J. Kissel
Still hunting for what's limiting our range, we took Valera's suggestion to drive stage 2 (ST2) the test masses' BSC-ISIs to check for, among other mechanisms,
(a) scattered light problems,
(b) charge coupling issues, or
(c) mechanical shorting / rubbing
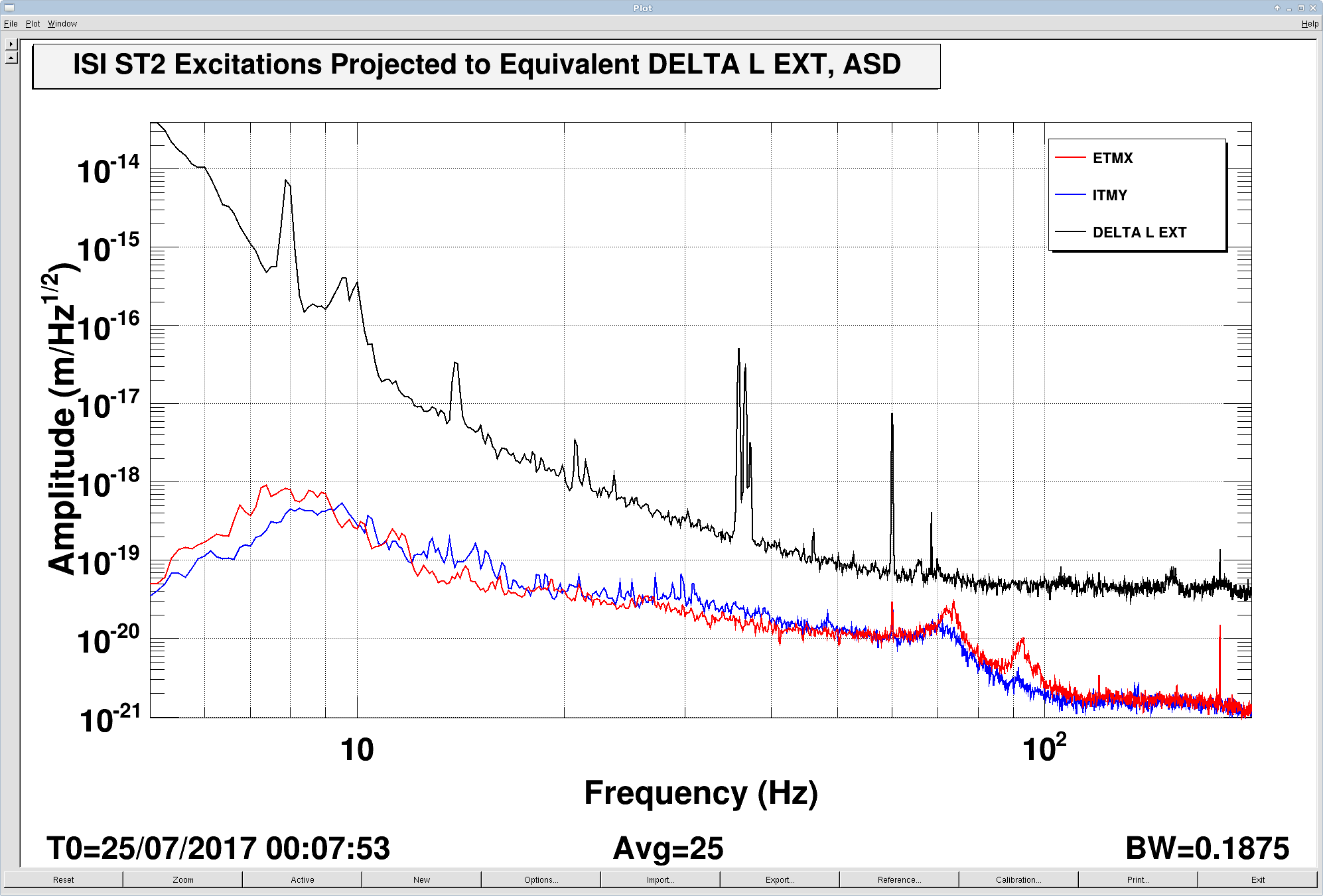
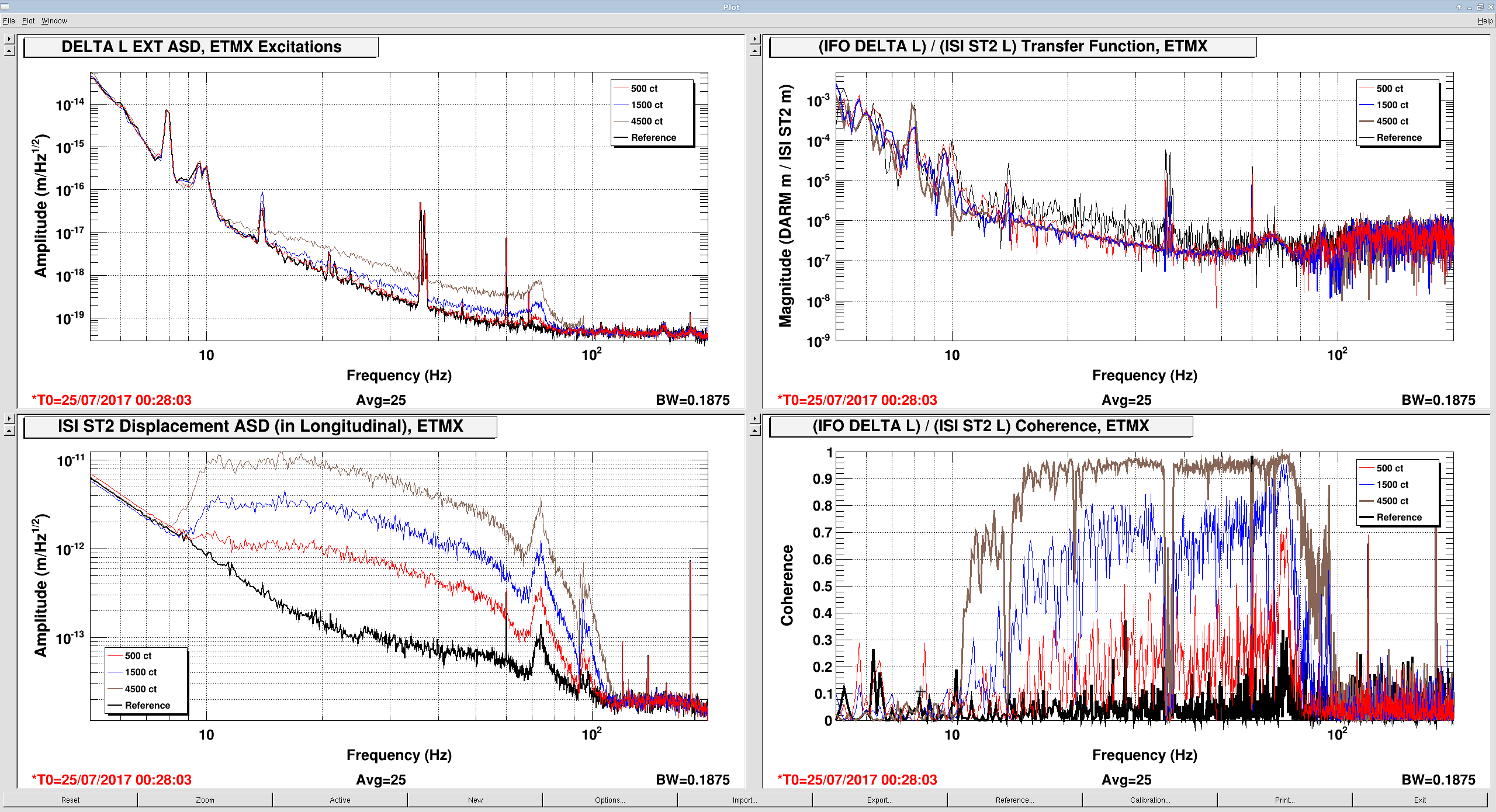
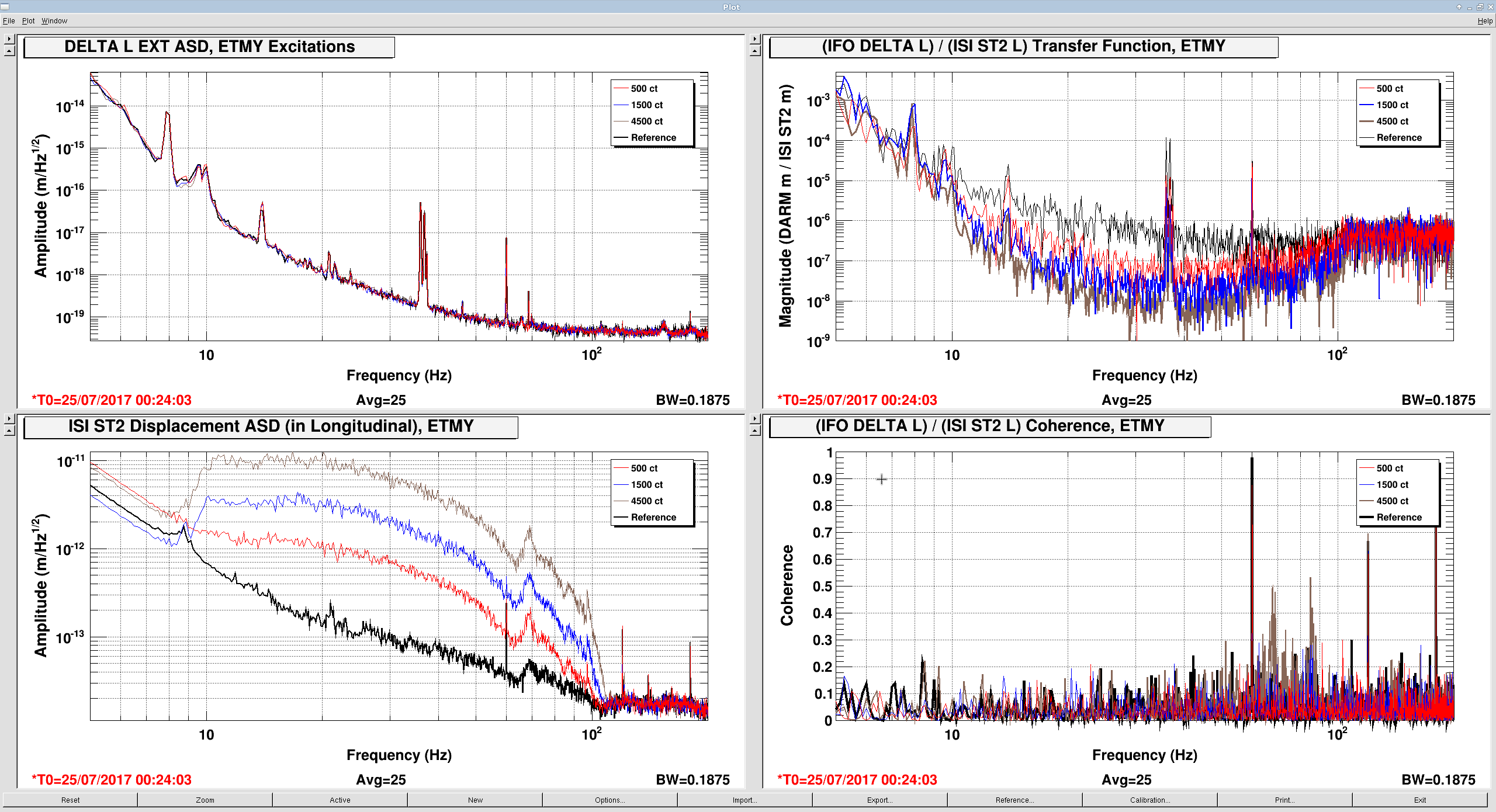
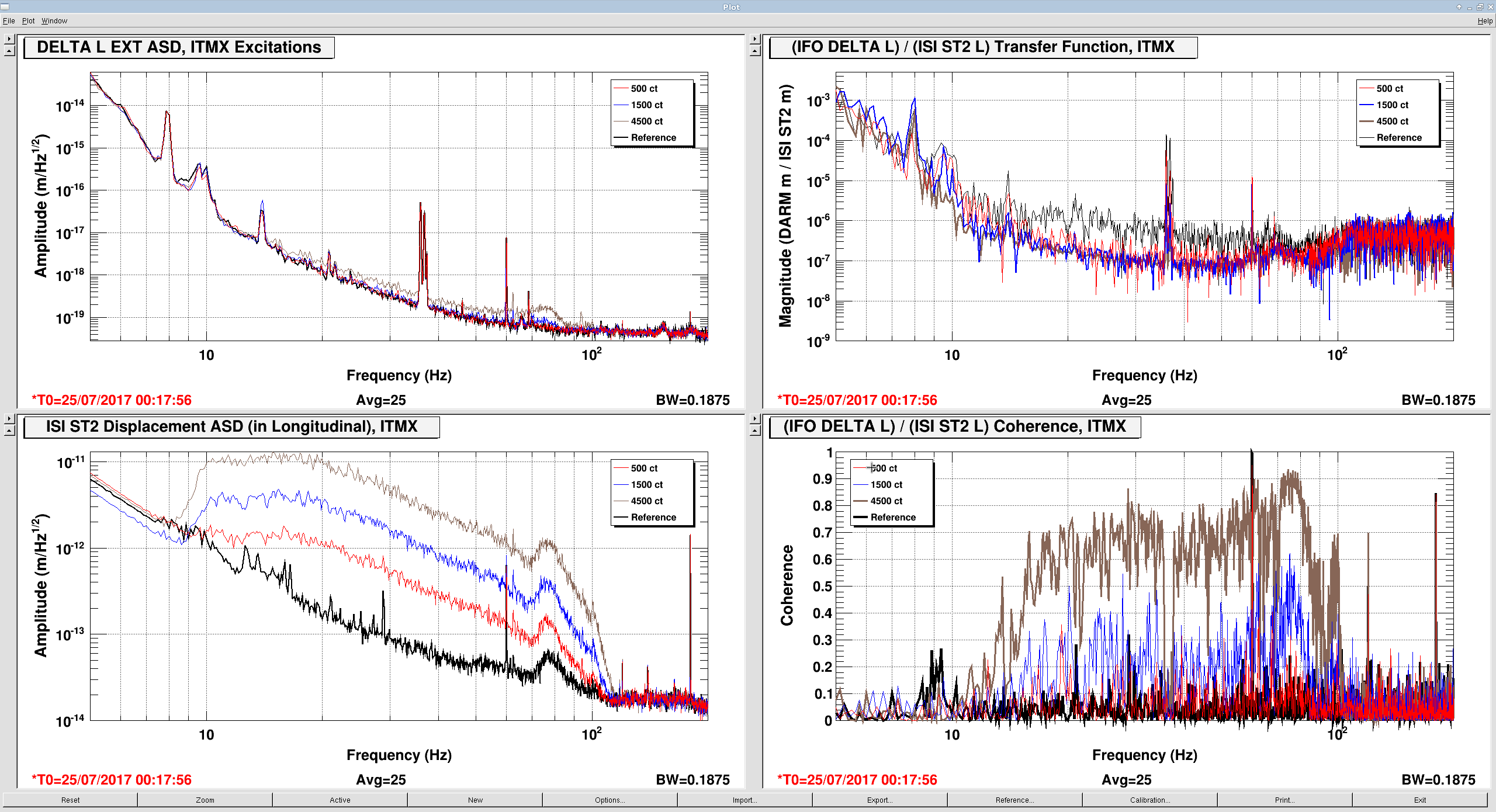
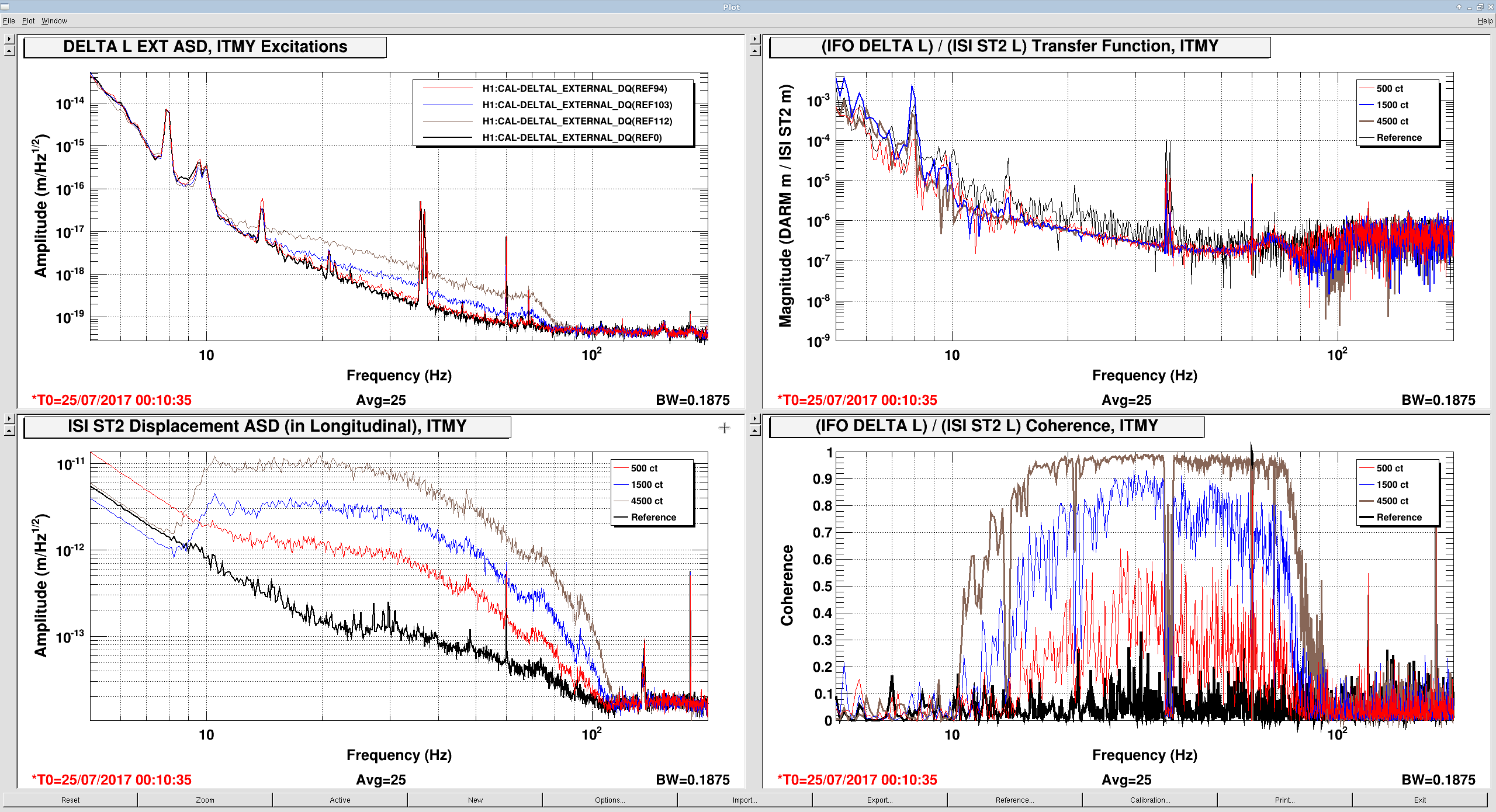
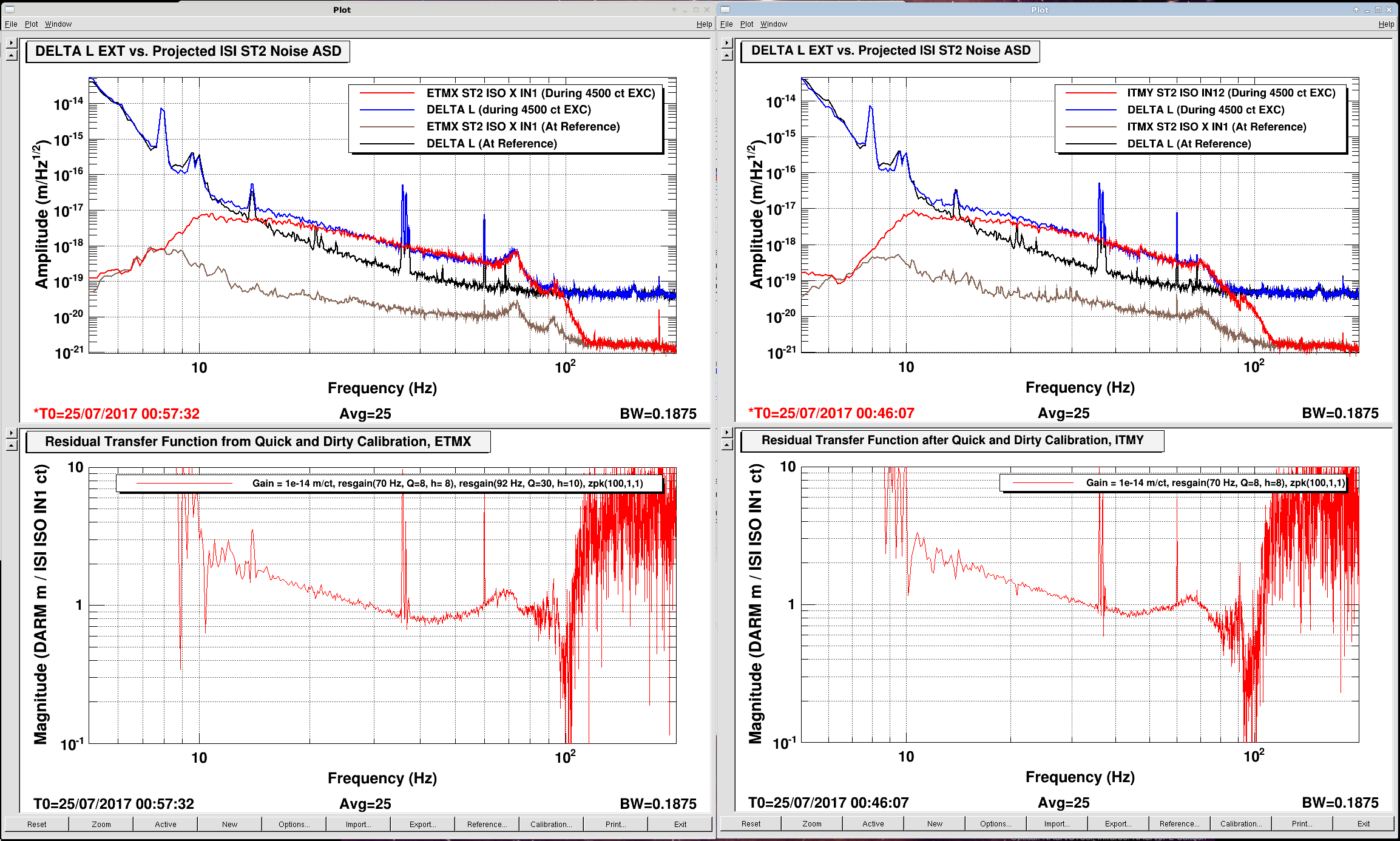
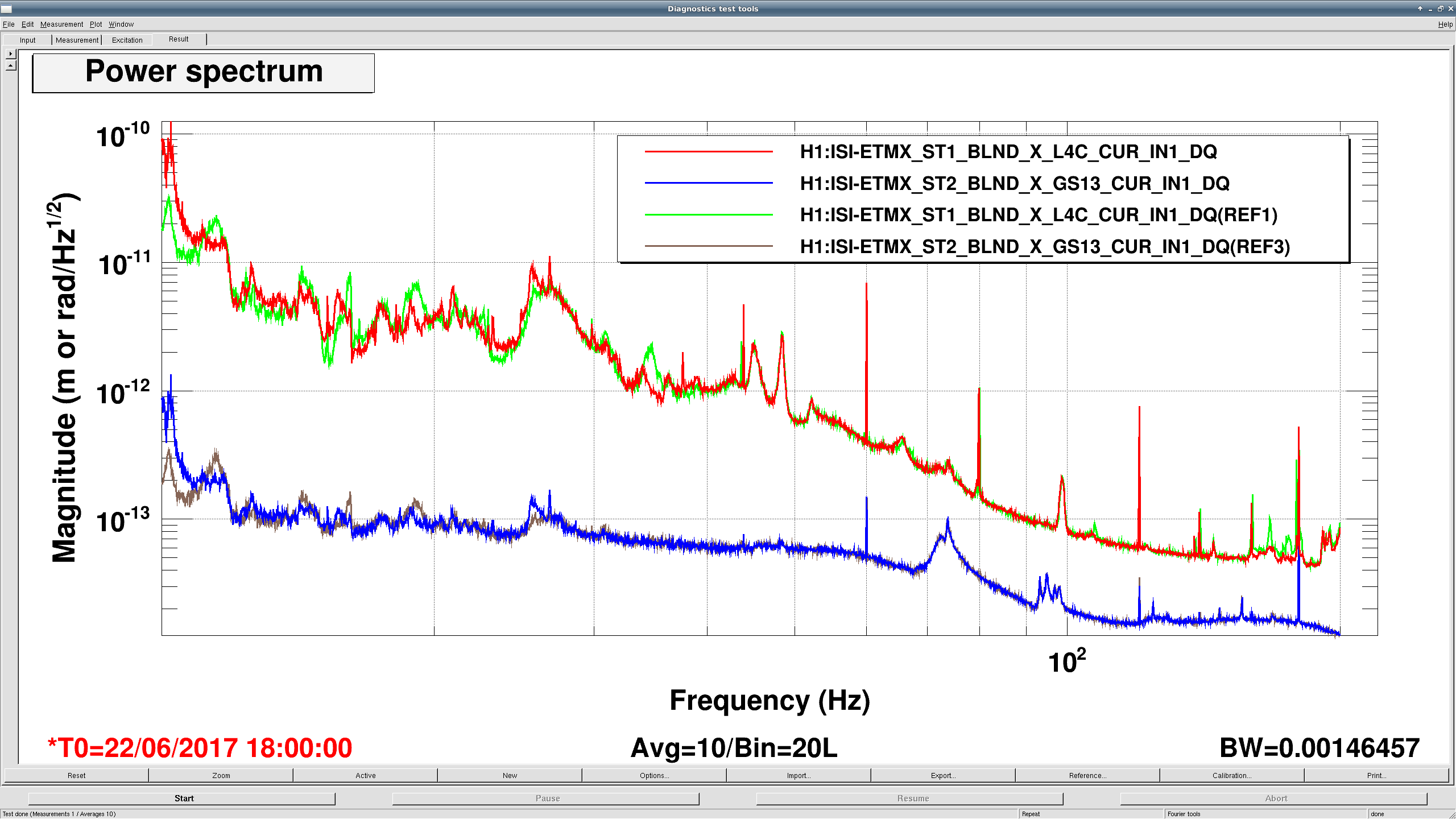
The measurements indicate that ETMX and ITMY are the worst offenders, in that their ambient noise falls as ~1/f^{1/2} between 10 and 100 Hz, with some resonant features at 70 and 92 Hz. The features