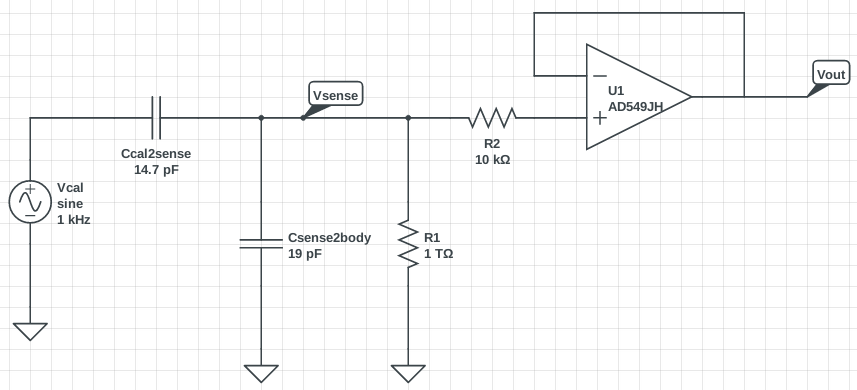
Georgia, Robert
This entry gives results from the test discussed by Georgia here: https://alog.ligo-wa.caltech.edu/aLOG/index.php?callRep=41559
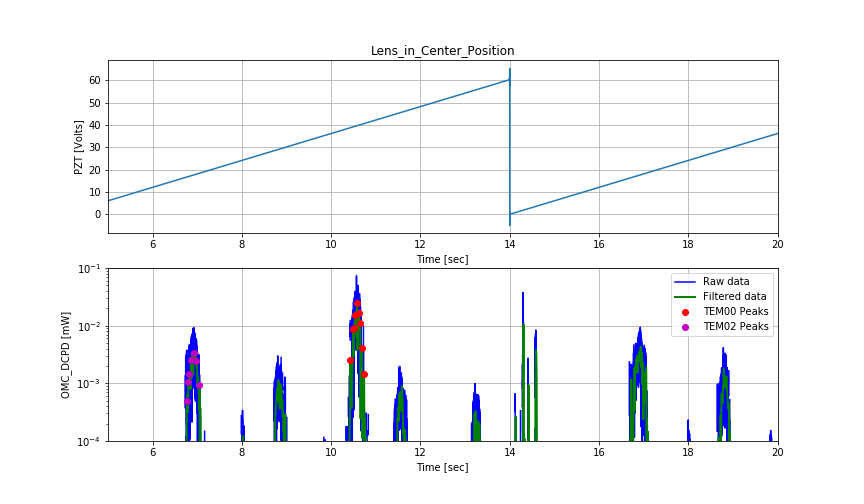
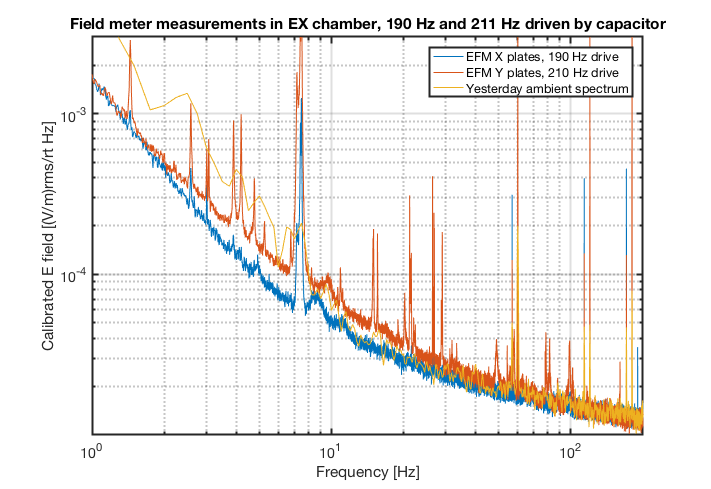
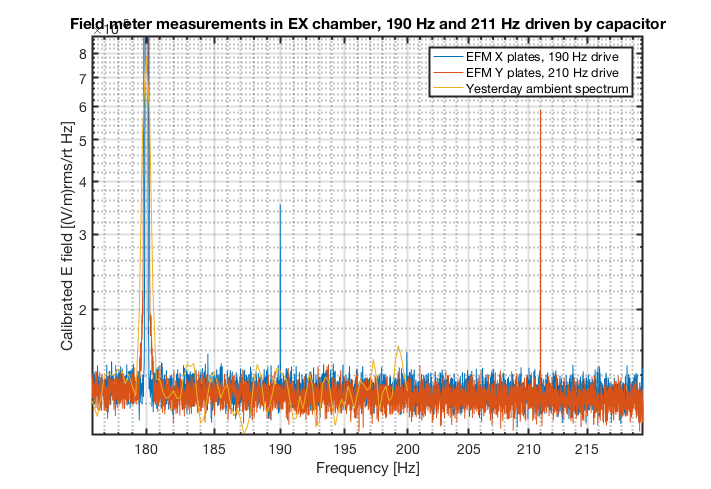
Sometimes during PEM injections, we sanity check that external electric fields (like from a lightning strike) do not significantly affect DARM by sneaking into the chamber through a viewport. A repeat of these injections allowed for a comparison of the field measured by the EFM to the test mass motion that has been induced in the past by similar injections. In the past, we only did a single frequency in the bucket - because the integration time to see the signal in DARM was long.
