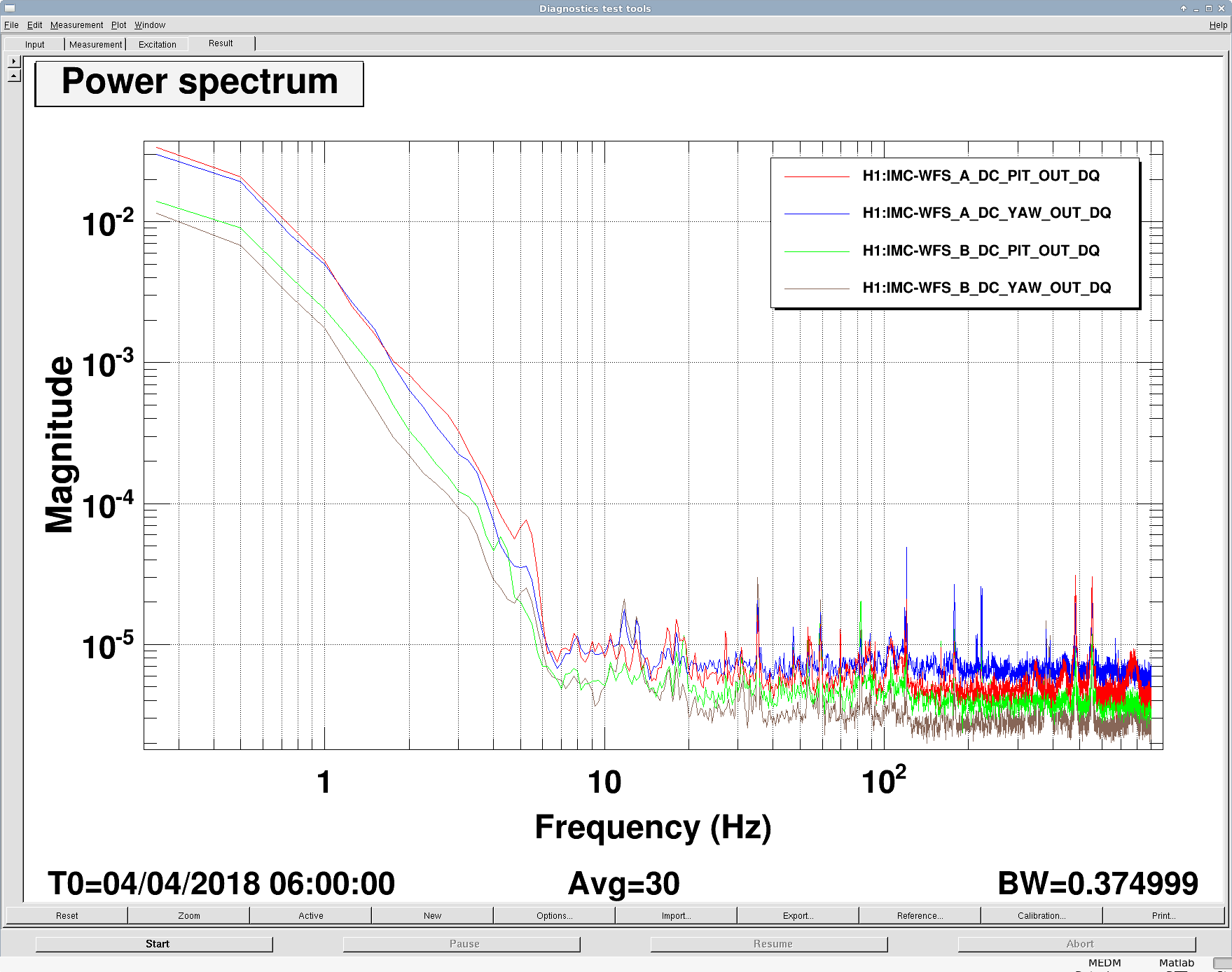
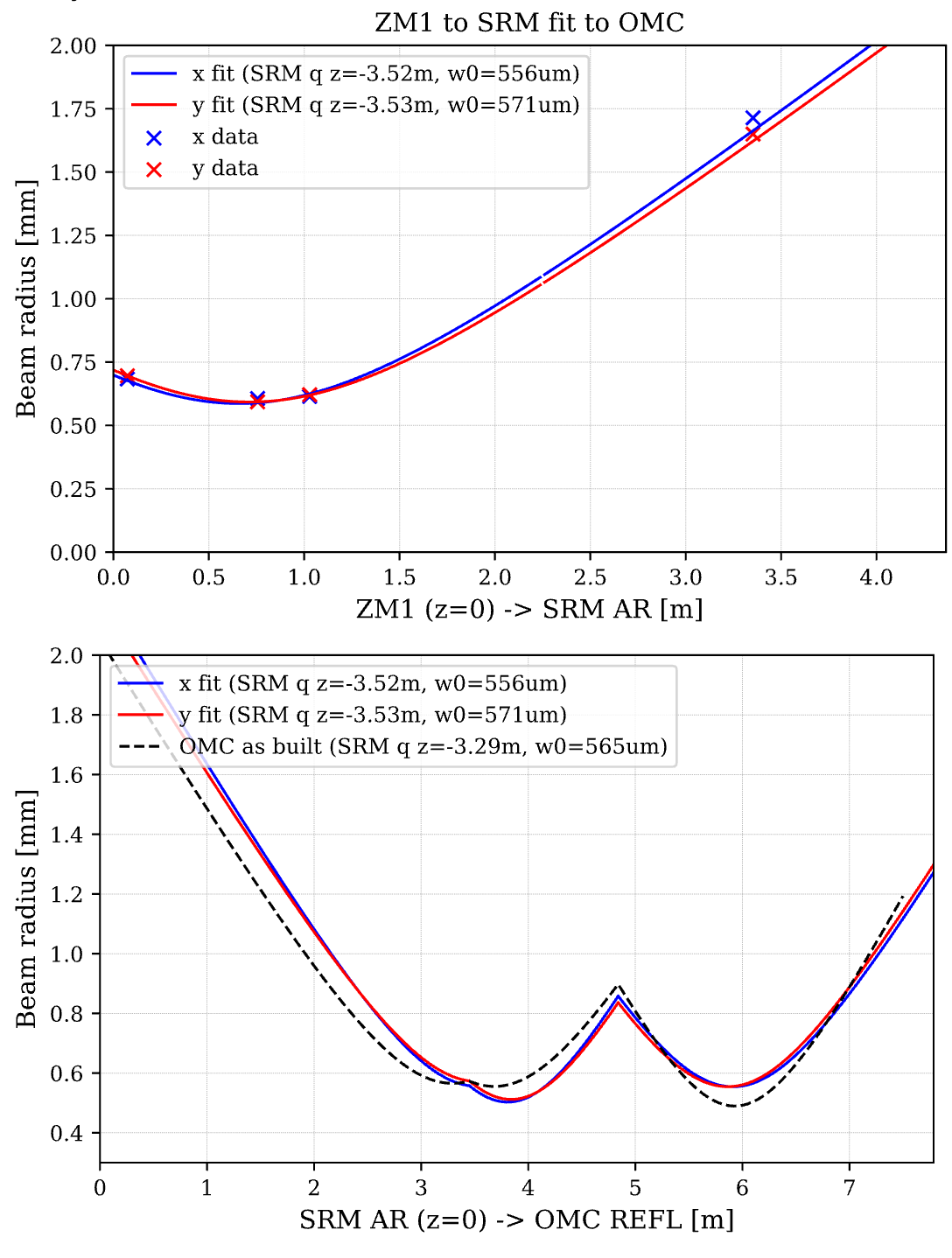
