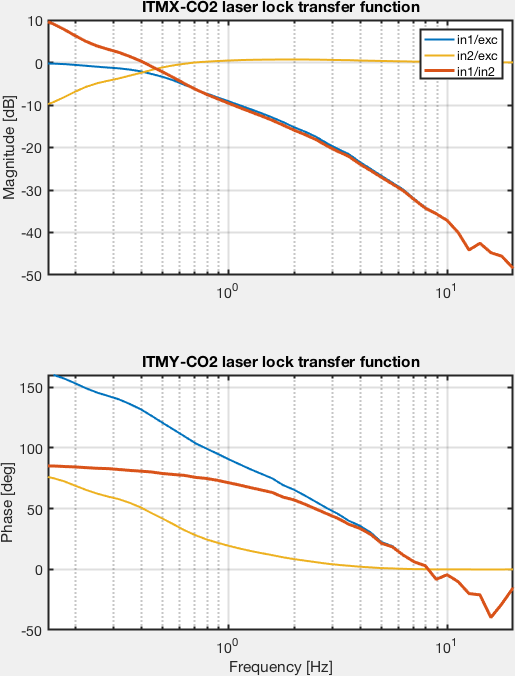
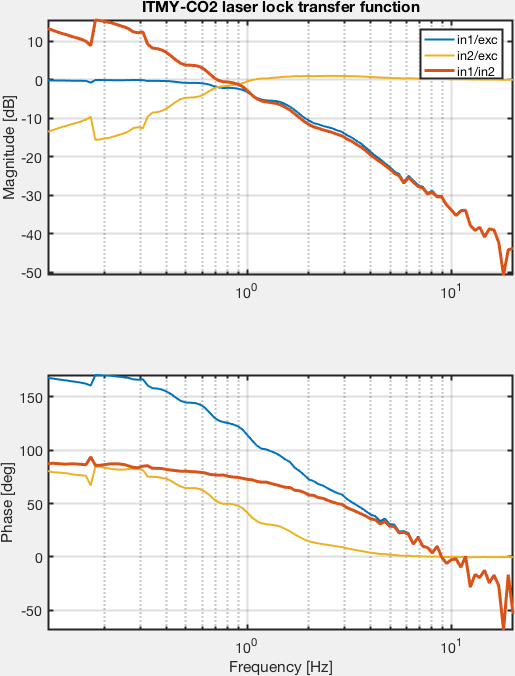
Ops Shift Log: 03/16/2018, Day Shift 15:00 – 23:00 (08:00 - 16:00) Time - UTC (PT)
State of H1: Unlocked – Vented for maintenance and upgrades
Intent Bit: Engineering
Support: N/A
Incoming Operator: N/A
Shift Summary: Vented for maintenance and upgrades
Activity Log: Time - UTC (PT)
14:44 (07:44) Apollo crew - End-Y to turn off cleanrooms
15:00 (08:00) Start of Shift
15:19 (08:19) Apollo crew – Back from End-Y
15:44 (08:44) Hugh – Going to HAM6
15:50 (08:50) Richard & Ken – Going to Mid-Y
16:03 (09:03) Gerardo – Going into LVEA to prep for work on new NAG pumps
16:12 (09:12) Contractor on site to work on bake out at Mid-Y
16:13 (09:13) Hugh – Out of the LVEA
16:22 (09:22) Gerardo – Out of the LVEA
16:30 (09:30) Gerardo – Going to End-Y to recover a Nitrogen cylinder
16:46 (09:46) Rick – Going to End-X
16:57 (09:57) Rick has transitioned End-X to Laser Hazard
17:01 (10:01) Richard & Ken – Back from Mid-Y
17:14 (10:14) Ken – Going to End-Y
17:18 (10:18) Jason & Ed – Going into the PSL Enclosure for 70W amp work
17:34 (10:34) Ken – Back from End-Y
17:50 (10:50) Kyle – Going to End-Y from Mid-Y and them back to Mid-Y
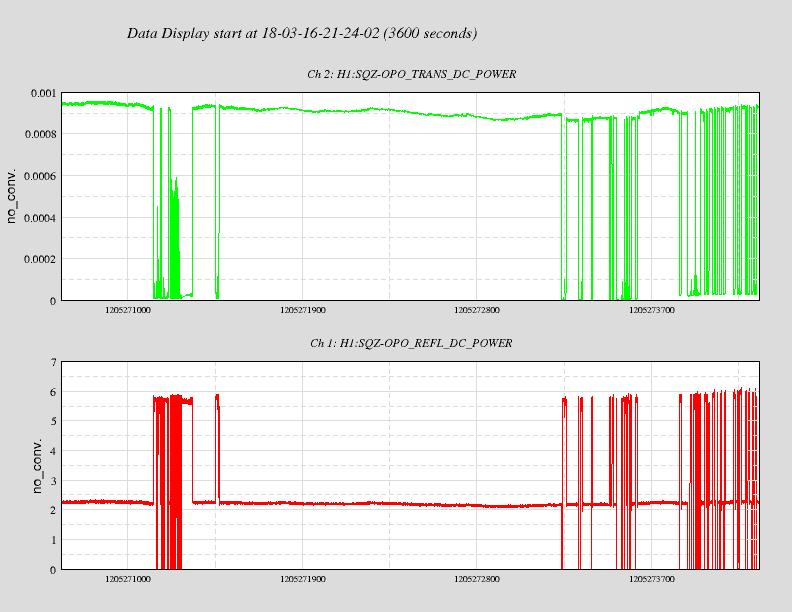
19:02 (12:02) Terry – Going to HAM6 for Squeezer work
19:05 (12:05) Jason & Peter – Out of the PSL Enclosure for lunch
19:19 (12:09) End-X is back to laser safe – Crew is coming back to CS for lunch
20:21 (13:21) Jason & Ed – Going into the PSL Enclosure for 70W amp work
20:48 (13:48) Travis – Going to End-X
21:35 (14:35) Travis – Back from End-X
21:38 (14:38) Apollo – On site sheet metal delivery for Bubba
22:15 (15:15) Gerardo – Going to End-Y to pick up equipment
22:30 (15:30) Gerardo – Back from End-Y
22:55 (15:55) Gerardo – Taking ETM optic to End-X
23:00 (16:00) End of Shift