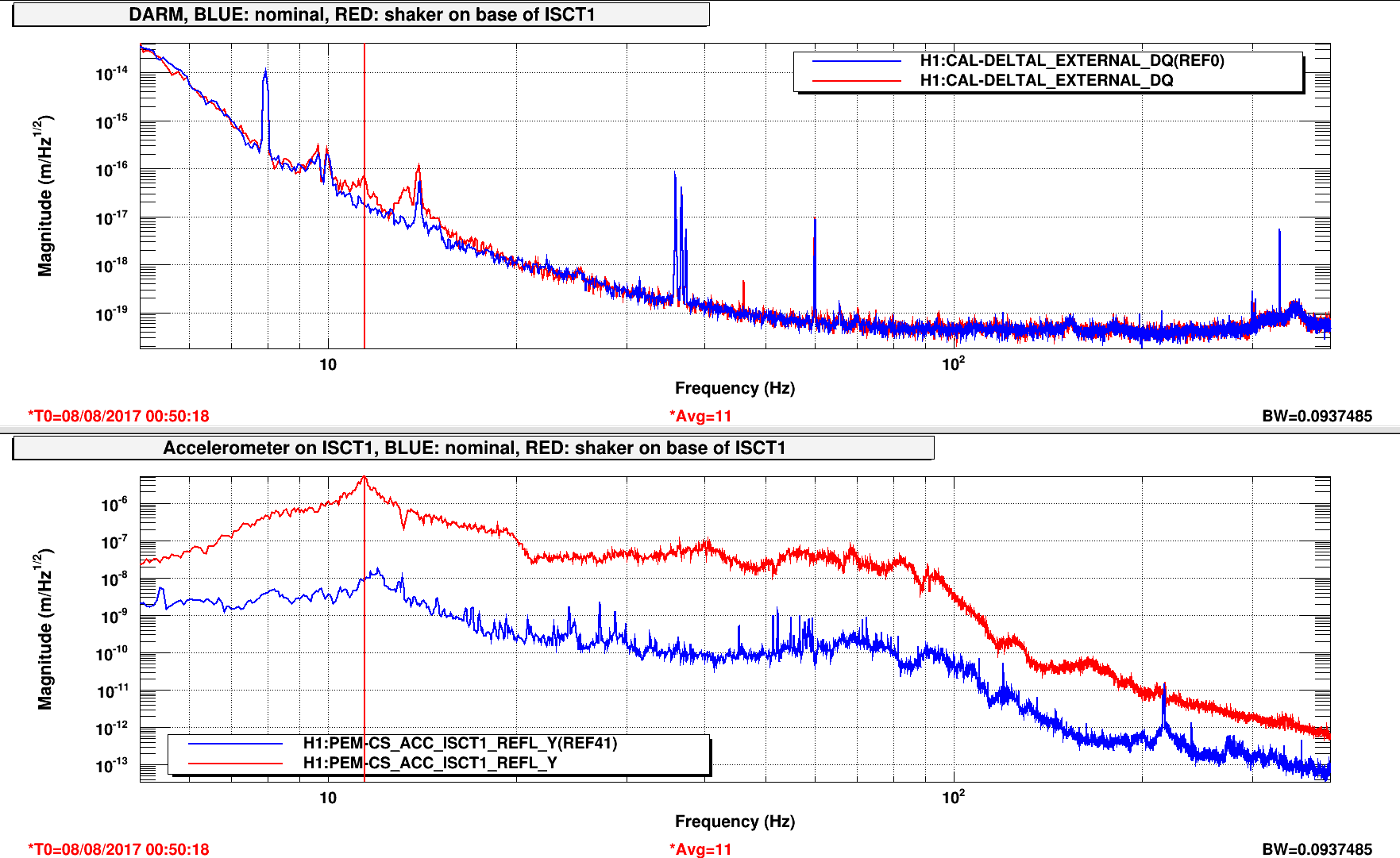
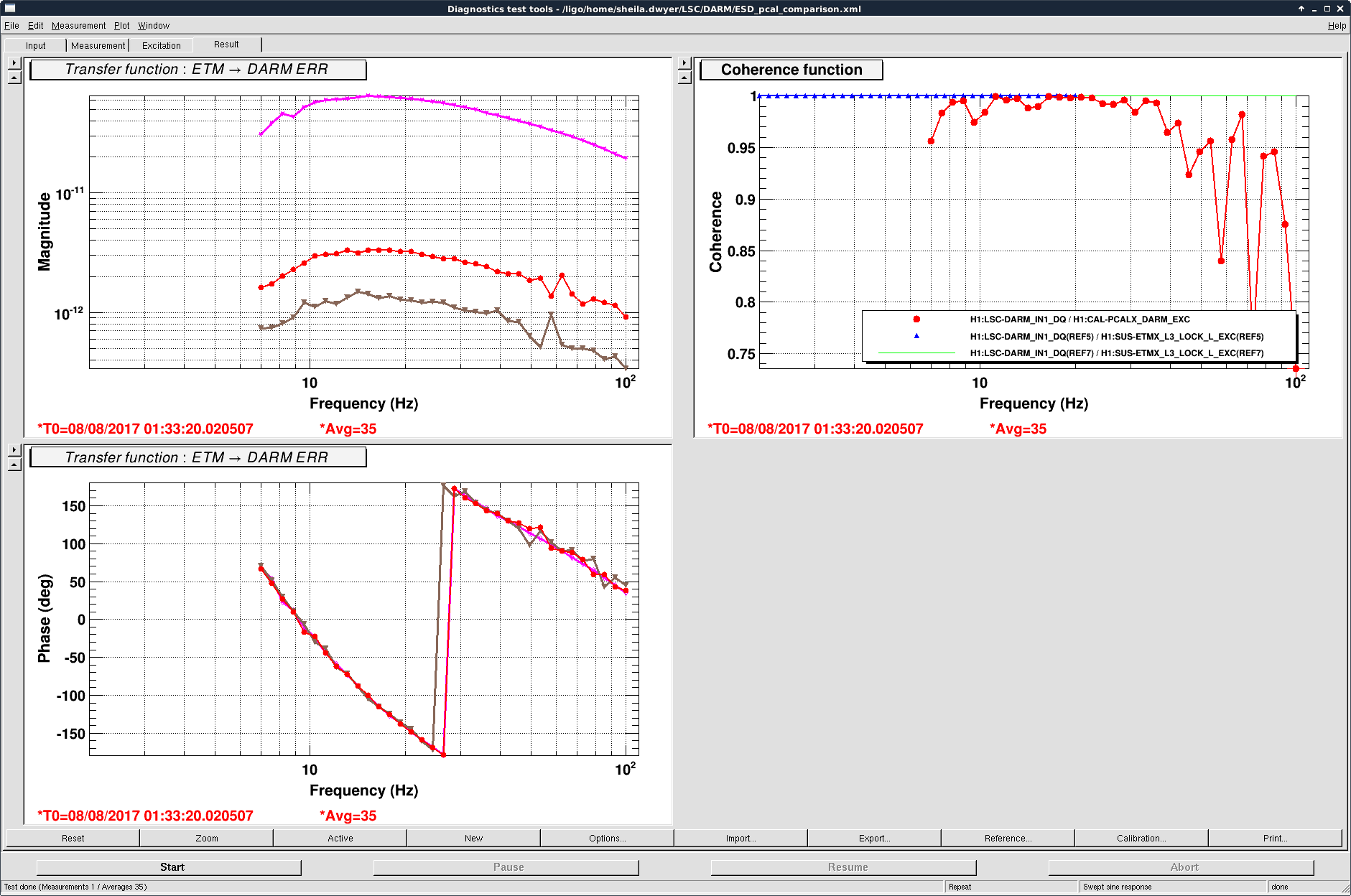
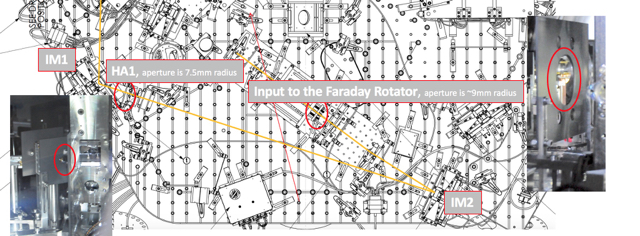
