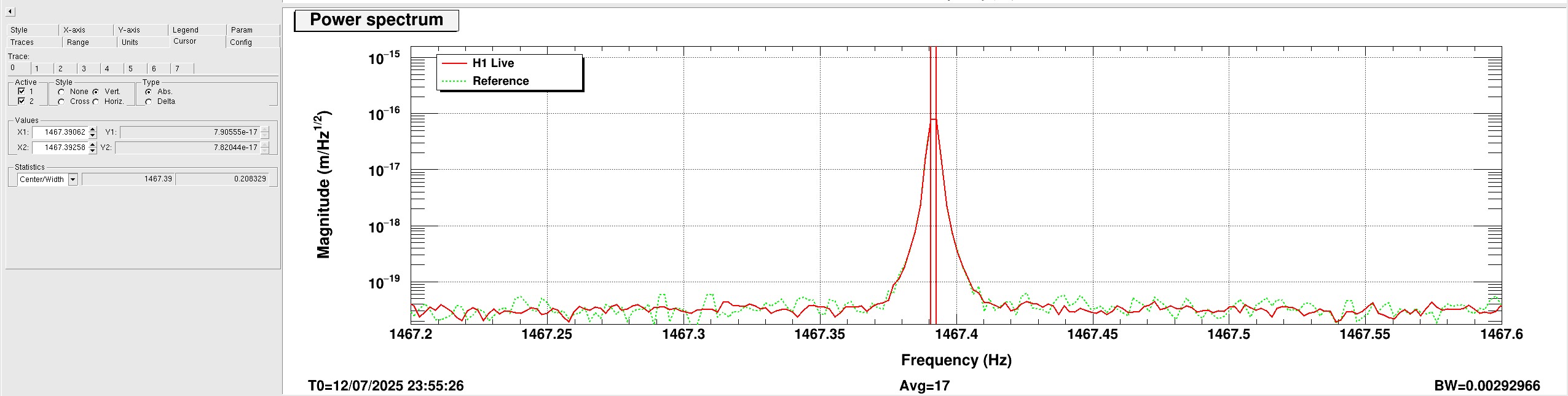
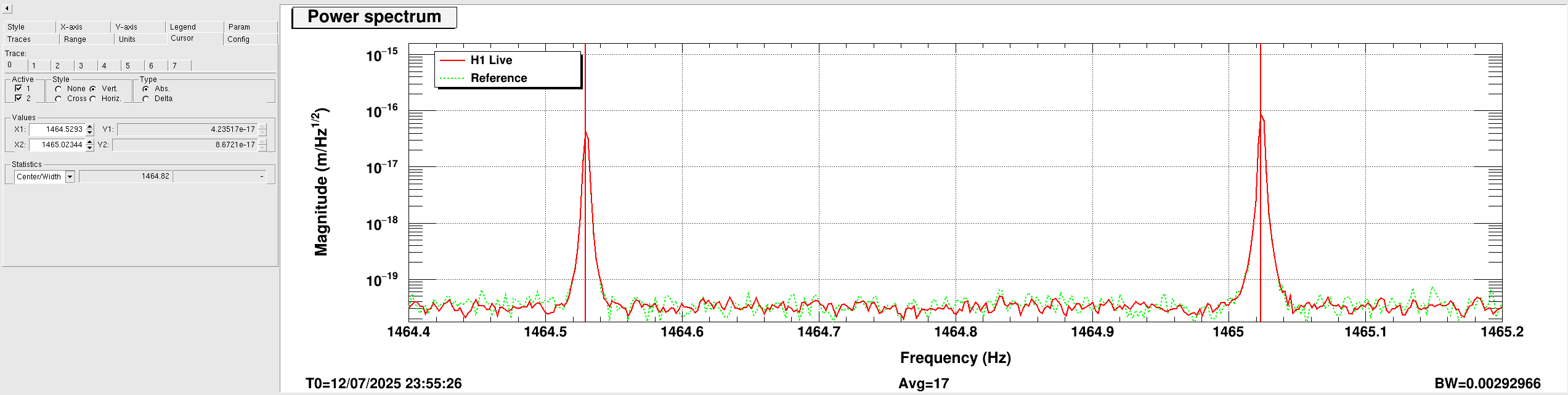
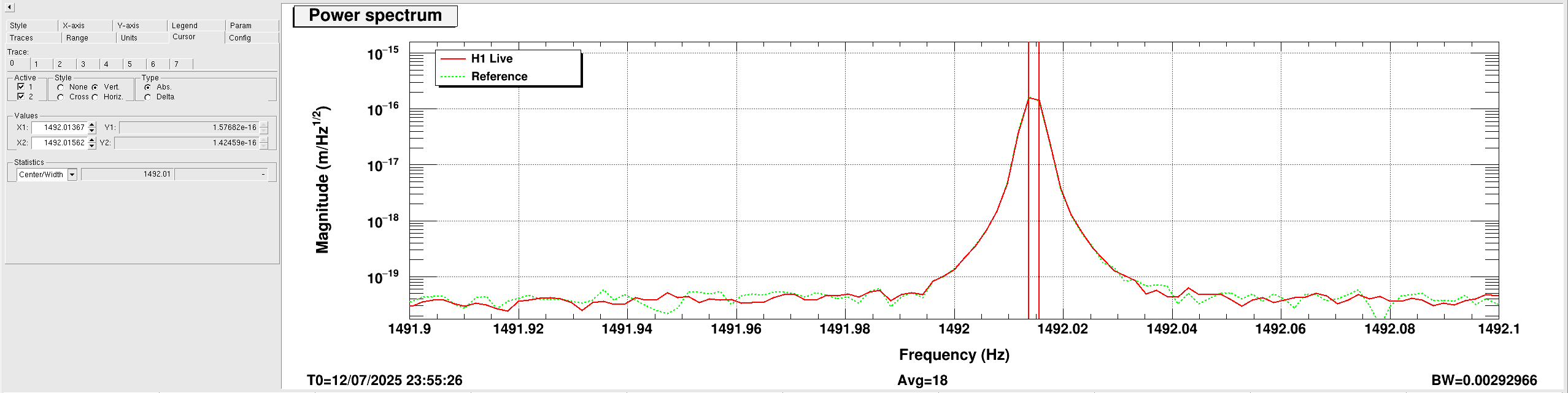
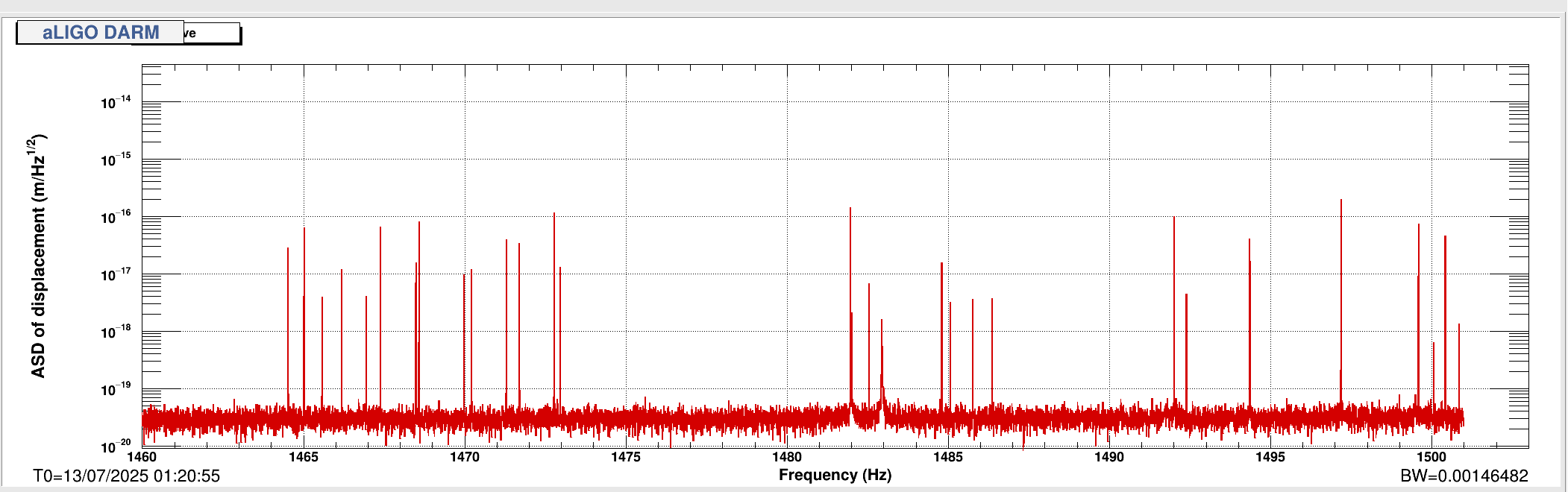
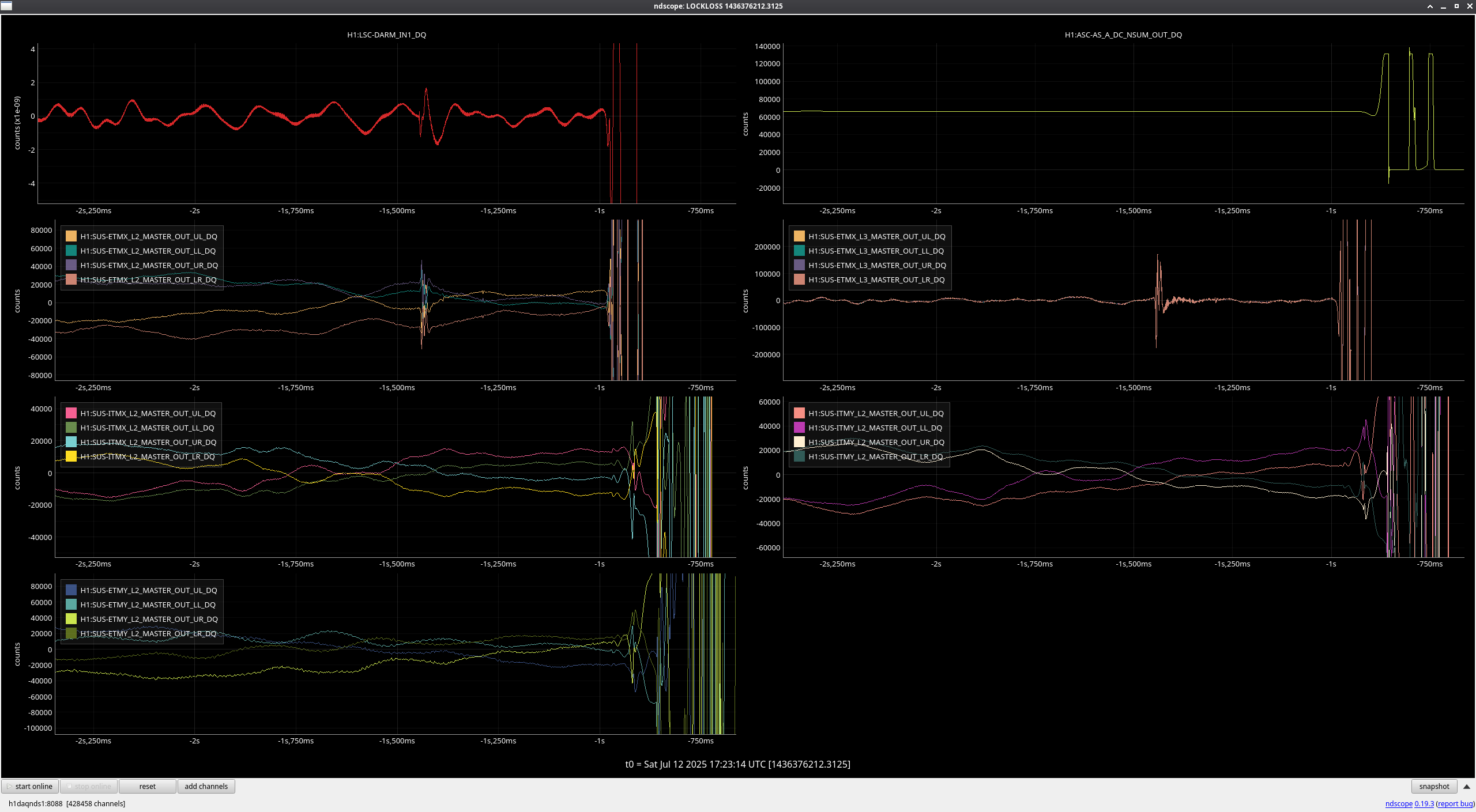
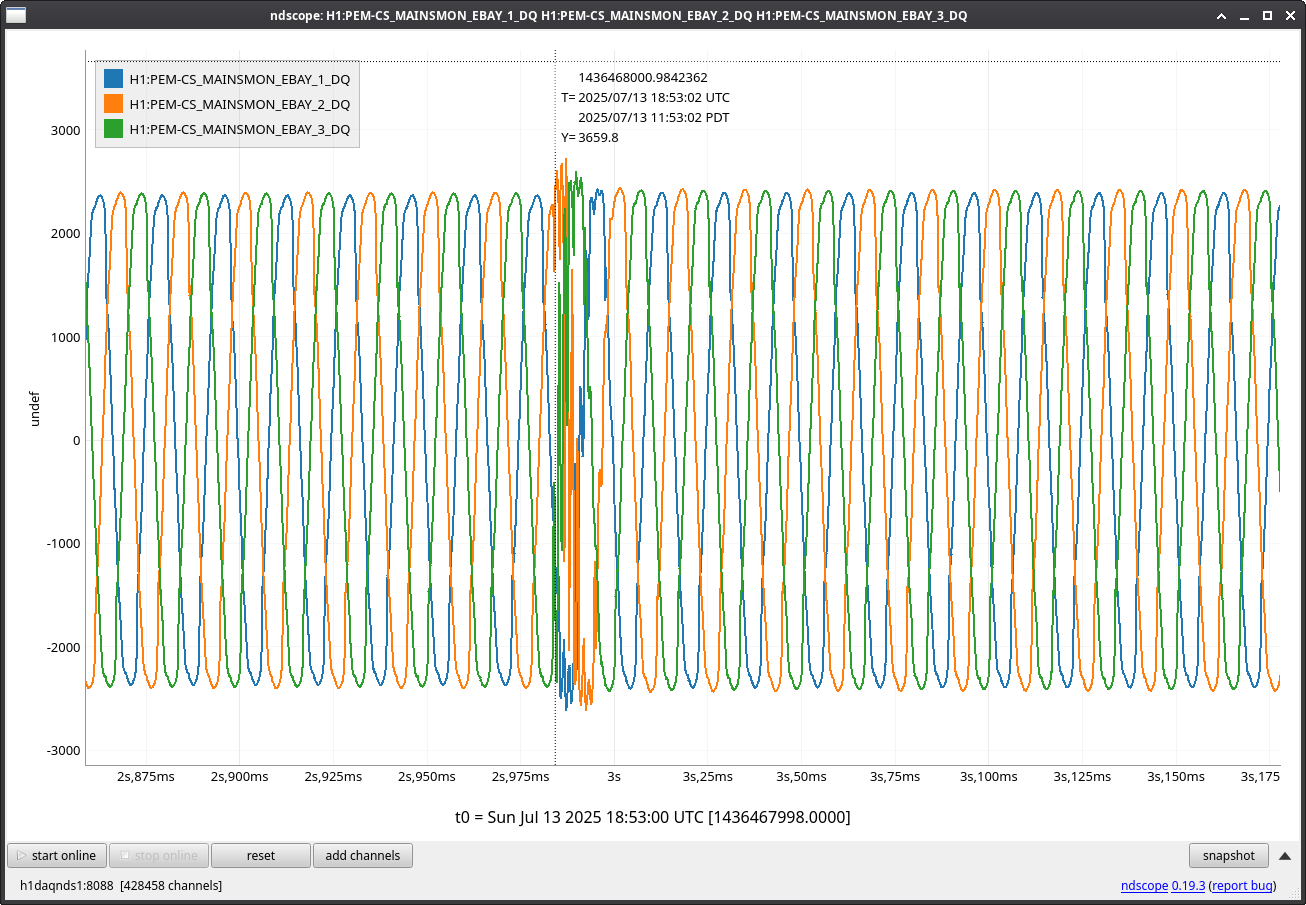
