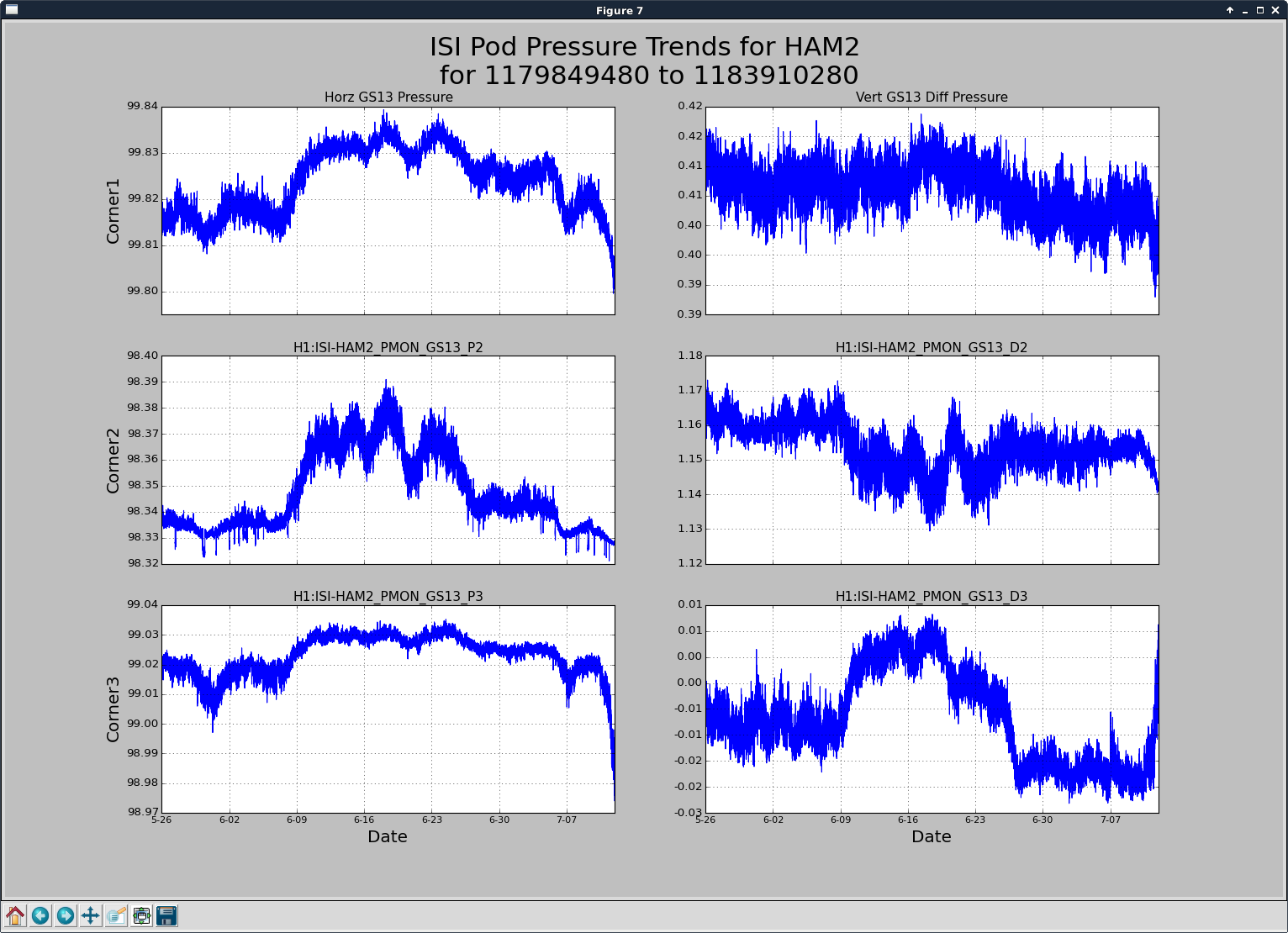
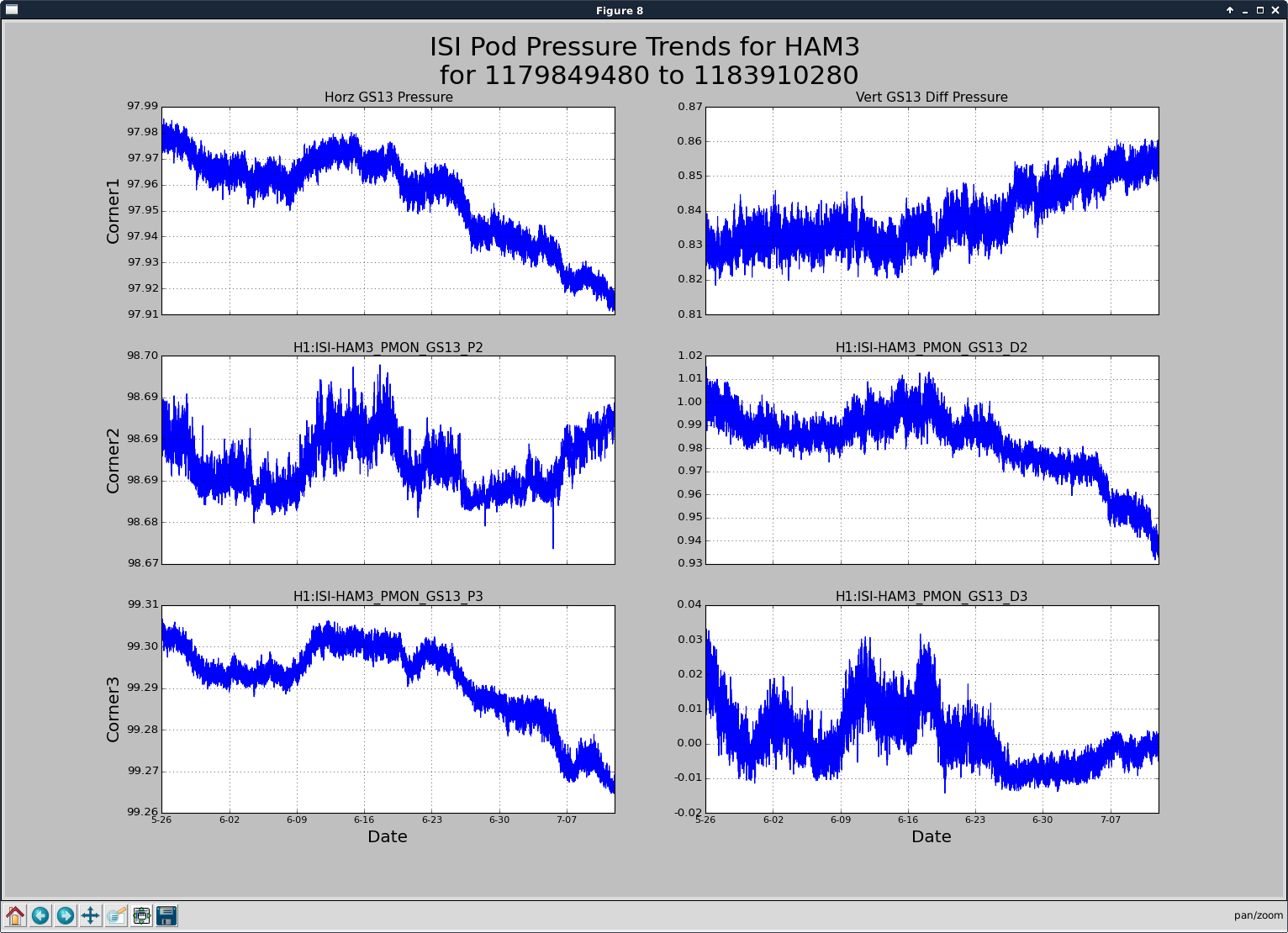
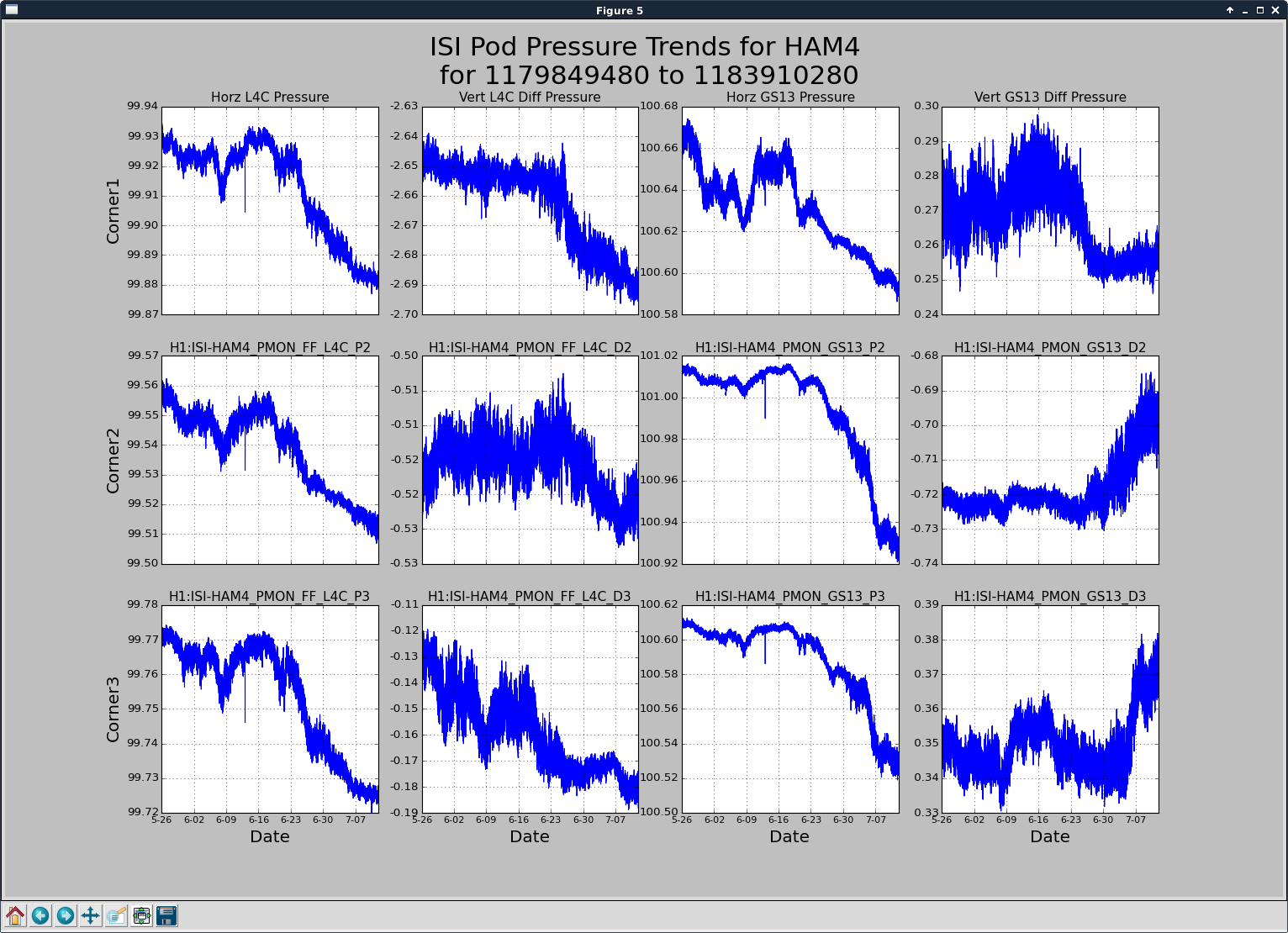
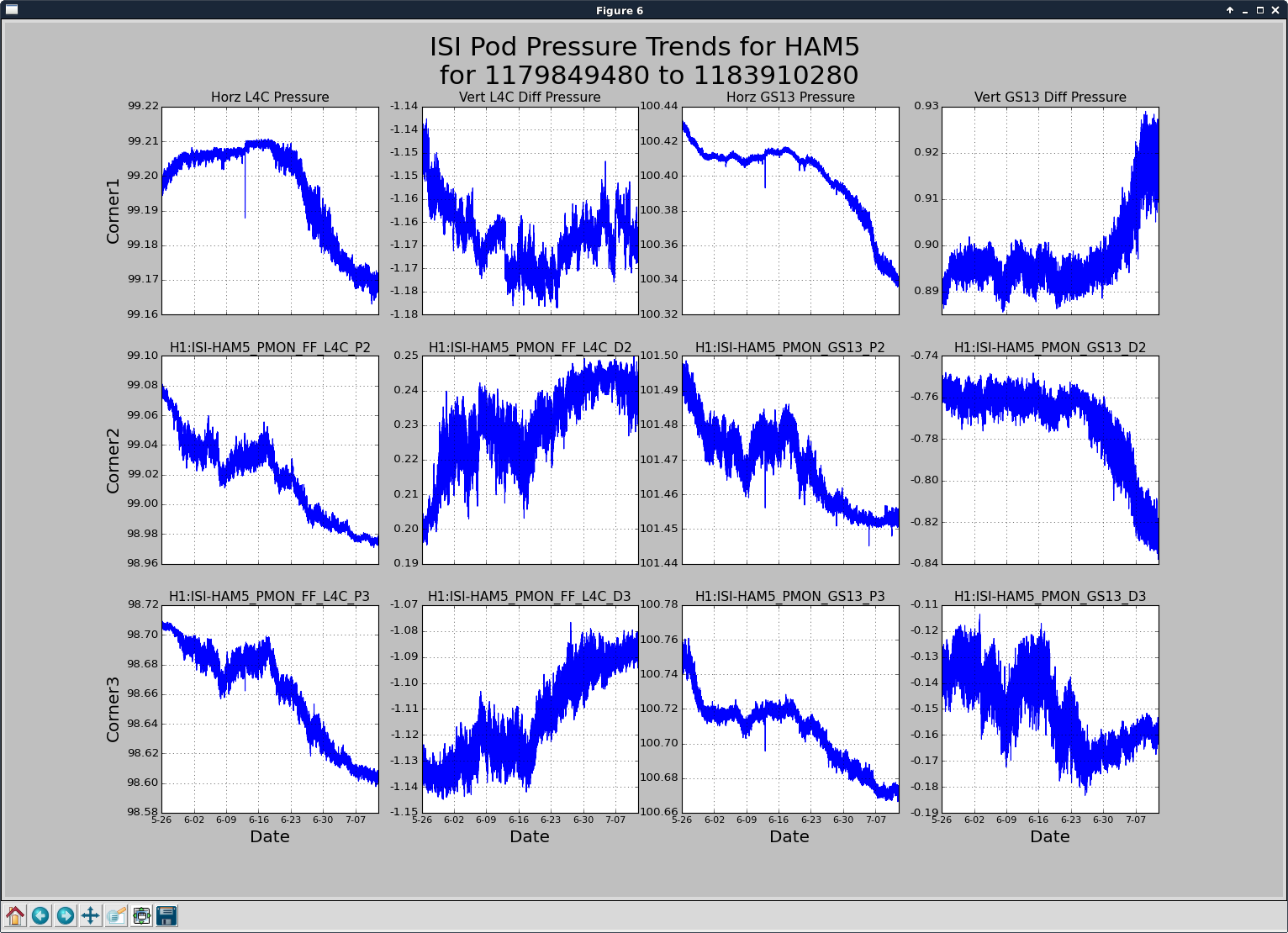
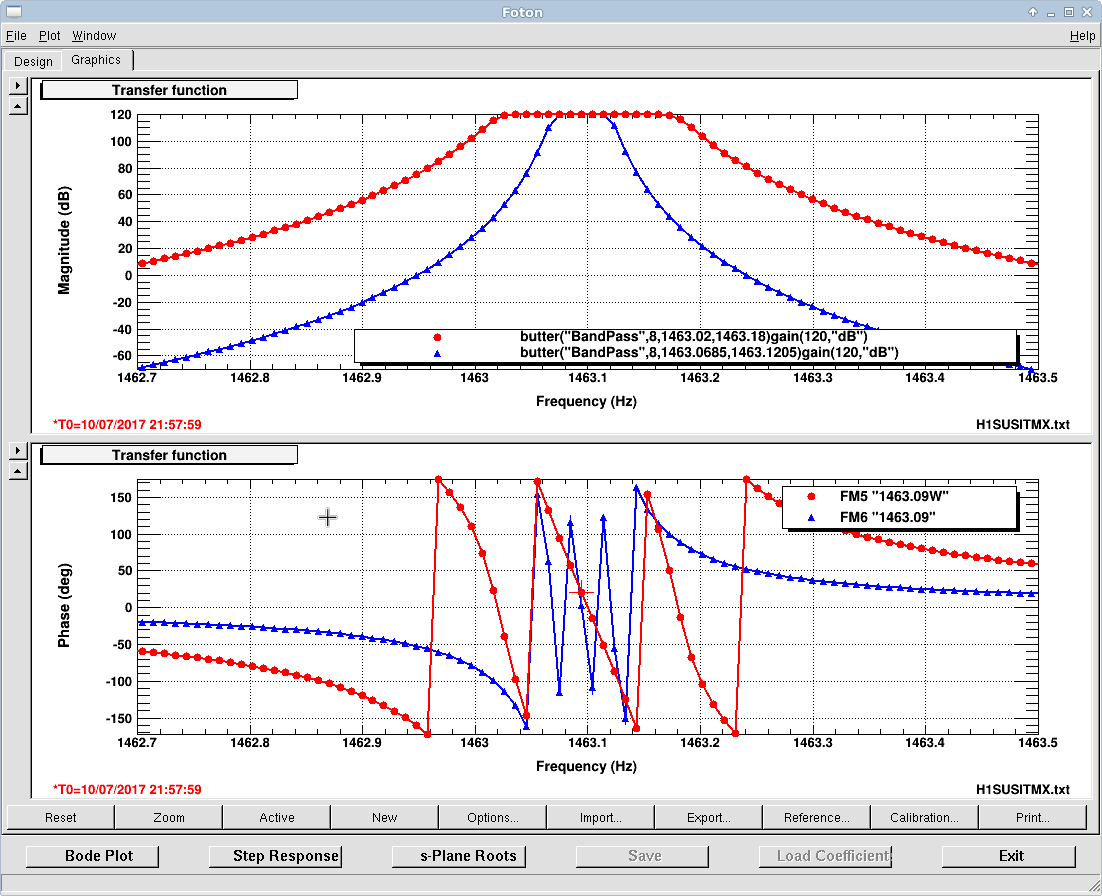
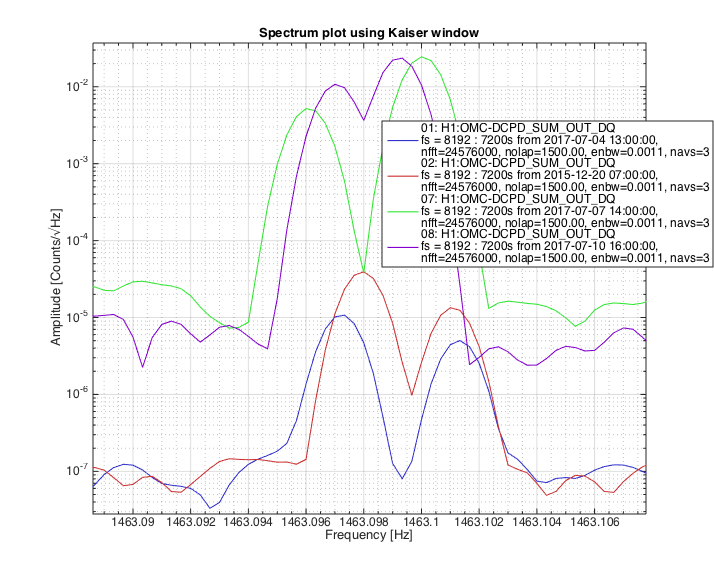
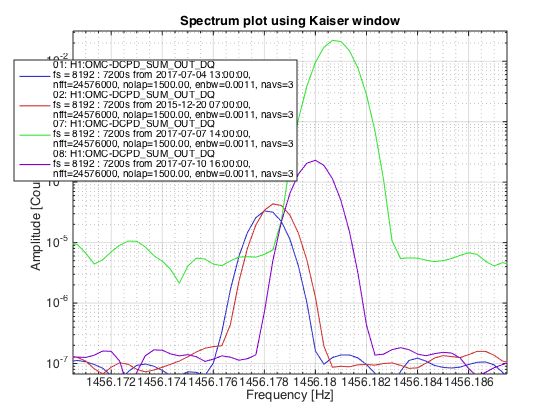
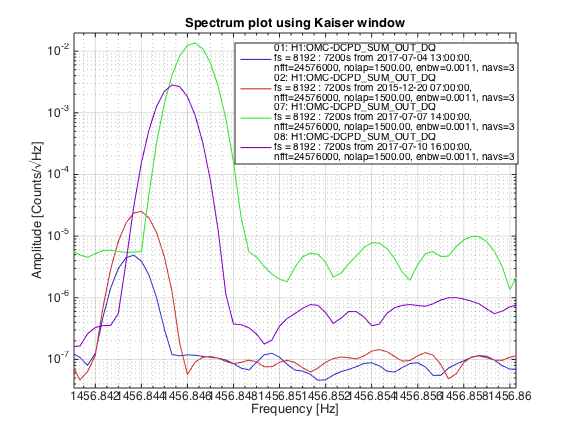
