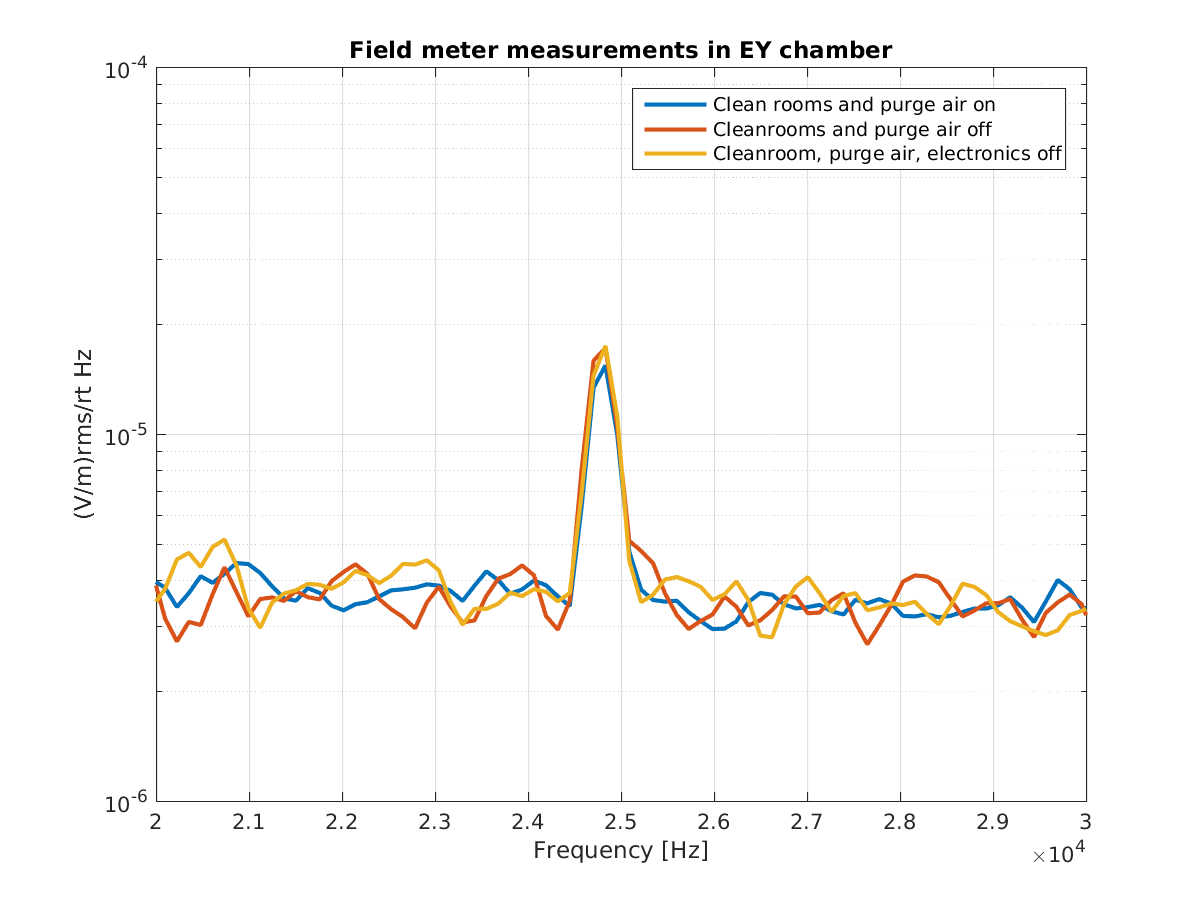
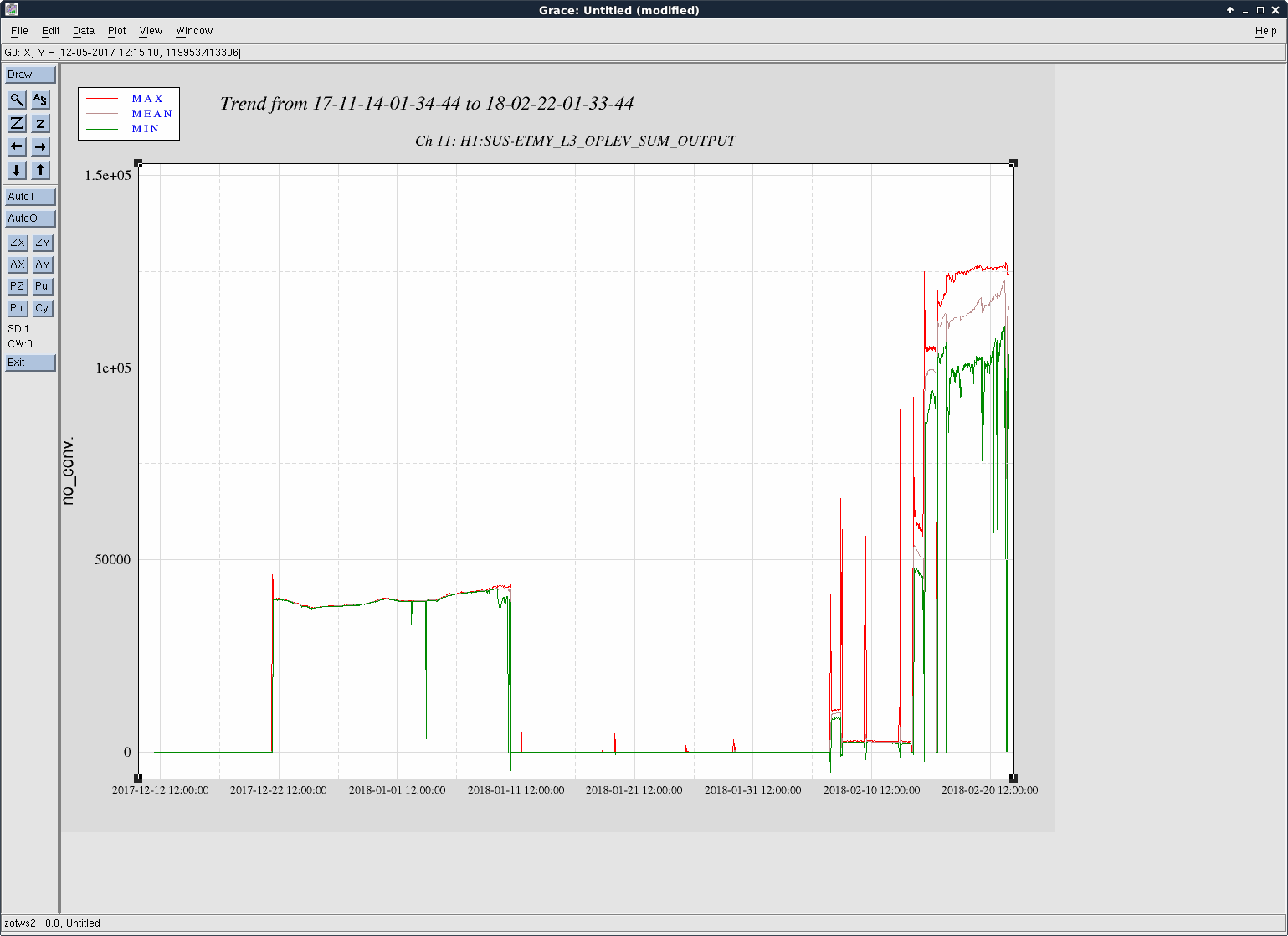
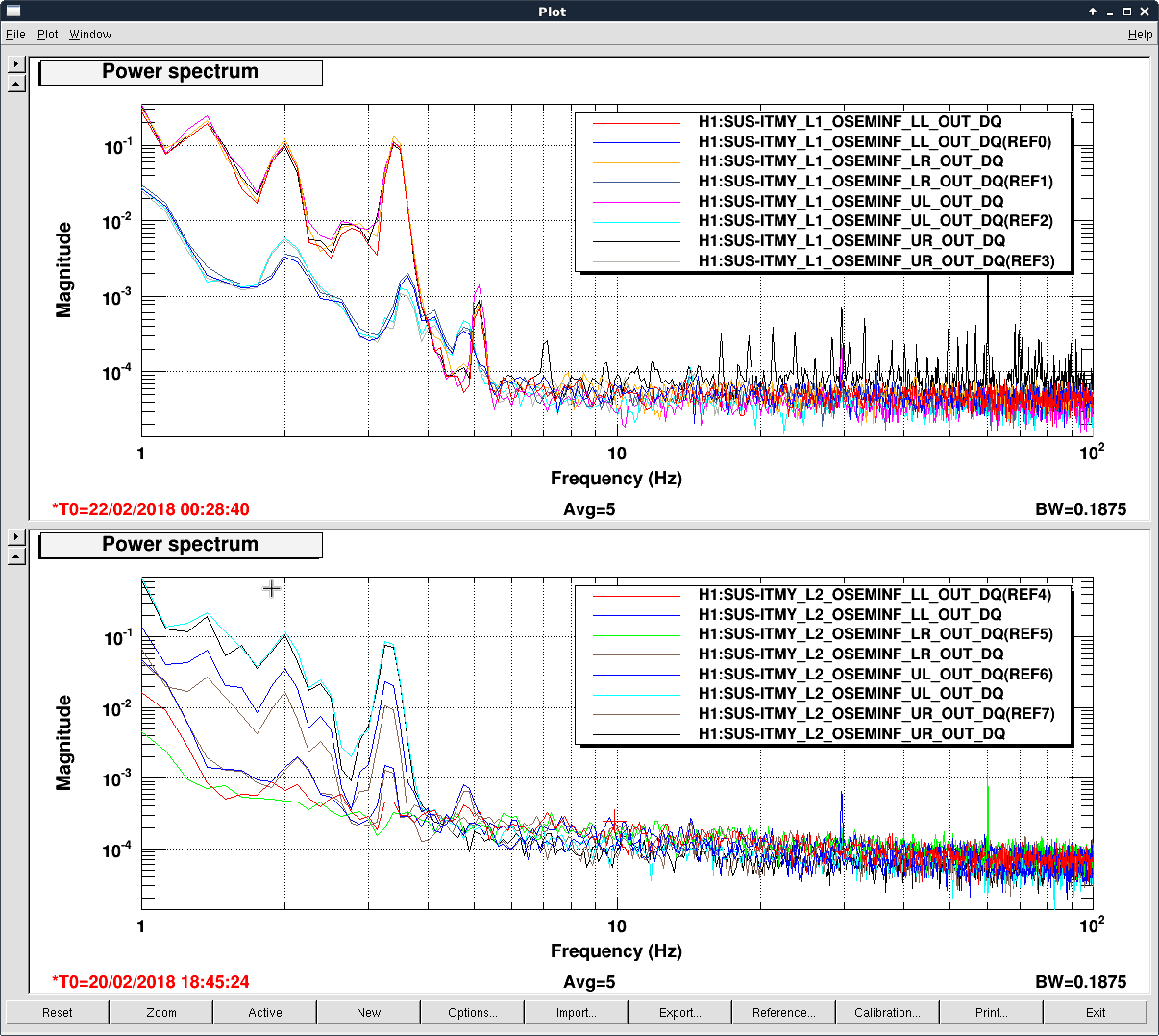
TITLE: 02/22 Day Shift: 16:00-00:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Planned Engineering
INCOMING OPERATOR: None
LOG:
16:00 (8:00) Start of shift
16:18 (8:16) Maik to laser enclosure
16:26 (8:26) Bartlett swapping out laser chillers
16:52 (8:52) Corey to LVEA -- grab a screw
16:56 (8:56) Corey back from LVEA
17:02 (9:00) Ed and Fil to EX -- work on safety system
17:05 (9:05) Gerardo to LVEA -- retrieve items
17:05 (9:05) TJ to Optics Lab -- VOPO work
17:14 (9:14) Gerardo out of LVEA
17:14 (9:14) Gerardo to End-X
17:17 (9:17) Bartlett to LVEA -- Getting parts
17:24 (9:24) Jeff to Optics Lab -- VOPO work
17:25 (9:25) Jason to PSL enclosure
17:28 (9:28) Chandra to Mid-Y
17:30 (9:30) Richard to HAM6 -- put up warning signs
17:35 (9:35) Jeff and TJ out of Optics Lab
