[Keita, Rahul, Elenna]
Today I moved IM2 and IM3 to bring the beam back to our reference position on IM4 trans QPD and center it on ISS QPD after Keita's move of the mode cleaner mirrors in 90259. This requires some iteration back and forth on both suspensions.
Our desired positon on IM4 trans is P = 0.22 and Y = -0.06. On ISS QPD, it is centered, so P=0 and Y=0.
We are driving MC2 in length, so the mode cleaner is flashing, and there are bright flashes on the QPDs. I am pausing ndscope on a flash and measuring the height of the peak in the fast channel and calculating the pit and yaw position from each QDP segment.
| |
Start |
|
End |
| IM2 P slider |
765 |
IM2 P slider |
810 |
| IM2 Y slider |
-187.7 |
IM2 Y slider |
-88.7 |
| IM3 P slider |
-560.7 |
IM3 P slider |
-614.7 |
| IM3 Y slider |
320 |
IM3 Y slider |
385 |
| |
|
|
|
| IM4 trans PIT |
0.390 |
IM4 trans P |
0.268 |
| IM4 trans YAW |
0.450 |
IM4 trans Y |
0.010 |
| ISS QPD PIT |
-0.379 |
ISS QPD PIT |
-0.059 |
| ISS QPD YAW |
-0.455 |
ISS QPD YAW |
0.08 |
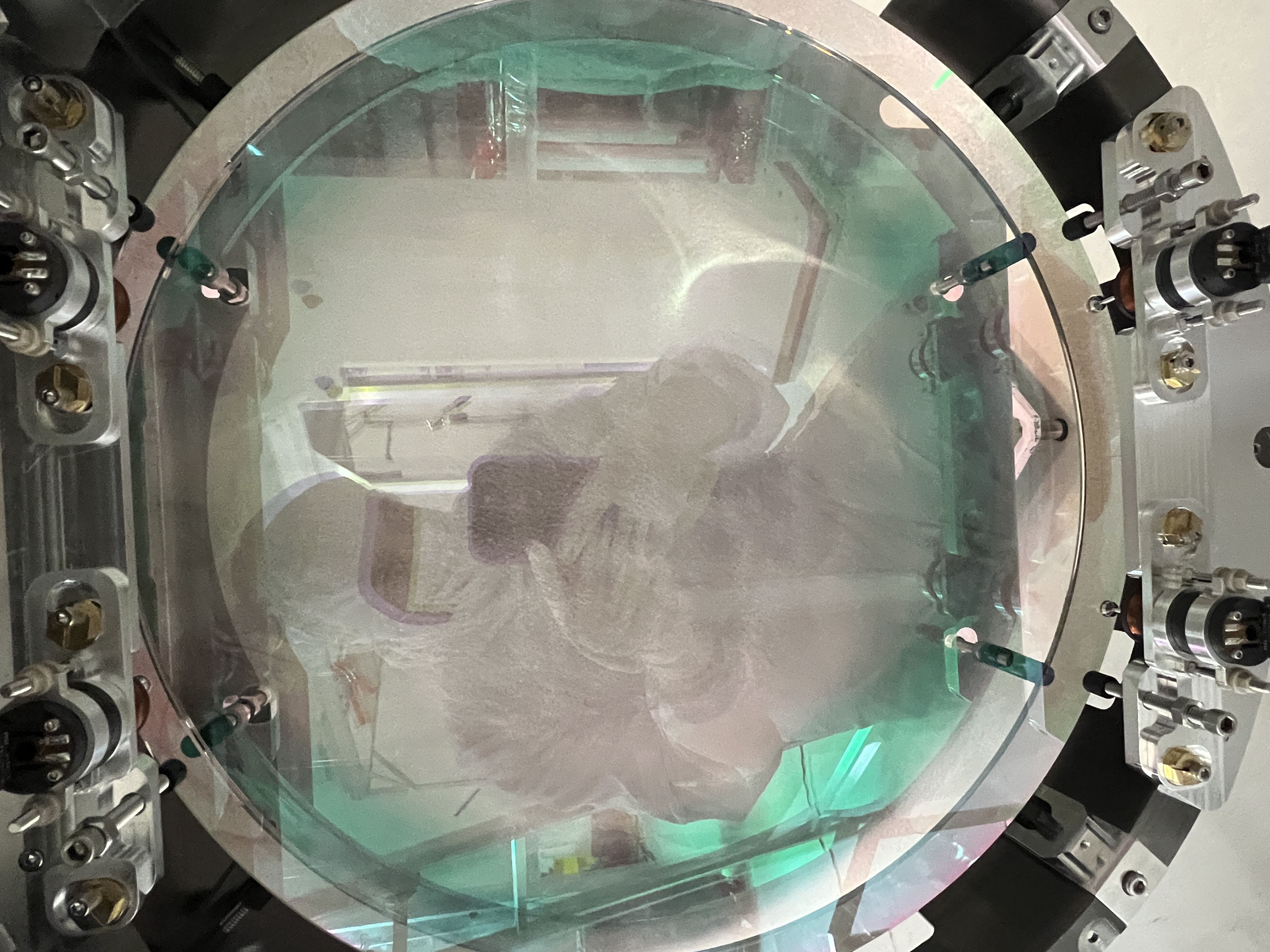
Unfortunately, this still results in clipping on the baffles Keita notes above, so we will keep going.
At the nominal IM4 trans position, yaw is pretty well centered. I then moved IM2 to both edges of IM4 trans QPD.
I changed the IM2 yaw slider to -250.7, which brought the yaw position on IM4 trans to 0.85. This made the clipping worse.
I changed the IM2 yaw slider to 90.3, which brought the yaw position on IM4 trans to -0.88. This was still not good enough to fix the clipping on the baffle.
By making a very large move to IM2 yaw slider value of 710.3, this centered the beam in the IM4 baffle. This is a ~800 urad move according to the osems and slider. The IFO REFL beam is still clipped.
I undid the 800 urad move, so the IM2 yaw slider is back to -88.7 for now.
Keita and Rahul went out to measure the position of the beam on MCs 1,2 and 3. We think that we need to make a move of these three mirrors to see if we can unclip the beam on these baffles that way.
We want to note that the positive yaw move of IM2 corresponds to unclipping on the IM4 baffle, this is consistent with the beam motion observed in chamber in the -X direction. However, this is contradictory to the sign on IM4 trans QPD, which was moving to negative yaw when we did this move. We suspect that the segment defintion must be wrong somewhere.
Keita will say more later once we have a chance to analyze the positions in chamber.
To clarify, the slider values of IM2 and IM3 are left at the "end" positions on the table above.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}