We repeated the injection by placing an insulated plate over the illuminator port of the EX chamber, and driving at 211 Hz with a voltage of about +/- 11 V relative to the chamber. Similar injections have produced an rms DARM signal as high as 1.5e-21 m in the past, though this is variable, and sometimes we can’t integrate long enough to see the injection in DARM.
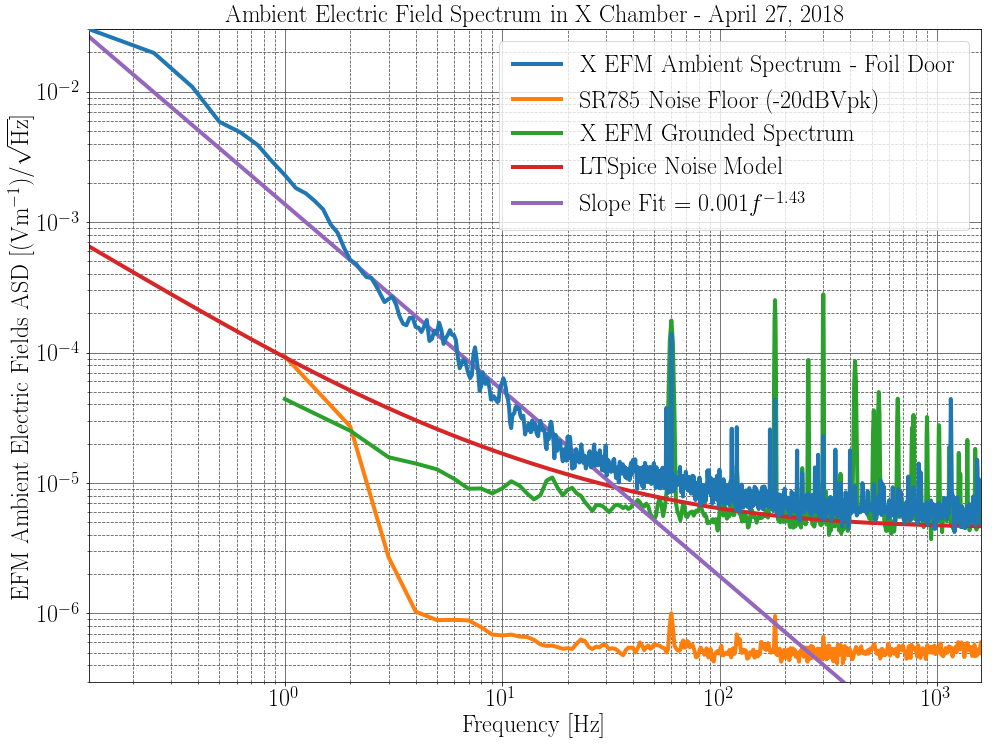
The figure shows an EFM spectrum for this injection and DARM for a similar injection in the past. The calibration from the log referenced above gives an rms field at 211 Hz of about 1e-5 V/m at the EFM. Assuming similar conditions to those in the past, we get a coupling of about 1.6e-16 meters of DARM motion per V/m measured by the EFM, for this injection configuration. The SNR of the EFM signal for the injection appeared to be nearly ten times greater than the DARM SNR had been during similar injections in the past. Shielding may differ for different injection points, but at least for this port injection, the EFM appears to be more sensitive than DARM.