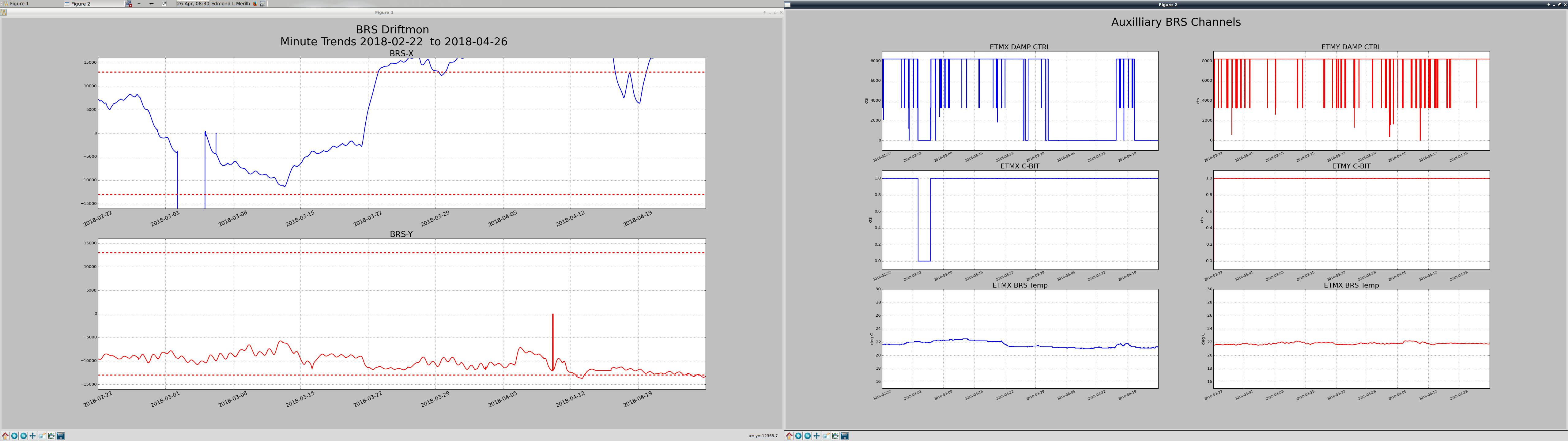
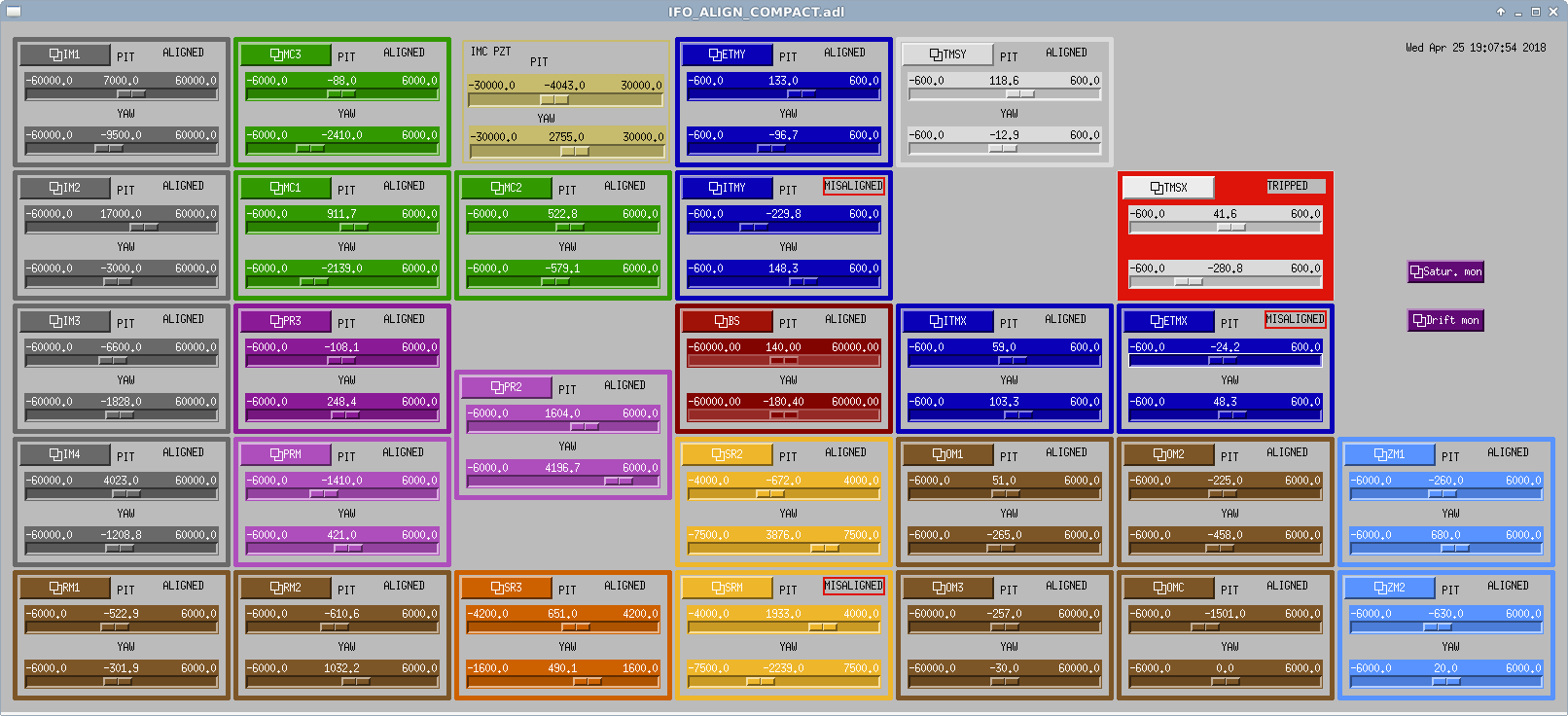
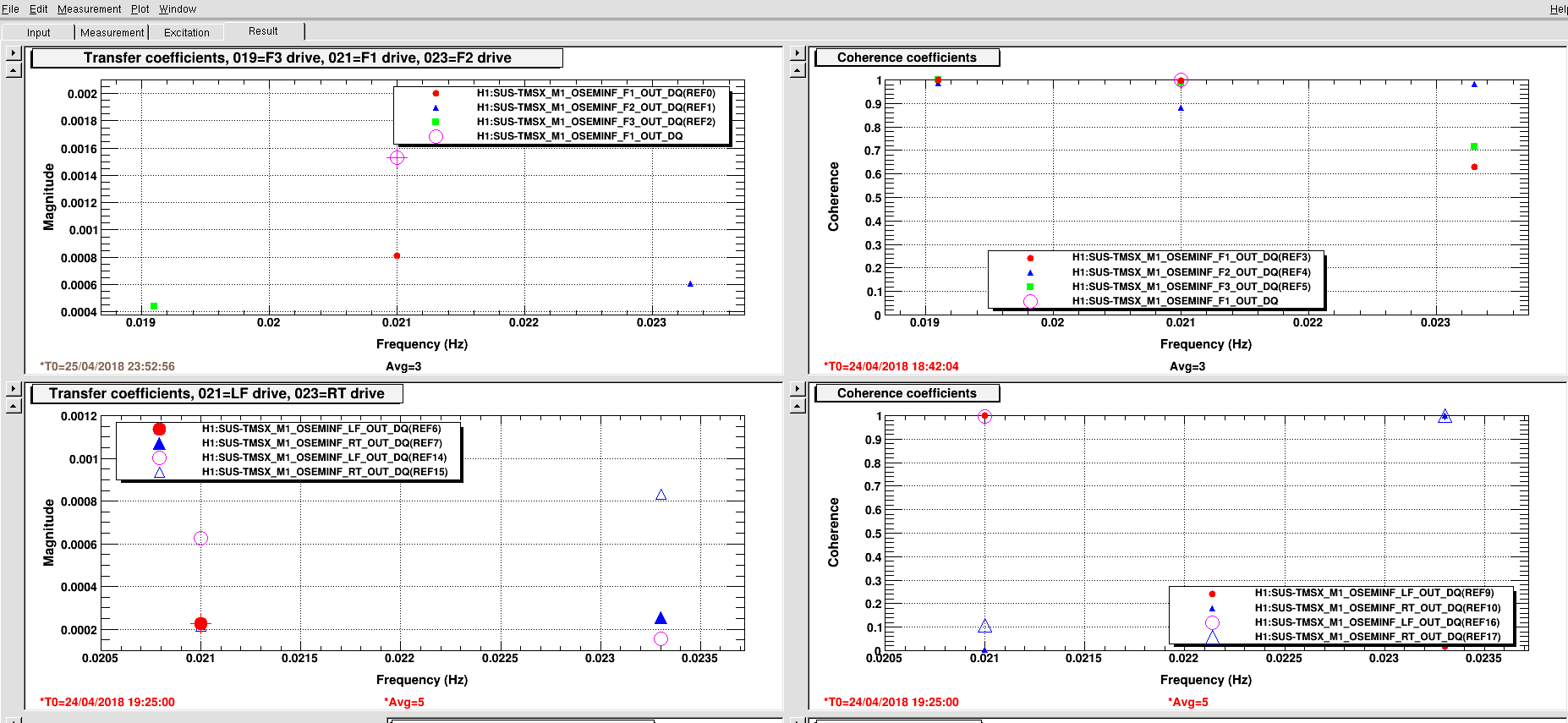