are presumably the first few cage bending modes, for which we have Vibration Absorbers that have already knocked down the Q of the ~70 Hz modes, thankfully.
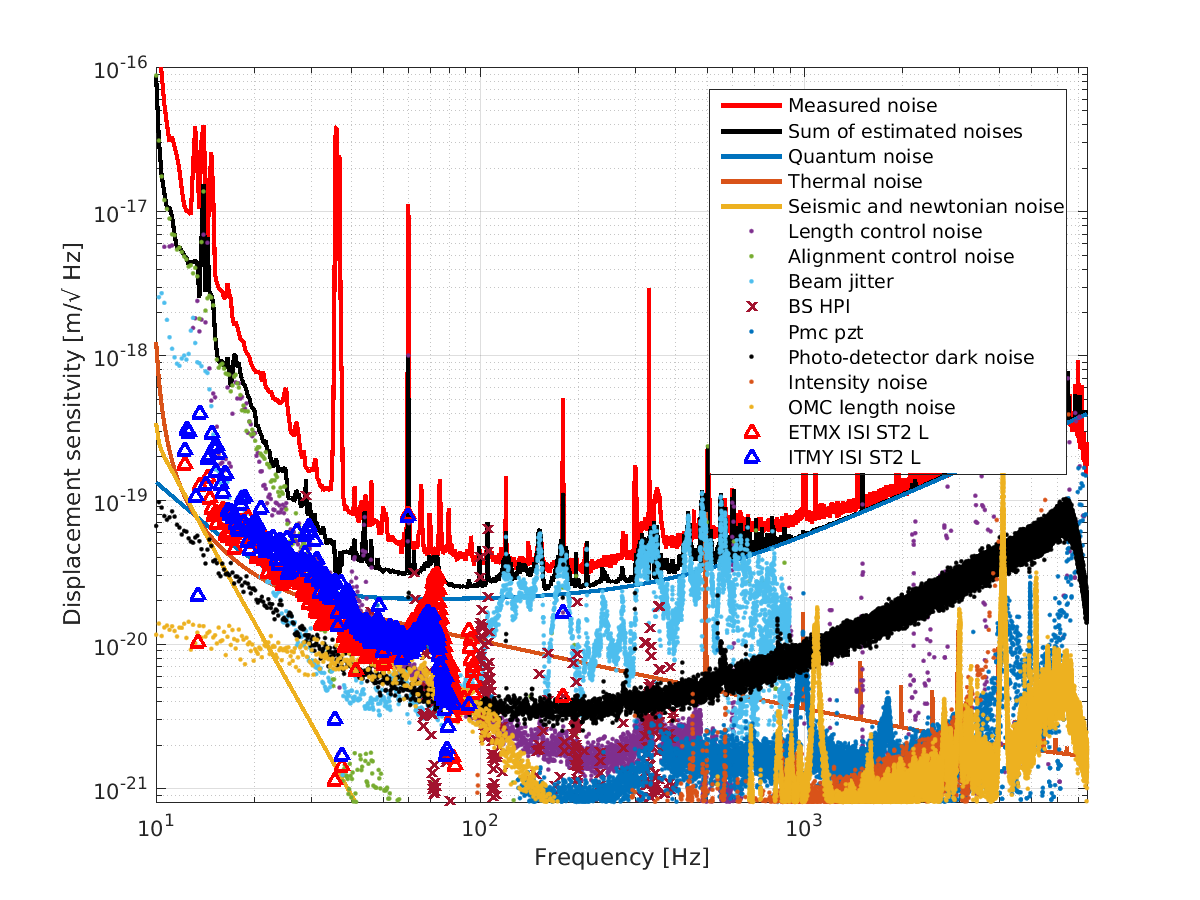
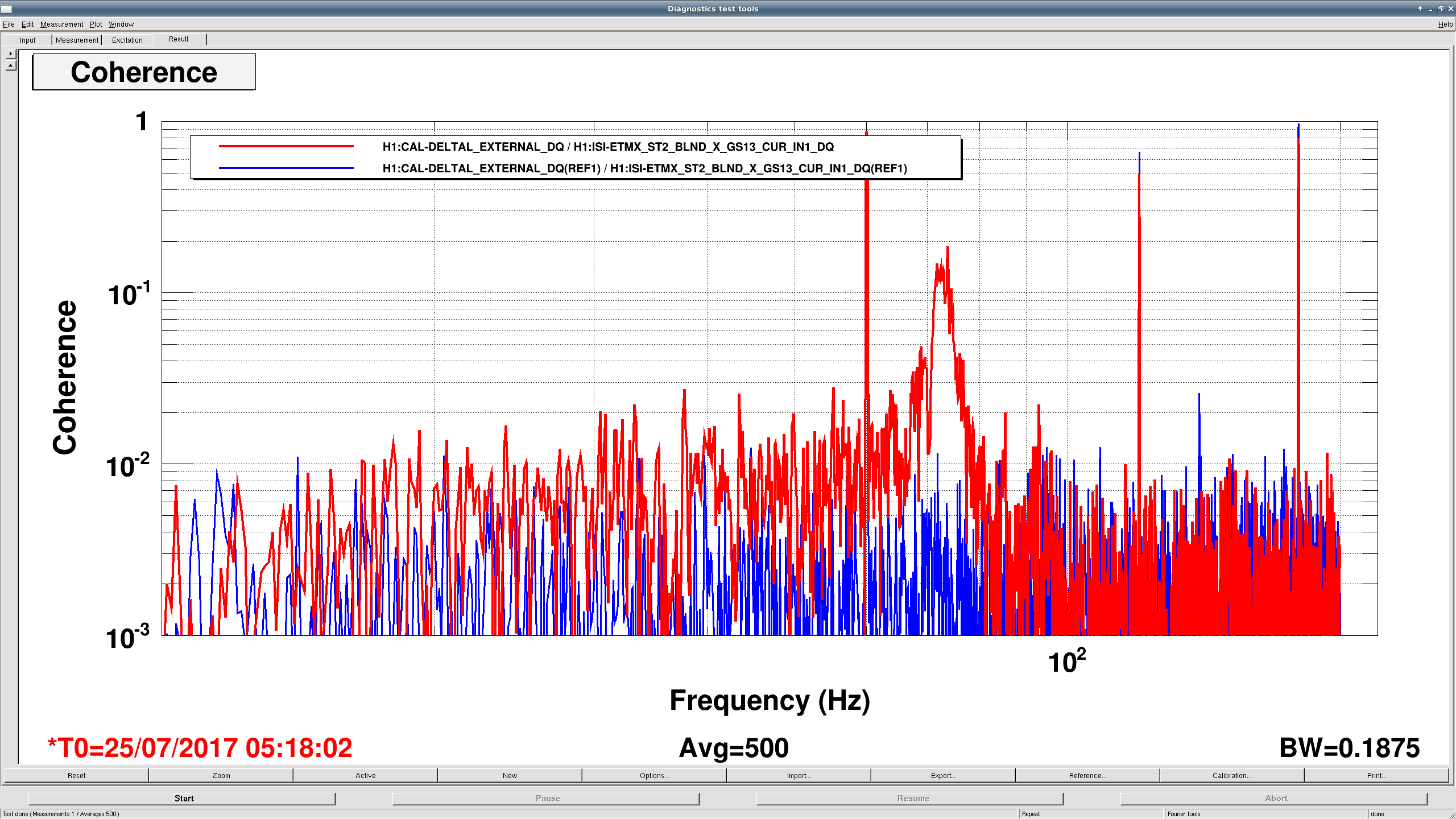
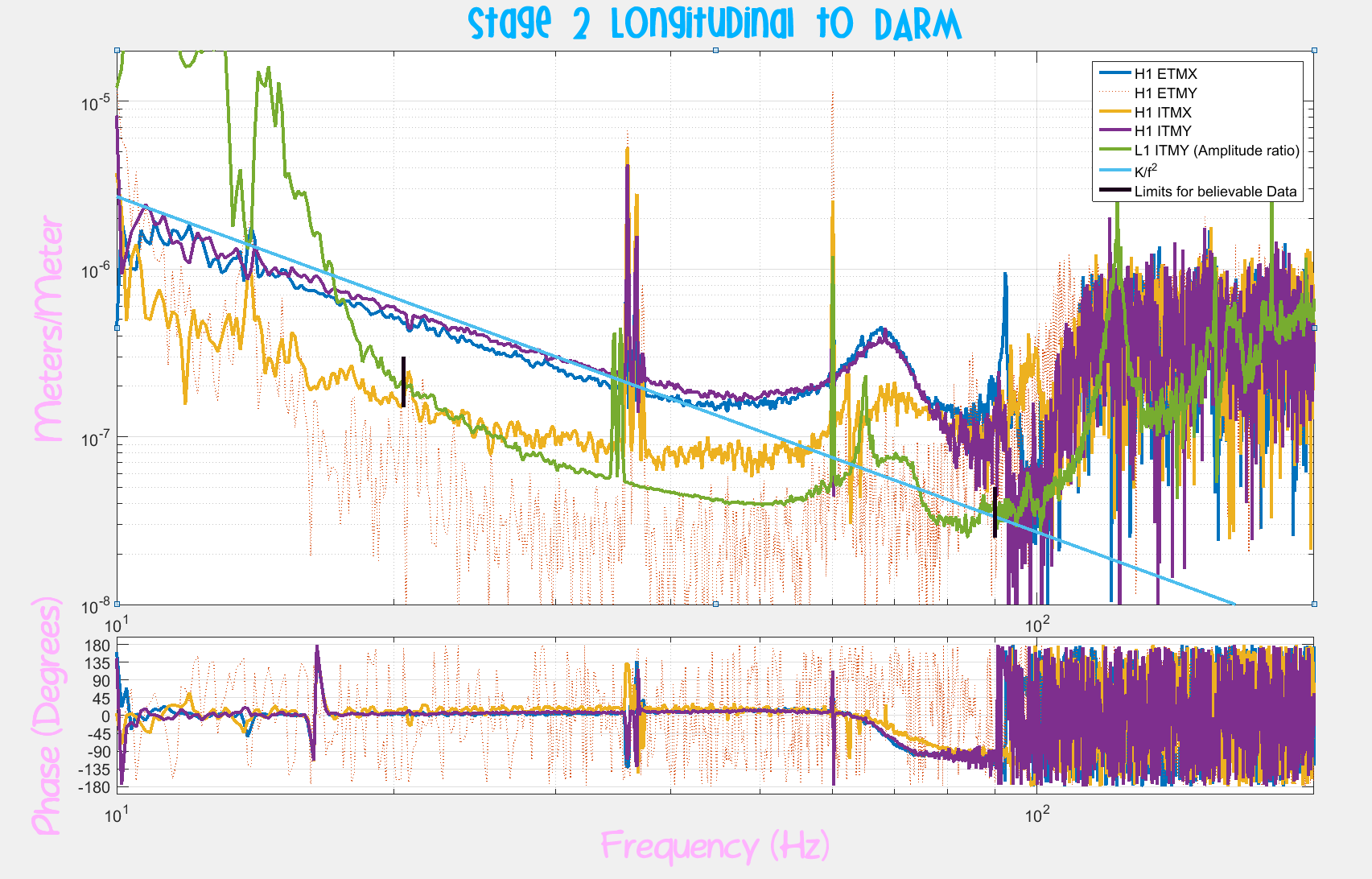
I've used the measurements to "calibrate" the error point of the ISI's ST2 Isolation Loops, and project the ambient noise to equivalent DARM displacement noise (a.k.a. primitive noise budgeting), see first attachment.
Each come within a factor of 3-5 at their worst parts during ambient conditions; too close for comfort.
Also, of course, there should be no such coupling at all if the cage were properly isolated from the suspension, and this appears to be a straight-forward linear coupling.
