sheila.dwyer@LIGO.ORG - posted 17:35, Monday 19 June 2017 (37000)
more spot position moves
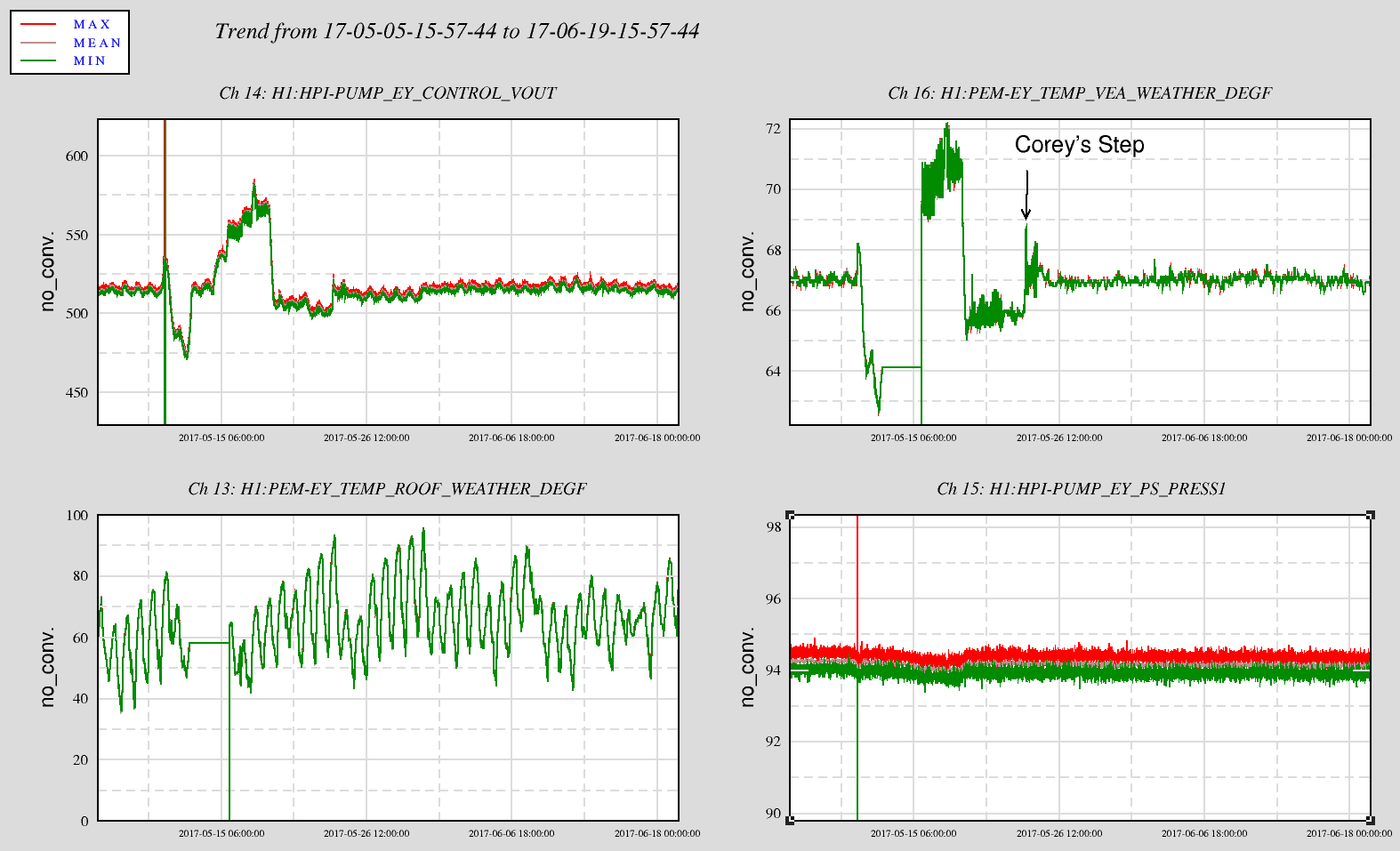
Today I spent some more time moving POP spot positions as well as soft again. In the end we have gone back to where we were over the weekend.
