kyle.ryan@LIGO.ORG - posted 20:59, Sunday 25 February 2018 (40705)
In-chamber work in HAM6 OK now abiding by normal protocol
Significant pressure transition across septum viewport complete
Significant pressure transition across septum viewport complete
Sheila D. Greg G.
Remotely enabled the CO2 lasers from the control room, CO2Y is in the Guardian lock laser state, while X is merely on. The integrators in the chiller control loops have been turned off, and a new chiller limit value was set to try and keep the control loop from giving the chillers a value that causes them to trip.
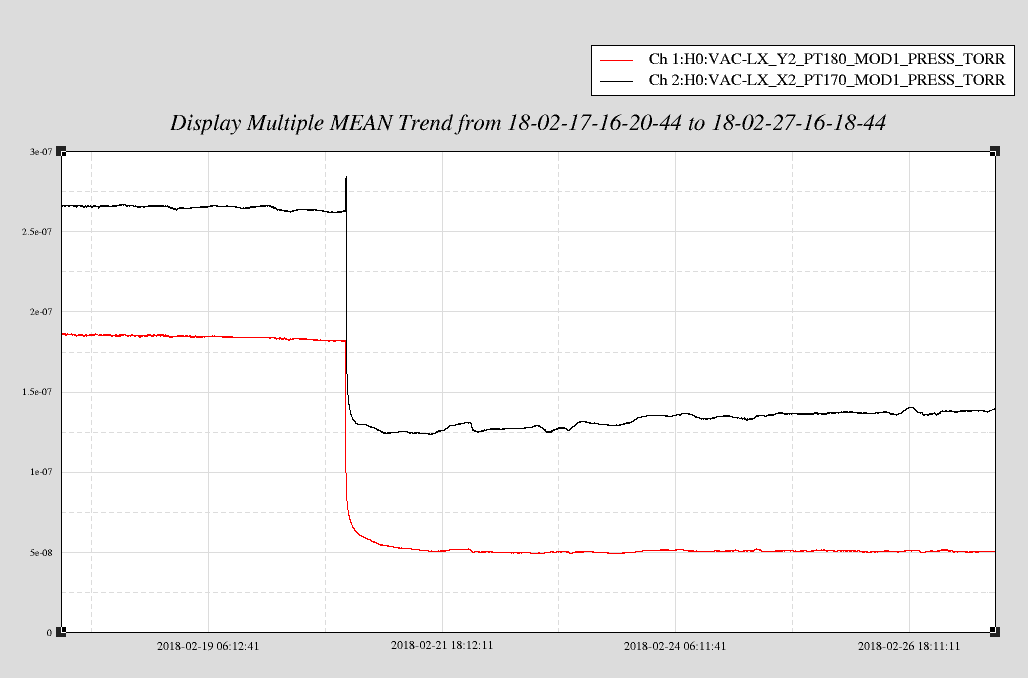
As seen in the attached pressure graph, the XBM pressure isn't following the expected pump down curve. Since GV2 was closed, thus isolating the XBM from the adjacent volumes, the pressure has been rising, flat or not decreasing etc.. In this configuration, IP6 and the XBM MTP are the only pumps pumping. Chandra R. had suspected previously that IP6 may be dying. Even so, I would expect that the symptom would be a loss of net pump speed. With the LVEA temperature constant, I'm wondering if this apparent increase is something else, like.....?
I confirmed that the MTP and IP6 are valved in. 4.9 x 10-9 Torr indicated at Turbo inlet -> PT170 gauge has been questioned in the past and is suspect
Here is a 10 day trend on both beam manifolds. The pressure in XBM seems to have settled. I need to follow up with the manufacturer of these gauges - an ongoing issue.
John and I spent time leak checking the XBM last year after noticing these pressure trends. No leaks found, but we didn't check welds.
