TITLE: 02/09 Day Shift: 16:00-00:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Planned Engineering
INCOMING OPERATOR: None
LOG:
15:52 (7:52) Bubba, guest to LVEA, Vertex
16:00 (8:00) Start of shift
16:16 (8:16) Hugh to LVEA
16:16 (8:16) Bubba, guest out of LVEA
16:23 (8:23) Hugh out of LVEA
17:15 (9:15) Peter to LVEA
17:19 (9:19) Peter out of LVEA
17:24 (9:24) Corey to Optics Lab -- Pick up parts
17:24 (9:24) Karen to Mid-Y
17:33 (9:33) Corey to LVEA -- Deliver parts
17:50 (9:50) Peter, Phil to End-Y, End-X -- Access control installation
18:05 (10:05) Karen leaving Mid-Y
18:06 (10:06) Corey back from LVEA
18:23 (10:23) Travis to End-Y
18:26 (10:26) Terry to SQZ Bay -- Place optics, label cables
18:26 (10:26) Sheila, Georgia to HAM6
18:37 (10:37) Richard, Phil, Peter to End-X
18:40 (10:40) Nutsinee to SQZ Bay
18:40 (10:40) Travis back from End-Y, going to Optics Lab
18:49 (10:49) Mark to Mid-Y
18:56 (10:56) Mark to CER -- Sticker delivery
19:00 (11:00) Mark back from CER
19:01 (11:01) Jason to LVEA -- Grab cart
19:12 (11:12) Jason out of LVEA
19:13 (11:13) Mark back from Mid-Y
19:14 (11:14) Richard back from End-X
19:50 (11:50) Jason to PSL enclosure -- Delivering equipment