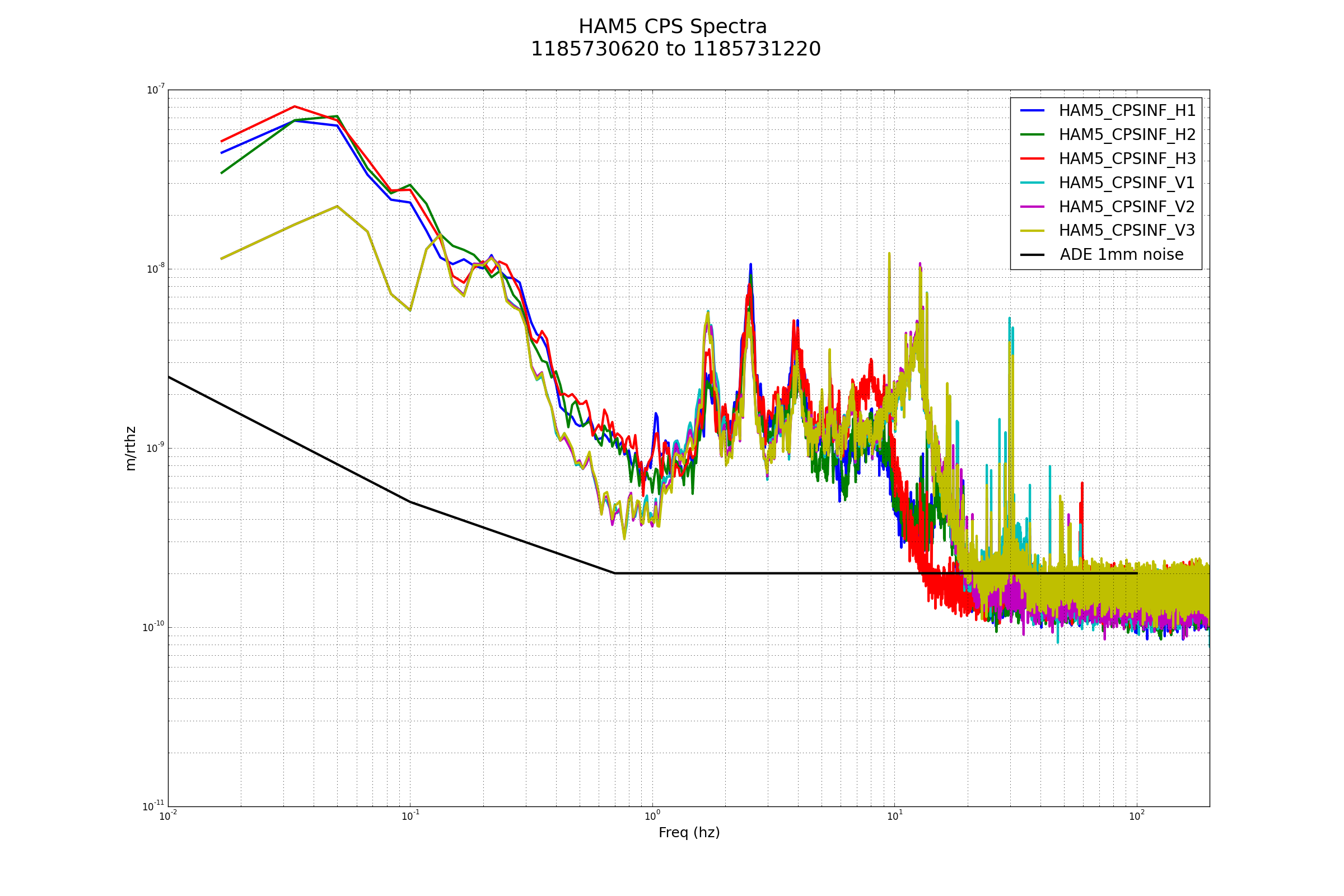
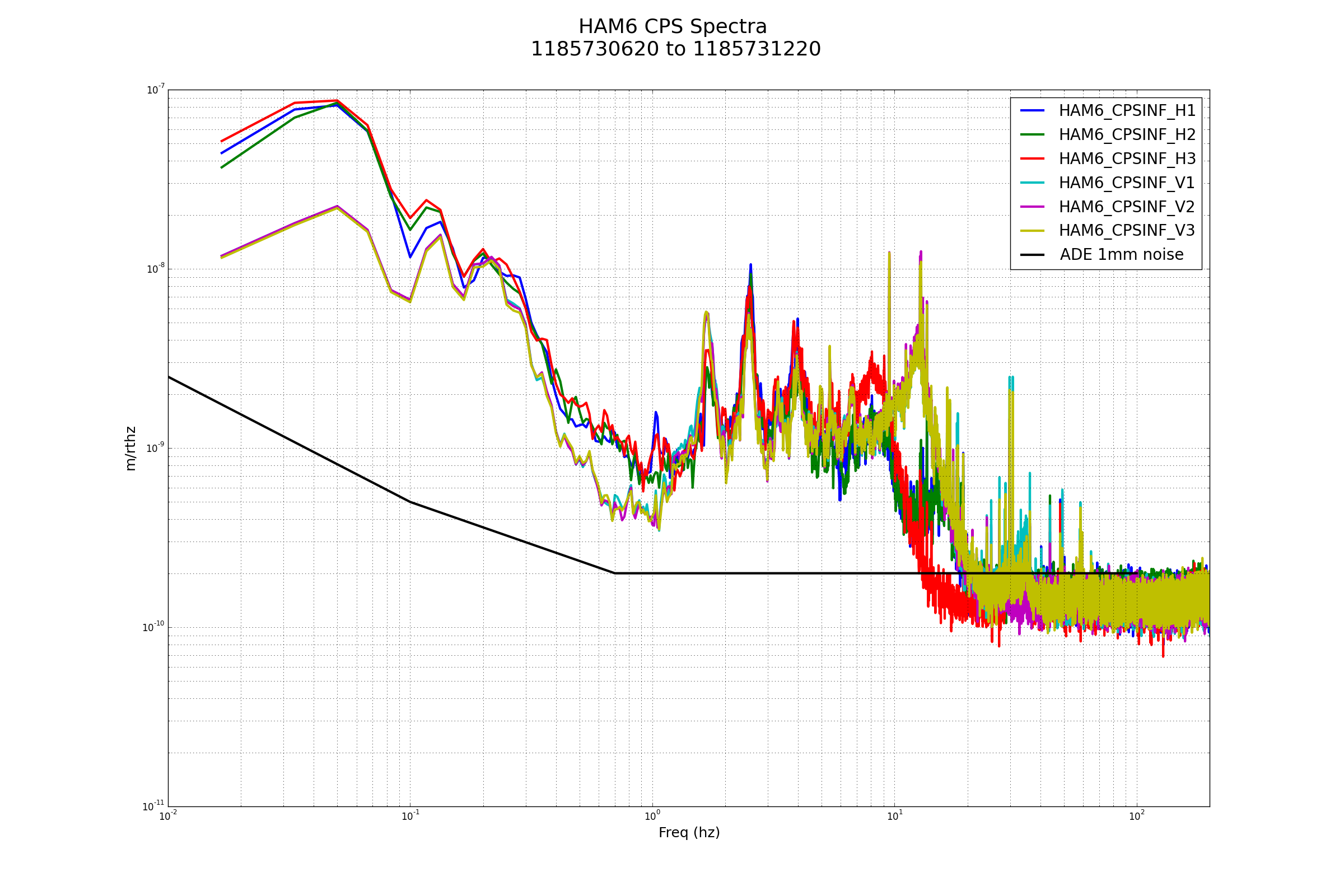
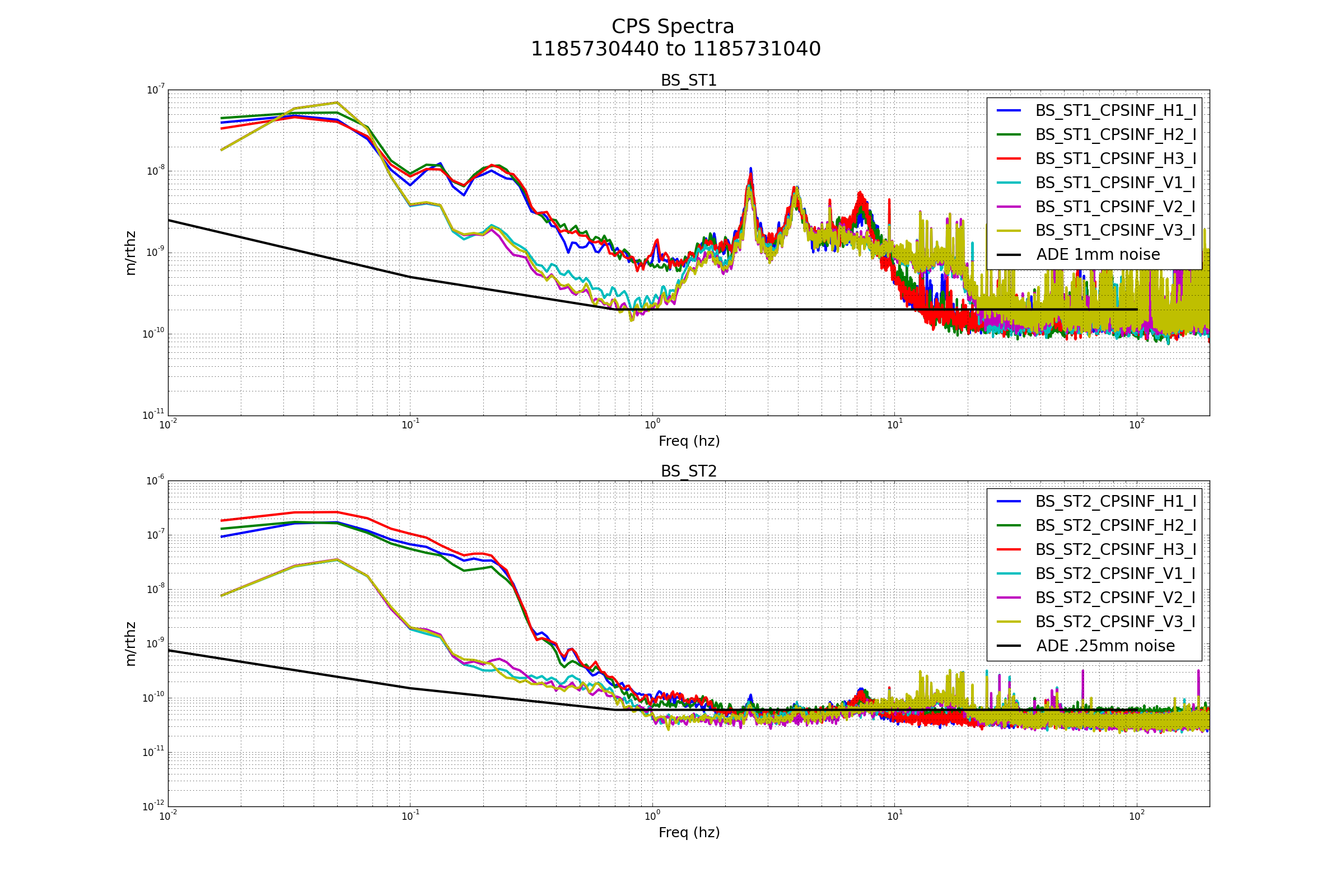
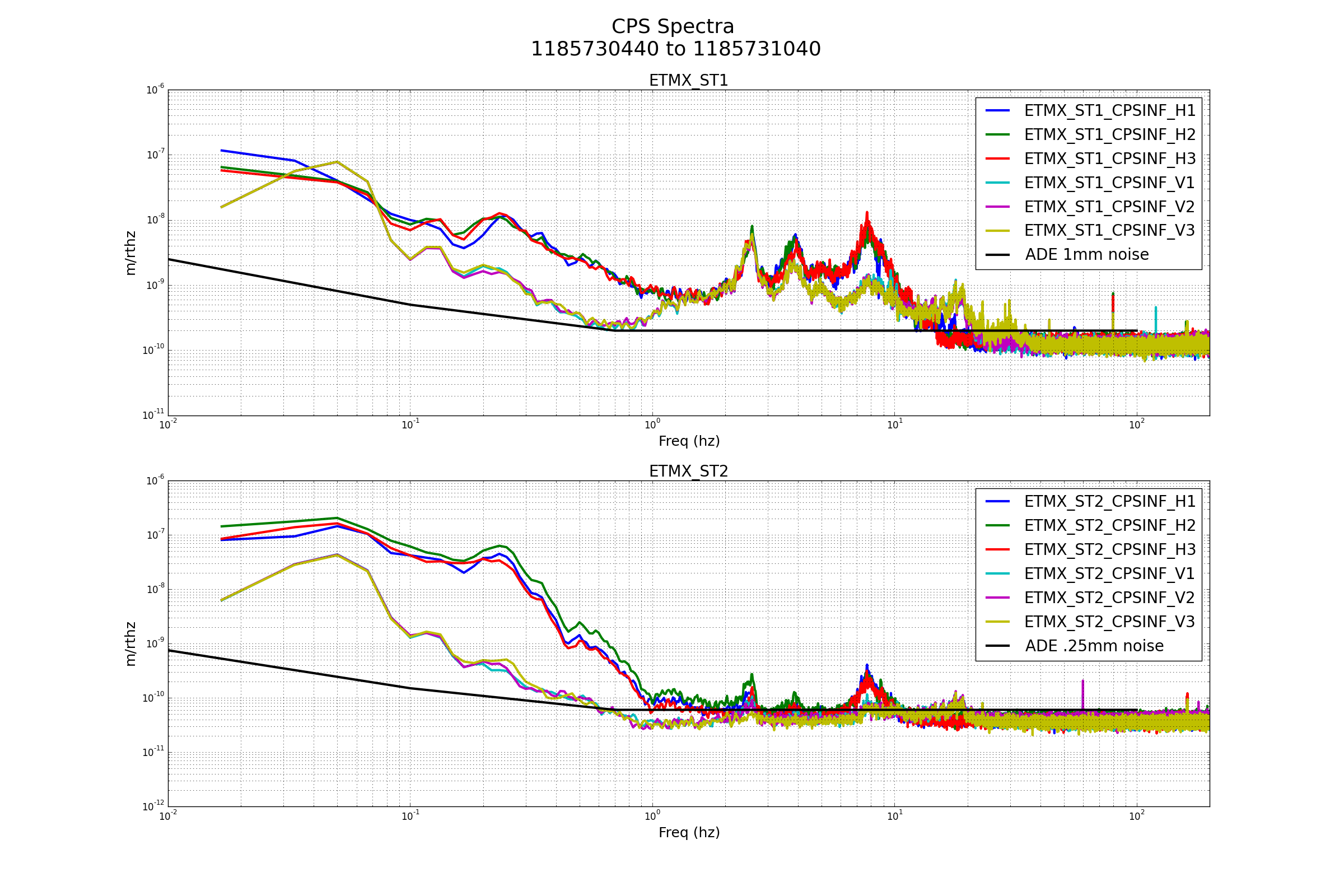