17:35 (9:35) Jeff and TJ to End-Y -- pick up component
17:36 (9:36) Bubba and Chris to End-X -- swapping batteries, straightening up
17:38 (9:38) Ed and Fil back from End-X
17:47 (9:47) Richard out of HAM6
17:48 (9:48) Bartlett out of LVEA
17:49 (9:49) Alvaro to Optics Lab
18:05 (10:05) TJ and Jeff back from End-Y
18:05 (10:05) TJ and Jeff to Optics Lab
18:29 (10:29) Nutsinee and Sheila to Optics Lab
18:40 (10:40) Nutsinee out of Optics Lab
18:44 (10:44) Corey to SQZ Bay -- grabbing panel
19:17 (11:17) Sheila out of Optics Lab
19:18 (11:18) Fil and Ed to End-X
19:20 (11:20) Keita Georgia and Betsy back from End-Y
19:25 (11:25) Rick and Travis to End-Y -- PCal work
19:39 (11:39) Jeff out of Optics Lab
19:42 (11:42) Bartlett back from chiller swap
19:59 (11:59) Rick and Travis back from End-Y
20:00 (12:00) TJ and Alvaro out of Optics Lab
20:02 (12:02) Fil and Ed back from End-X
20:02 (12:02) Richard to LVEA -- look at squeezer table
20:04 (12:04) Jason and Maik to diode room
20:13 (12:13) Jason and Maik out of diode room
20:22 (12:22) Nutsinee to ISCT6
20:32 (12:32) Sheila and Terry to Optics Lab
21:41 (13:41) Peter to Diode Room -- move equipment
21:42 (13:42) TJ to Optics Lab -- VOPO work
21:44 (13:44) Sheila Georgia Salvo Terry to Optics Lab
21:45 (13:45) Nutsinee out of ISCT6
21:46 (13:46) Peter out of Diode Room
22:02 (14:02) Ed and Fil to End Stations -- set up emergency stop buttons
22:04 (14:04) Rick and Marek to LVEA -- grab headsets
22:12 (14:12) Georgia and Salvo out of Optics Lab
22:30 (14:30) Nutsinee out of ISCT6
22:35 (14:35) Corey to SQZ Bay -- Deliver panels
22:43 (14:43) Gerardo back from End-X
22:50 (14:50) Corey out of SQZ Bay
23:08 (15:08) Chandra to Mid-Y
23:14 (15:14) Ed and Fil back from End Stations
23:29 (15:29) Ed and Fil to HAM6 -- high voltage cabling
23:50 (15:50) TJ out of Optics Lab
00:00 (16:00) End of shift