19:57 (11:57) Jason back from PSL enclosure
20:10 (12:10) Evan to Electronics Bay -- Take photos
20:11 (12:11) Nutsinee out of SQZ Bay
20:15 (12:15) Evan back from Electronics Bay
20:42 (12:42) Corey back from Optics Lab
20:47 (12:47) Nutsinee to SQZ Bay
20:53 (12:53) Elizabeth to End-X -- Installing network switch
21:07 (13:07) Hugh to Optics Lab
21:10 (13:10) Betsy and Travis to End-Y -- ETMY work
21:19 (13:19) Elizabeth back from End-X
21:32 (13:32) Mark to Mid-X
21:52 (13:52) Nutsinee back from SQZ Bay
23:12 (15:12) Hugh to LVEA
23:35 (15:35) Ken back from Mid-X
23:49 (15:49) Travis and Betsy back from End-Y
23:59 (15:59) Hugh out of LVEA
00:00 (16:00) End of shift
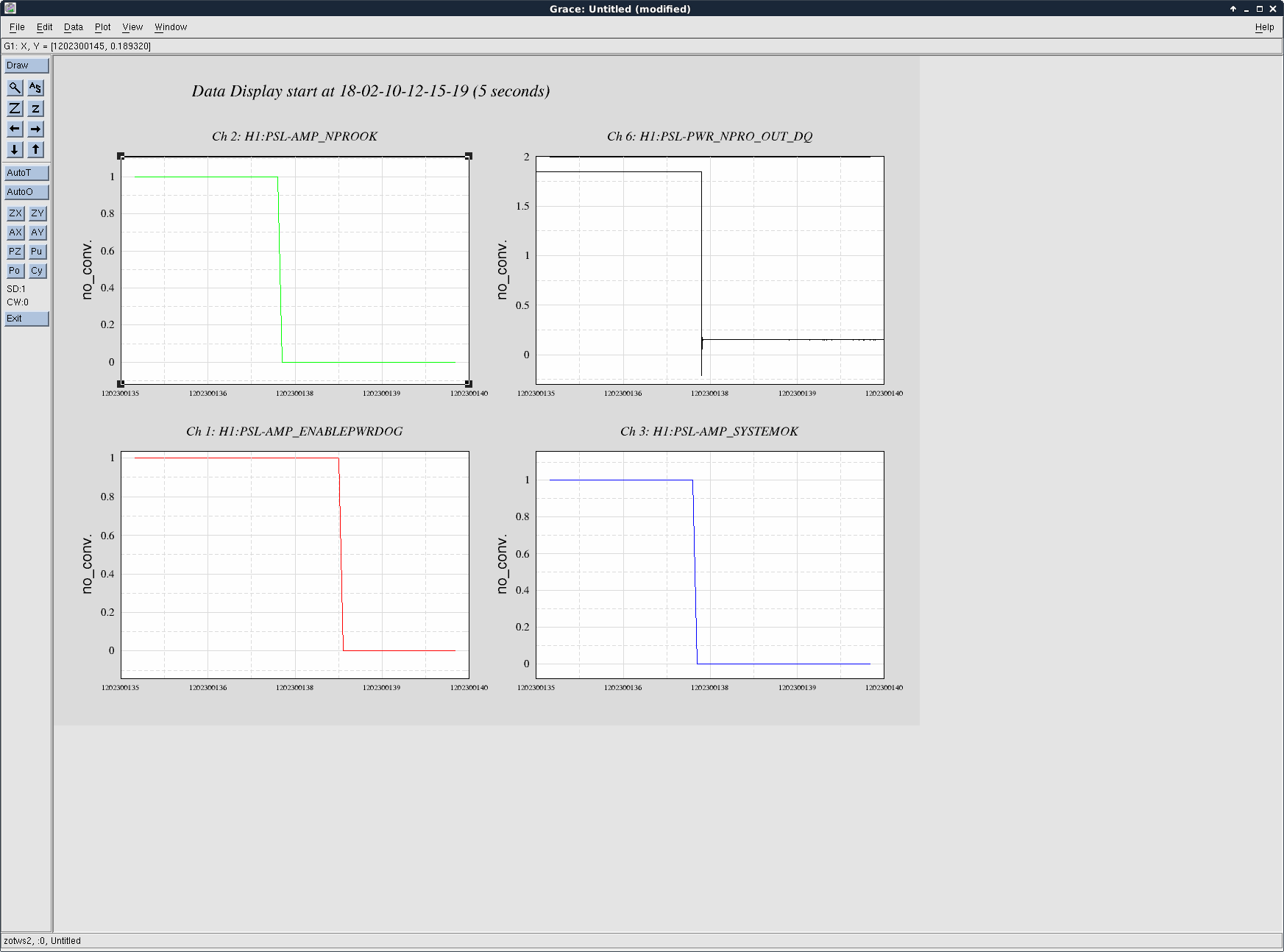
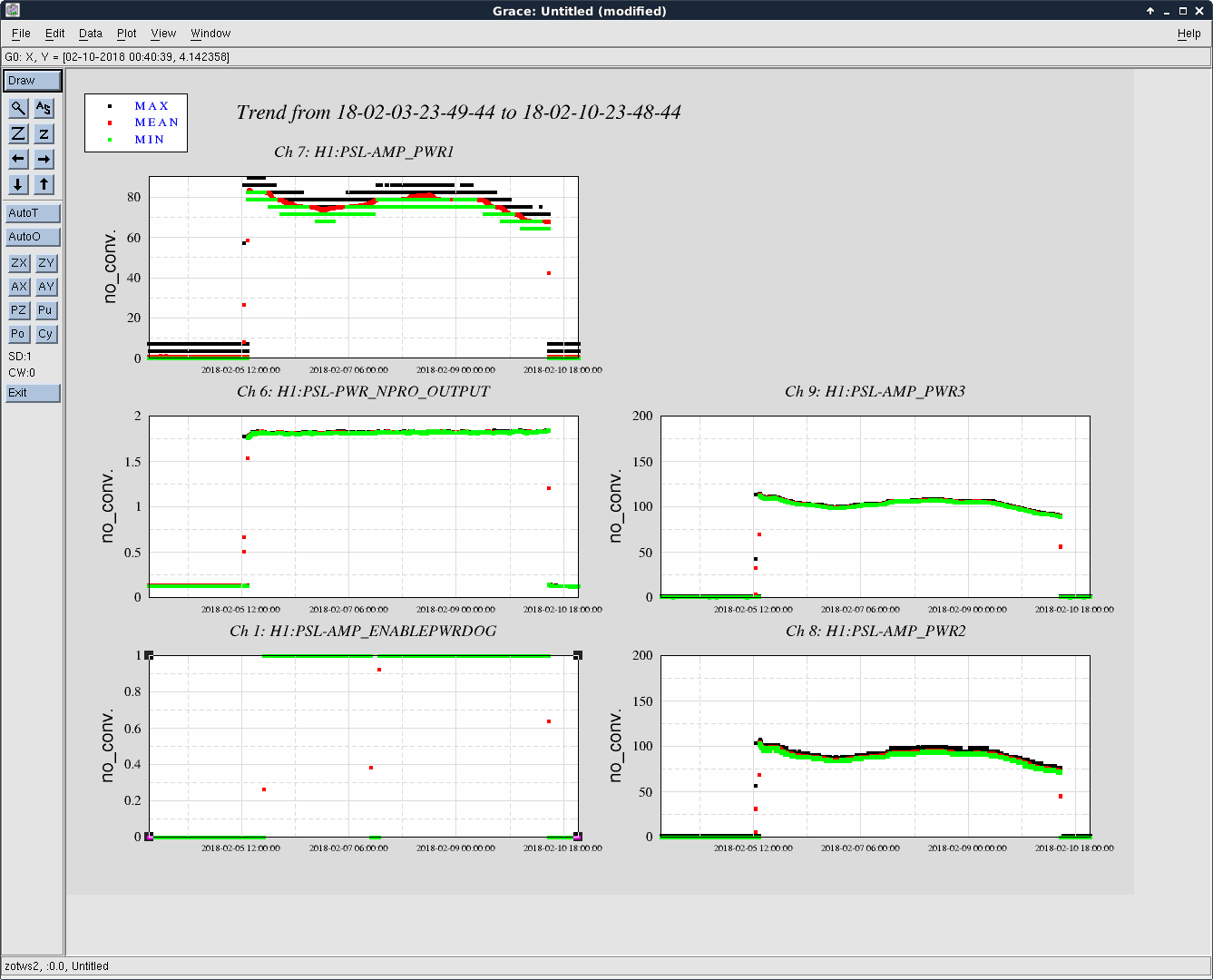
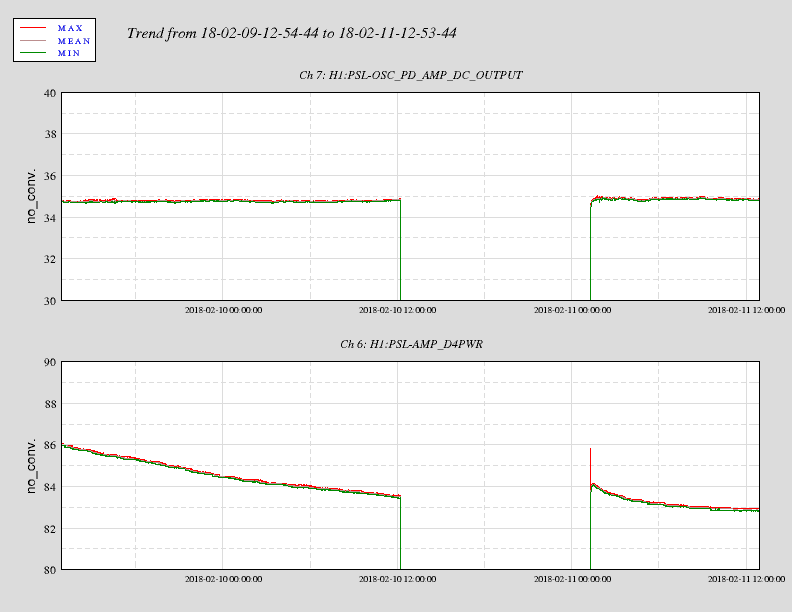