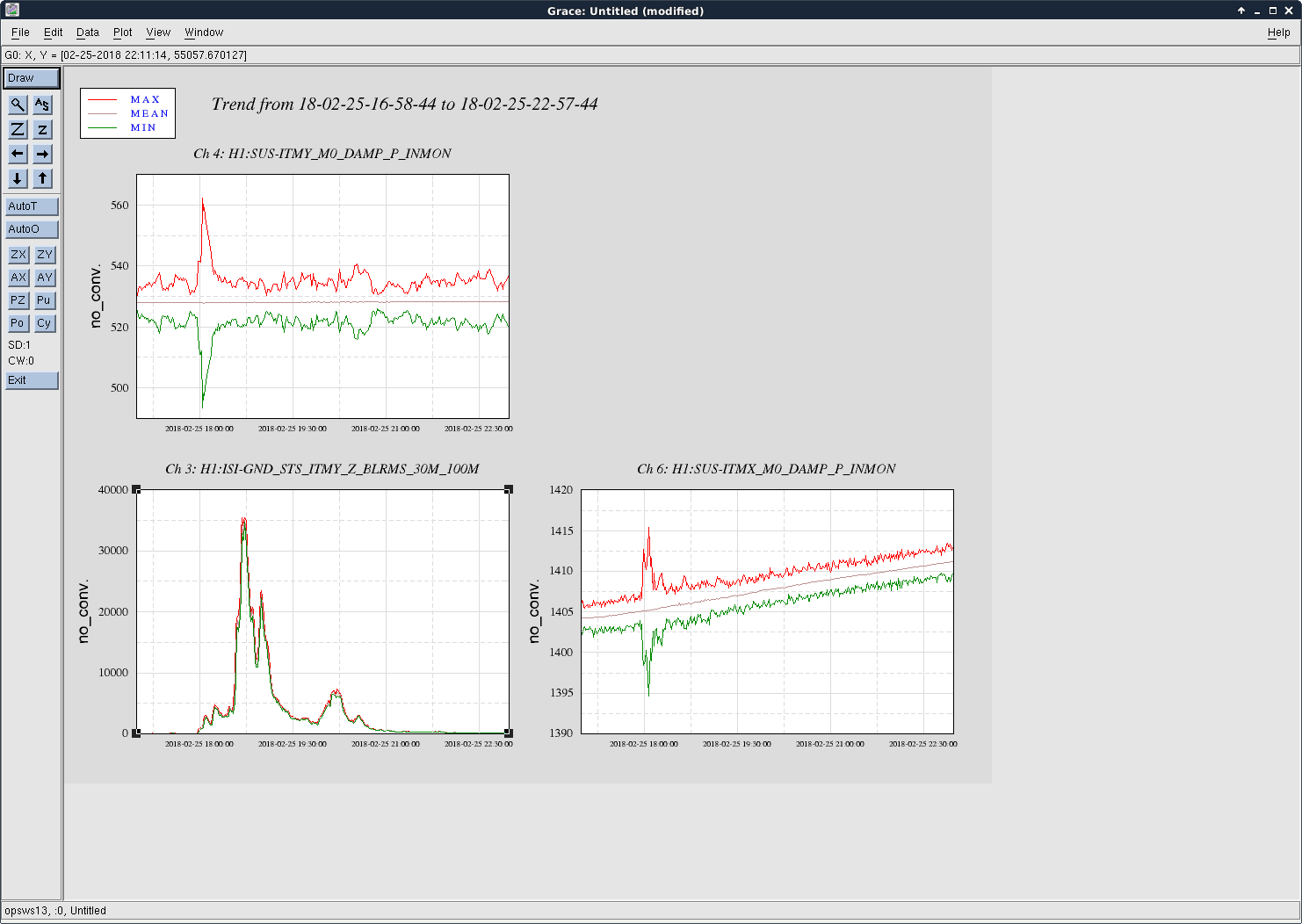
The good news is that it looks like someone must have set our seismic system to the Large EQ mode before this morning's EQ hit, and none of the seismic systems are tripped now, the ISIs are set to damped with feedforward off and sensor correction seems to be off.