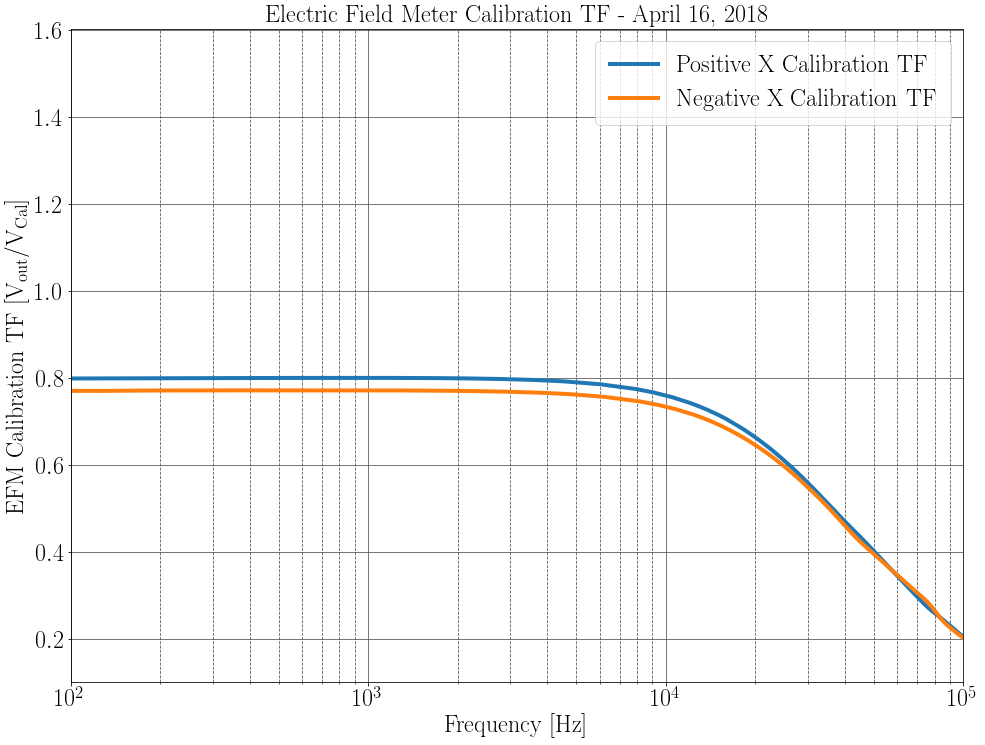
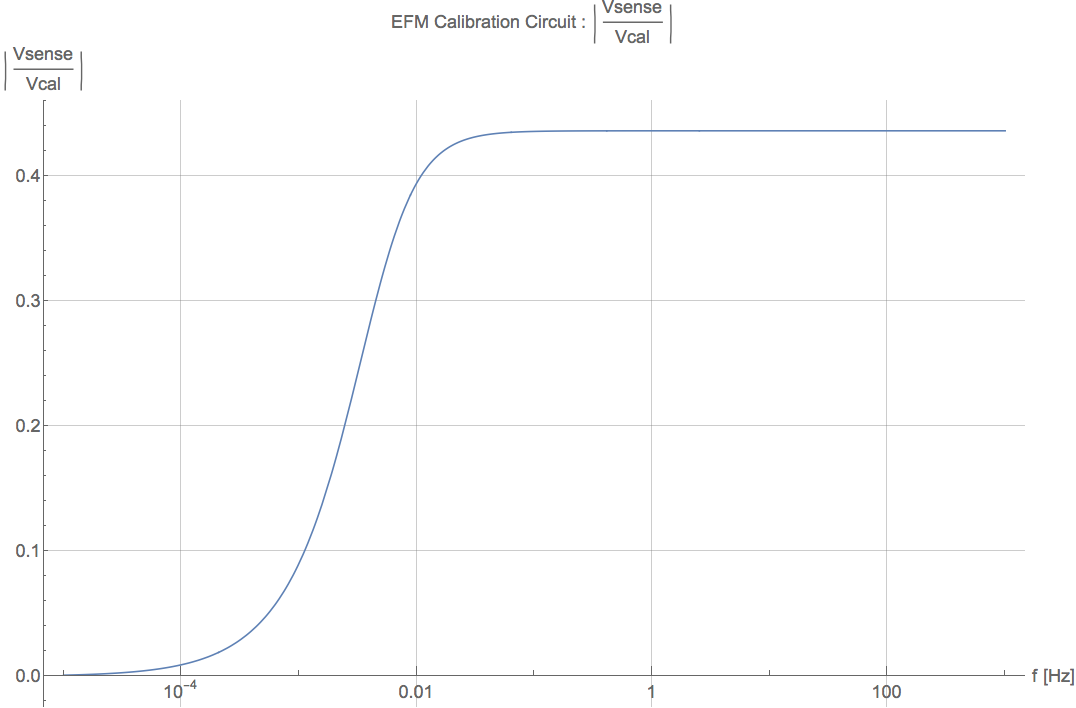
I calibrated our EFM spectrum into DARM, this time using Robert and Georgia's electric field to meter TF numberI assumed that
due to the test mass suspensions, where
is some constant. From Robert's measurement I found
. Then, calibrating EFM voltage output noise
into displacement noise:
where
from alog 41591, and
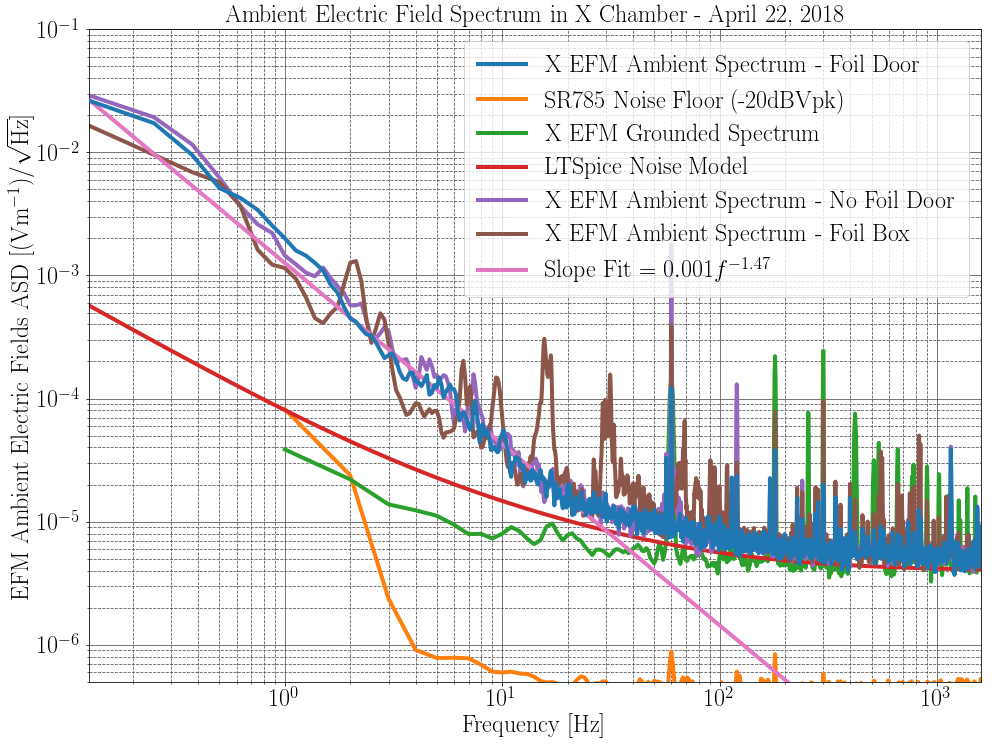
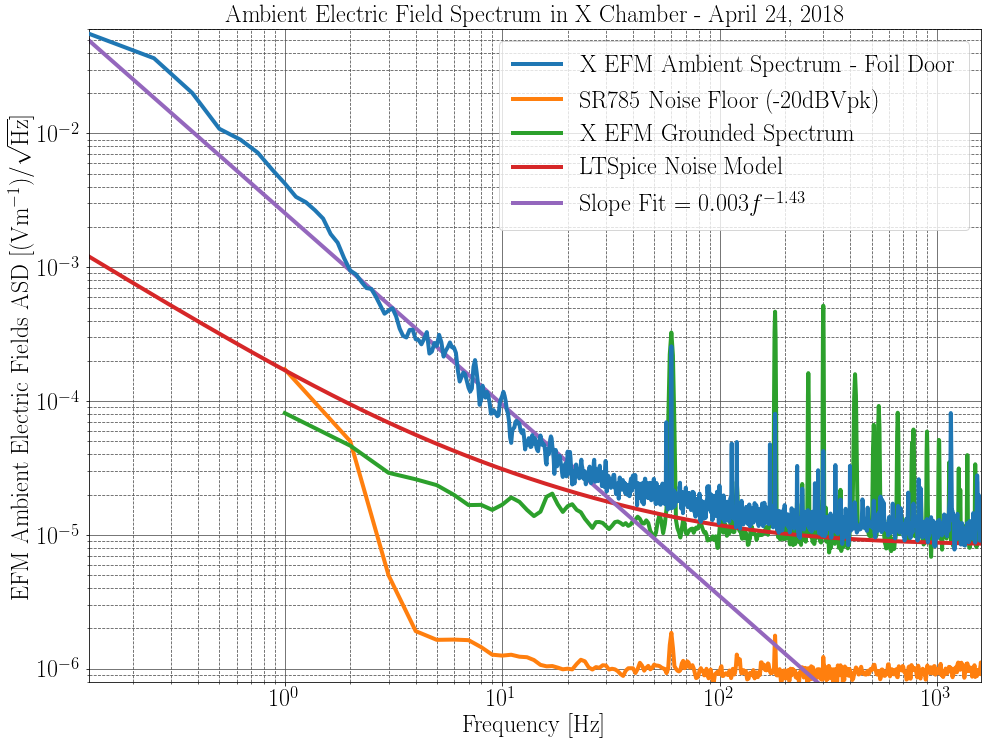
. The estimated displacement noise is plotted below. Think of this as an upper bound for the ambient electric field noise, since we are not sure our EFM noise floor below 100 Hz is not sensor noise, and this is literally a single point measurement of
.