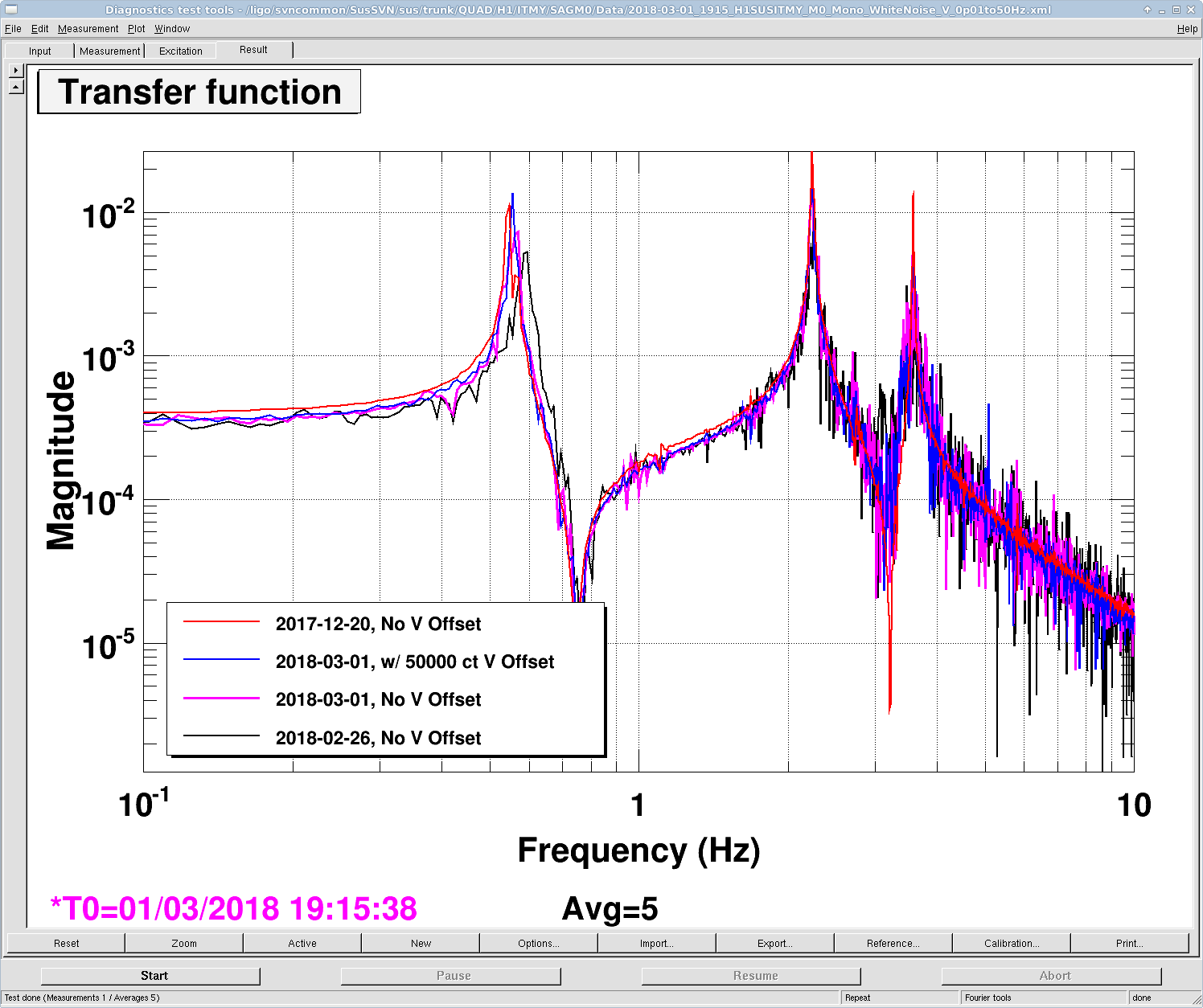
jeffrey.kissel@LIGO.ORG - posted 22:03, Thursday 01 March 2018 (40801)
First H1SUSOPO (an OPOS) M1 to M1 Transfer Functions, and the Beginnings of Standard T&C Infrastructure
E. Bonilla, A. Fernandez-Galiana, J. Kissel A few days ago, I took the first transfer functions of the newly free, newly installed H1 SUS OPO, and instantiation of an optical parametric oscillator suspension (OPOS) -- see initial results in LHO aLOG 40749. The data can be found here: /ligo/svncommon/SusSVN/sus/trunk/VOPO/H1/OPO/SAGM1/Data/ 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_L_0p02to50Hz.xml 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_P_0p02to50Hz.xml 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_R_0p02to50Hz.xml 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_T_0p02to50Hz.xml 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_V_0p02to50Hz.xml 2018-02-27_2209_H1SUSOPO_M1_WhiteNoise_Y_0p02to50Hz.xml In order to bring this new suspension type into the fold, I've started to create the standard testing and commissioning infrastructure for analyzing the data in full, namely - With extensive help from Edgard, I've updated the single stage suspension model generating function, /ligo/svncommon/SusSVN/sus/trunk/Common/MatlabTools/SingleModel_Production/generate_Single_Model_Production.m to accept the new dynamical model, /ligo/svncommon/SusSVN/sus/trunk/Common/MatlabTools/SingleModel_Production/ssmake_voposus.m and the new parameter file /ligo/svncommon/SusSVN/sus/trunk/Common/MatlabTools/SingleModel_Production/oposopt_h1susopo.m such that I can produce a dynamical model of the OPOS on the fly. - I've copied over Alvaro's updated OSEM2EUL and EUL2OSEM matrix generation script into a more standard name and format, /ligo/svncommon/SusSVN/sus/trunk/VOPO/Common/MatlabTools/make_susopos_projections.m such that it's functional, and can spit out those matrices for use on the fly. - I've created a new DTT measurement analysis script that calibrates the raw data, and compares that data against the model, /ligo/svncommon/SusSVN/sus/trunk/VOPO/Common/MatlabTools/plotOPOS_dtttfs_M1.m so that we can debug an individual set of TFs for rubbing and expected/unexpected cross-coupling, and save the data to a standard, matlab friendly format so that we can compare different measurement sets over time and across sites. The last thing on the to-do list is to create a "plotallopos_dtttfs.m" that will then contain a list of all measurements of any OPOS that will do that comparison over time and across sites. Also, as I'm sure you've noticed, there're still lingerings of "vopo" in all the scripts and folders that I haven't touched yet in the interest of getting the data processed. I'll save both for another day. After all that infrastructure work, and comparison against the model, we clearly have our work cut-out for us, and the terrible T and Y TFs explain why I wasn't able to get rudimentary damping loops to work. TJ has said that he's moved around a cable by H3 that he thinks was rubbing today, so I'll make attempts to remeasure the thing ASAP. Didn't get to it tonight 'cause of the work needed to create the above infrastructure. Sorry!
Non-image files attached to this report




{kind=link}