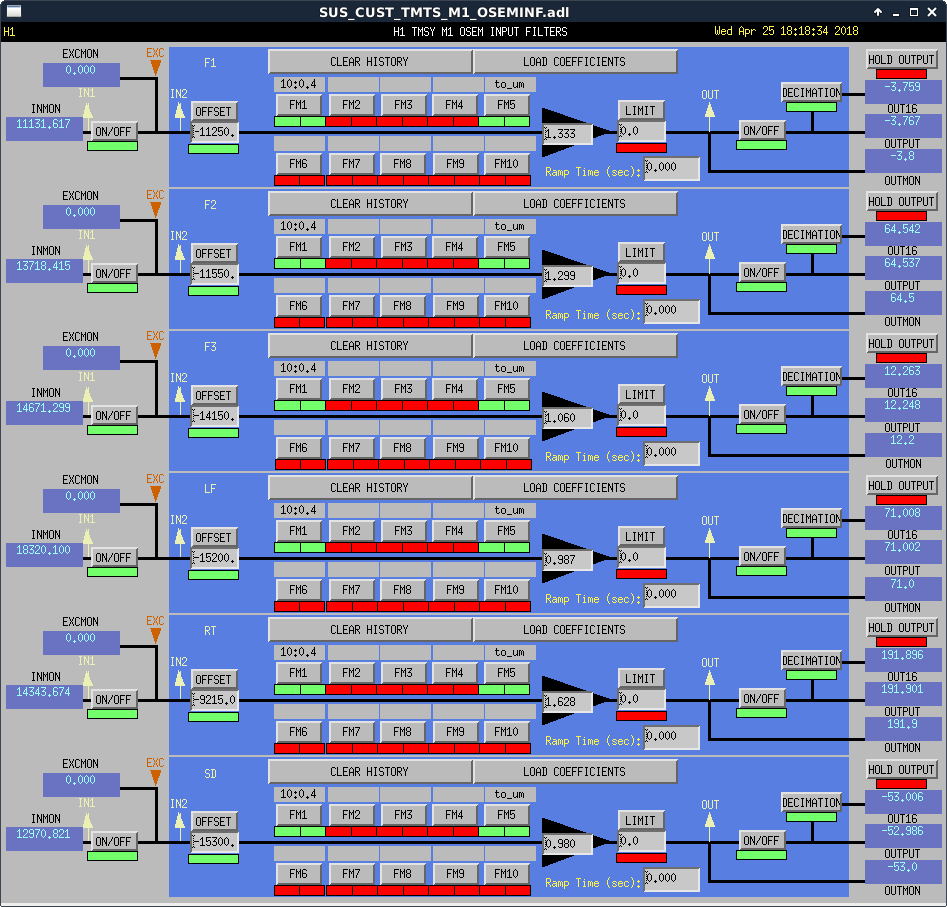
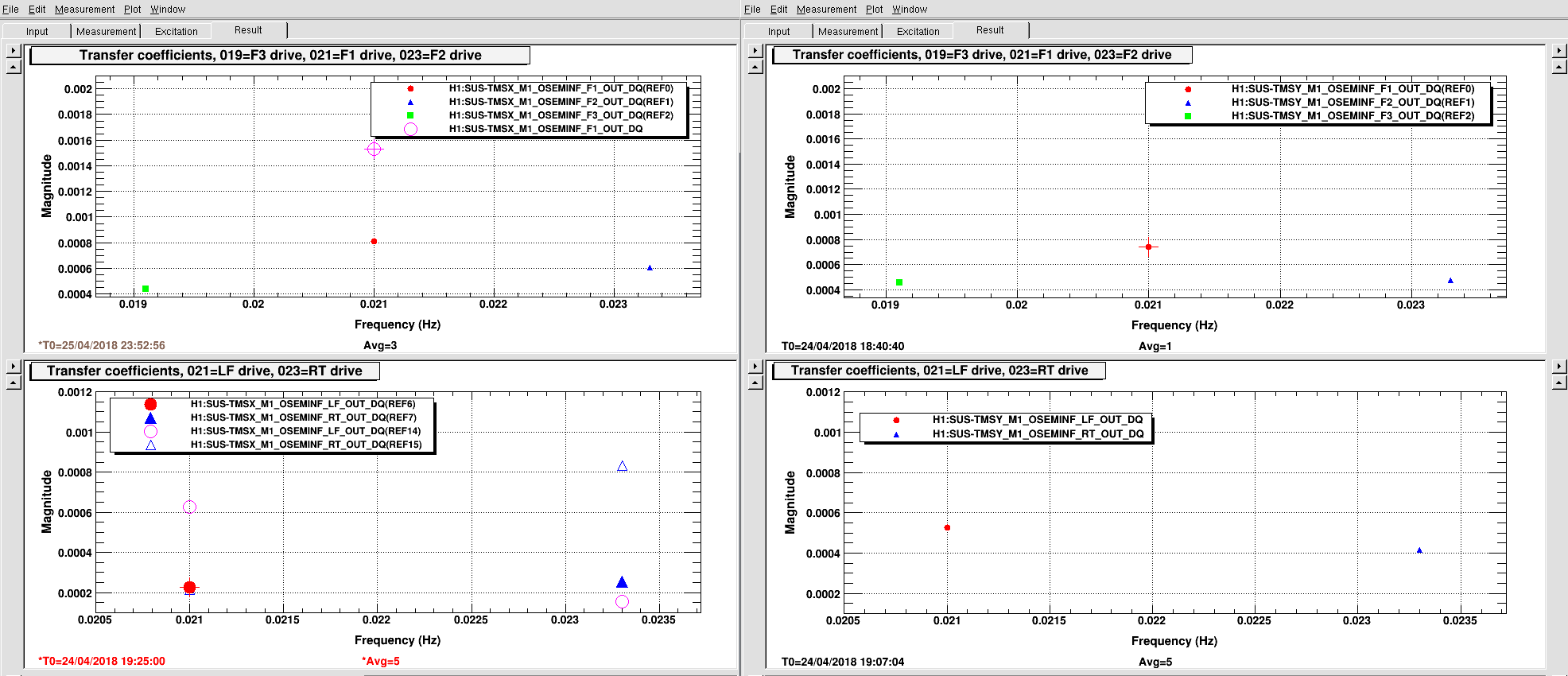