Note that the precision of the projection is not great -- I did not try hard to get it right. There are addendum plots that show the residual between model and measurement.
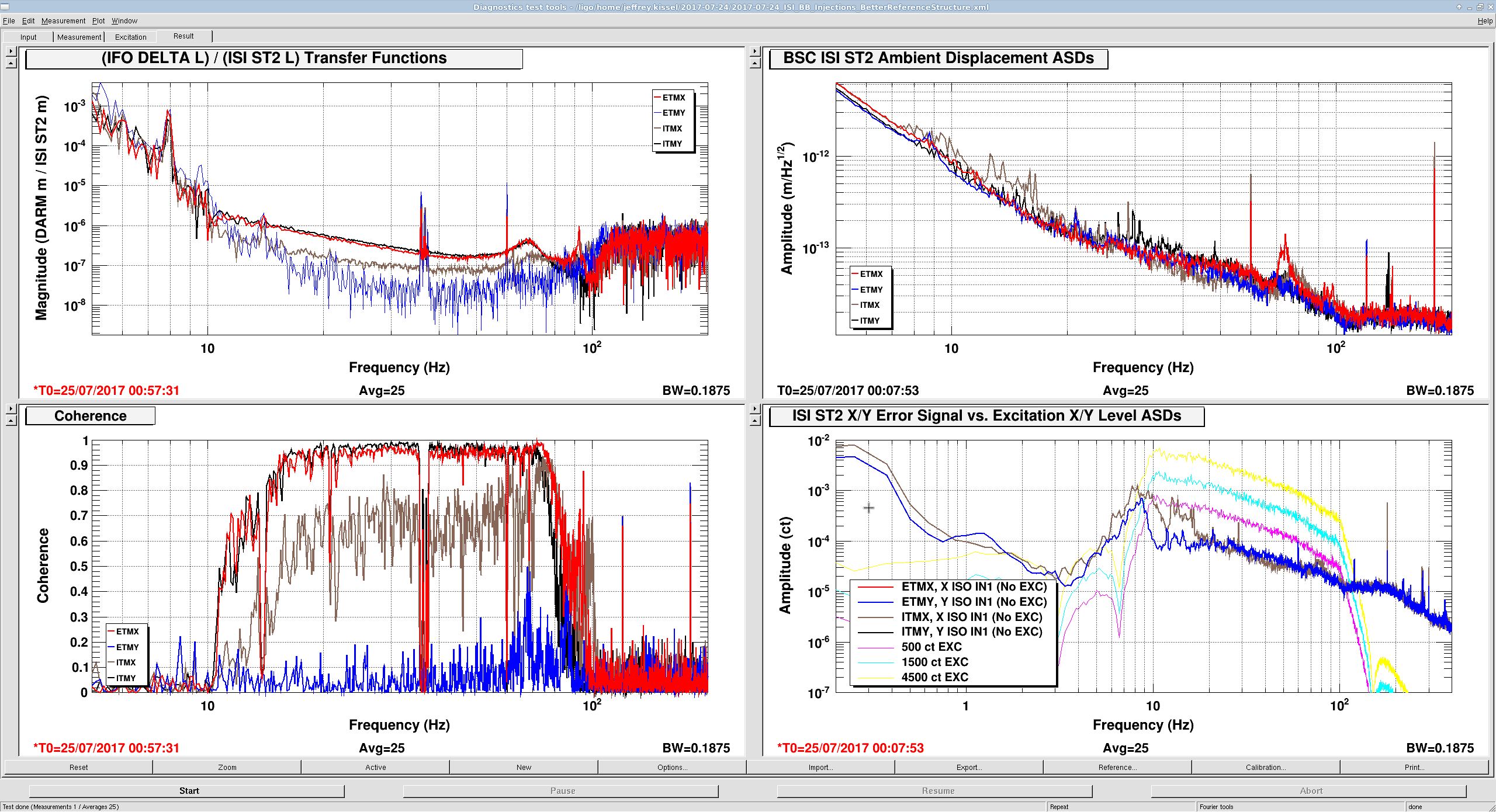
I don't think this is a / the limiting source now, since there is little coherence during ambient conditions, but this will certainly be a problem in the future if the coupling remains this bad for ETMX and ITMY. It definitely deserves a more careful calibration, further study with other degrees of freedom, and mapping out a broader frequency band. Perhaps we should check the coherence with these ST2 ISI channels after Jenne's subtraction of jitter (see LHO aLOG 37590) -- though the slope doesn't quite match up (from eye-ball memory).