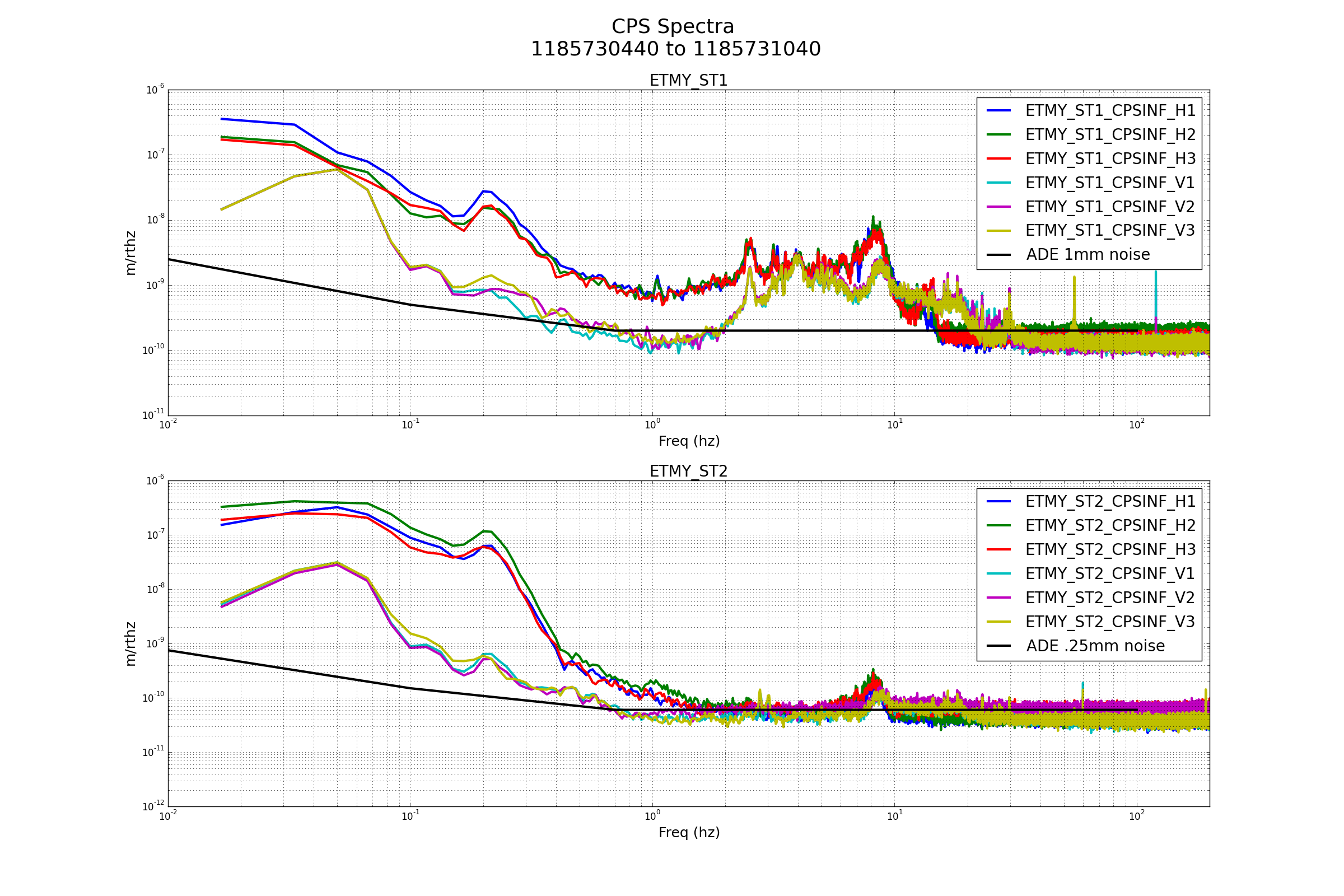
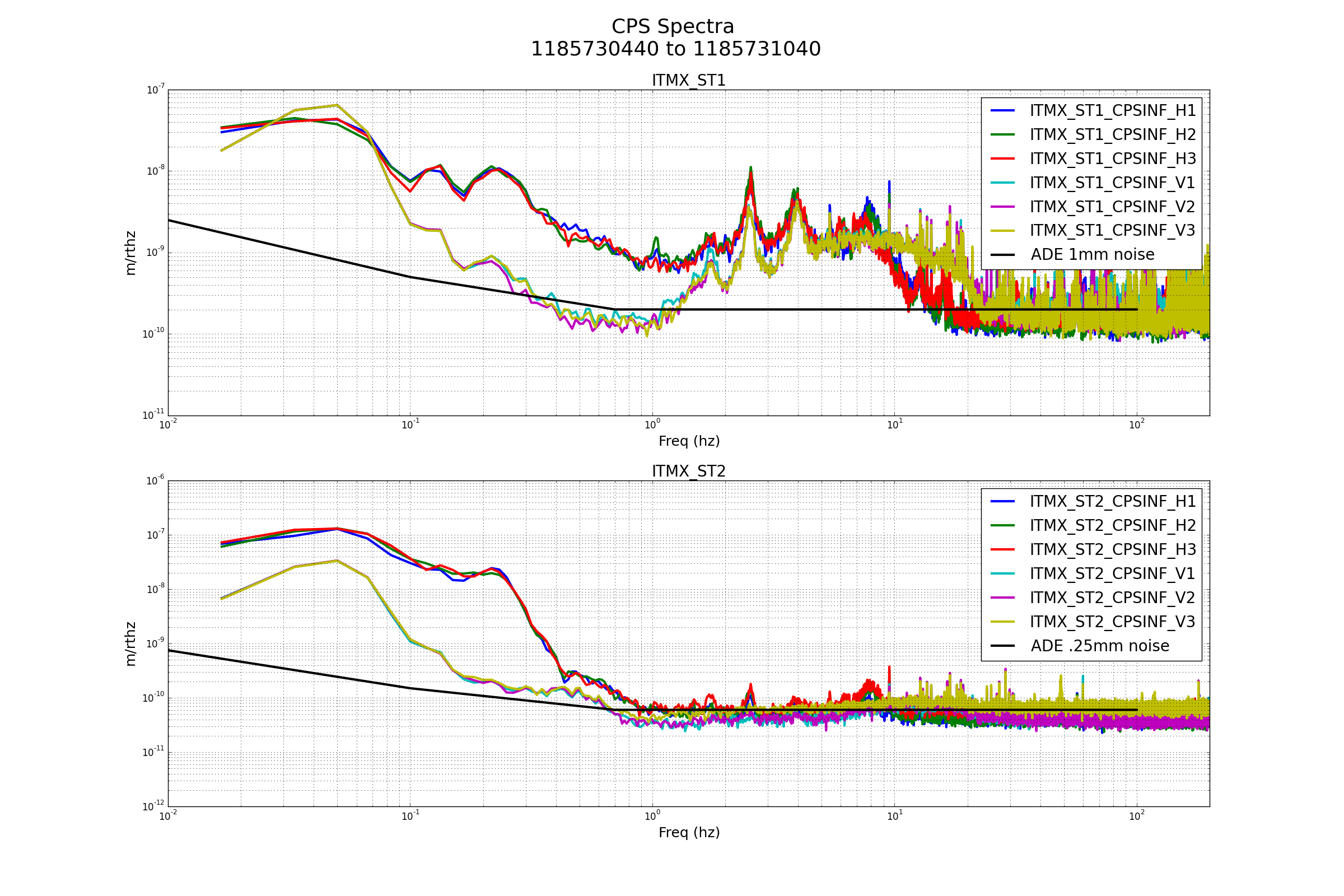
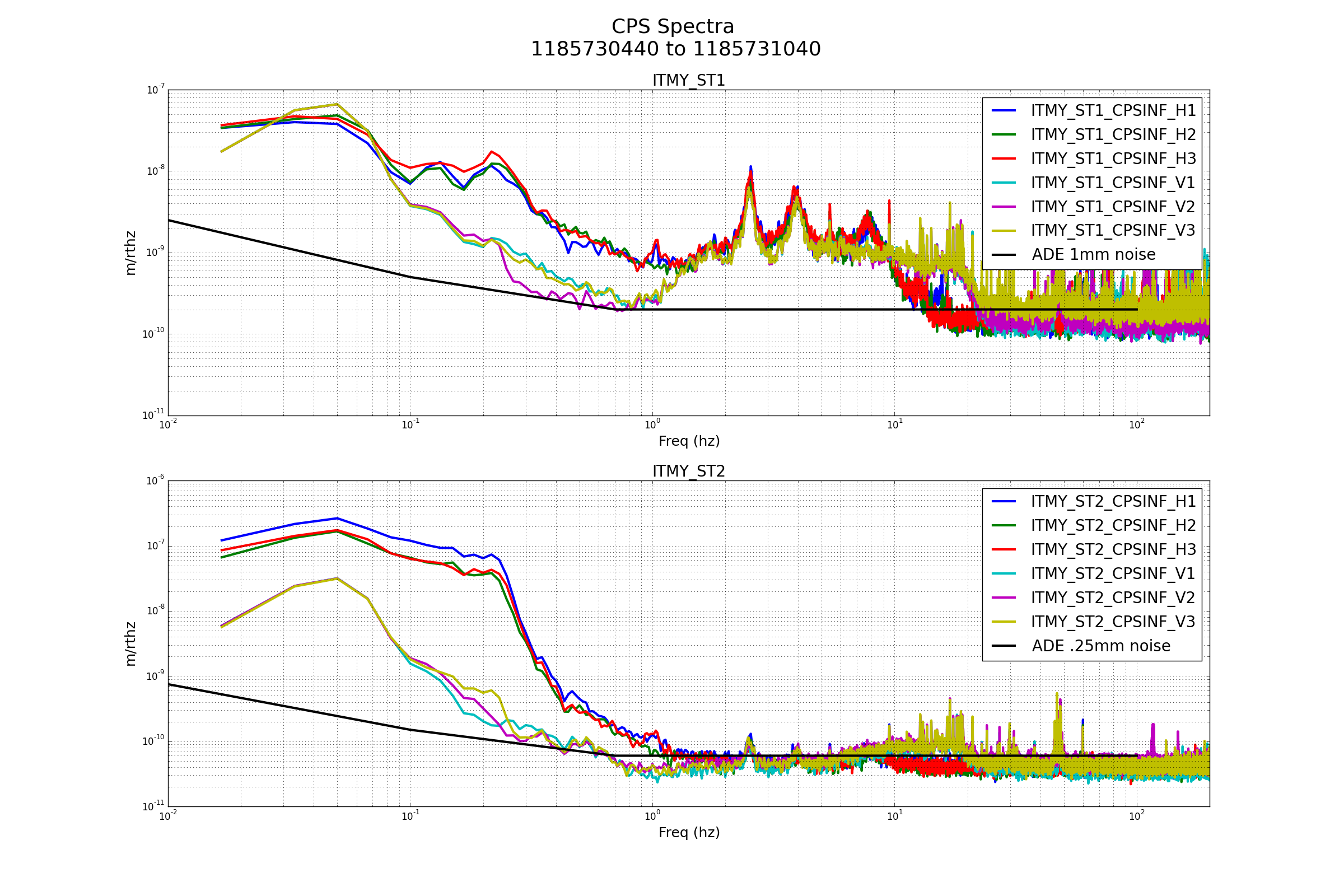