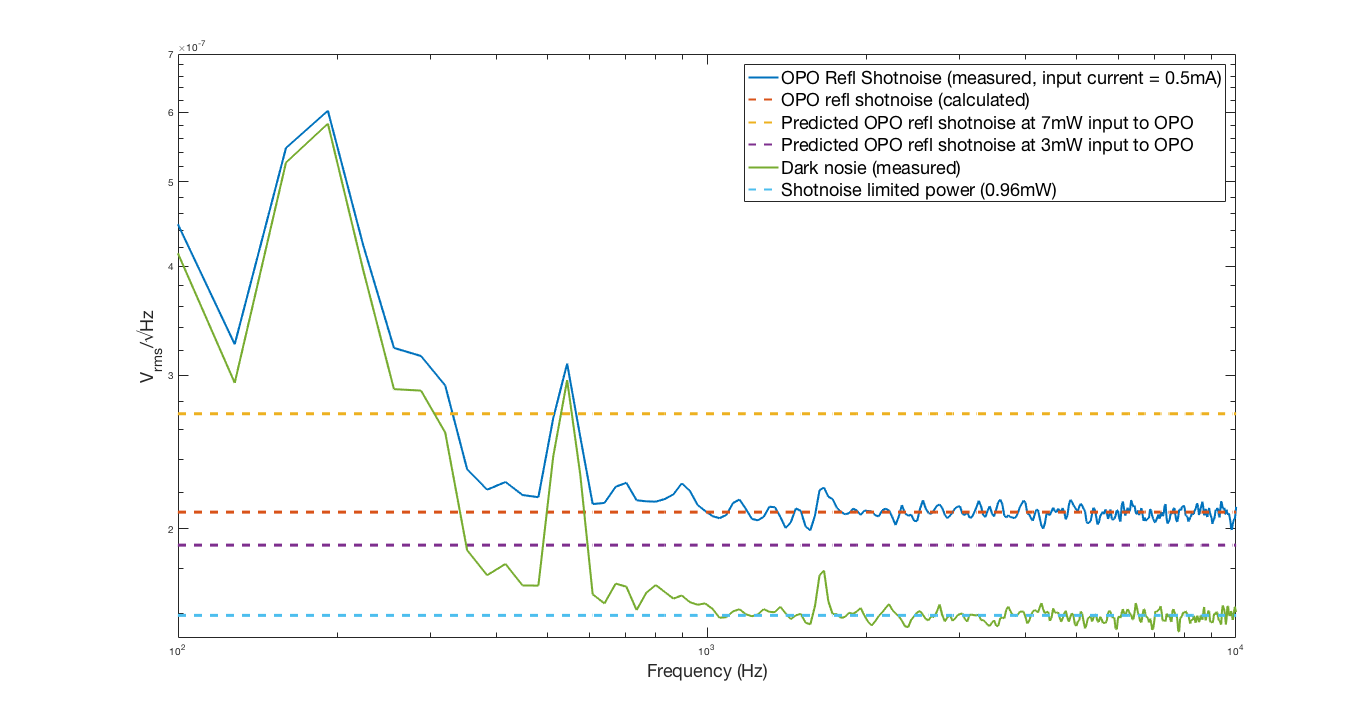
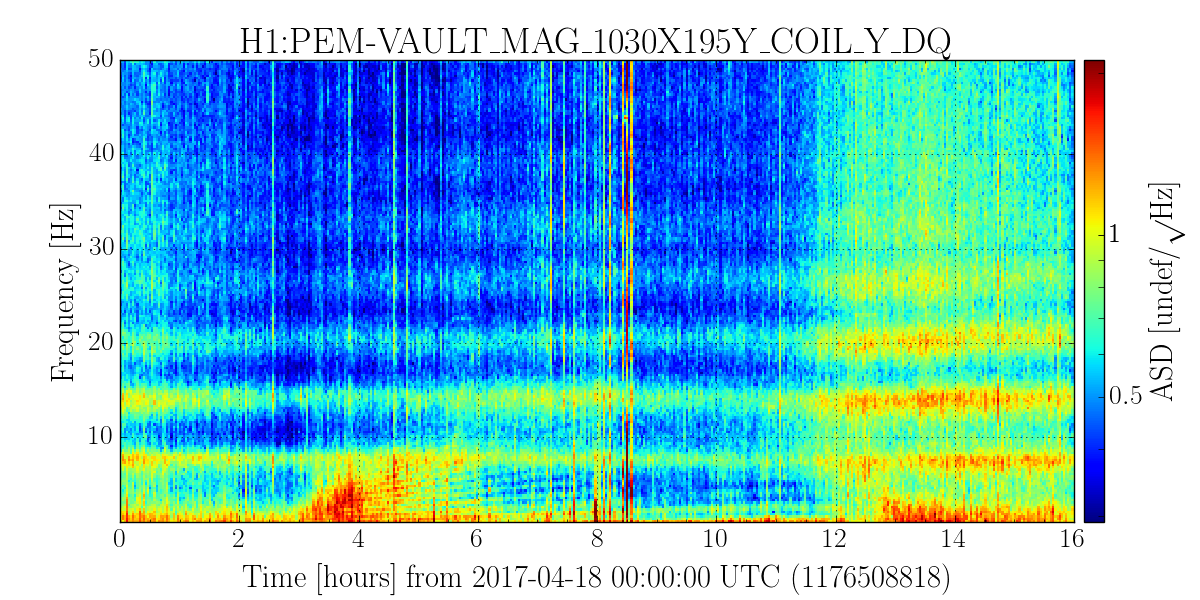
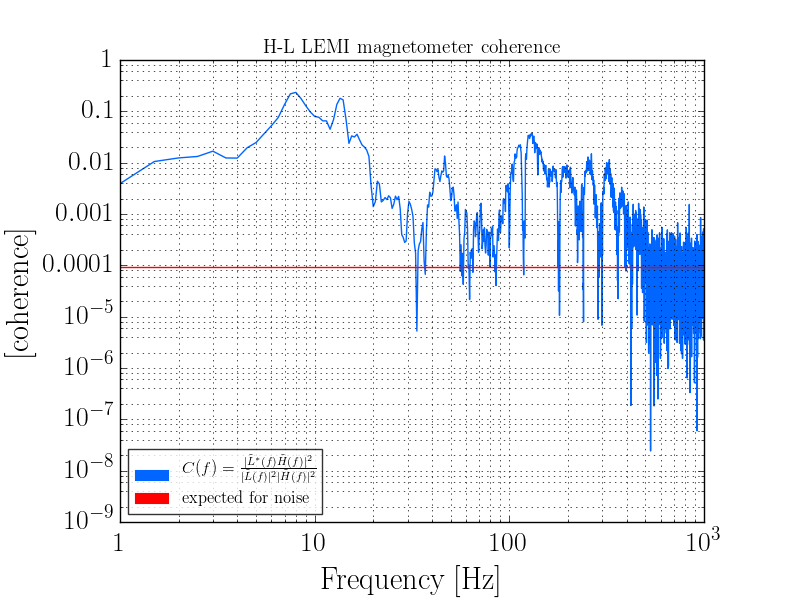