patrick.thomas@LIGO.ORG - posted 00:13, Thursday 13 July 2017 (37487)
Ops Eve Shift Summary
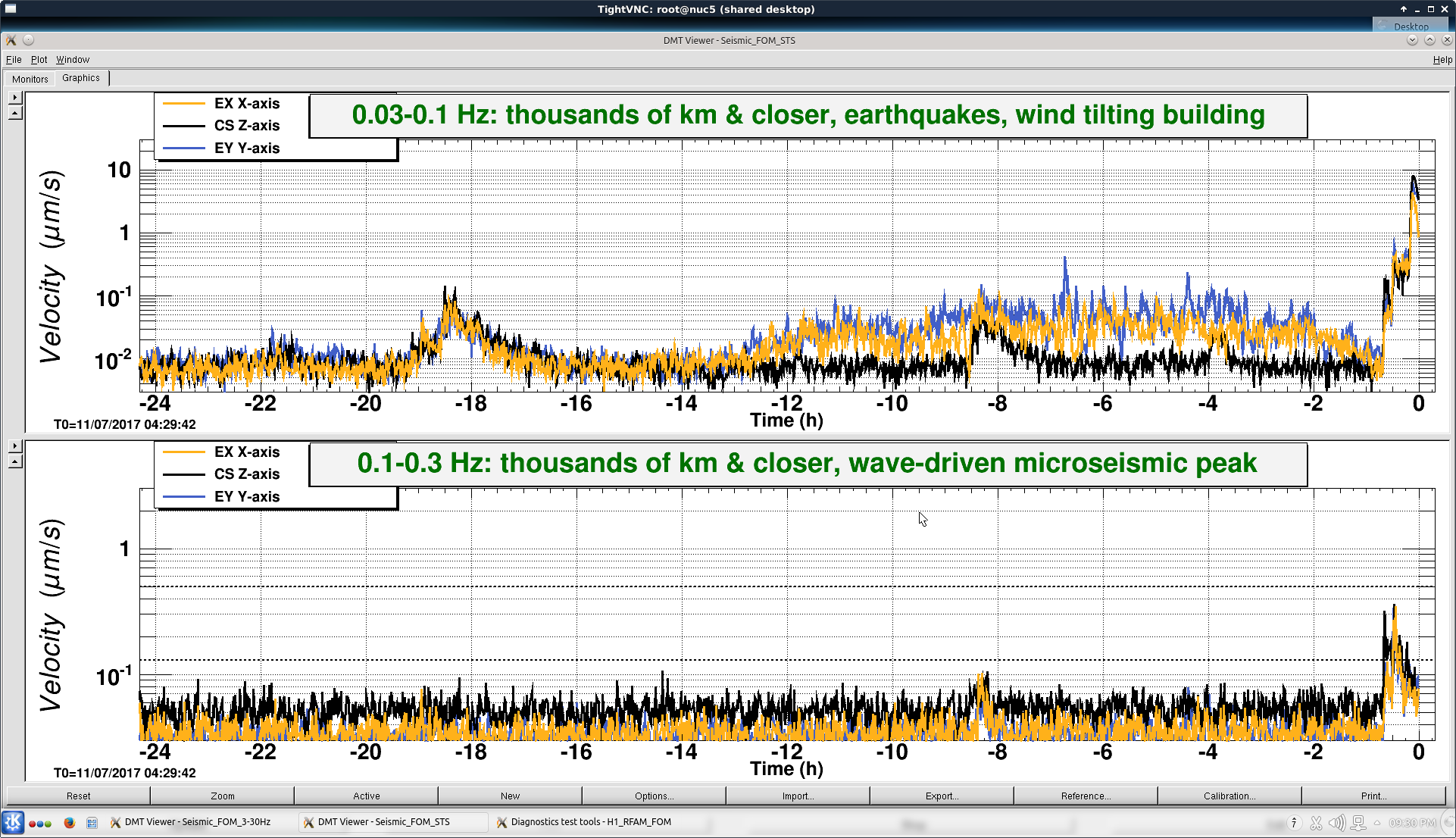
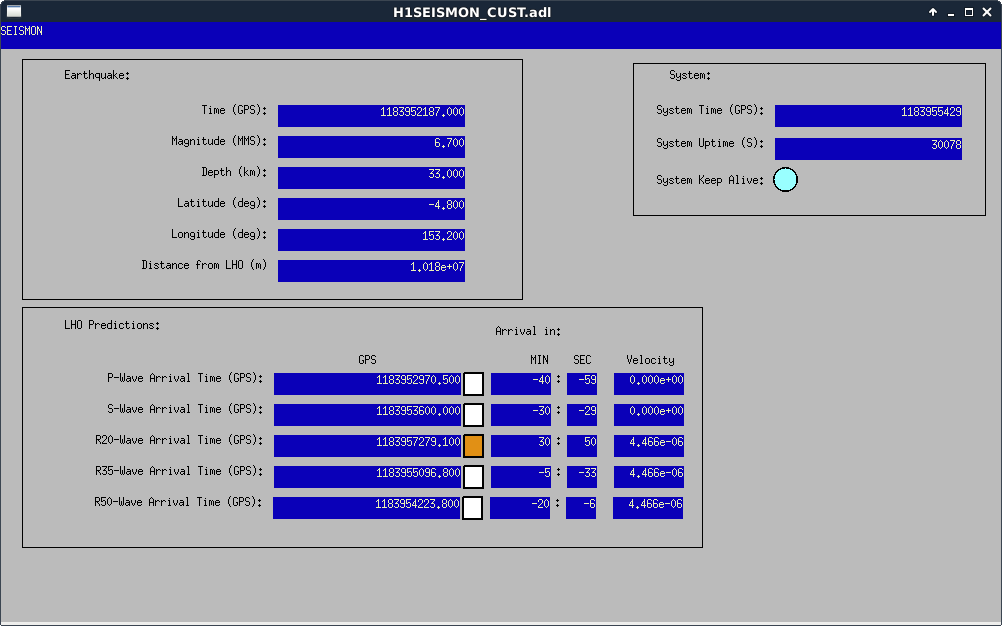
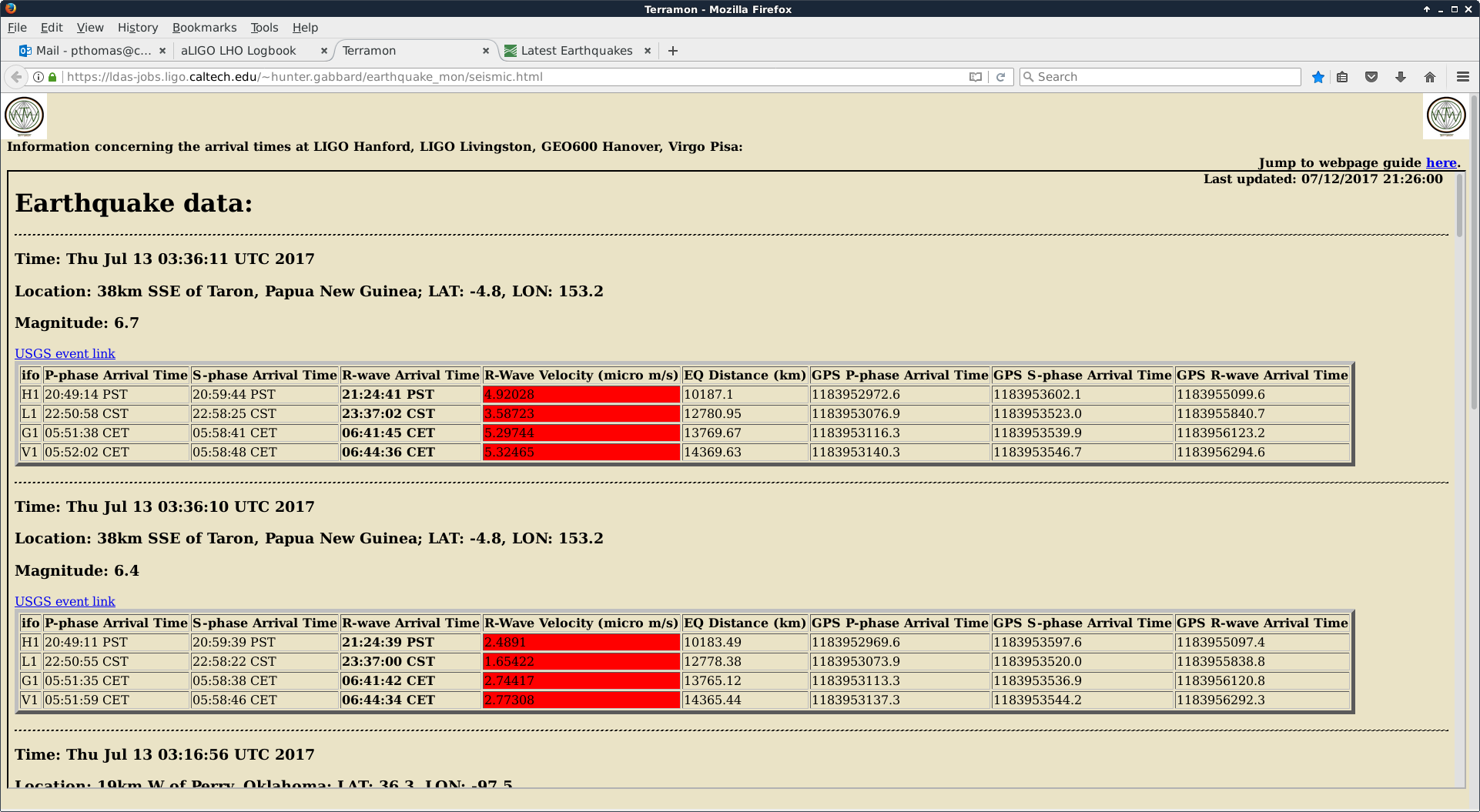
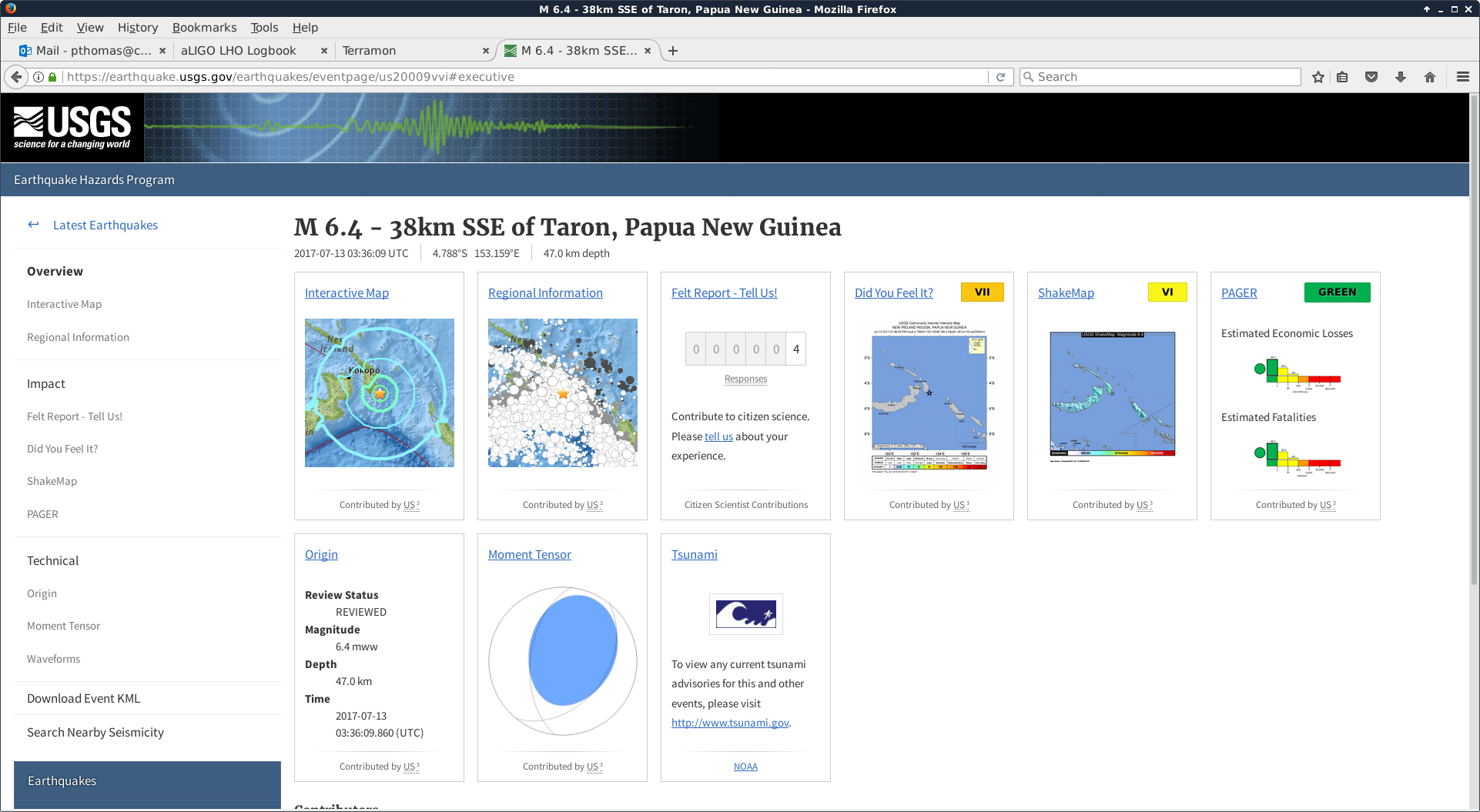
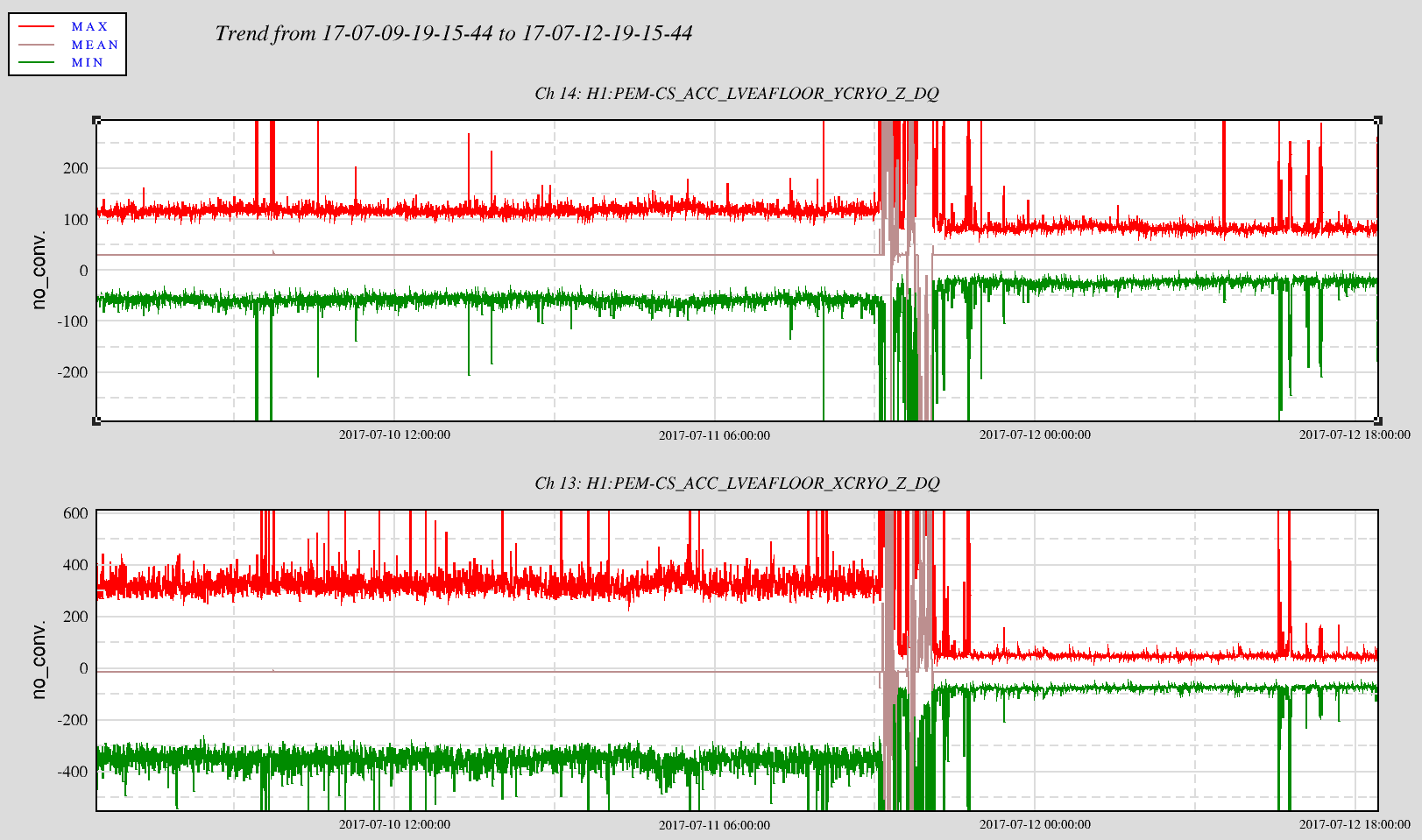