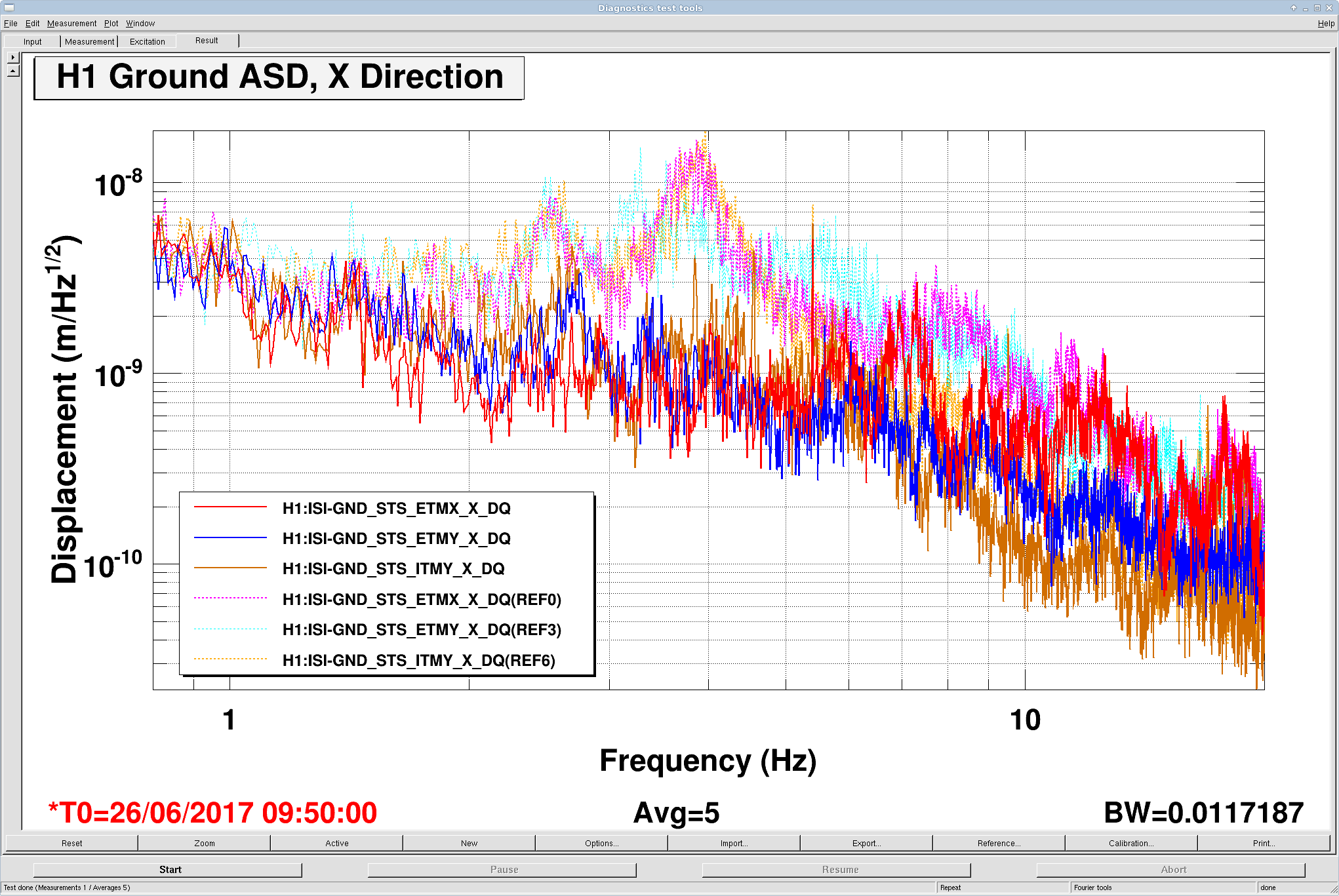
patrick.thomas@LIGO.ORG - posted 00:31, Tuesday 08 August 2017 (38060)
Ops Owl Shift Transition
