patrick.thomas@LIGO.ORG - posted 16:28, Wednesday 02 May 2018 (41810)
Ops Shift Summary
14:52 UTC Mark into LVEA 14:52 UTC Peter to PSL enclosure Hugh running transfer functions on HAM4 ISI 15:39 UTC APS through gate 15:39 UTC Chris opening inner rollup door to LVEA 15:45 UTC Chris done 15:58 UTC Stephen, Angus, Jason, Travis (weld crew) to end X 16:51 UTC Karen to mid Y, cleaning outside of VEA 16:55 UTC Hugh to HAM5 17:06 UTC Ken and Chandra to mid Y 17:25 UTC Visitor from Mid Columbia Engineering through gate 17:35 UTC Chris to LVEA to help Tyler with ion pump removal 18:01 UTC Kyle to end X to measure purge air humidity 18:02 UTC Bubba WP 7529 18:07 UTC Tour in CR 18:20 UTC Tour leaving CR 18:52 UTC Hugh out of HAM5 19:03 UTC Mark and Tyler out for lunch 19:17 UTC Travis and Angus back from end X 19:22 UTC Kyle back Peter out of PSL enclosure 19:29 UTC Daniel to IO racks to take cable length measurements 19:39 UTC Daniel done 20:08 UTC Mark to LVEA to work on IP1 20:08 UTC Visitor through gate to see Filiberto 20:11 UTC Peter to optics