ryan.short@LIGO.ORG - posted 12:19, Sunday 13 July 2025 - last comment - 08:42, Monday 14 July 2025(85722)
Lockloss @ 18:53 UTC - Power Glitch
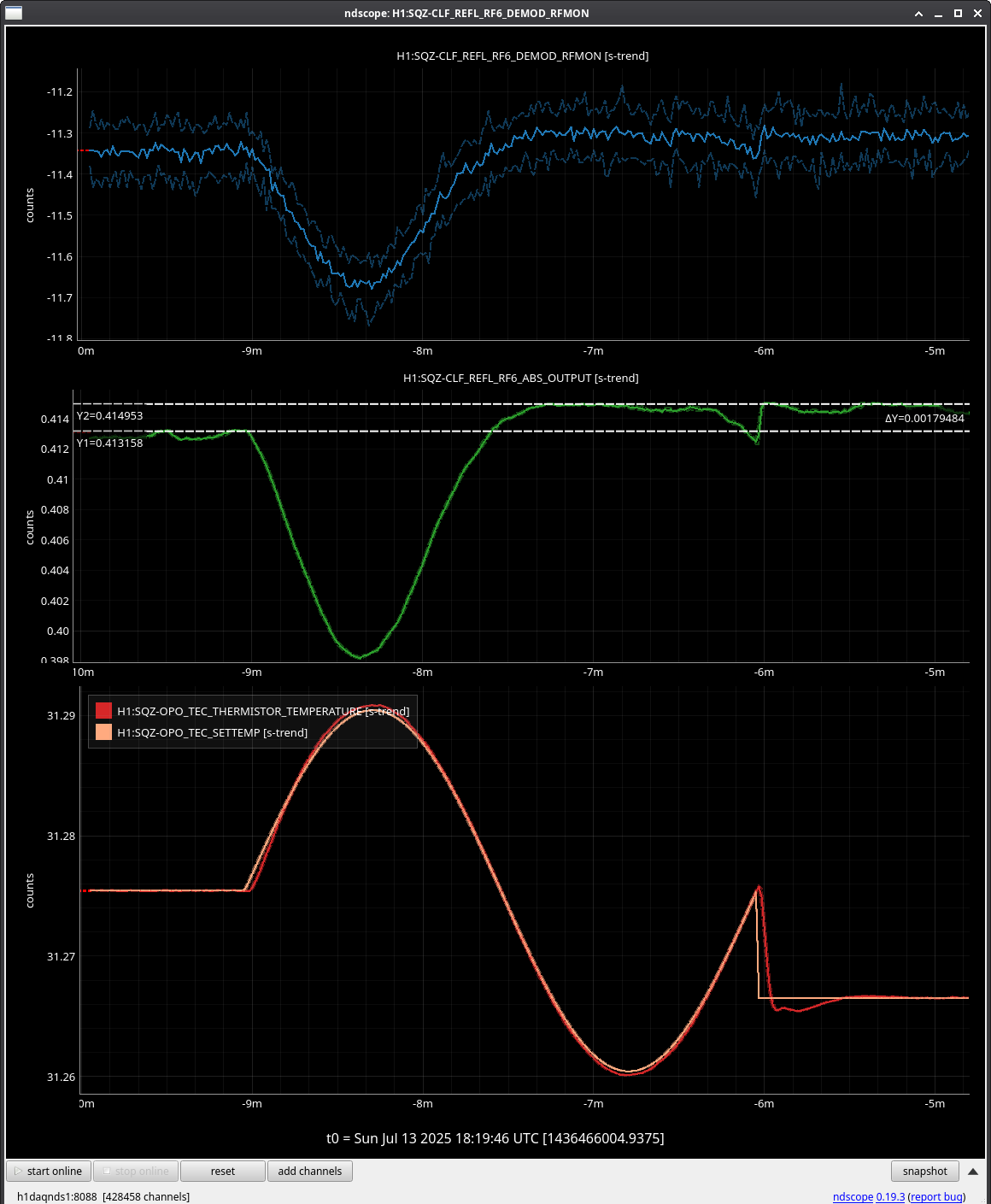
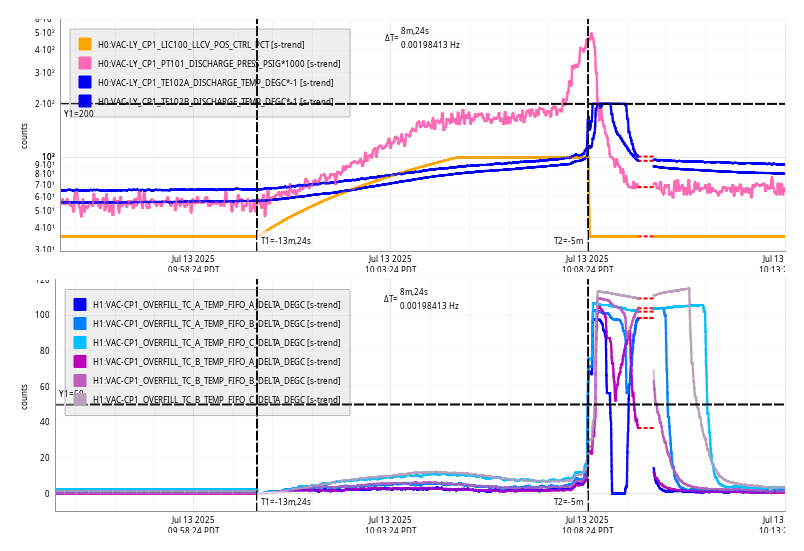
Lockloss @ 18:53 UTC from site power glitch, trend attached. This tripped the end station HEPI pump controllers (and so far nothing else, that I've noticed), so I consulted with Jim and he walked me through what needs to be done to reset them. Heading out to the end stations now.
Images attached to this report
Comments related to this report
Pump stations and all seismic systems fully recovered. Starting an initial alignment now.
H1 back to observing at 21:50 UTC. Initial alignment and lock acquisition both ran fully automatically and without issues.
Note that none of the UPS units emailed us regarding this event, which is unusual for a glitch which caused HEPI pump controller issues.
Jonathan checked the front panel on the MSR UPS and confirmed it logged nothing at the time of this power glitch.