ITMX's coupling is about 1/2 as bad, and ETMY does not show any visible signs of bad coupling at this excitation level (which is damning evidence that it's related to charge, since ETMY has the largest effective bias voltage at the moment).
%%%%%%% Details %%%%%%%%
Measurement Technique (all while in nominal low noise):
- choose obvious, simply to imagine coupling degrees of freedom: the longitudinal axis for the optics in the arm cavity (X for ETMX and ITMX, Y for ETMY and ITMY)
- measure ambient error signals in those directions using DTT.
- In the same DTT template, create a band-passed excitation where you suspect you're having problems (10-100 Hz), shape it to look roughly like that ambient spectra you see. I used
ellip("BandPass",4,1,40,10,100)zpk([0.1],[1; 10],1,"n")gain(0.159461)gain(1e-4)
copied and pasted to the 4 excitation banks (thanks Daniel!) so that I can pick and chose what I'm driving, and with what amplitude.
- Grab a bunch of relevant response signals; the excitations, the error signals, the calibrated displacement (the pre-calibrated SUSPOINT signals are especially nice -- though the suffer from spectral leakage up to above 10 Hz).
- Slowly creep up the drive (I started with 0.001 [ct] to be extra careful) until you start to see hints of something / coherence.
- In case the coupling is non-linear, record the results at three different drive levels (I chose factors of three, 500 ct, 1500 ct, and 4500 ct, filtered by the above band-pass.)