ITMY suspension was unfortunately set to safe, I assume this is left over from the fix earlier in the week. The attachment shows a comparison of ITMX and ITMY top mass osems (ITMY oplev beam is not on the QPD in safe mode) during the EQ, ITMY was swinging by more than 60 urad peak to peak while ITMX which had suspension damping loops engaged was swinging by about 20 urad at most.
I've turned on the damping on ITMY now. I also hit the button RECOVER EQ on the ISI_CONFIG screen, I got some errors from the script but it did take the ISIs to the windy state (screenshot attached).
It might be good to add to the operator tasks a check that suspensions and ISIs are in a good state before leaving for the night or weekend. (ie, if suspensions are not damped, operators could make sure they know that it is intentional and there is a good reason for it). Leaving our suspensions damped as much as possible will help us avoid some problems similar to what we had after the Montana EQ last summer. (For reference, while the suspensions were undamped during that EQ they were moving by 10,000 urad peak to peak, so this EQ is not really comparable.)
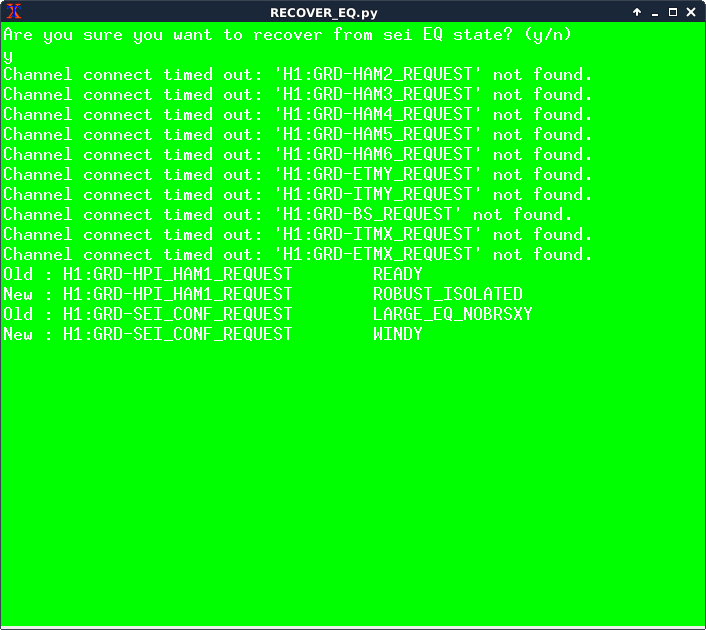
The original script I wrote for recovering the seismic platforms seemed to have been deleted in the svn update, so I had to write a new one and never got a chance to test it. I've fixed the recovery script, tested it and added it to the svn. With the laser down and not much going on in the way of commissioning right now, I would suggest it is safest to leave the seismic configuration in the state that the red button puts everything. The script doesn't touch the suspensions though.
This is probably my fault. I set ITMY SUS to safe on Feb. 21 before Filiberto started disconnecting cables and didn't think to set it back.
Remember that no files were deleted during the SVN 1.6 to 1.8 upgrade. The original userapps working directory was renamed userapps_1.6. If a file is needed in the new userapps area but it is not under SVN control and it should be, please add it to the repository (using userapps_1.6) and then do an svn update in userapps (please do not just copy the file across). I am happy to help.
Details in alog Link
Changes to the suspension state should be explicit in the WP and it should not be closed until all those steps are completed, I should think.
Patrick, I don't think this is anyone in particular's fault, it is just something that is not anyone's responsibility at the moment. We just need to figure out how to make it routine to check that suspensions are damped, which we hadn't had as a part of any checklist before.
I texted Gerardo and Chandra when arriving and will when leaving or 6pm, whichever occurs first. Will also finish rough pumping the Vertex. I expect to be here until around 6pm and will make a comment to this entry when leaving. I can be found in the LVEA, Mechanical Room (Kobelco area), VPW, Y-mid VEA or my office. I won't be craning, on ladders or using power equipment.
Need until 7pm
Leaving site now.