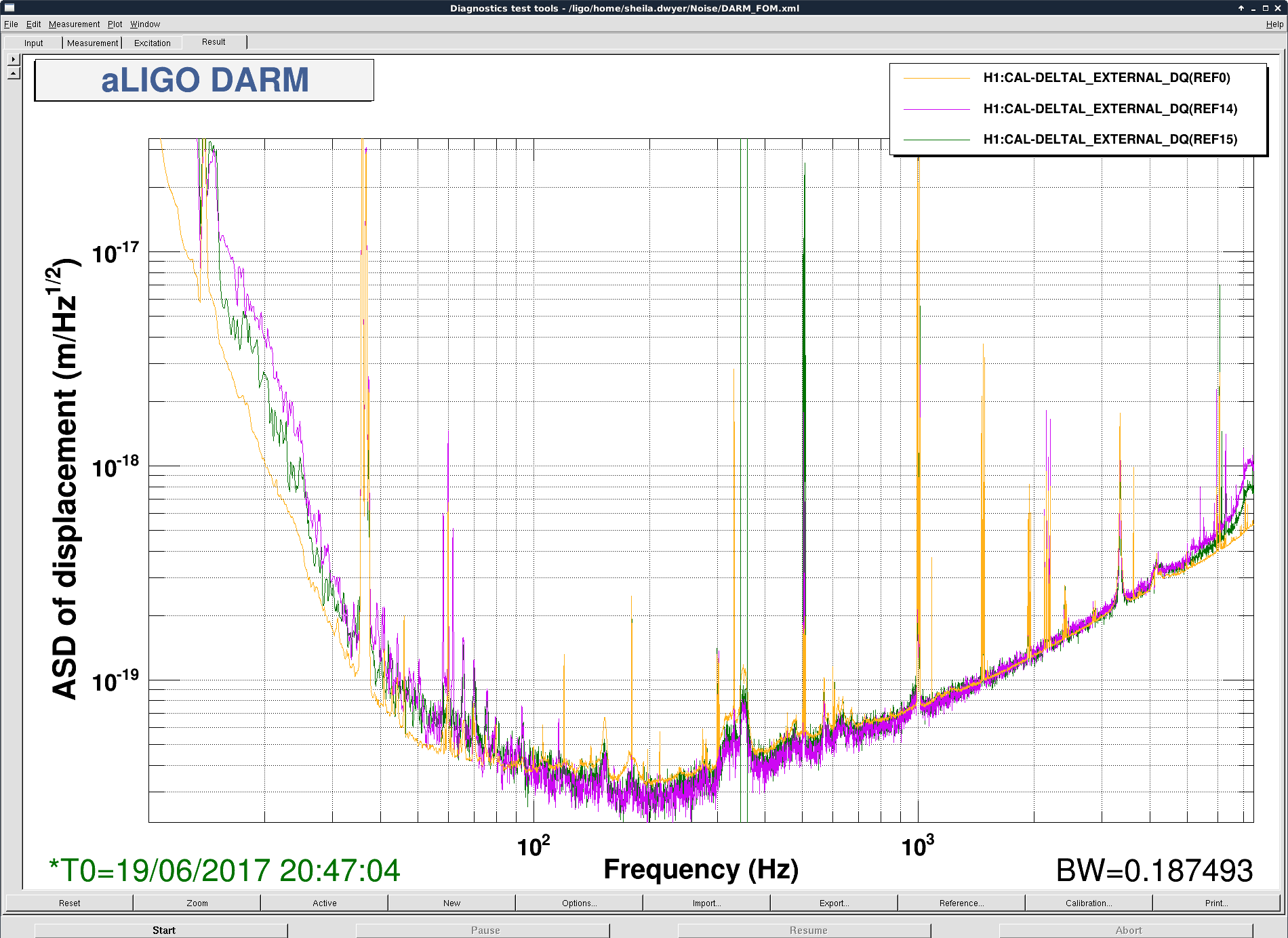
- The first attachment shows that there are some alignments for which we can have lower jitter than the alignment we had over the weekend. The degradation in sensitivity you see at low frequency is because the A2L was not tuned, and probably also because the SRCL FF might need to be returned for these new alignments. We can move the IFO to the locations where the jitter is better (P= 0.15, Y=0.2 for example) and use the soft offsets to make the recycling gain better (CSOFT +DSOFT Y offsets =0.07 brought the recycling gain back to 28 from about 24). Returning to these alignments where the jitter coupling had been seen to be better didn't result in a lower noise than over the weekend though- for some reason going back to the same spot on the POP QPD doesn't mean we get the same spectrum.
