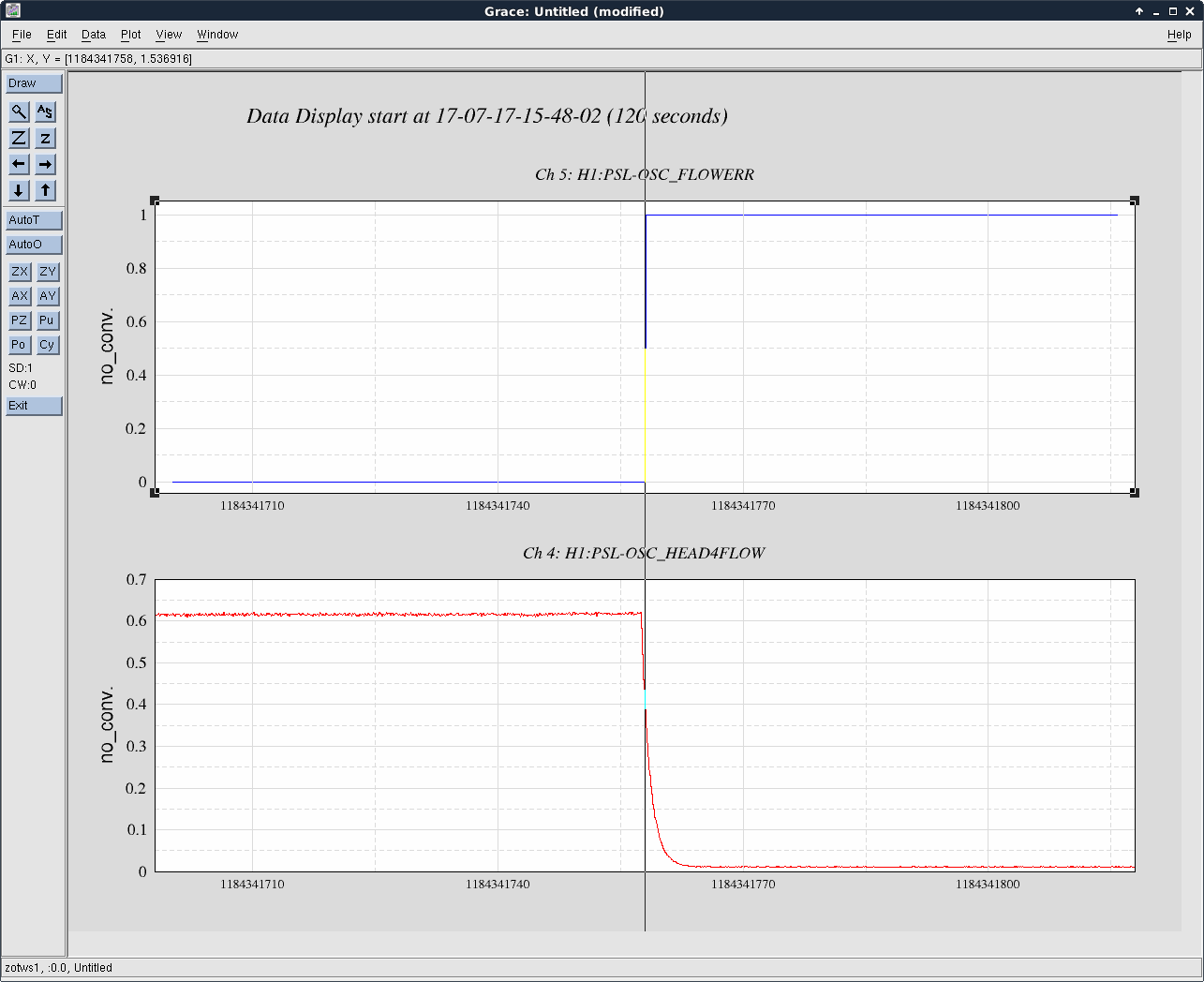
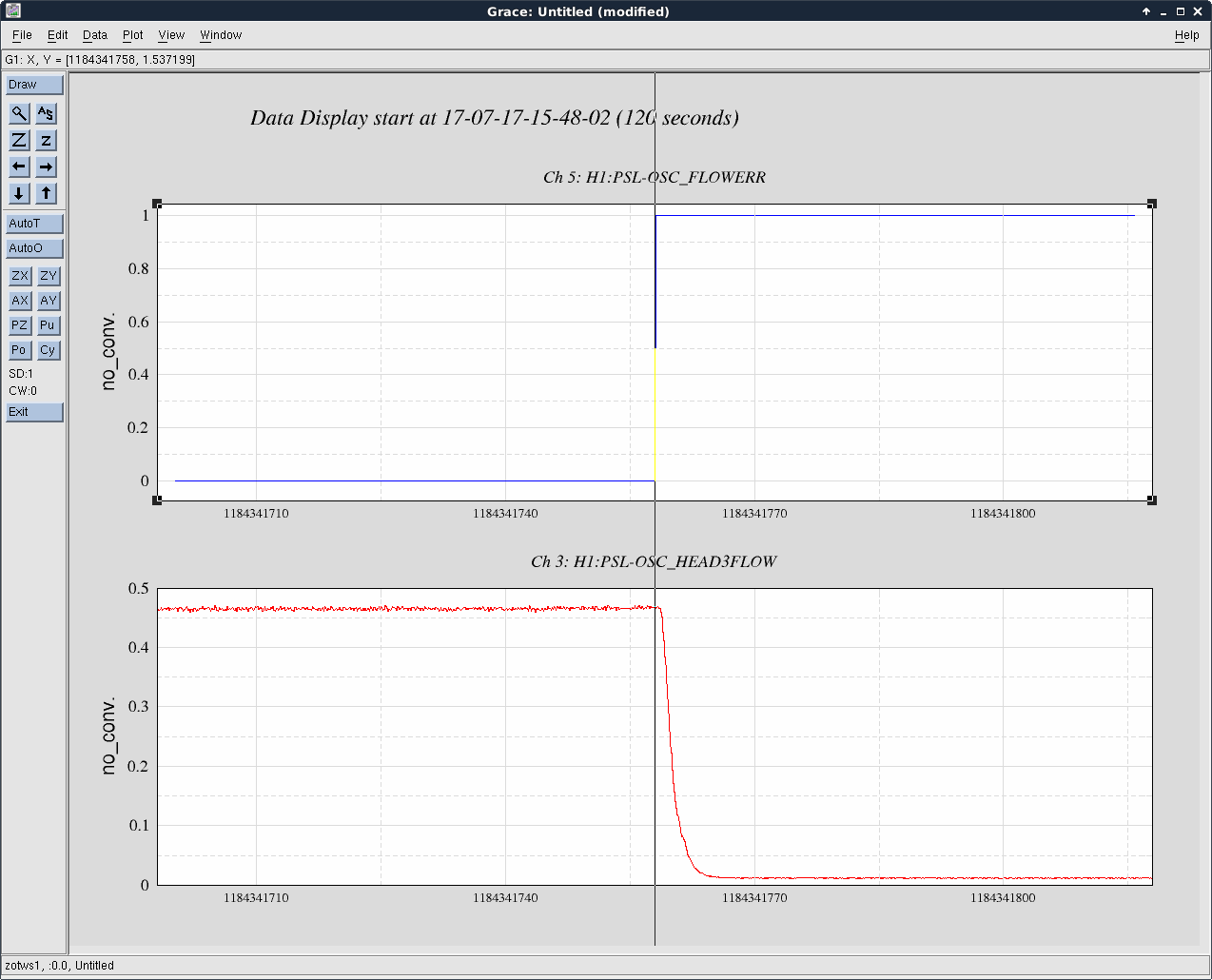
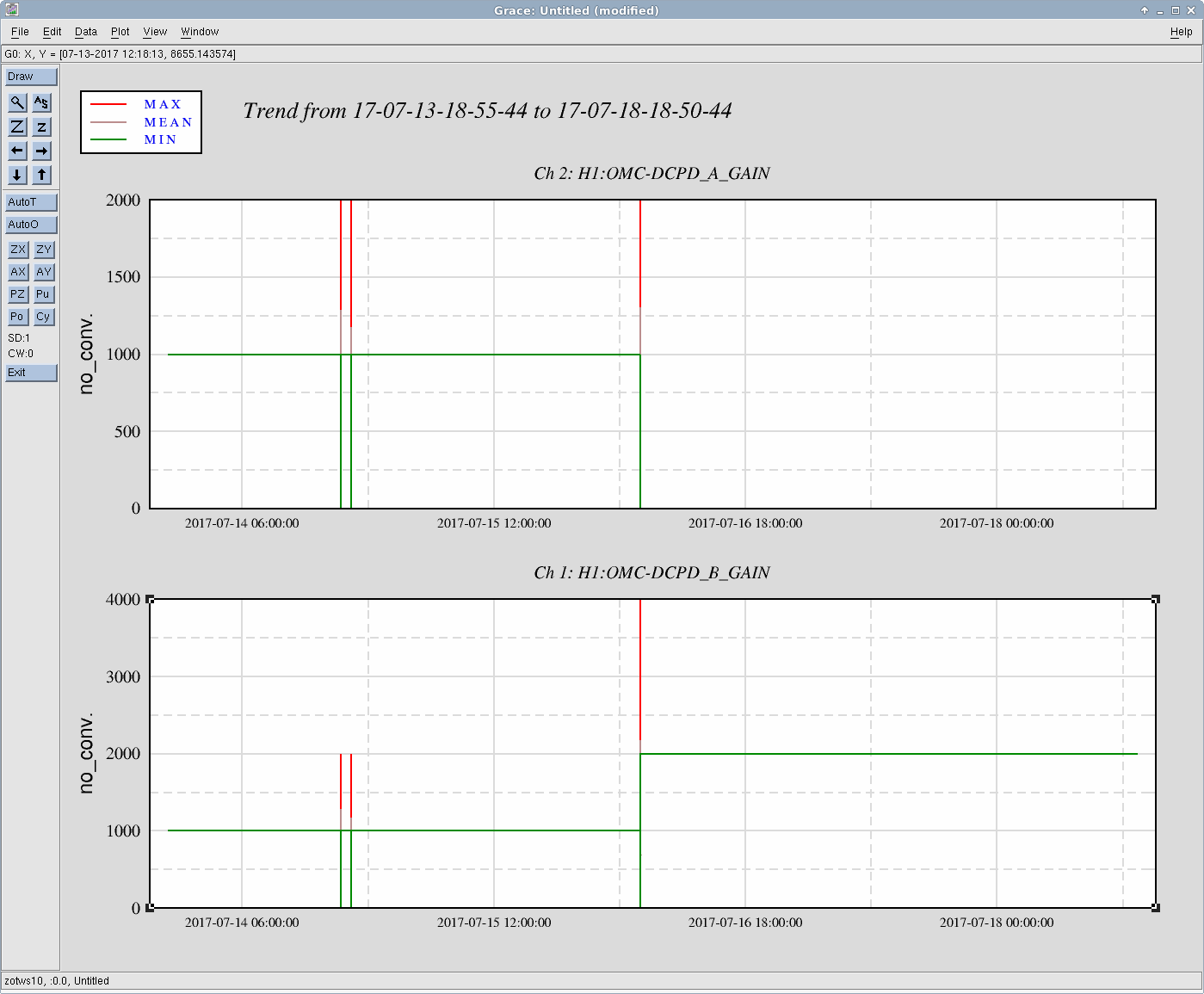
Keita pointed out that we have only been using OMC DCPD B for at least the last lock. I trended the relative gains of DCPD A and DCPD B, and it looks like we've been in this situation since 16July2017 at around 05:30 UTC.
The attached is a 5 day trend of the gains. The 2 spikes earlier are when we were either adding or removing a layer of whitening, due to the violin modes being too high. On the 16th, it looks like the guardian was started to switch the whitening, but then maybe got stopped halfway. This explains why it has looked like the shot noise was too high the last few days.