lab and then PSL enclosure 20:21 UTC Chris to LVEA to help Mark with IP1 20:37 UTC Jason to end X for fiber welding 20:49 UTC Hugh to end X mechanical room 21:10 UTC Sebastien, Slawek, Betsy to LVEA 21:12 UTC Hugh to end Y 21:16 UTC Visitor from University of Washington through gate 21:22 UTC Filiberto to vault and mid X 21:41 UTC Mark and Chris done. IP1 is done. IP2 is on floor. South bay crane locked out. Hugh back 22:00 UTC Site weekly meeting 22:05 UTC Filiberto back Slawek, Sebastien, Betsy back 23:18 UTC Sheila transitioning LVEA to laser hazard



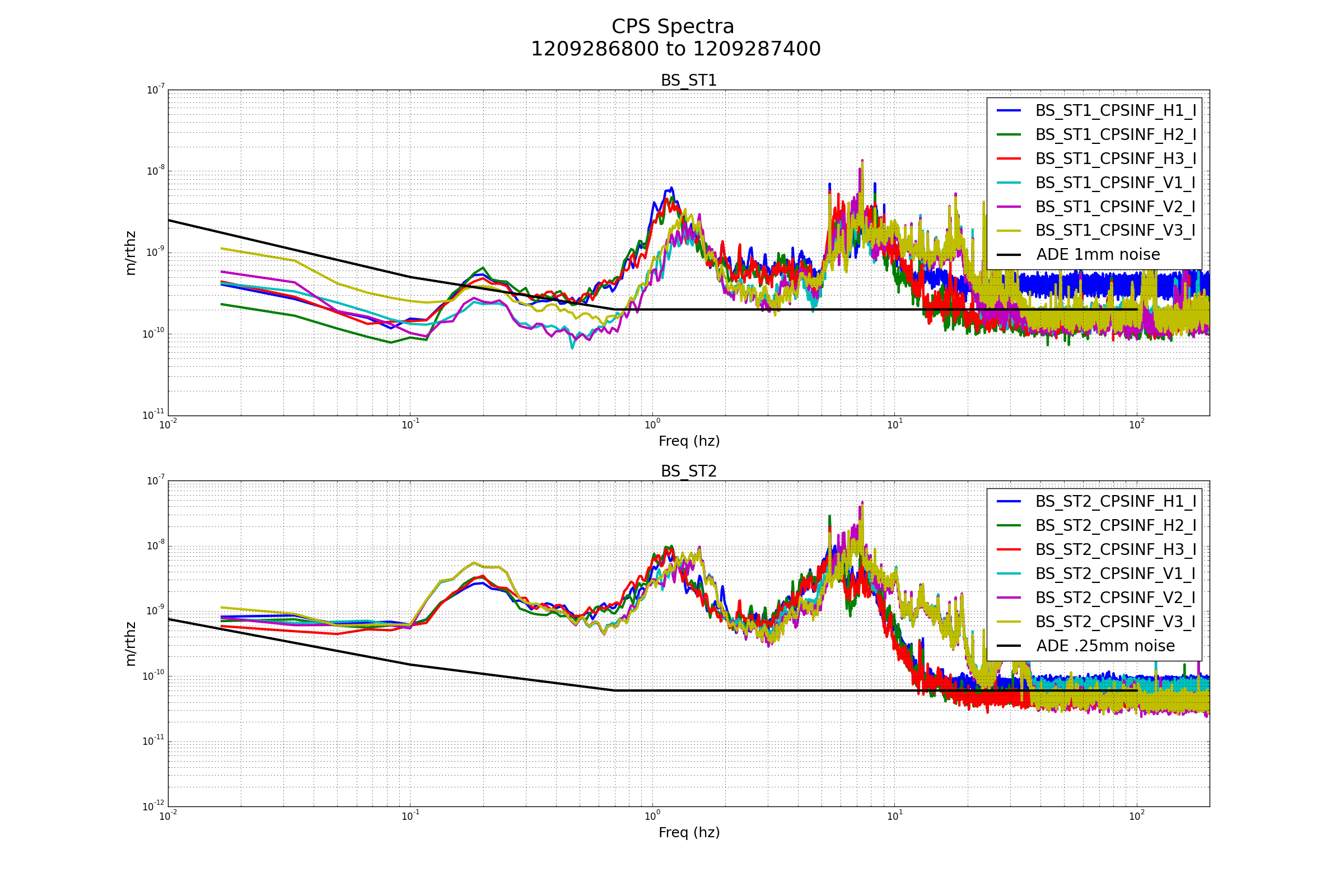


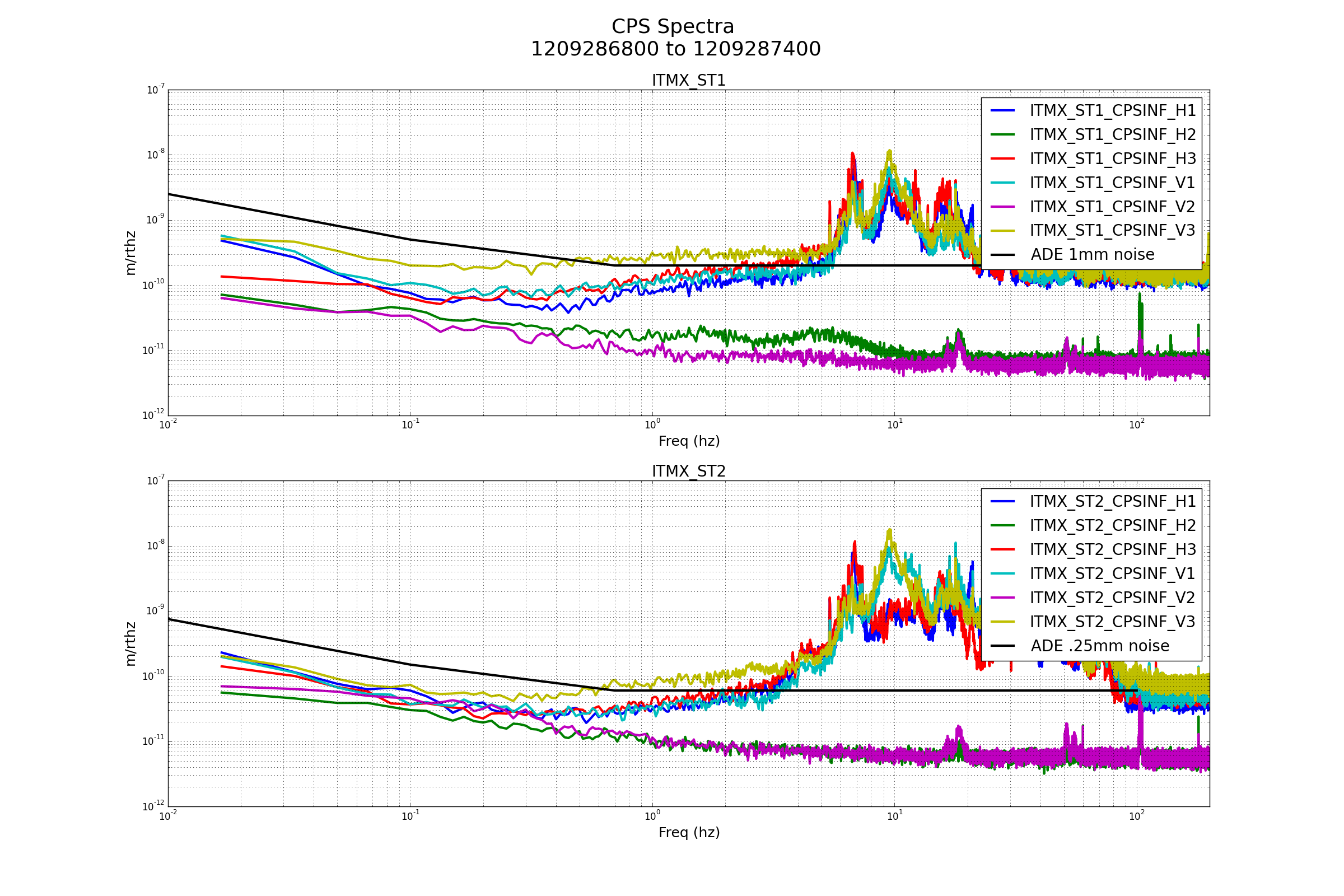

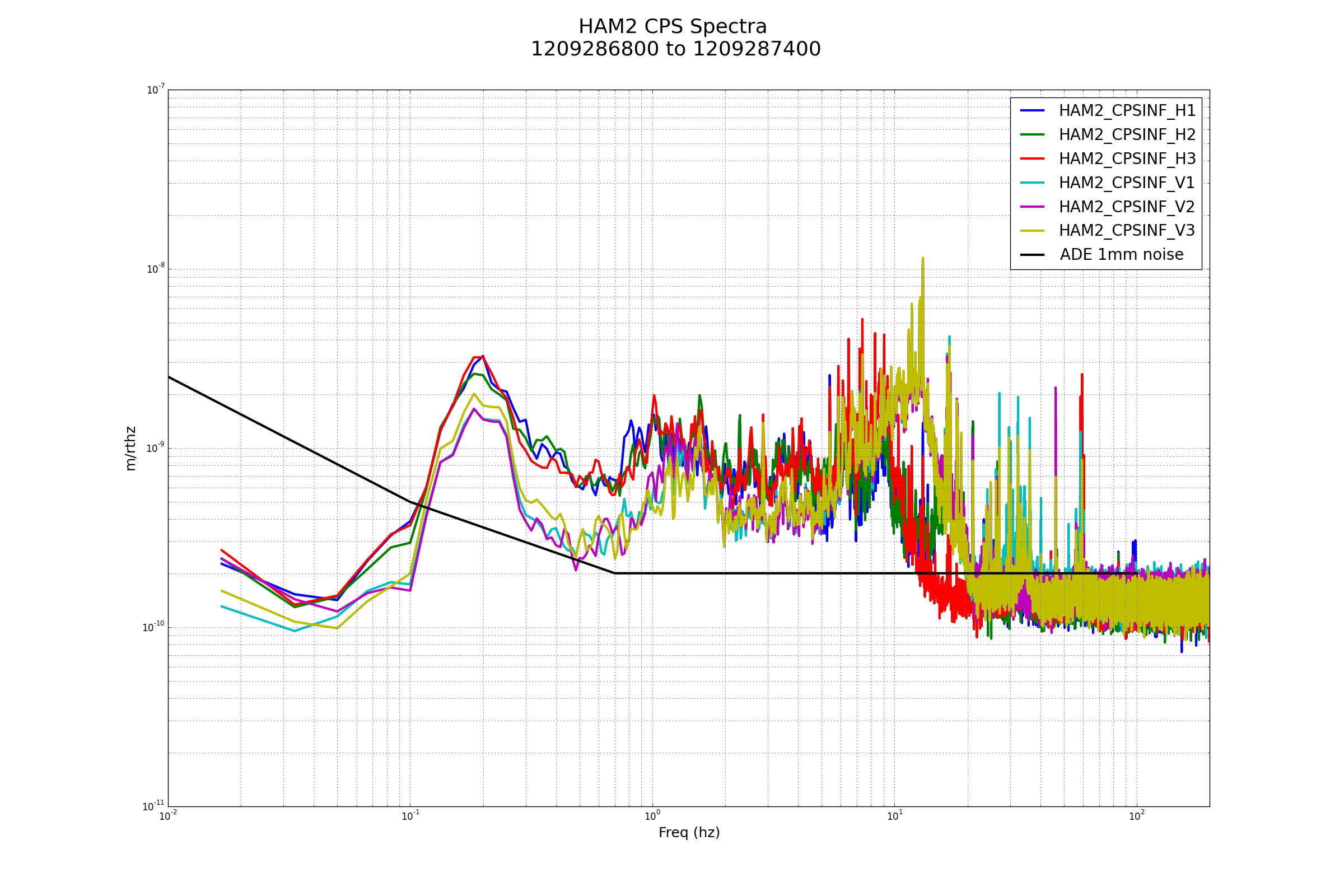
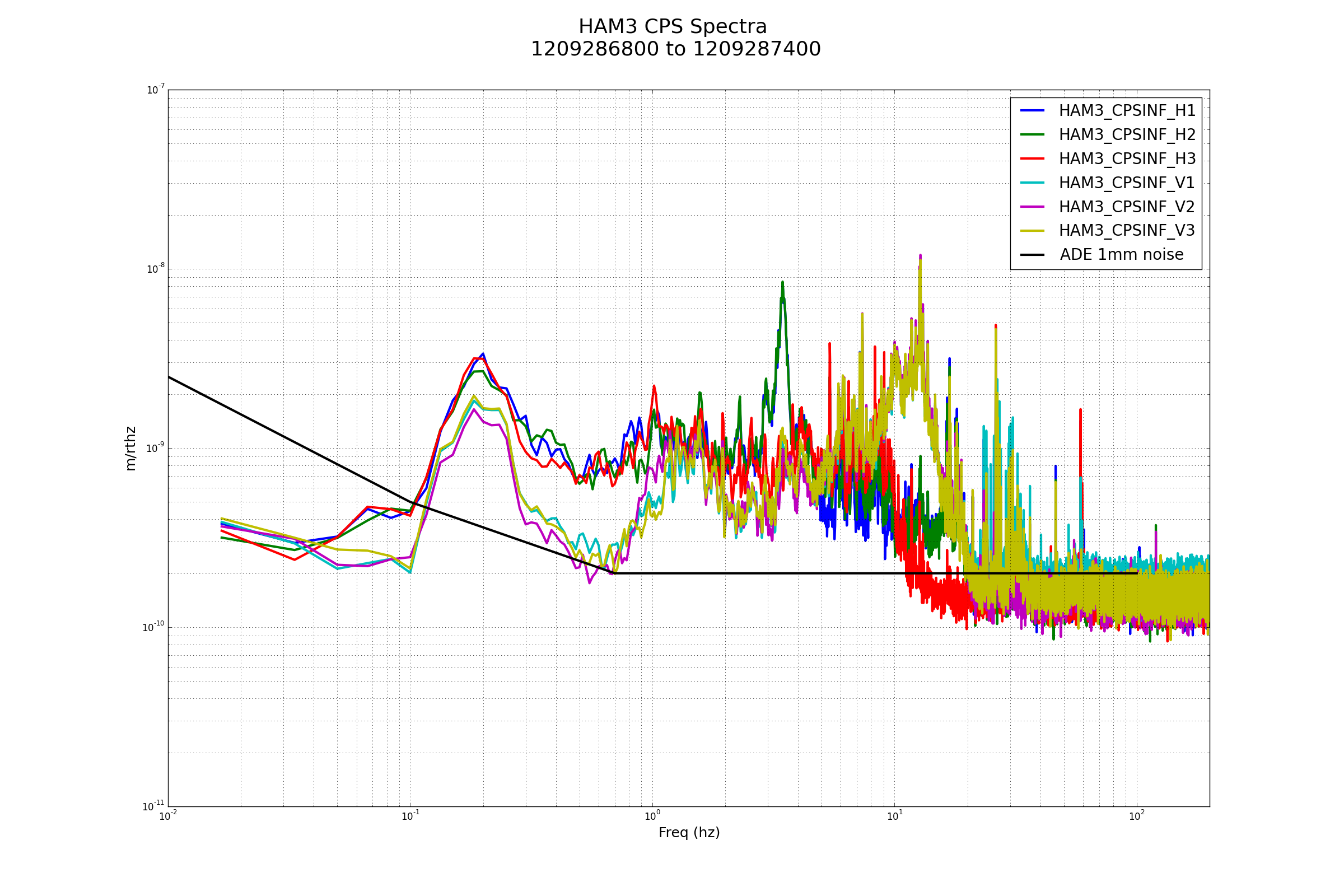

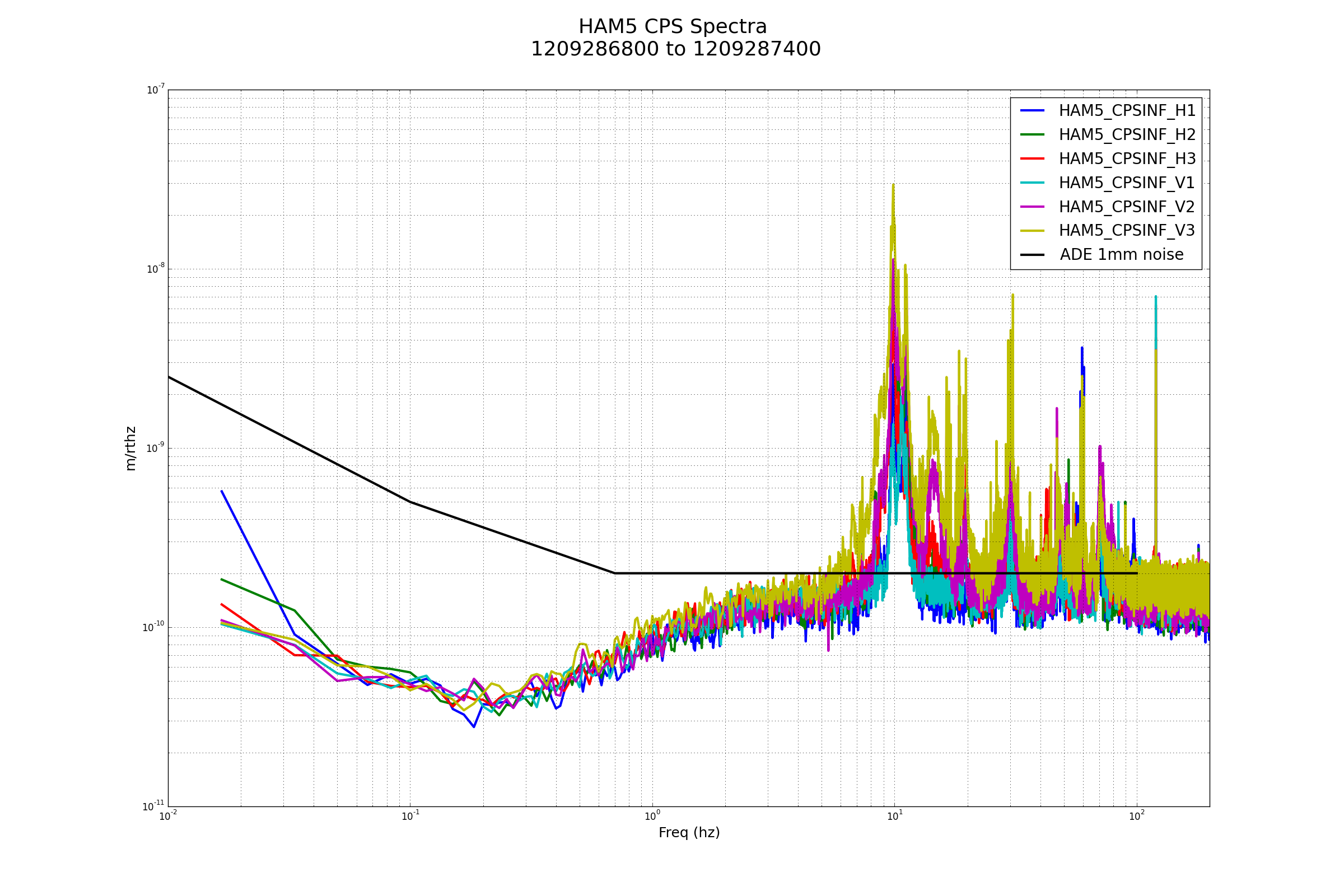
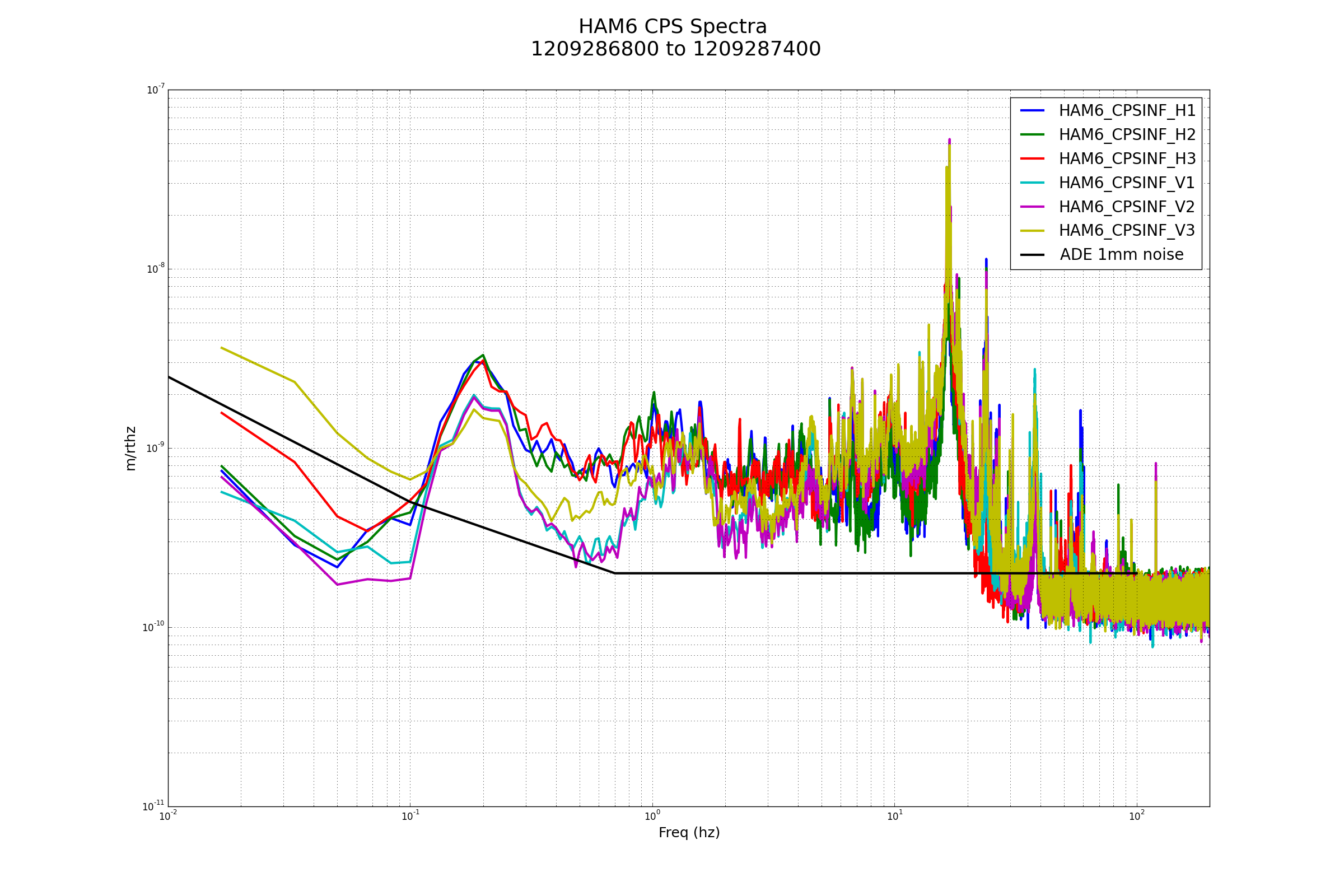

