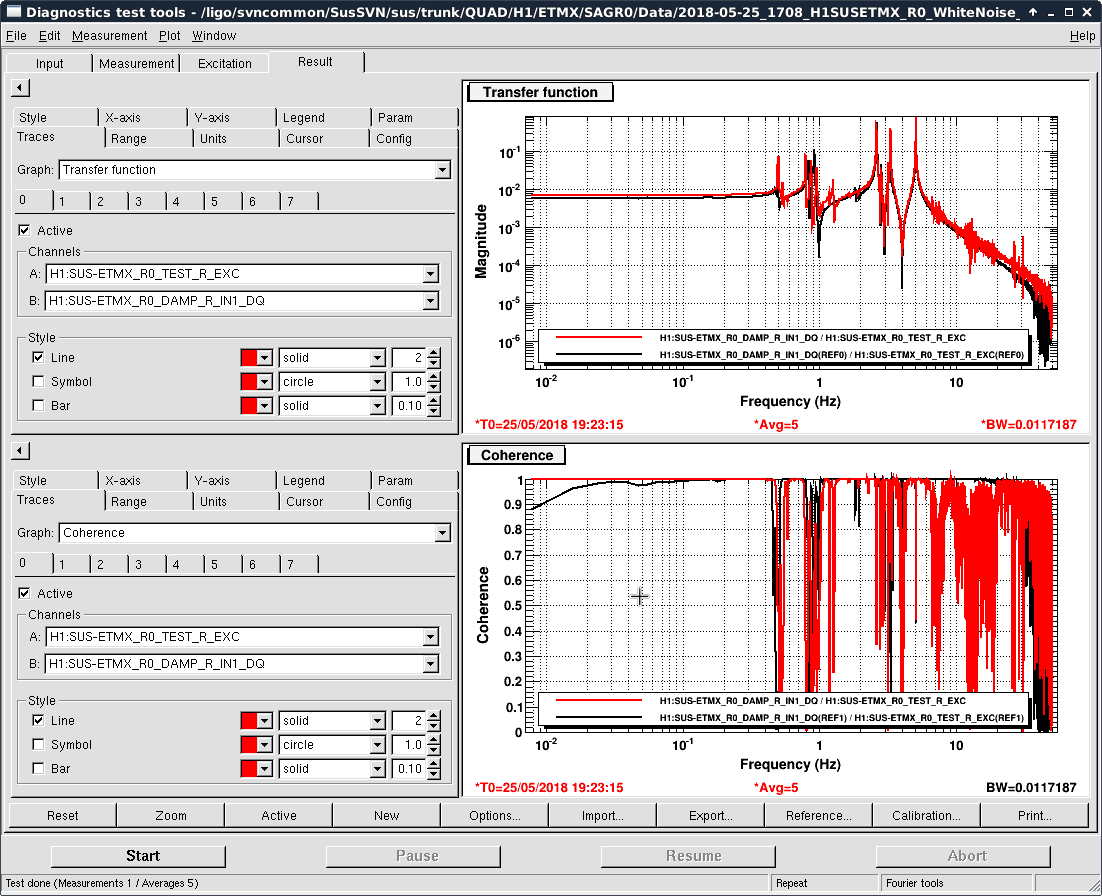
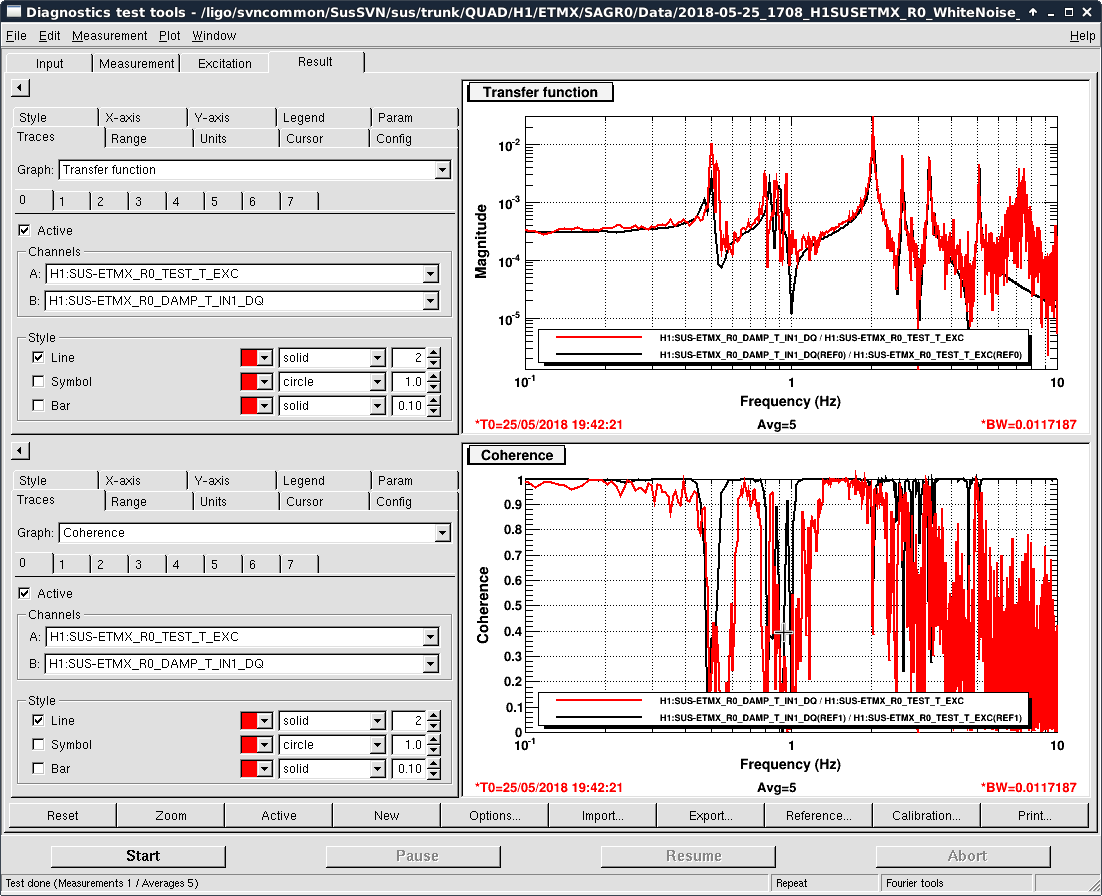
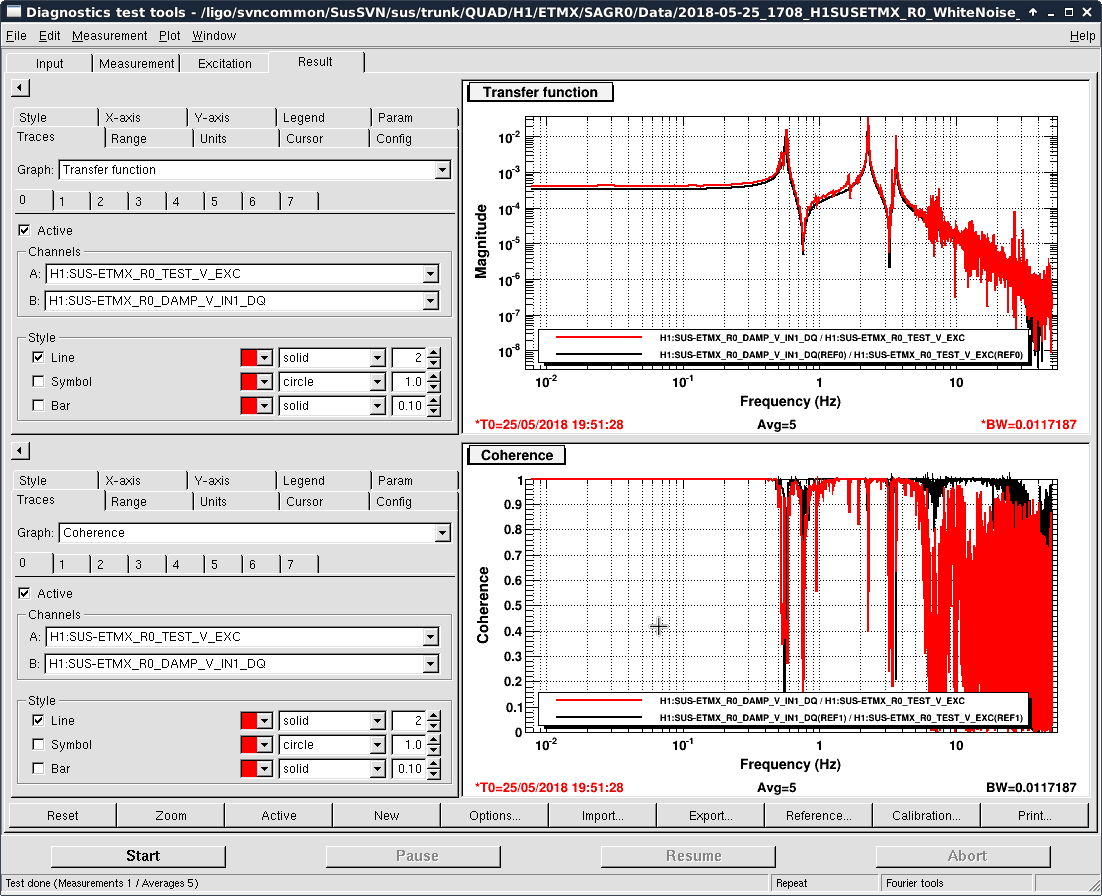
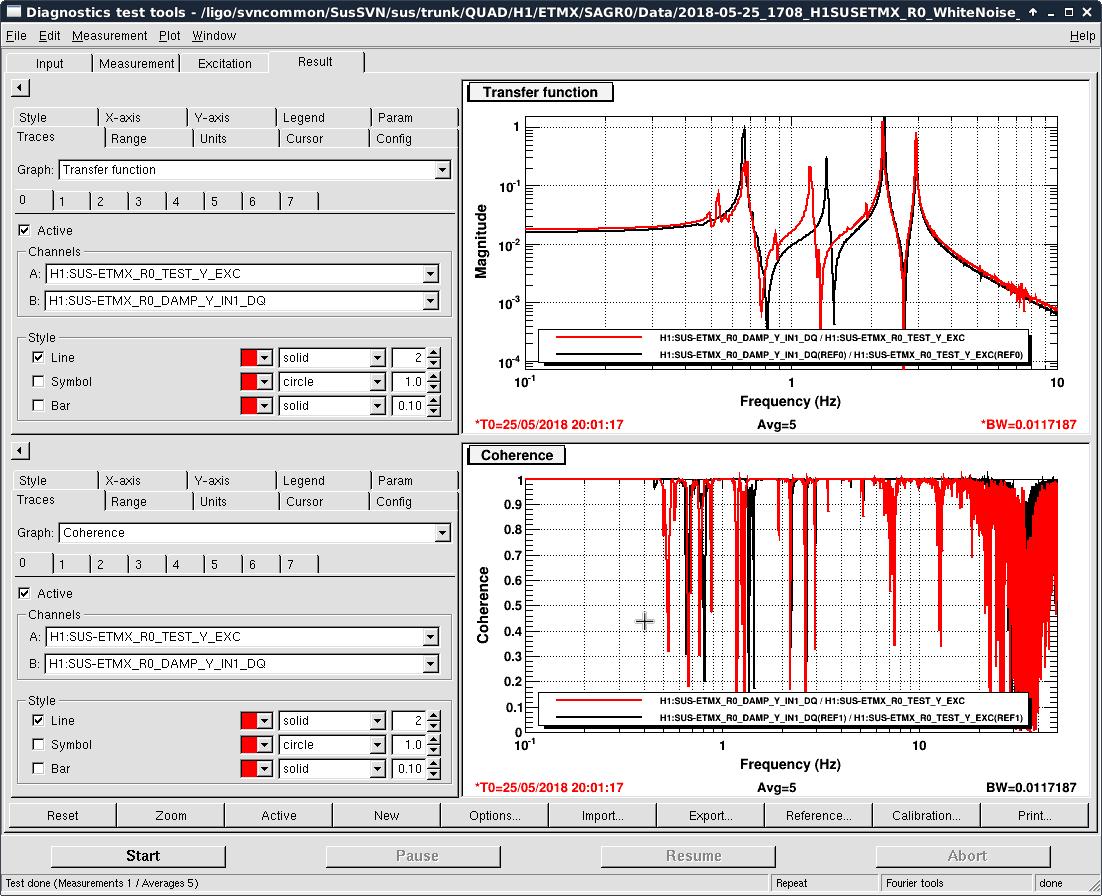
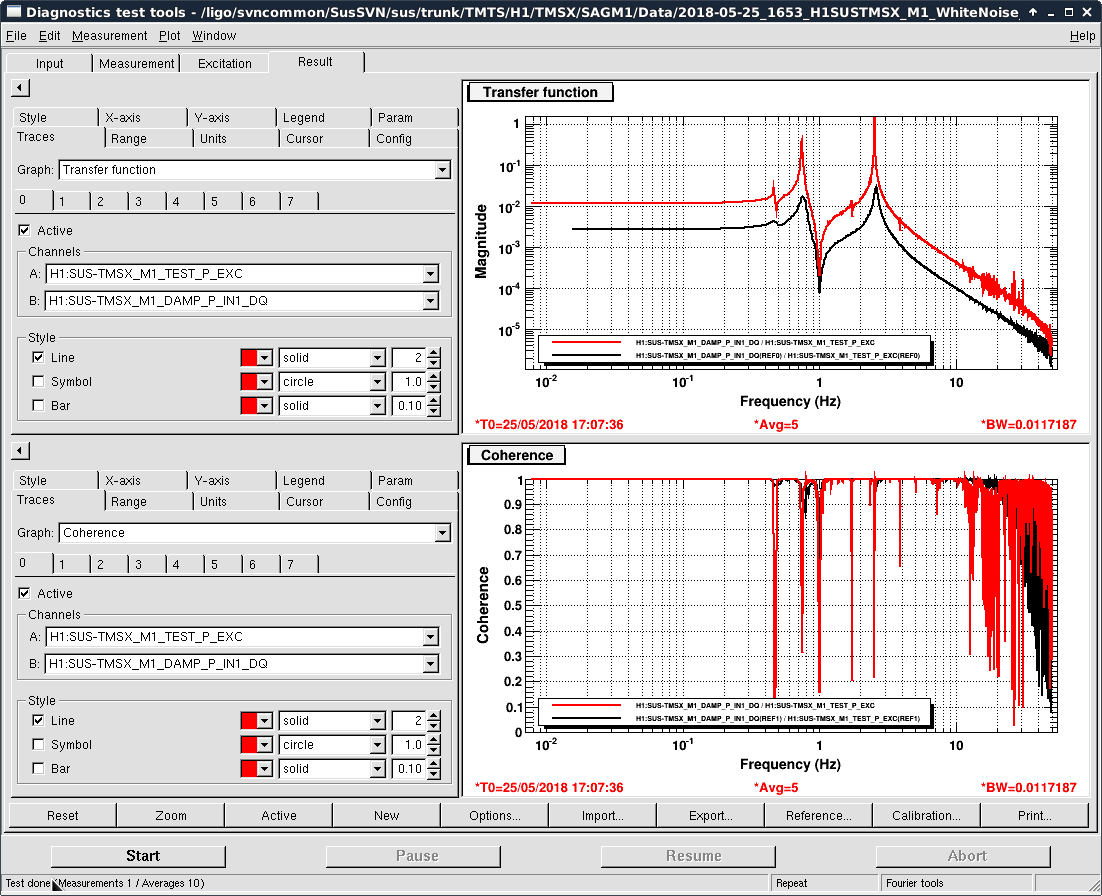
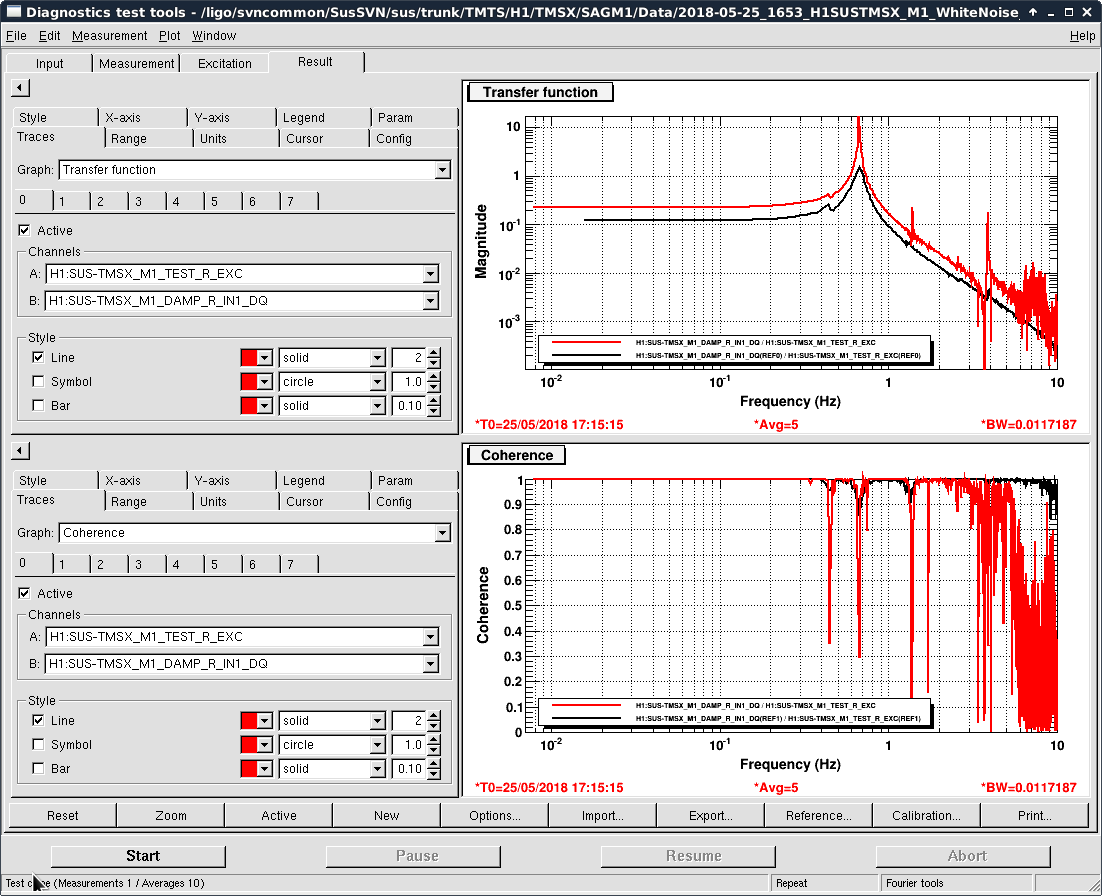
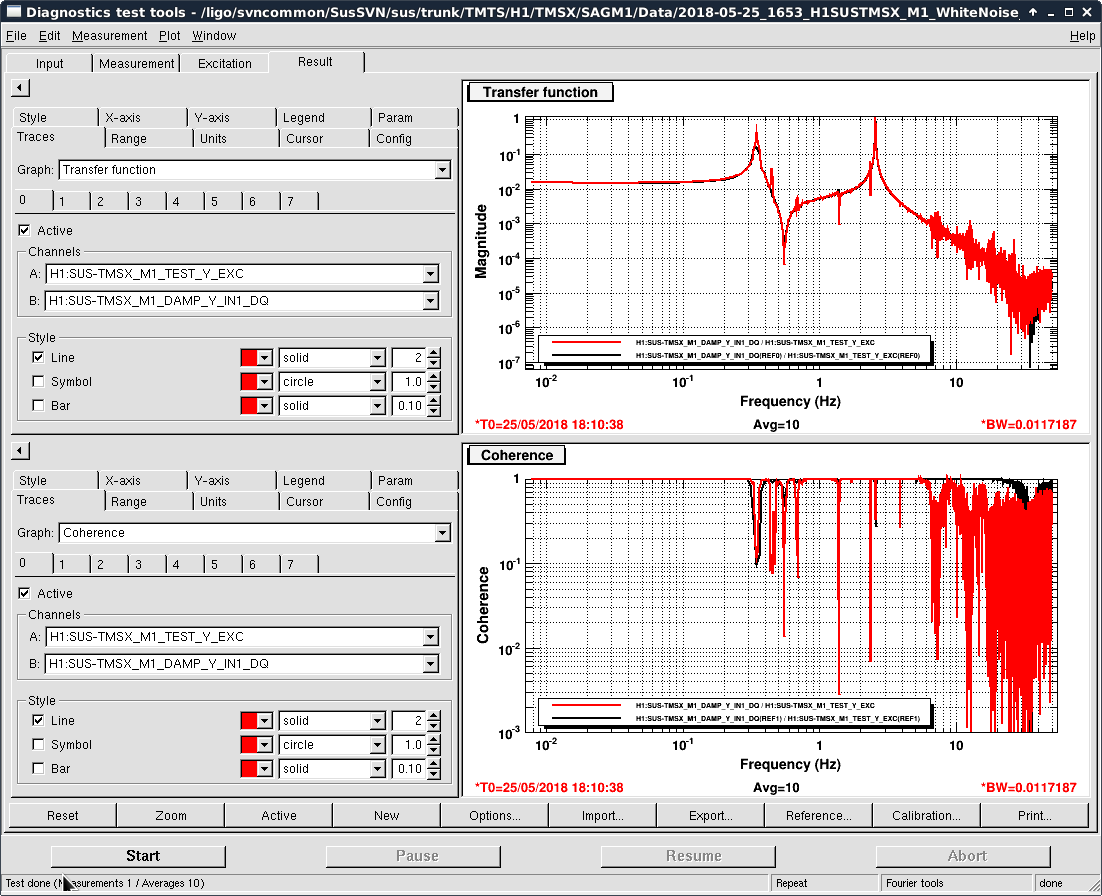
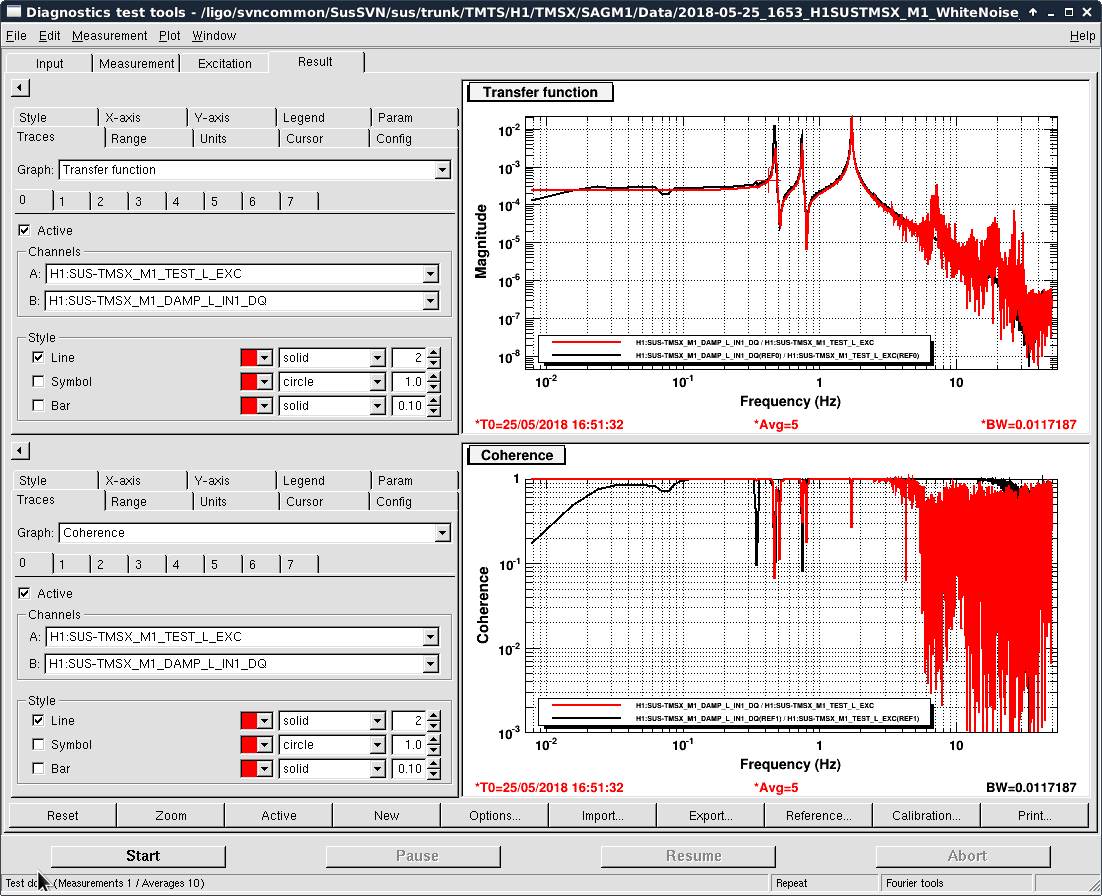
- Thomas and I phased the diodes with PRMI locked by driving PRCL at 138 Hz with a notch engaged in both MICH and PRCL loops. We phased both