Clearly we need to write into the READY_FOR_HANDOFF OMC lock state to ensure that the 2 gains are both at their nominal values. Also, it looks like someone accepted the wrong values into the Observe SDF file, so we've been able to go to Observing with the wrong values :( No good. The safe SDF file was correct. I'll fix the Observe file.
EDIT: Looking through the guardian log file, it looks like the code gets a bit confused when you try to use these states before we're using the DCPDs for DARM. So, now if we're at DC_Readout_Transition or before (and don't need to do any gain ramping), we skip the gain changes and just change the whitening. If we're on DC_Readout or after, the change will happen as before. Either way, at the end of the state is now a check to see if the DCPD gains are equal (they should both be 1000). The new code is in the svn and has been reloaded, although not actually used.
Tagging CAL and DetChar.
The exact time of departure from this configuration is Jul 16 2017 05:24:00 UTC (1184217858) and return to normal is Jul 18 2017 18:58:00 UTC (1184439498) We (the calibration group) have recommended that any observation time within the period be marked with a CAT1 veto, citing that the detector was in a non-O2-standard configuration and the calibration is suspect. Yes, it is plausible to reconstruct the calibration during these times, but given our limited person-power we have elected to abandon the effort at this time.
No problem, I made a flag and inserted it in to the segment database. H1:DCH-CAL_NON_O2_STANDARD_CONFIG:1 captures this time.