TITLE: 08/08 Owl Shift: 07:00-15:00 UTC (00:00-08:00 PST), all times posted in UTC
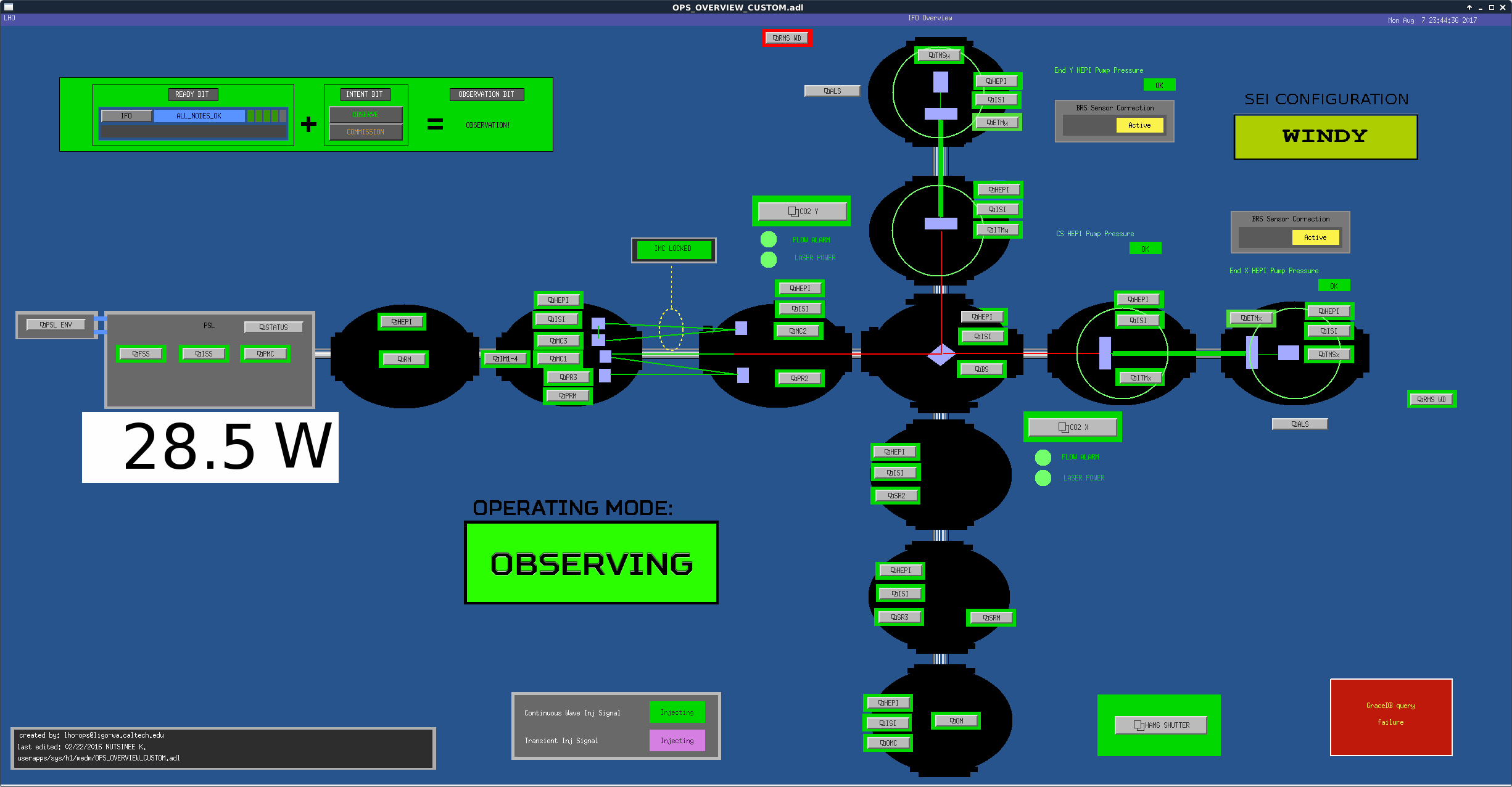
STATE of H1: Observing at 53Mpc