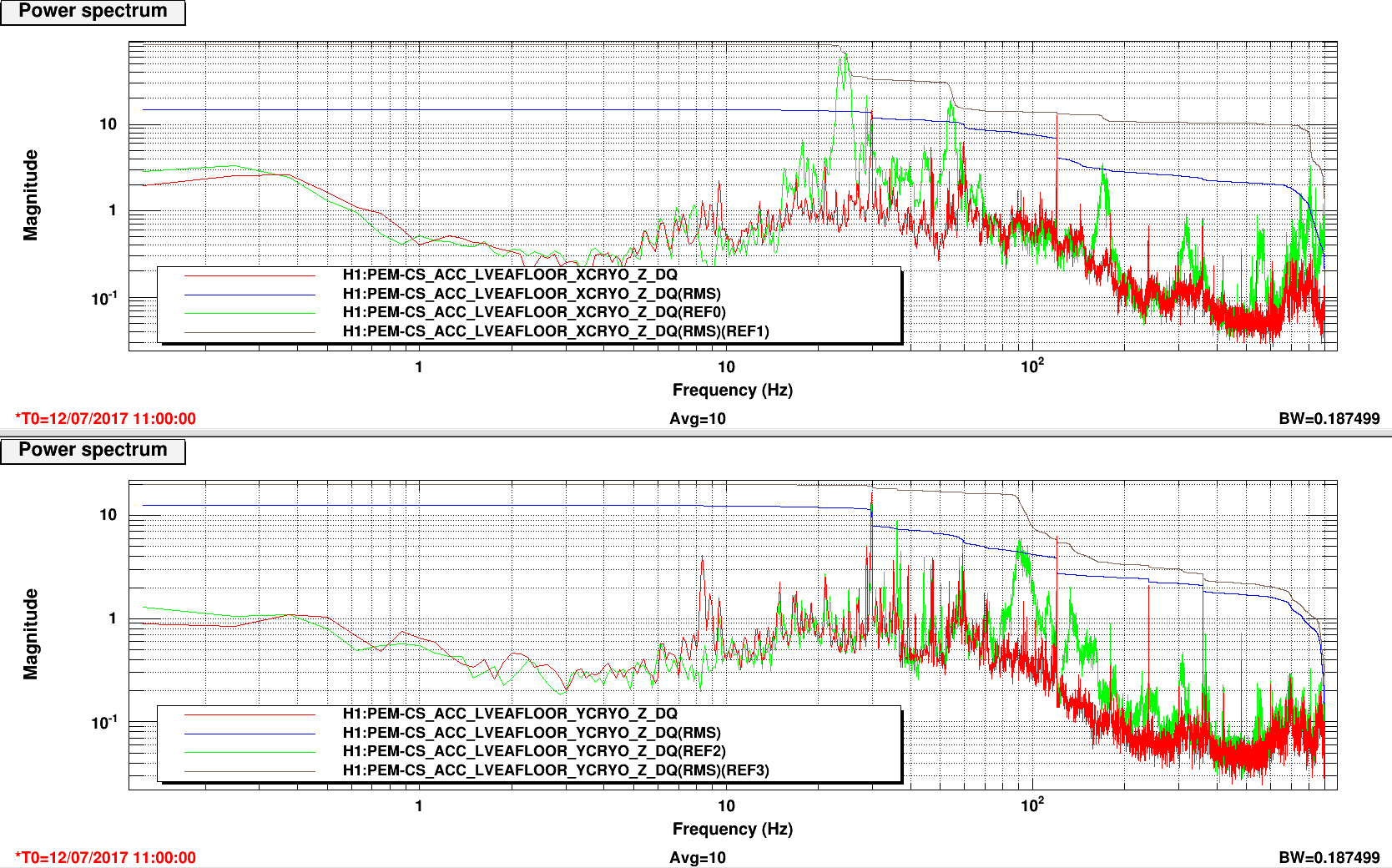
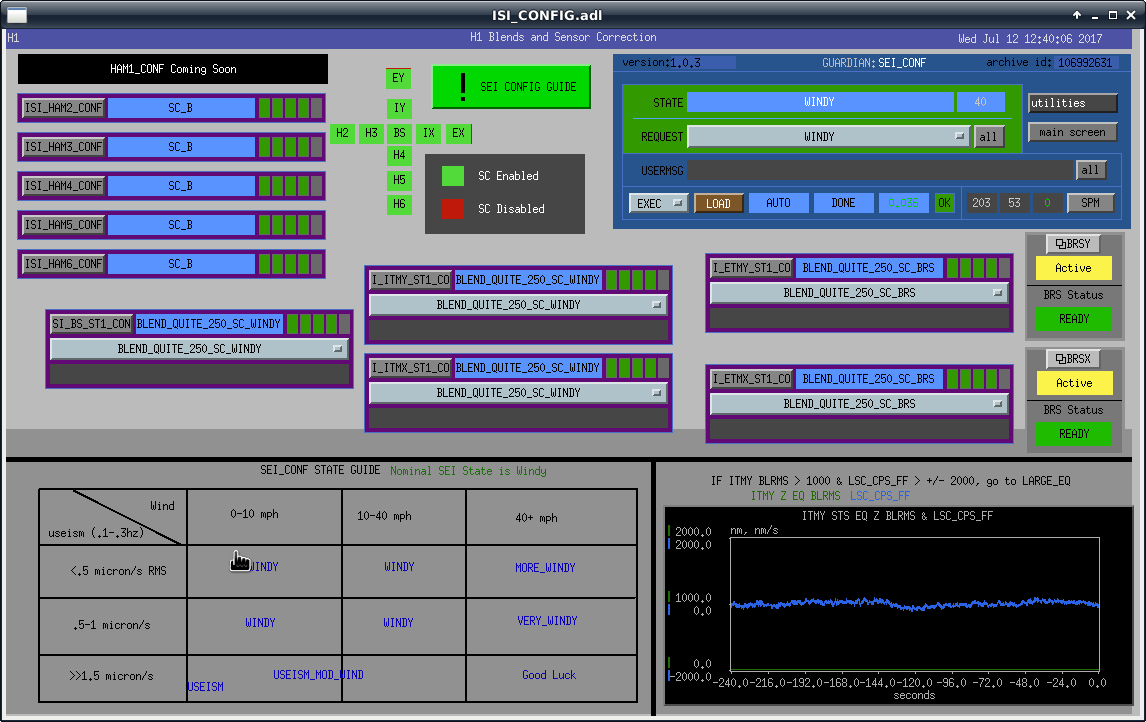
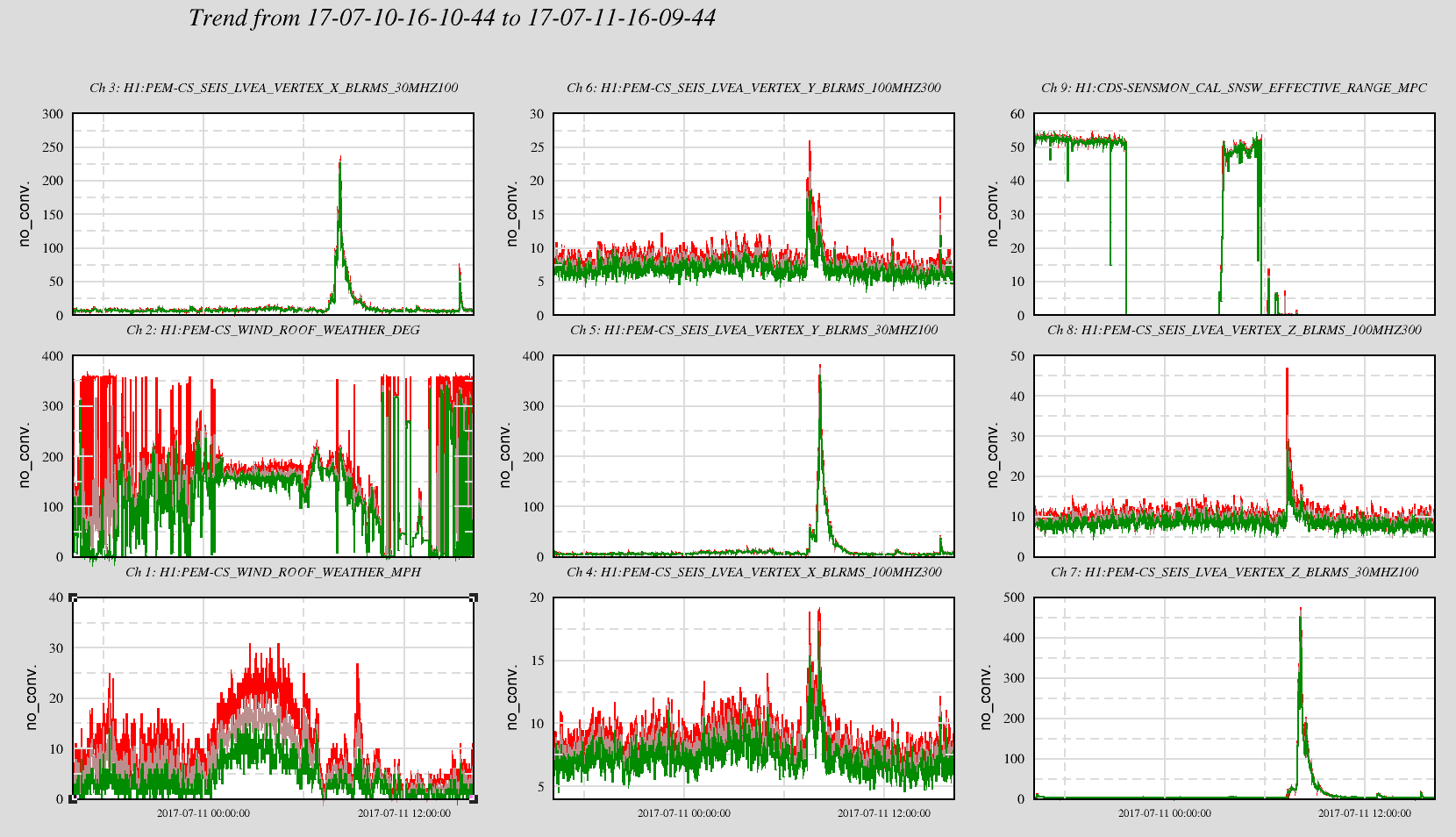
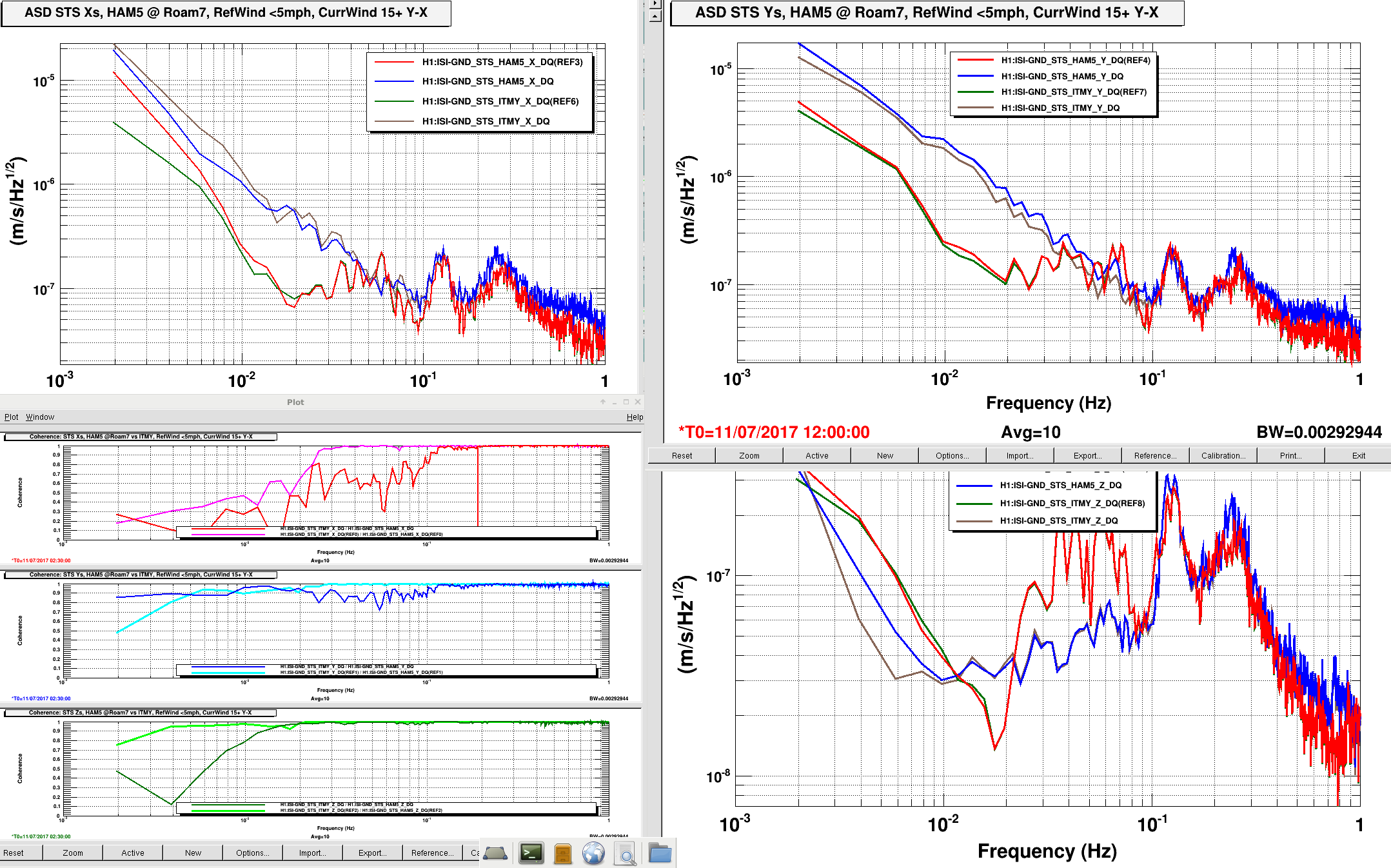
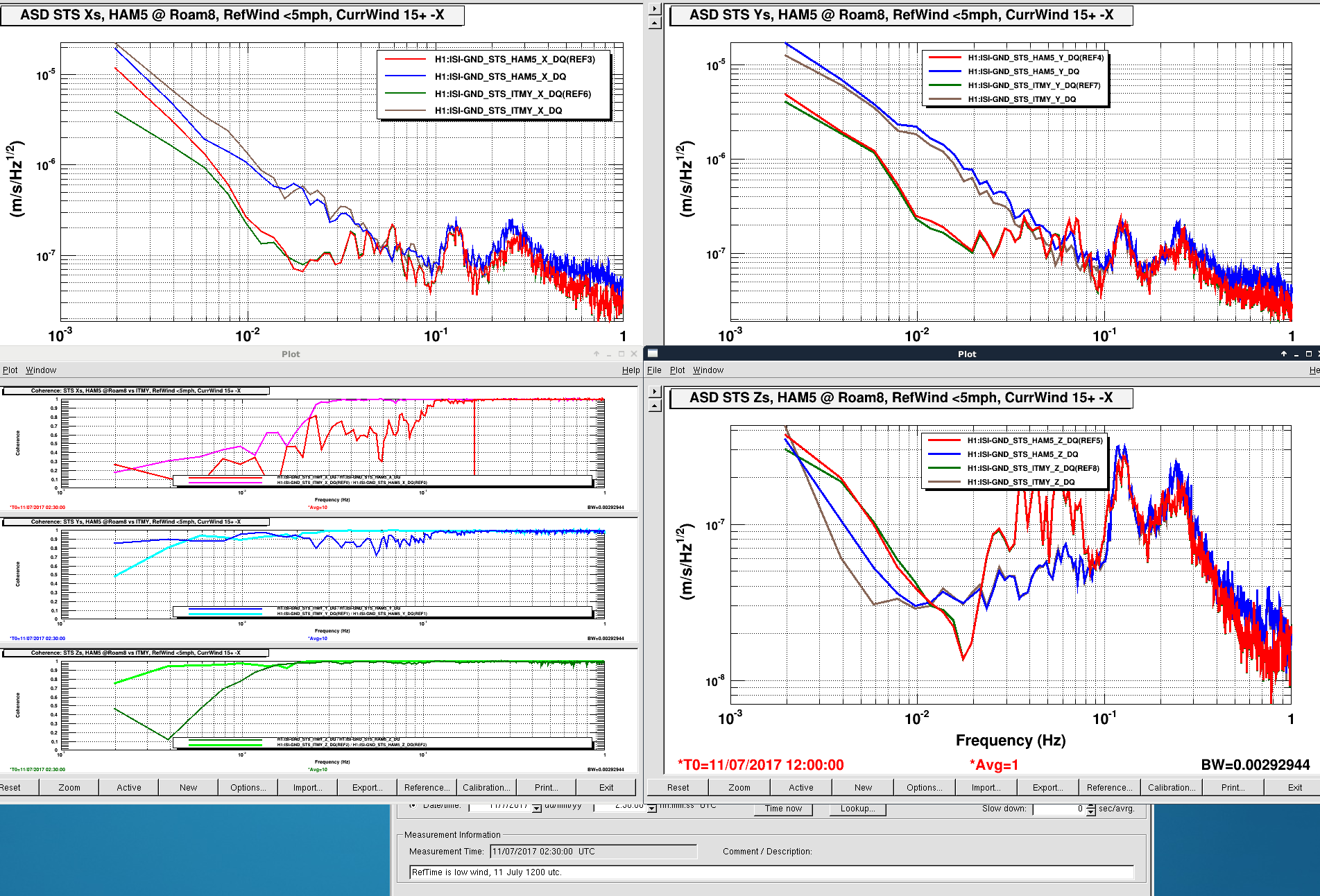
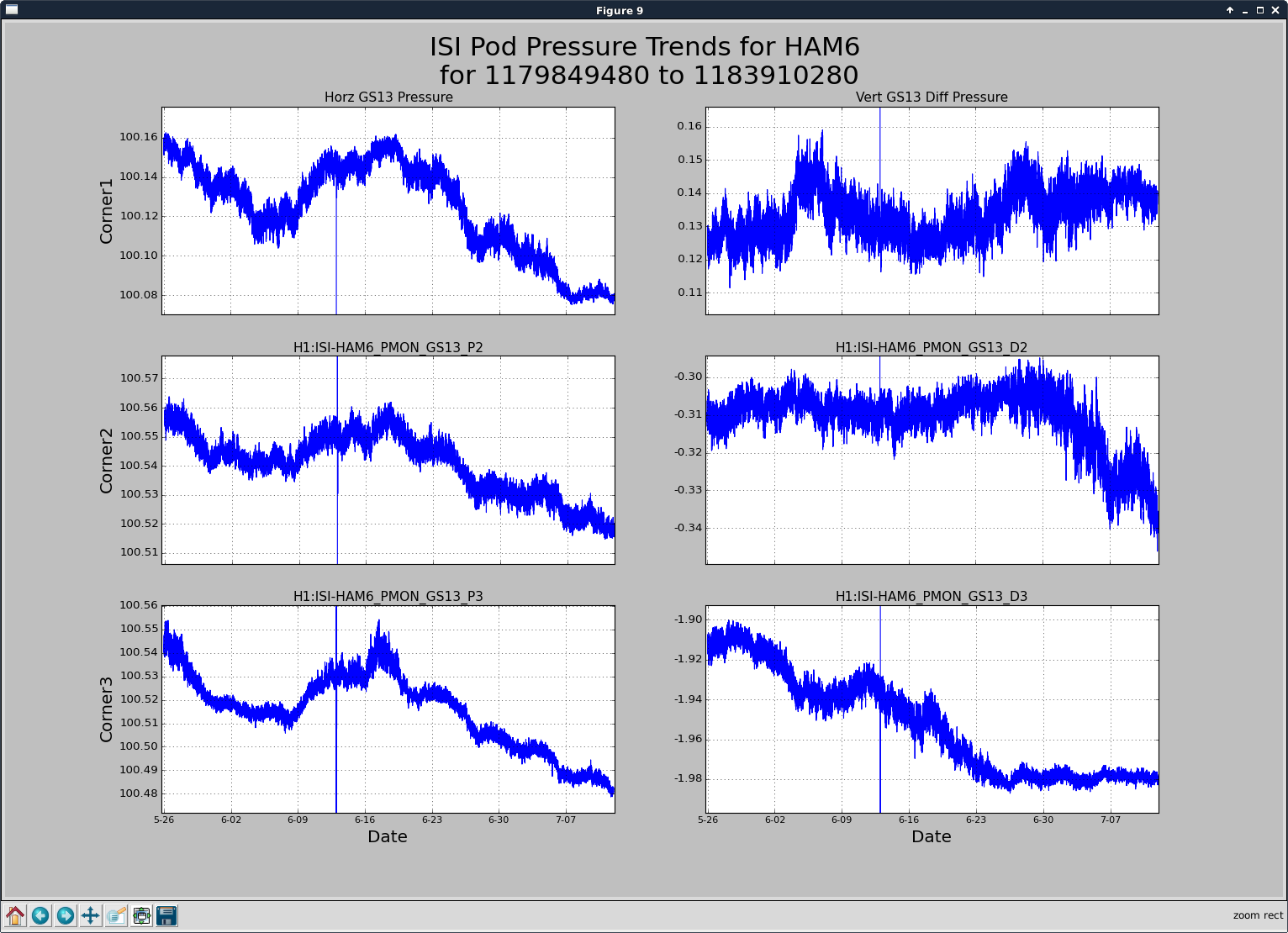
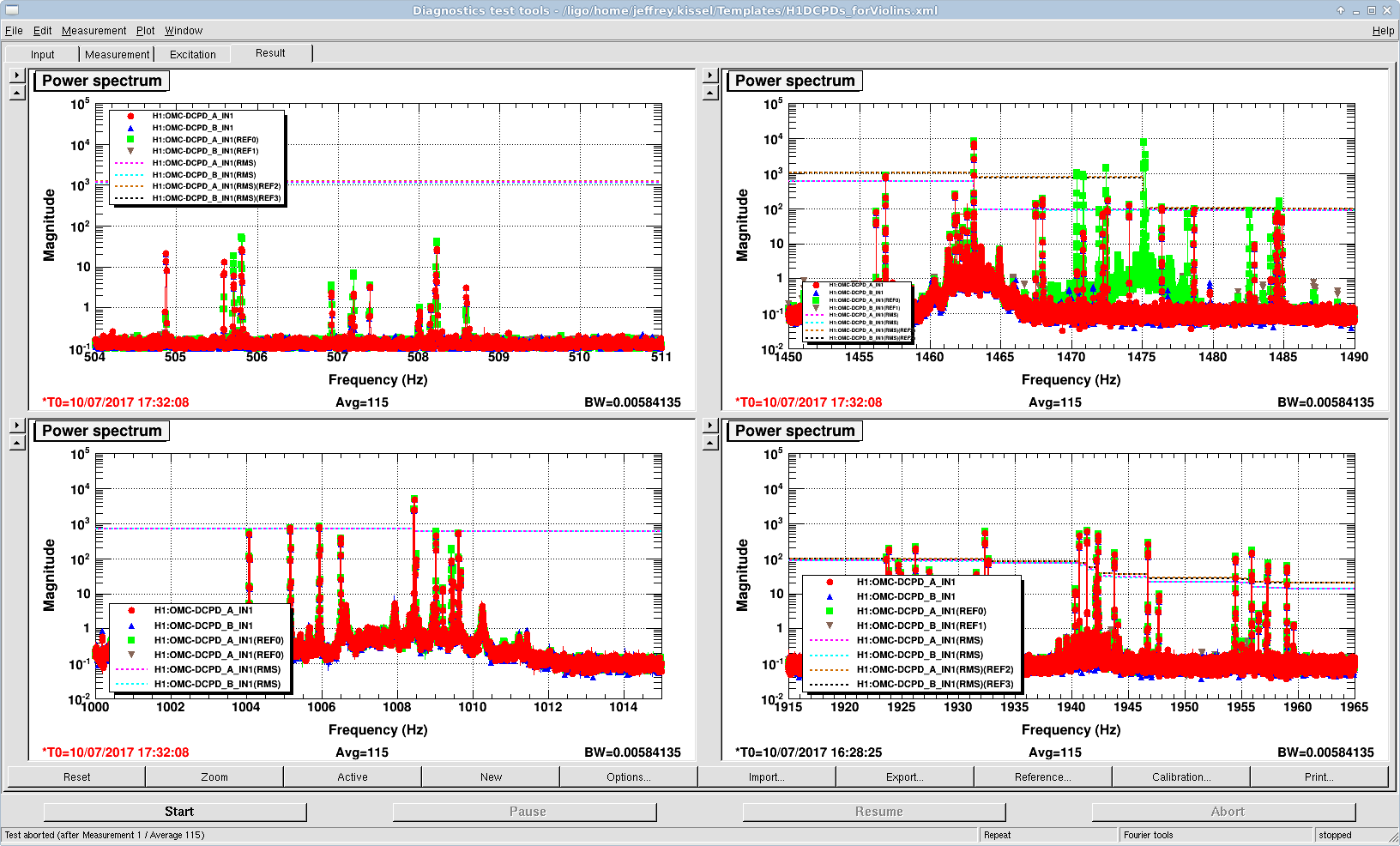
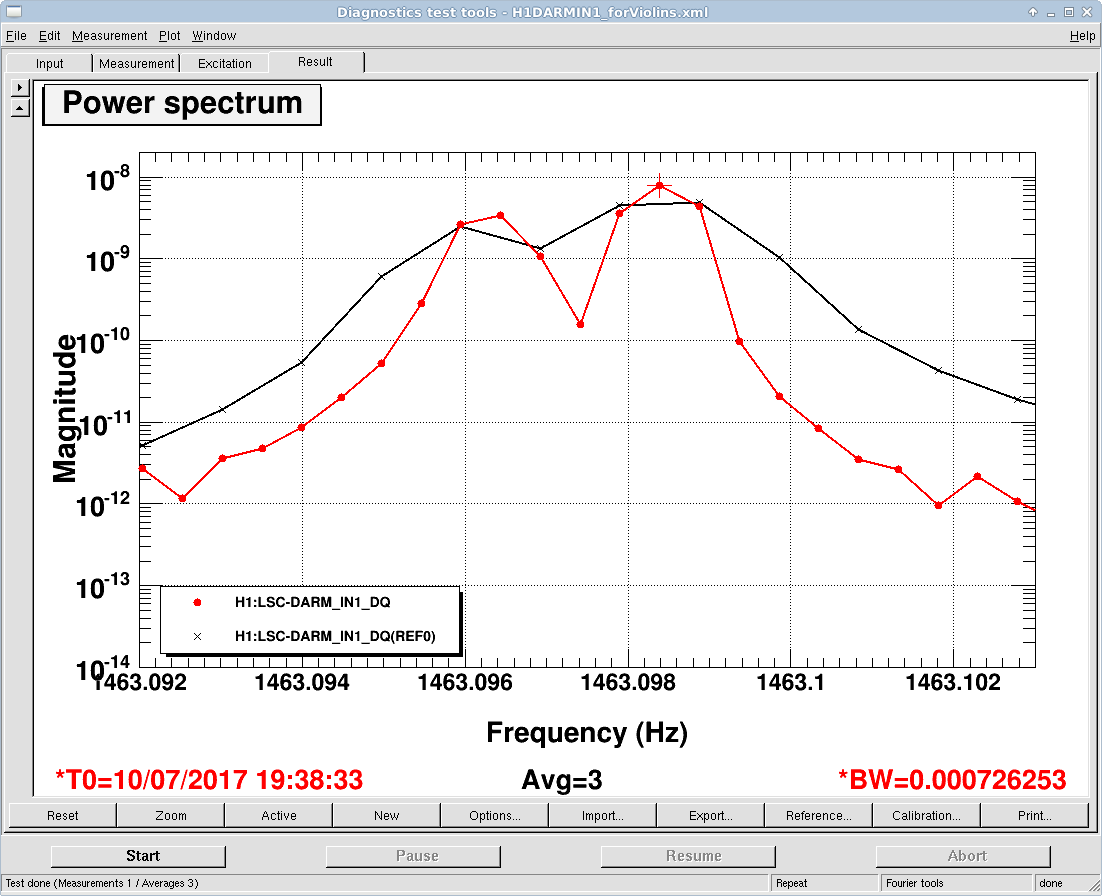