Terry, Daniel, Nutsinee
Two weeks ago ISCT6 got craned over from the SQZ bay to HAM6 (alog40588). We hooked everything back up but was only able to check the alignment when the LVEA became laser Hazard on Thursday. Pretty much everything became misaligned, from small amount of misalignment into the SHG to catastrophic amount of misalignment into the fiber couplers. Below is a summary of the work we did to get the table back to the condition it once was.
SHG
Because we got rid of the extension cables the RF35 phase shifter needed some adjustment (now 193.88 deg) and a sign flip on the common mode board was required. I tweaked the alignment to get rid of a higher order mode. The mode matching is currently 98.6% (about as good as it gets). I took a transfer function to make sure that the UGF hasn't changed (~3kHz). We also took a measurement of shot noise, dark noise, and SHG length noise (weekend, when the LVEA is relatively quiet). These measurements will be posted in a different alog.
Alignment to fiber coupler
Alignment land is still work in progress. We got every thing back up to over 60% and 70% coupling efficiency as of Saturday. For a reference, this is what we were able to achieve before (alog40342) and should be able to get them back to at least the same efficiency given more time. The pump light now has 15.8mW coming out of the fiber. CLF has 10.2 mW coming out of the fiber (still a lot of room for improvement).
CLF AOMs
For a reference, this is what we used to have when the table was in the SQZ bay: alog40198.
We are now getting more RF power coming to the amplifier (extension cables were surprisingly lossy). The top RF amp that drives AOM1 used to not have any attenuator, now has 3dB attenuator at the input. RF power measured at the output to the AOM1 is now 34.29 dBm, or 2.68W. Maximum drive power allowed for this AOM is 2.9W.
The bottom RF amp that drives AOM2 used to have a 6dB attenuator, now has 10dB attenuator. RF power measured at the output to the AOM2 is now 32.83 dBm, or 1.9W (.2dBm less than what it used to be in the SQZ bay). Maximum drive power allowed for this AOM is 2.2W. Putting 9dB attenuator would have given 33.56 dBm (2.27 W) at the output. Which is slightly more than maximum drive power allowed.
AOM1 (IntraAction ATM-200) now has diffraction efficiency of 83%, AOM2 (AA Opto Electronic MT200) now has coupling efficiency of 69.7%.
Flippers
We found that CLF and Pump flipper wasn't working. We were able to open and close the shutter by hand which implies that these flippers were not getting any power. Turns out these DC plugs from Thorlabs are very dodgy. We unplugged the cables and plugged them back in that seems to solve our power issue.
Pump flipper still wasn't working then. It was not getting any signal from Beckhoff. Turns out the new cables from the EE shop we put in for I/O1 was bad (again, how? I have no clue). SQ_259-2 was removed then replaced with a temporary cable. I suspect these bad cables are acting like something of a high resistance. Which would explain the issue we once had with the cable at the output of an RF amplifier (the signal came out to be 30dB less than what it should be). But does that explain why we're not getting any DC signal to the flipper?
Motorized Rotation stages
All working fine.
Stray beams
We went around the table and hunt for any stray beams we could find. Several additional beam dumbs have been installed. There should be no stray beam higher than a milliwatt leaving the table at this point. In fact there should't be any stray beam leaving the table at all. Both red and green.
Nominal laser box settings
Current = 2.182 A
Crystal Temperature = 25.98 C
Diode Temperature = 20.22 C
Kyle, Gerardo, Chandra
We moved PT-245 cold cathode gauge cable to the full-range hot cathode gauge on turbo inlet temporarily for the bake exercise (which caused some alarms today). Thus, the pressure readout (at PT-245 on MEDM) is not accurate - will calibrate in software on Monday; need to read out the voltage displayed on MY screen and convert to mbar per the attached plot. Current reading is 2.38 V which converts to 8e-8 mbar or 6e-8 Torr. Since screen shots read remotely don't capture voltage, we put the voltage display up in the control room, found here: https://lhocds.ligo-wa.caltech.edu/cr_screens/png/video0-1.png
We started to test CP4 regen. First flowed GN2 through the reservoir at 20-50 SCF/H (after LN2 was vaporized in tower outside). Regen controls system needed some work - discovered a few thermocouple wires were backwards, at both the Watlow heater and Beckhoff rack and one of the exhaust TCs does not work due to some broken wires in well - TE252B (note cable in Watlow controller is labeled 253, not 252). We need to figure out how to satisfy the two gate valve "closed" interlocks. We tried to jumper the limit switch signal at Beckhoff, and also the pin switch for LOTO. We'll work with Richard and Patrick on Monday to see what signals the software is looking at. Once we override this interlock we will test the regen heater and Watlow over-limit switch.