OUTGOING OPERATOR: Ed
CURRENT ENVIRONMENT:
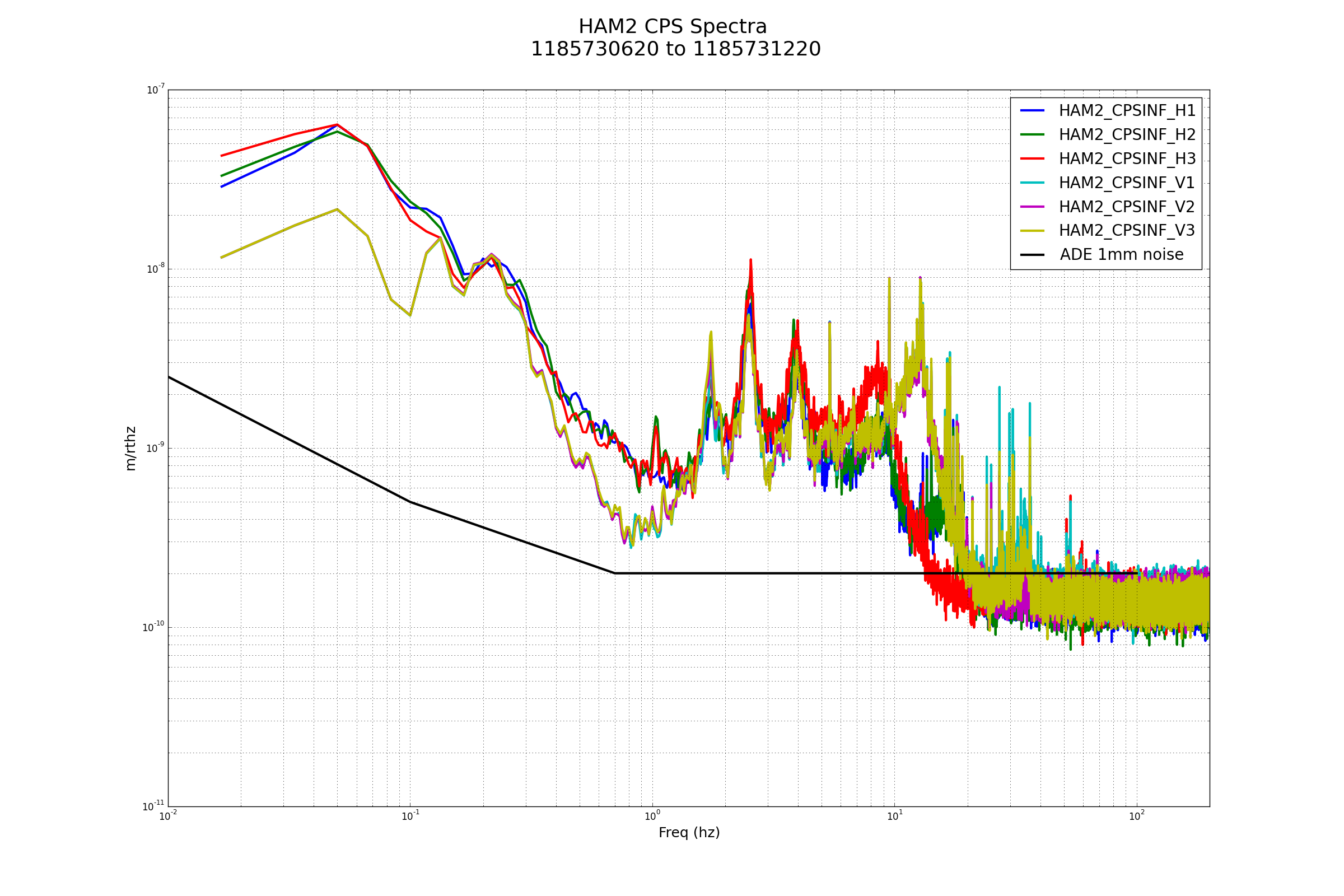
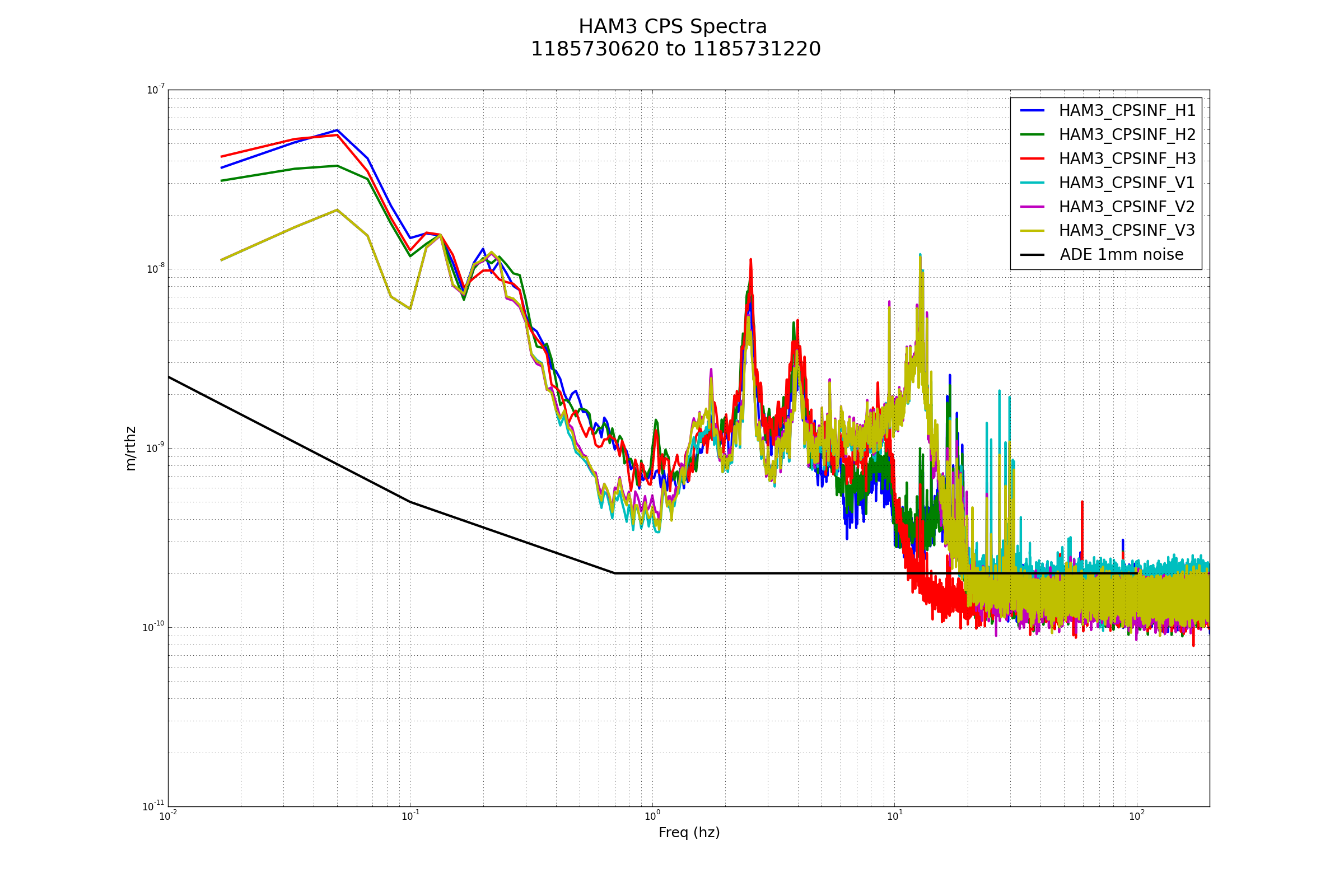