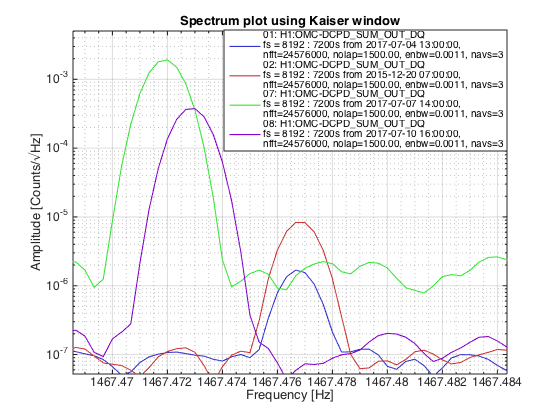
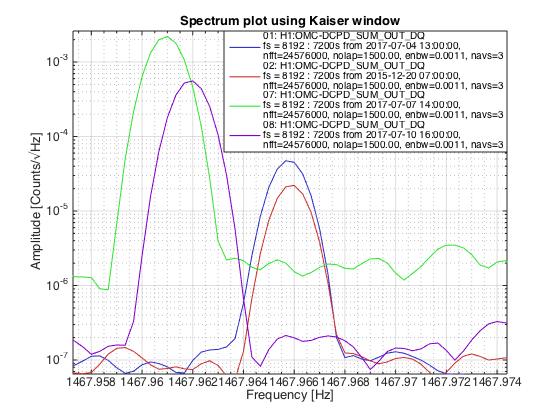
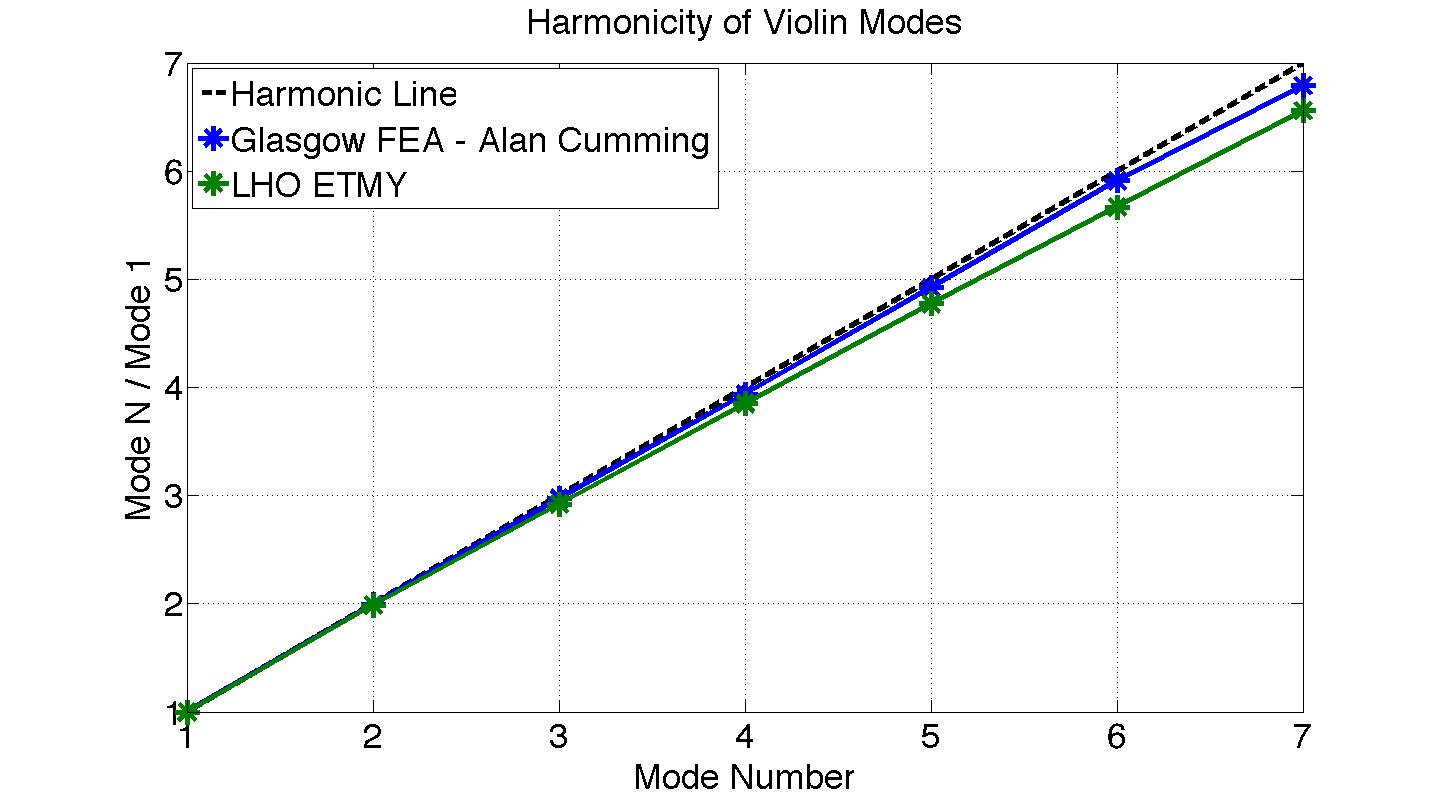
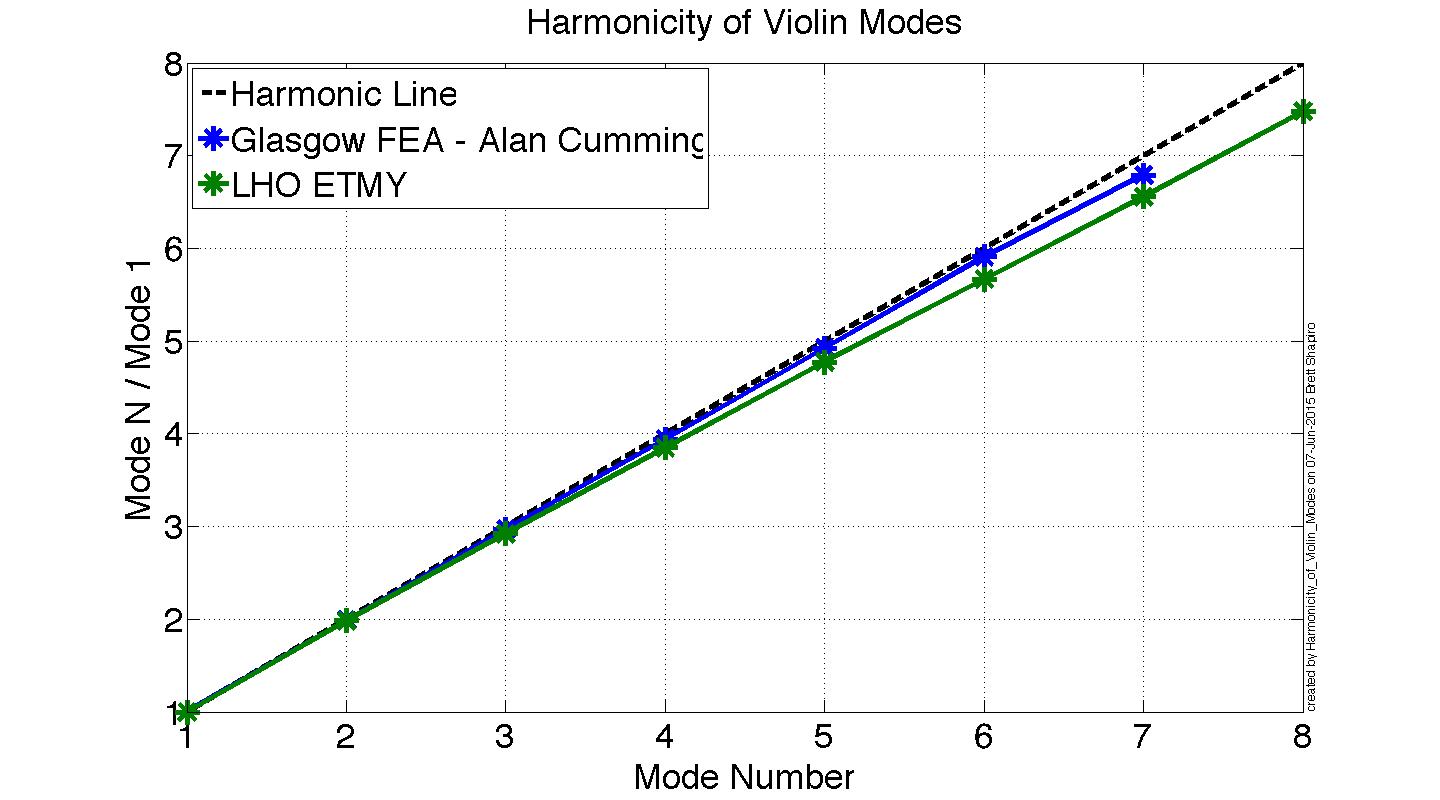
TITLE: 07/12 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC STATE of H1: Earthquake INCOMING OPERATOR: TJ SHIFT SUMMARY: Things were going