Attached are a couple RGA scans from today and from Tuesday. Note that today's scan was taken after cold GN2 was passed through CP4 so there may have been some water pumping. Both are faraday mode.
After scan I turned RGA filament off and valved it out from turbo.
Will resume Monday morning. Note that "in-chamber work" in HAM6 is still prohibited until further notice.
J. Oberling, E. Merilh, P. King
Today we installed the new 35W Front End power monitor pick-off. We removed the unused AOM port from the back wall of the FE (1st attachment), wired the pick-off, and installed it in front of the output of the MOPA (2nd attachment). The half-wave plate in front of the FE FI was adjusted to minimize the NPRO power delived to the MOPA and the NPRO current was decreased from 2.222A to 1.0A. This was to minimize the output of the FE while adjusting and aligning the new pick-off. Using a WinCAM, we positioned the pick-off such that it was not clipping the beam, and aligned it using the 3 set screws (can be seen on the 2nd attachment) to maximize the signal seen by Beckhoff; this was a very tedious and time-consuming process. Once the PD output was aligned we slowly increased the NPRO current back to its nominal operating value of 2.222A. All being good, we then adjusted the half-wave plate to deliver the maximum NPRO power to the MOPA. Once again, there were no issues with the beam profile and the output power of the MOPA read 36.2 W. We calibrated the new pick-off to this value.
On Monday, we will recover the alignment to the PMC if necessary (the new pick-off could potentially change this alignment), then proceed with installation of the new PBSC and half-wave plate. These 2 components replace the mirror that is currently being used to direct the beam into the HPO, and allow us to change the beam path either toward the 70W amplifier or toward the HPO; the latter will allow operation of the just the 35W FE laser, if necessary.


Fixed the display logic for Out 2 on the CM board medms.
TITLE: 02/23 Day Shift: 16:00-00:00 UTC (08:00-16:00 PST), all times posted in UTC STATE of H1: Planned Engineering LOG: 15:52 UTC Terry to LVEA to work on squeezer table 16:24 UTC Nutsinee to ISCT6 16:53 UTC Ed to end X, Filiberto to ISCT6 (Beckhoff safety) 17:01 UTC Filiberto done 17:06 UTC Gerardo to LVEA to unpause pumping of vertex 17:06 UTC Ed starting work at end X 17:11 UTC Peter to chiller/diode room for documentation 17:13 UTC Ed to end Y 17:28 UTC Ed starting work at end Y 17:32 UTC Ed done, heading back 17:39 UTC Peter done 17:41 UTC Marc to mid Y to drop off and receive parts 18:07 UTC Marc back 18:08 UTC Georgia to end Y, taking electric field measurements with grounded battery pack 18:20 UTC Jason to PSL enclosure 18:25 UTC Alvaro to optics lab 18:26 UTC Betsy and Travis to end Y to realign ETMY 18:33 UTC Ed to PSL enclosure 18:40 UTC TJ to optics lab 19:35 UTC Georgia back 19:47 UTC Filiberto to LVEA to install safety relay for SQZ laser interlock 20:08 UTC Betsy and Travis back 20:09 UTC TJ back 20:20 UTC Sheila to optics lab 20:30 UTC Ed and Jason back 20:31 UTC Sheila back 20:31 UTC Nutsinee back 20:53 UTC Travis and Betsy to end Y 21:01 UTC Richard to LVEA 21:10 UTC Alvaro back from optics lab 21:29 UTC Jason and Ed to PSL enclosure 21:44 UTC Peter to PSL enclosure 21:44 UTC Nutsinee to ISCT6 21:56 UTC Greg to LVEA to turn on TCS laser power supplies 22:04 UTC Filiberto to CER 22:09 UTC Greg back 22:10 UTC Alvaro to optics lab 22:15 UTC Mark to mid Y 22:42 UTC Gerardo to mid Y to connect Inficon gauge to ADC for PT-245 22:48 UTC Filiberto done 23:43 UTC Ed back 00:09 UTC Betsy and Travis back
Late entry.