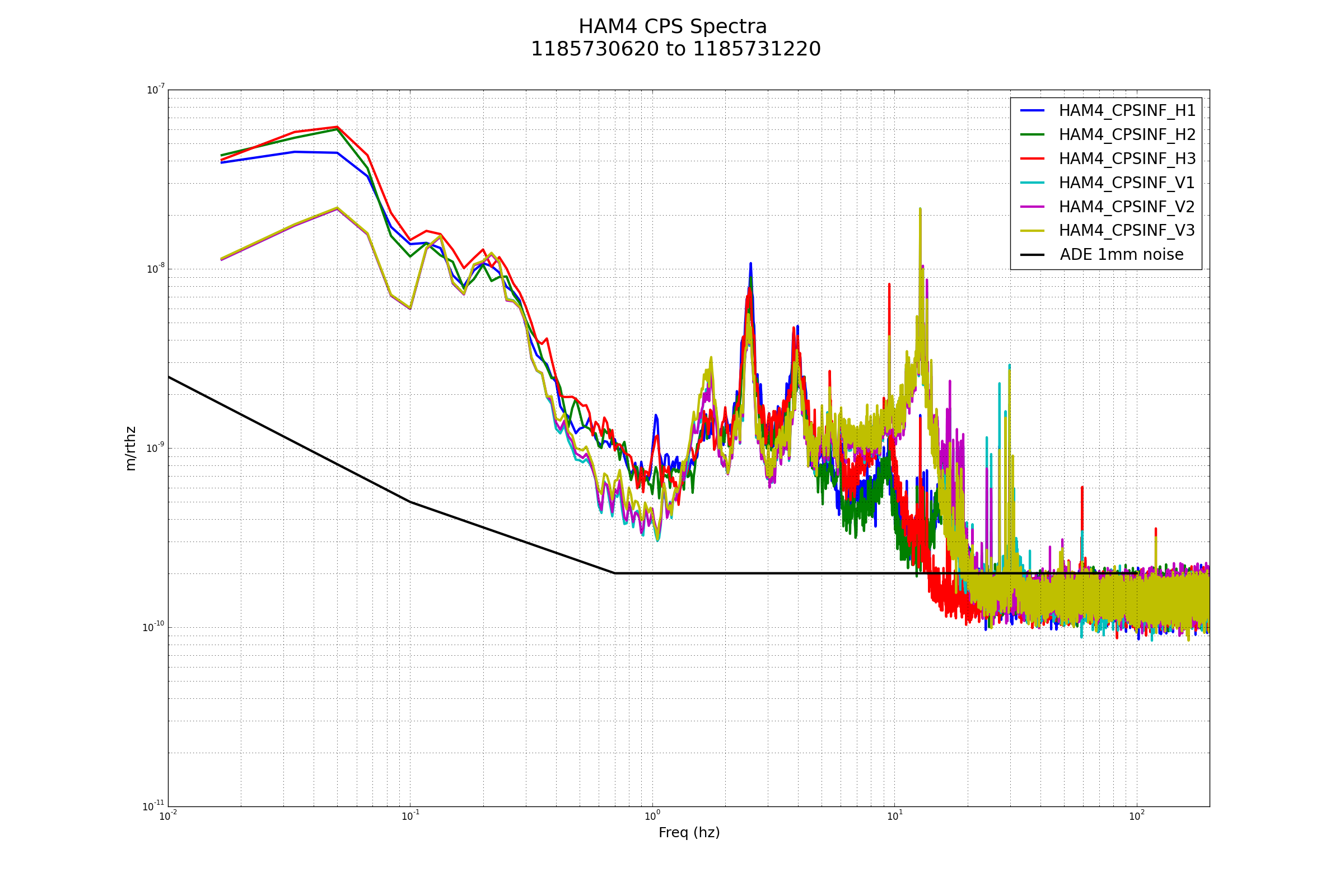
Wind: 5mph Gusts, 4mph 5min avg
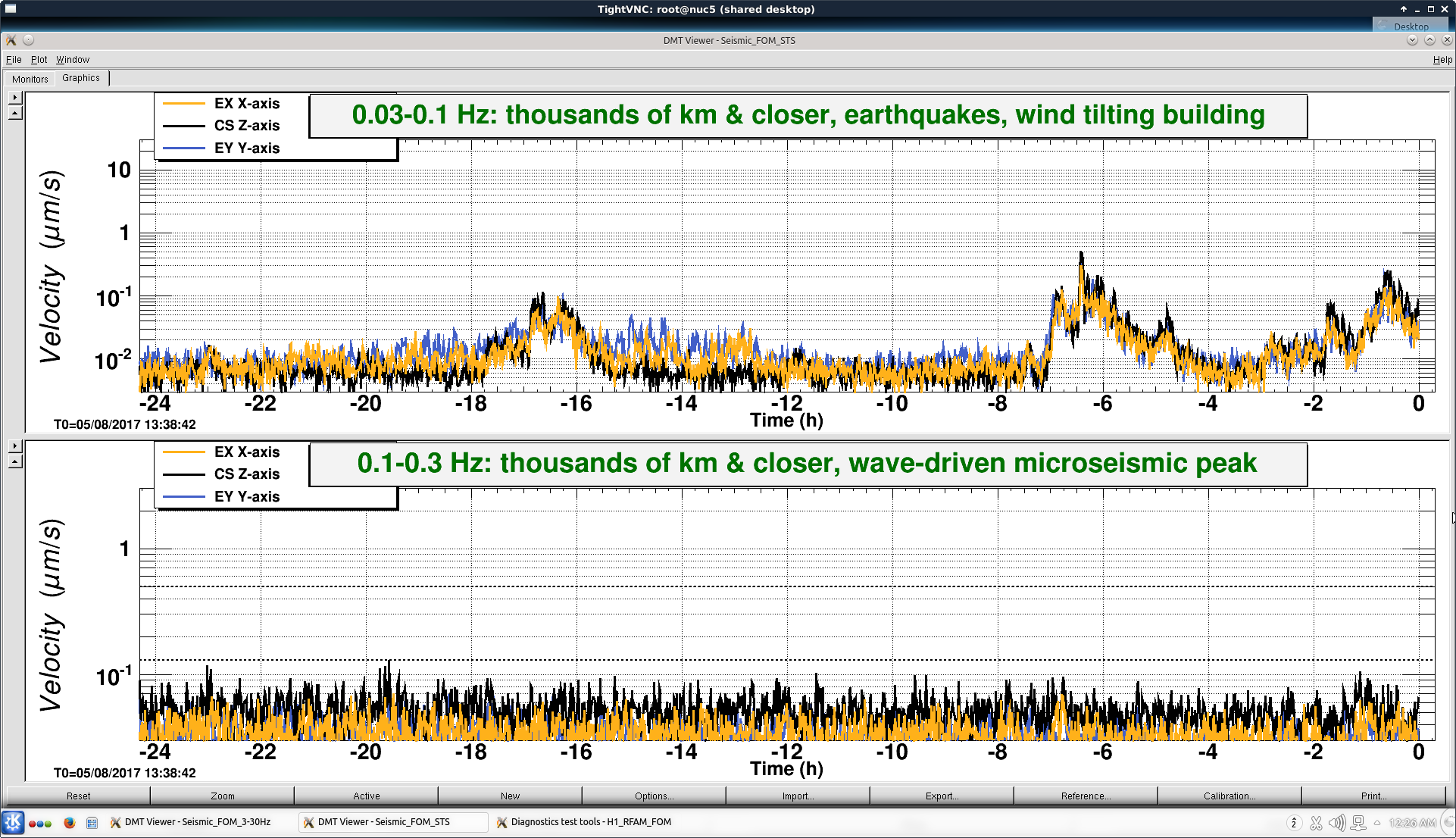
Primary useism: 0.01 μm/s
Secondary useism: 0.05 μm/s
QUICK SUMMARY:
GraceDB query failure (see previous alog). Talked to LLO and asked them to alert us when they receive notifications.