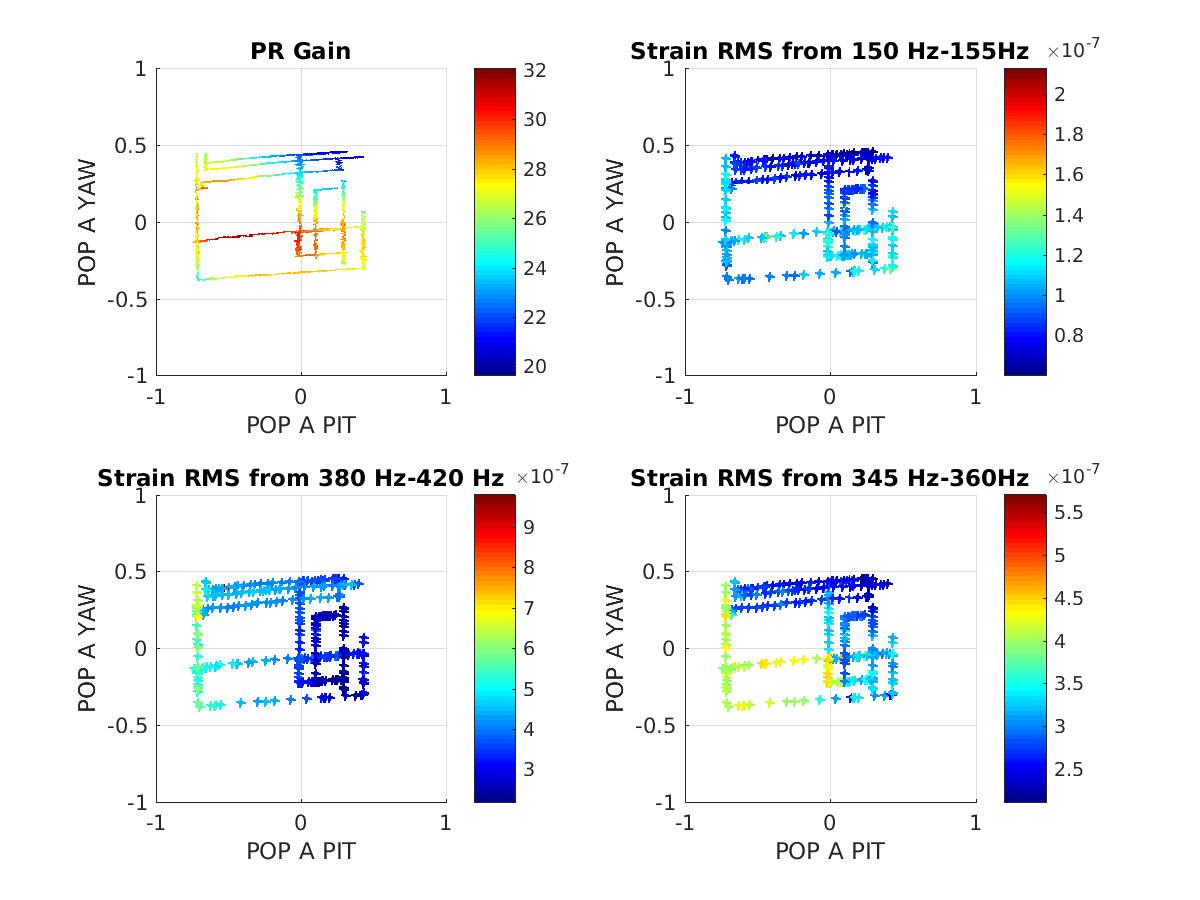
- The second attachment shows scatter plots of reycling gains and BLRMS in 3 bands made in the same way as the attachments to alog 36957, but with todays spot move added as well as a BLRMS around our largest jitter peak at 350Hz. You can see again from this plot that things aren't always the same when we return to the same POP A spot locatin, although all this data is taken with our usual soft offsets.
- We lost lock a couple of times due to what I think is the SRCL FF. We had an oscillation in SRCL (and the FF path) around 3 to 4 Hz, which does not show up in MICH.
- It might be possible to move the soft offsets to get better recycling gain at the location where our jitter was good, and redo this scan of POP offsets to see if we can have a better compromise position. It might not be a good use of time though, especially if we can't rely on the ASC to bring us back to the same spectrum in the future.
- Things that probably are worth putting some time into:
- better roll off for DHARD, this noise is worse than CHARD now that we put more agresive filters in CHARD
- LSC noise- decoupling PRCL from SRCL in the input matrix, turning back on the MICH actuator digitalization, and SRCL FF retuning
Images attached to this report