REFLAIR 9 and REFLAIR 45 to minimize the Q signal from the PRCL drive. For 9MHz, this required a net phase shift of +40 degrees (in agreement with what Jenne found using PRX (41962). For 45 MHz, we found a net phase shift (compared to before the EOM swap) of +51 degrees, which is intermediate between what Jenne had found and what Thomas and I found using MICH on Wednesday.
- Once Thomas phased REFLAIR9, the gain of the PRCL is back to normal (ie, the UGF looks good with the gain that we used before the EOM swap). We don't have an explanation for why the gain for REFL 45 needed to be increased, although it could be that this setting was not well tuned for PRMI before the EOM swap.
- Thomas has found the beam on AS_C with PRMI locked.
Next steps:
- Walk the alignment of PRM, PR2 and MICH to try to maximize build ups and see how our build ups compare to a past time when PRMI was locked without arms.
- Figure out how to accept changes to AS_A_RF45 settings in SDF
- Get AS AIR camera signal in control room
- Alignment of SRC
- Check beam at AS AIR using a card, scan SR2 to center in the aperture from SR2 to HAM6 (the SRM baffle and OFI).
- pico AS_C if necessary to center on AS_C
- possibly painful step, close centering loop on SR2 from AS_C, walk SR3 to center on SR2 keyhole baffle
- Align SRY, check if SRM is still at edge of T2 osem
| May 14th change | May22nd | May 23rd | May 25 | final value May 25th | |