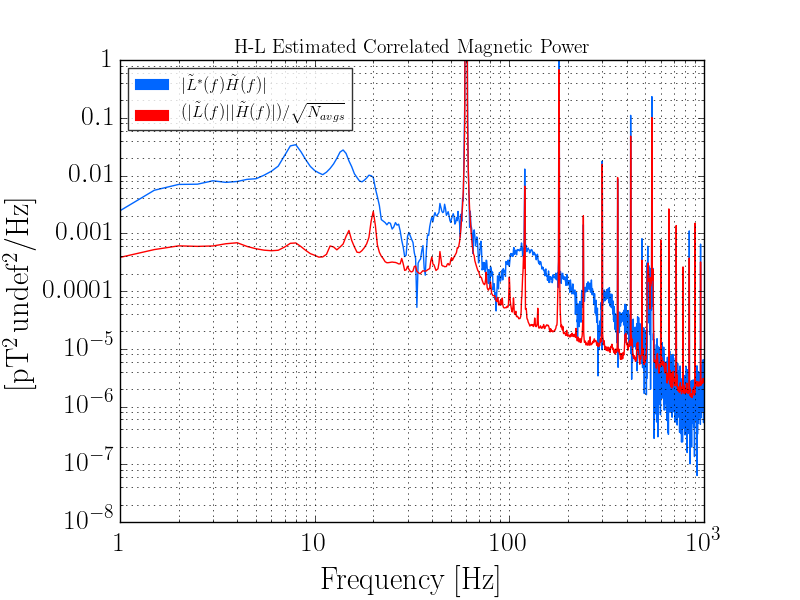
PeterF pointed out that it would be good to see what beam jitter the IMC WFS are seeing now that we have the new 70W laser operating with the lower water flow.