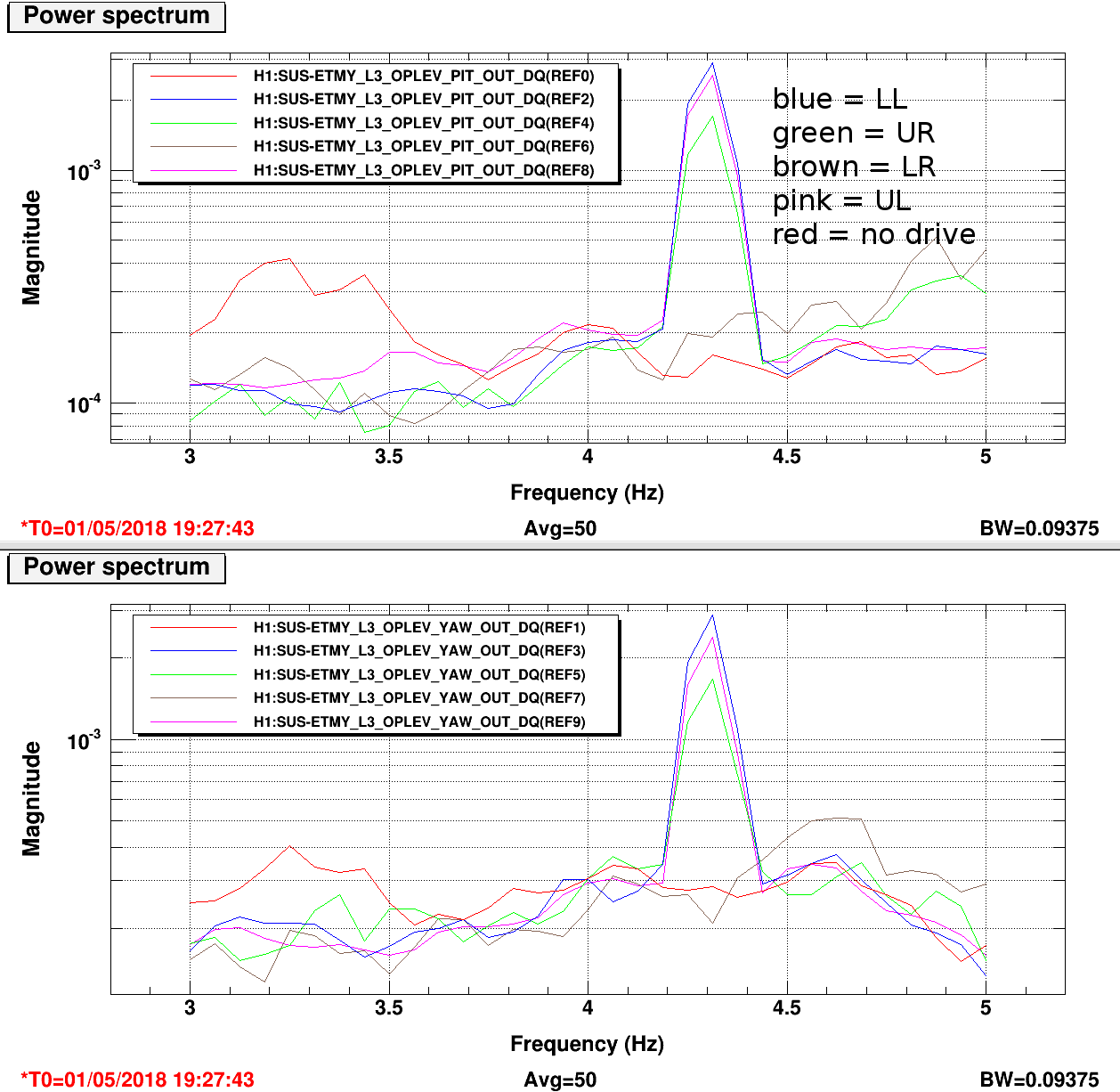
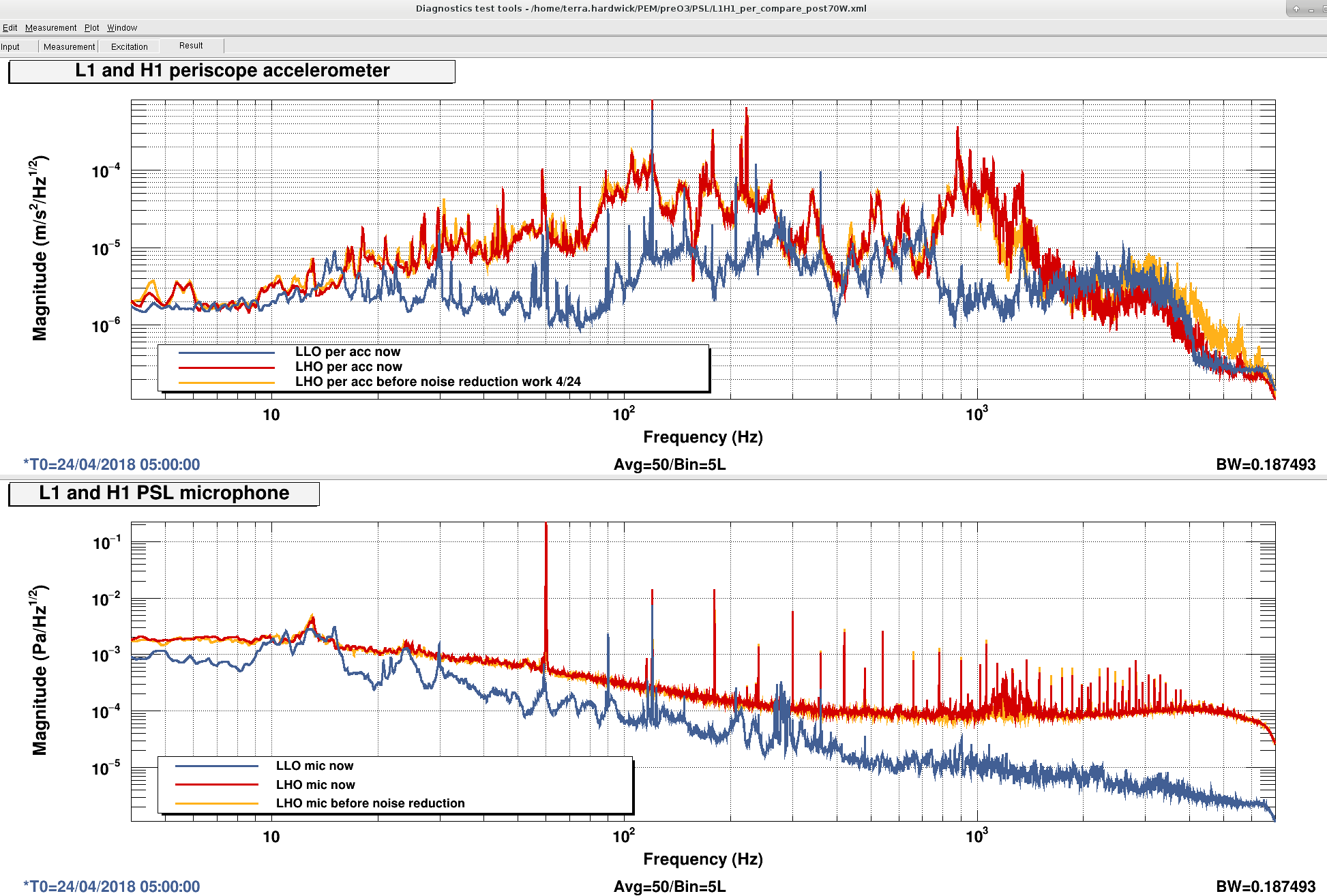
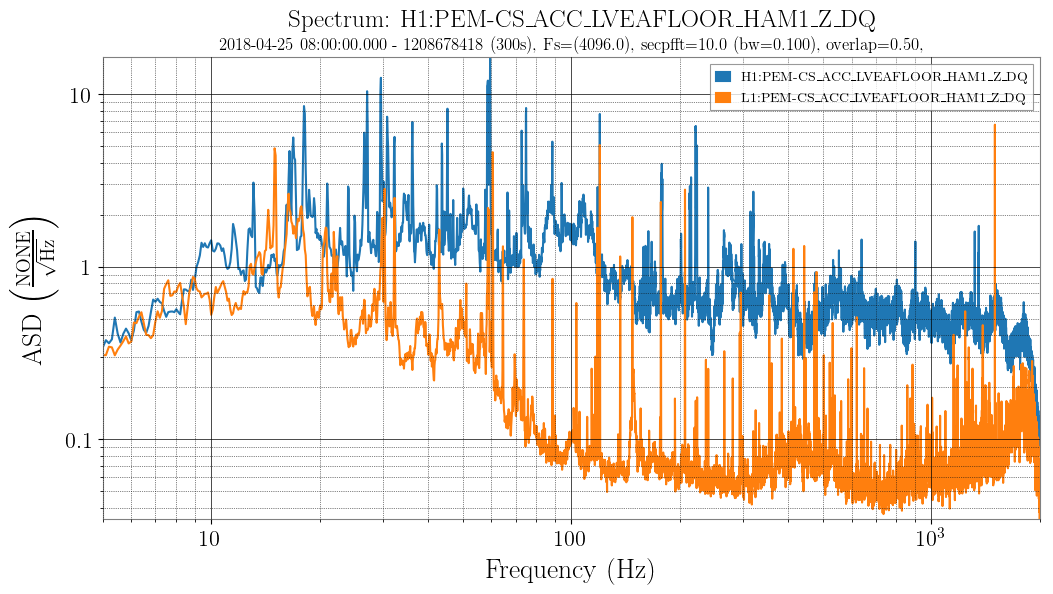
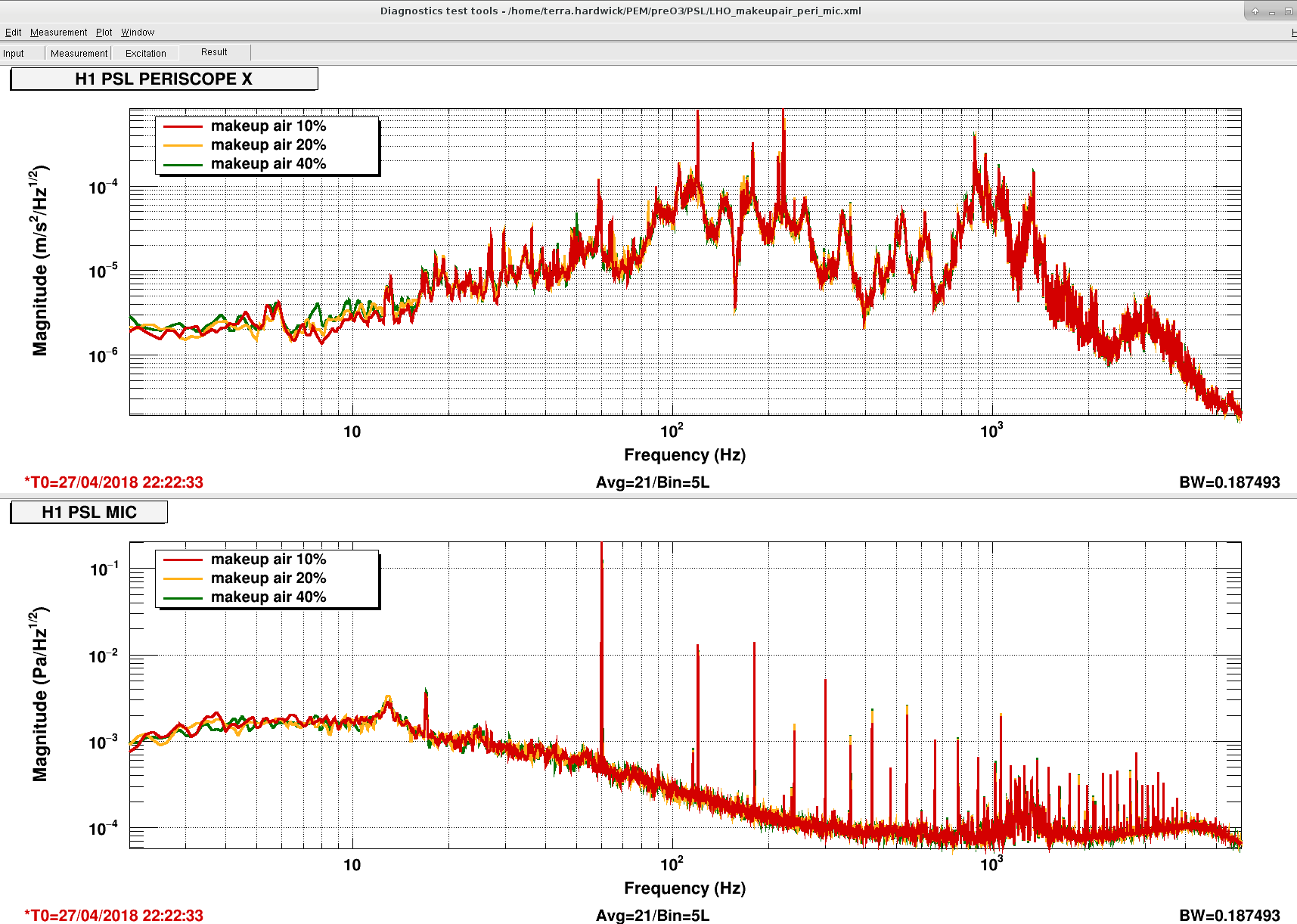
Excellent!
Here are a few pictures of the ITMY second set install from yesterday.