Pump down of the vertex was restarted today at 17:10 utc.
Terry and I finished the final output paths of on the VIP last week and monday. The last thing that we checked with laser beams on the platform was adjusting the alignment through the Faraday to reduce the misalignment caused by moving the lens translation stage from one extreme of its range to the other. Alvaro helped us to check this using an iris about a meter away from the platform, when we started the beam was about 5mm lower with the translation stage at it's closest position to the Faraday than at its furthest. After we adjusted the pointing into the Faraday the beam still moves vertically up by about 1 mm as the lens is moved from the closest position to the Faraday to the furthest from the Faraday.
In the squeezing output path, we installed the dichroic 182mm from the edge of the OPO box, which means it is just over 226mm from the AR side of M1 to the dichroic. We placed the dichroic (labeled DM1 on page 6 pf D1500302-v5) in about a half inch further from the OPO than was done at LLO to avoid mechanical interferences between our waveplate mounts. The ROC=+50mm lens (E1600300) is 350 mm from M1, (122mm from the dichroic DM1).
The next steering mirror labeled DM2 on page 6 pf D1500302-v5 is actually not a dichroic, but HR for 1064 (LLO had one more dichroic than we did), and it is 172mm from the dichroic DM1.
The ROC=+150mm lens on the translation stage is 498 mm from the steering mirror DM2, which means it is 900 mm from M1 when it is in the center of its range.
I've attached some photos of the VIP after Alvaro and TJ added cables and balanced it. I tried to give names to the photos that I think are most useful, including ones that show the settings on the waveplate rotation stages.
The CLF and green pump path waveplates were set to minimize the appearance of modes from horizontally polarized light in OPO scans. The one at the input to the Faraday isolator was set to maximize transmission of the IR through the OPO to the output of the Faraday, and the waveplate directly after the Faraday rotator was set to maximize transmission using the beam used to test the Faraday.



























Betsy and I worked today on realigning the ETMy SUS to the correct OpLev beam as indicated by PCal and TMS reflections. This involved the Quad-typical, many-many iteration adjustment of the both the main and reaction chain, OSEMs, EQ stops, and so on. We eventually converged on a happy suspension and took a few very preliminary TFs that look reasonable. We'll take a full set of TFs on Monday morning as the other teams are gearing up for their work in that chamber.
Peter, Lisa
(same entry as LLO log entry 37917)
Following up the discussion we had at the ISC meeting today about the scattered light peaks in DARM at LLO when the SQZ beam diverter is closed, Peter pointed out that the black glass used on the back of all of the beam diverters is not coated, so there is probably no good reason to believe that the reflectivity is much lower than that of uncoated glass, R=8%.
So we went back and look at HAM6 drawings and pictures, and the most likely explanation is that we are simply sending some light from the beam diverter toward the region of HAM6 where OM2 and the HR in the OMC transmission path is, and light can easily find a path to the OMC. So, it seems that the simplest thing to do at LHO is to put a beam dump to catch the reflection off the beam diverter black glass.
Completed in-rack cabling for the SR3 Heater Chassis D1700493 in the CER. Power, ADC, and DAC cables are now connected. The field cabling to the chamber (thermocouples and heater cable) were left disconnected. Chamber side is still missing connector for vacuum feed-through.


{kind=link}