relatively well until an earthquake in Papua New Guinea knocked us out of lock. I had just finished setting all the ITMX violin mode damping settings for the first fundamentals to the values in the wiki table and had them damping successfully. I had been able to get the first fundamental of ETMY mode 4 to damp using the settings from the wiki table, but was not having much luck with modes 5 and 6. The ETMX, ITMX and ITMY watchdogs tripped when the earthquake hit. I set the ISI config to LARGE_EQ_NOBRSXY while they were tripping, it may have saved other tables. The BLRMS has almost come back down to nominal and I have put the ISI config back to WINDY. I was able to lock both arms on green, but the X arm is only around .89. I will suggest to TJ that he does an initial alignment. Rick called at 5:50 UTC to tell me he is working in his office. LOG: 00:06 UTC Kyle back from mid station 05:30 UTC Reset ETMX ISI watchdogs 05:33 UTC Reset ITMX ISI watchdogs 05:36 UTC Reset ITMY ISI watchdogs 06:09 UTC Trying locking arms green. BLRMS is ~ .2 in 0.03 - 0.1 Hz band Y arm locks, X arm not so much. 06:33 UTC Setting ISI config back to WINDY 06:35 UTC Cleared WFS history for X arm ALS. Got X arm to lock at ~.88. I think it is going to need an initial alignment.