| POP45 | none | no change | -60 | -51 | 16.1 |
| REFL45 | -36 | -40 | -100 | -51 | -64 |
| POPAIR45 | none | none | -60 | -51 | -89 |
| REFLAIR45 | no net change | none | -60 | -51 | 91 |
| REFLAIR135 | none | none | +180 | -153 | 133 |
| POP90 | none | none | -120 | -102 | 24 |
| ASC ASA+B 45 | -40 | reset to 0 | -60 | -51 | |
| ASC REFLA+B45 | -40 | rest to 0 | -60 | -51 | |
| ASC POPX RF | -40 | reset to 0 | -60 | -51 | |
| POP9 | none | none | +75 | +60 | -32 |
| REFL9 | +60 | +59 | +59 | +60 | -29 |
| POPAIR 9 | none | none | none | +60 | -56 |
| REFLAIR 9 | none | none | none | +60 | -30 |
| REFLAIR 27 | none | none | none | +180 | -80 |
| POP 18 | none | none | +146 | +120 | 12 |
| ASC REFL A+B 9 | +60 | reset to 0 | none | +60 | |
| AS A+B 36 | none | none | none | +9 |
Images attached to this report

Comments related to this report
Further to do:
- Move the REFL9 phase shift to the delay line board. Since the REFL servo is analog, the REFL9 phase needs to be 0 or 90.
For the SDF of AS_A: In order for the AS_A_RF45 WFS to run faster than 2k (the rate of the regular ASC model) for use with locking without dealing with the IOP model, we have put AS_A_RF45 into the ASCIMC model (which runs at 16k). This means that AS_A_RF45 SDF settings should be accepted into the ASCIMC SDF.
For now, I have accepted the dark offsets and the phase of the AS_A_RF45 segments.