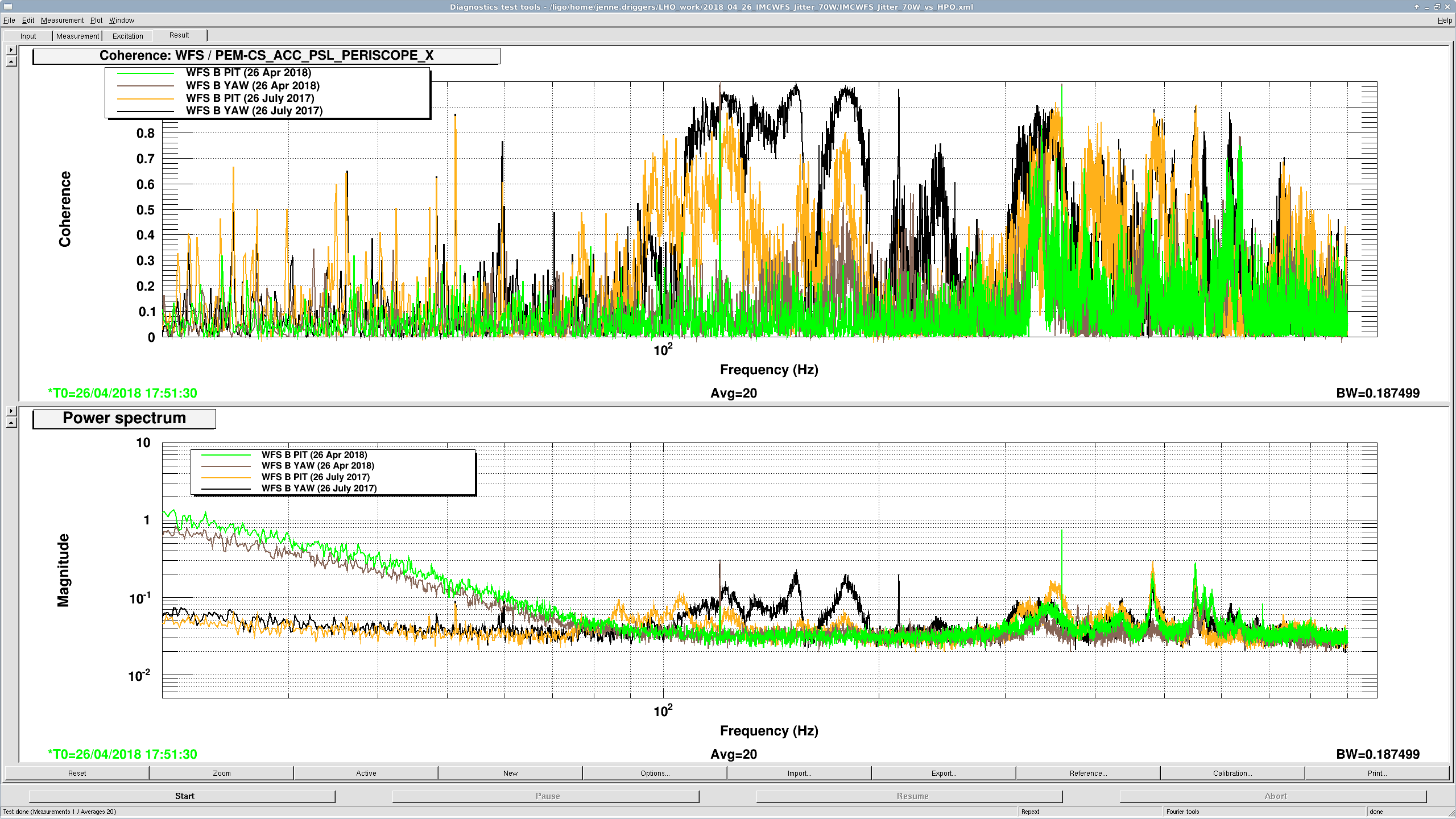
I attach 2 screenshots: one of all the WFS, and one with just WFS_B traces, since that has historically and is still the sensor that sees the jitter motion the best. You can see that the coherence between the WFS and the PEM accelerometer on the PSL periscope has decreased, as well as just the overall spectra. There is a small new feature at about 583 Hz, but otherwise the spectra above 100 Hz are all notably better. I haven't confirmed the source of extra low freq noise in the WFS right now, but there's a lot going on in the LVEA, and the comparison time is Observation mode.
