jeffrey.kissel@LIGO.ORG - posted 17:20, Friday 20 October 2017 (39113)
HAM2 PSL Down Periscope B&K Hammered
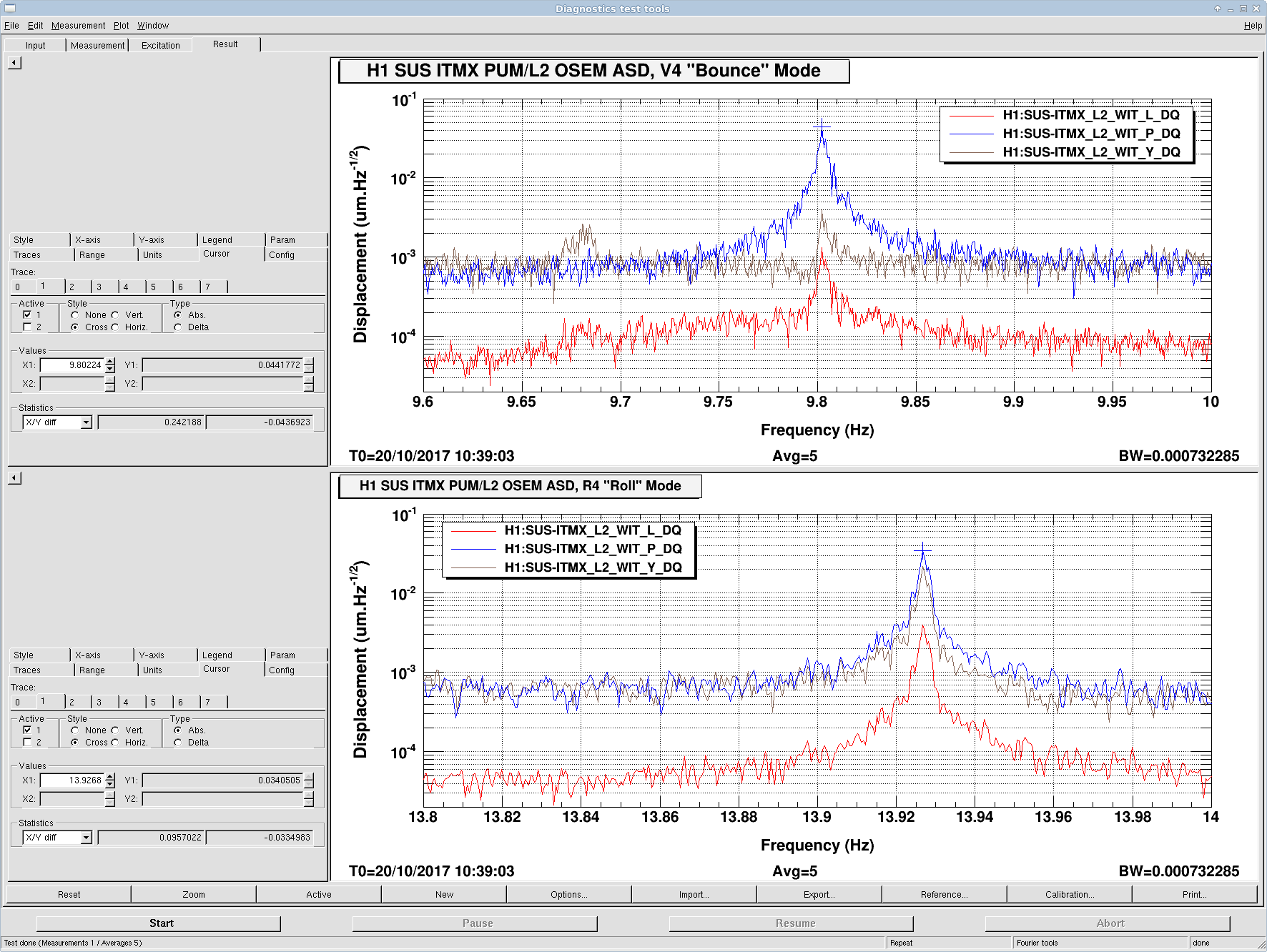
J. Kissel While in HAM2 finishing up the IM B&K hammering, I took some similar transfer functions of the PSL to MC1 Down Periscope (D0901093), because I noticed that it was of particularly high Q when I dinked it with a 3/32 hex key. Pictures attached, results to be process and posted later.
Images attached to this report