Analysis Techniques
- Remember, to calibrate DELTA L EXTERNAL, one must apply the transfer function from
/ligo/svncommon/CalSVN/aligocalibration/trunk/Runs/O2/H1/Scripts/ControlRoomCalib/caldeltal_calib.txt
i.e. copy and paste that file into the "Trans. Func." tab of the calibration for the channel, after creating a new entry called (whatever) with units "m".
- For calibrated transfer functions of ISI displacement in local meters to DELTA L in global differential arm meters, just plot transfer functions between SUSPOINT motion (which comes pre-calibrated) and DELTA L EXT.
- Store the transfer function between the ISI ST2 ISO error point and DELTA L EXT for the loudest injection
- For "good enough" calibration of the error point, make a foton filter (in some junk file) that looks like the transfer function of error point to DELTA L EXT, and install into DTT calibration for that channel. Guess the gain that makes the driven error-point spectra line up well with the DELTA L spectra. For ETMX this was
foton design: resgain(70 Hz, Q=8, h=8) * resgain(92 Hz, Q=30, h=10) * zpk(100,1,1)
equiv zeros and poles: z=[10.6082+/-i*69.1915, 3.42911+/-i*91.9361, 100], p = [4.2232+/-i*69.8725, 1.08438+/-i*91.9936, 1], g = 1
dtt calibration:
Gain: 1e-14 [m/ct]
Poles: 4.2232 69.8725, 1.08438 91.9936, 1
Zeros: 10.6082 69.1915, 3.42911 91.9361, 100
For ITMY this was the same thing, but without the 92 Hz resonant feature:
foton design: resgain(70 Hz, Q=8, h=8) * zpk(100,1,1)
equiv zeros and poles: z=[10.6082+/-i*69.1915, 100], p = [4.2232+/-i*69.8725, 1], g = 1
dtt calibration:
Gain: 1e-14 [m/ct]
Poles: 4.2232 69.8725, 1
Zeros: 10.6082 69.1915, 100
This calibrates the channel, regardless of if there's excitation or not (assuming all linearity and good coherent original transfer function) --- in the region where your transfer function is valid, then this will calibrate the ambient noise.
Since I didn't take enough data to really fill out the transfer function, I only bother to do this in the 10-100 Hz, and did it rather quickly -- only looking for factors of ~2 precision for this initial assessment.
So as to not confuse the main point of the aLOG, I'll attach supporting plots as a comment to this log.