Perhaps I'll ask one of our Fellows who is working on the noise budget to use the old coupling TF to try to project what this noise would mean for our O2 DARM, but hopefully we'll also have significantly less coupling now that we've replaced ITMX, so that projection would be an upper limit.
EDIT: Note that these are the RF channels (I just realized that I forgot to include that information in my DTT-froze-on-me / redo things fiasco). I'll soon post a version with the calibrated WFS DC channels.
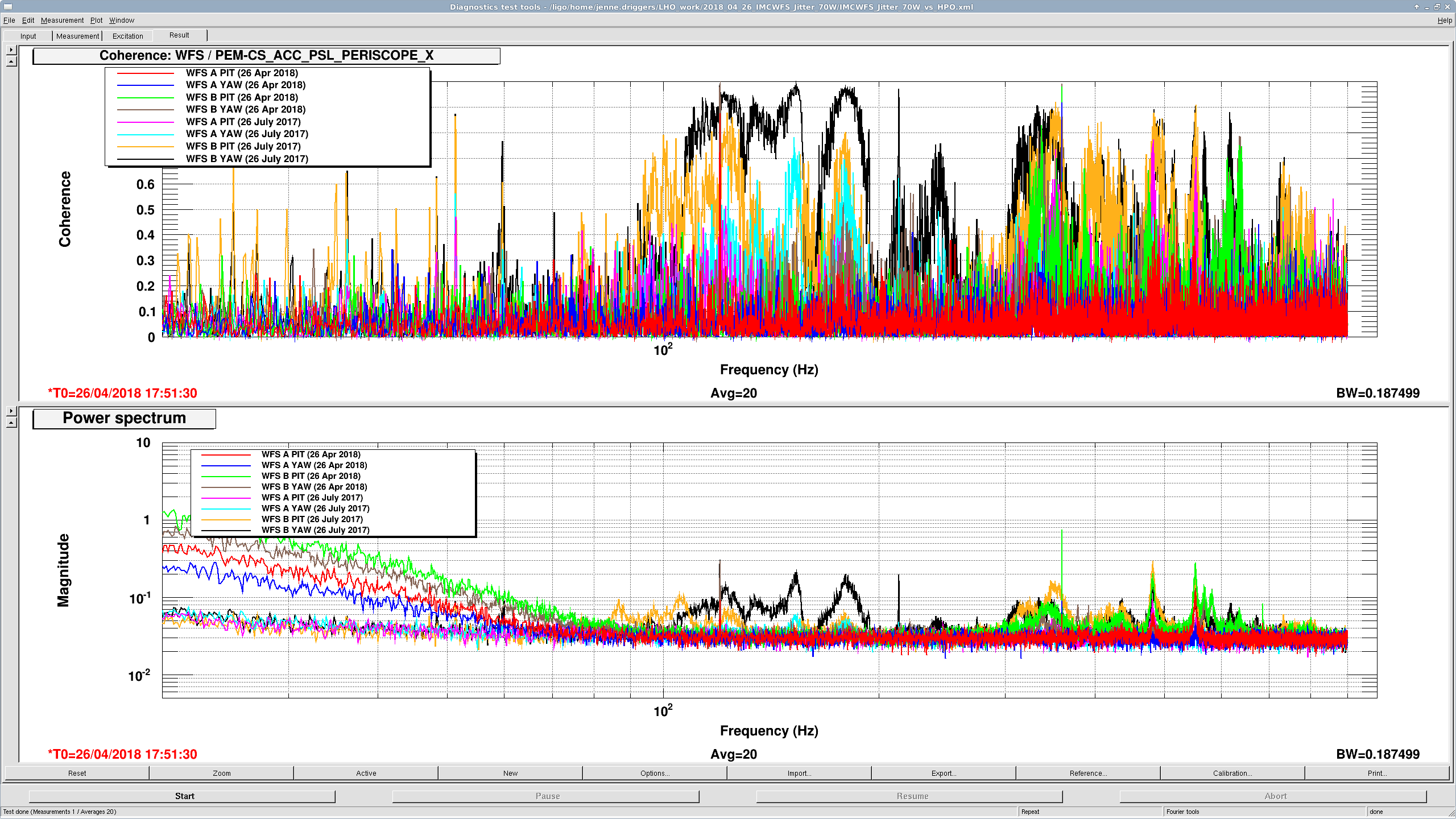
Really what we want to see is the WFS DC spectra, in calibrated units so that we can see the ratio of 1,0 modes to 0,0 modes. However, the times recently that the IMC has been locked have either been at such a low power (0.9W or less), or when the beam was very far off center from the WFS that the data isn't great.
I have some data from a lock on April 4th with the new 70W amplifier but before the rotation stage was locked out at low power (and before the PMC and EOM were swapped), so the IMC was locked with 5.2W injected into the vacuum. Comparing with alog 34845 from March 2017, some of the peaks look perhaps a little better, but I need to retake the data with the IMC locked at higher input power to have better SNR. I don't have the unlocked version of WFS at this time - we went straight from locked to laser safe.