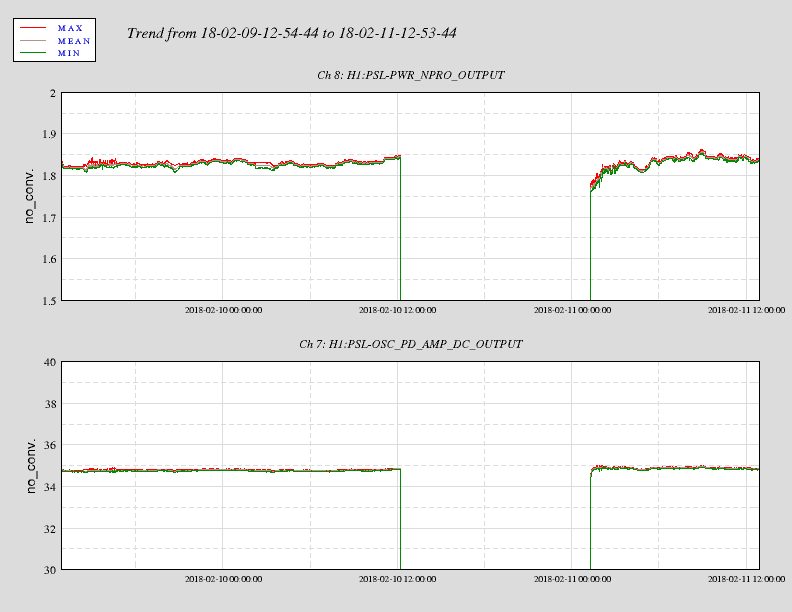
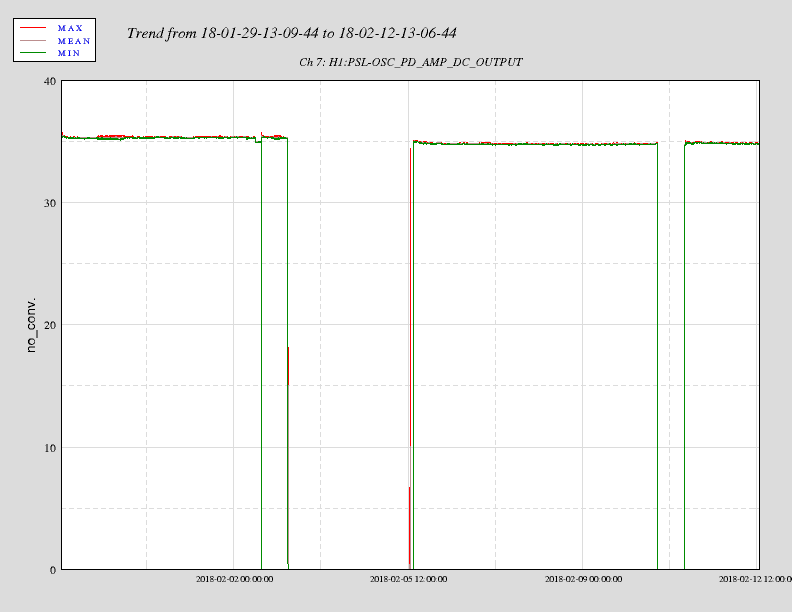
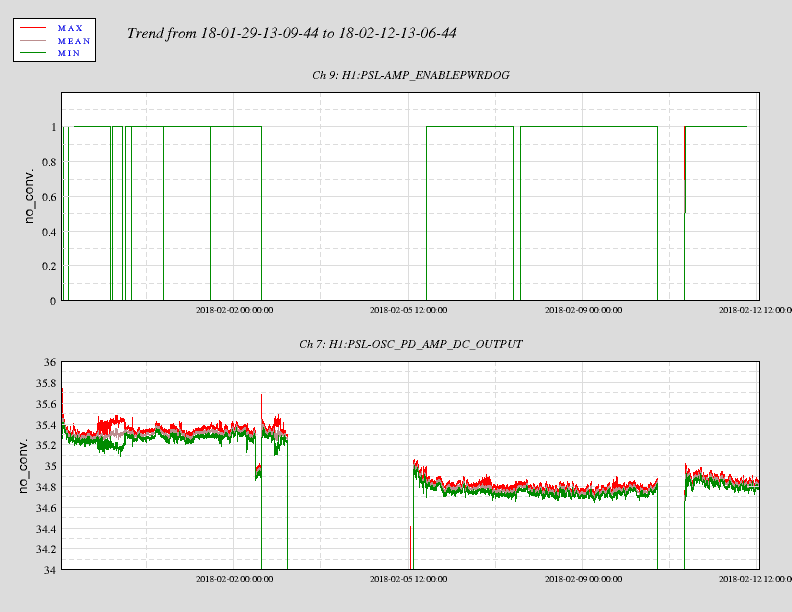
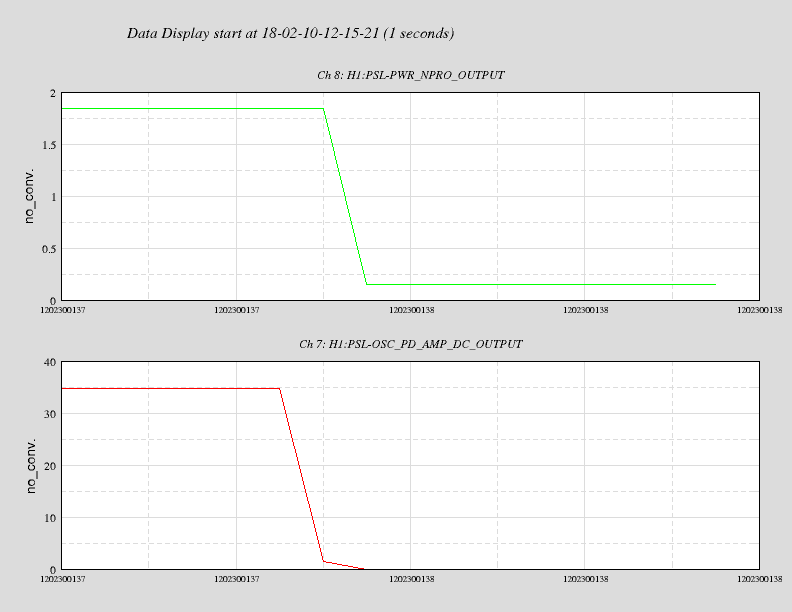
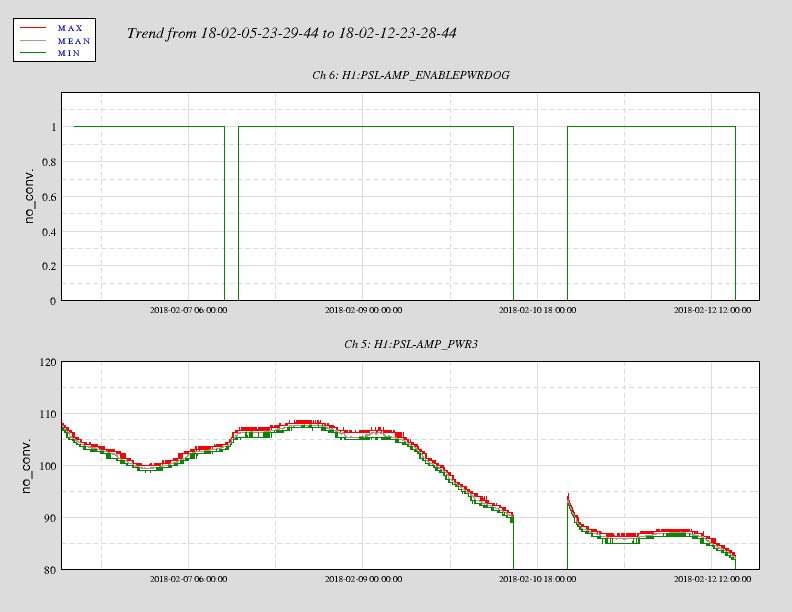

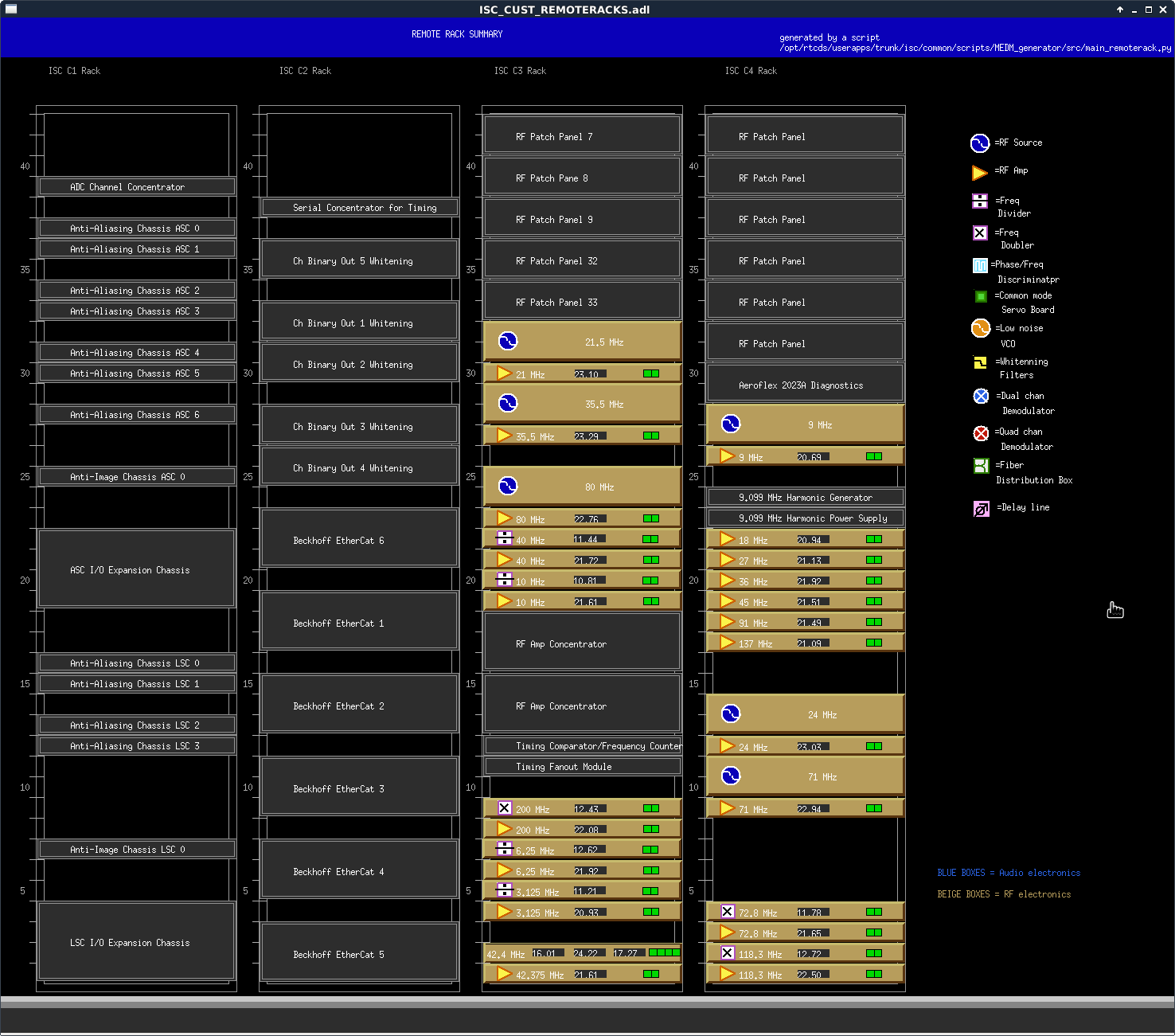
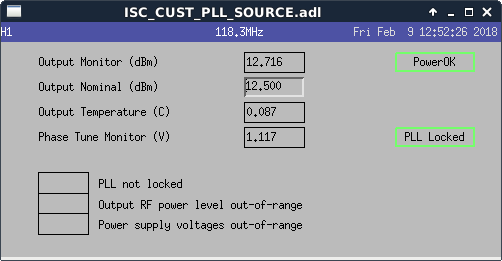


affirmative. The LN2 alarm level is 80%, CP4 just went below that. We'll reconfigure CP4's alarms tomorrow.