thomas.shaffer@LIGO.ORG - posted 00:59, Friday 30 June 2017 - last comment - 02:50, Friday 30 June 2017(37234)
Lockloss @ 07:58 UTC
No obvious cause.
No obvious cause.
TITLE: 06/30 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 68Mpc
OUTGOING OPERATOR: Travis
CURRENT ENVIRONMENT:
Wind: 5mph Gusts, 3mph 5min avg
Primary useism: 0.01 μm/s
Secondary useism: 0.07 μm/s
QUICK SUMMARY: 2 hour lock after recovering from an earthquake.
TITLE: 06/30 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 69Mpc
INCOMING OPERATOR: TJ
SHIFT SUMMARY: Some trouble after the EQ lockloss, but all seems to be well now. Lock is ~2 hours old.
LOG:
6:34 Accidentally went out of Observe for less than 1 minute
I ran A2L again which seemed to clear a bunch of SDF diffs in ASC (maybe it didn't complete the previous time I ran it), but not all of them. I accepted the remaining diffs (sorry, no screenshot). DARM spectrum looks normal again and we are at ~70 MPc.
When running A2L the past couple of times, I have noticed that the terminal is displaying errors about 'Leap second data expired' that I don't recall seeing before. See screenshot.
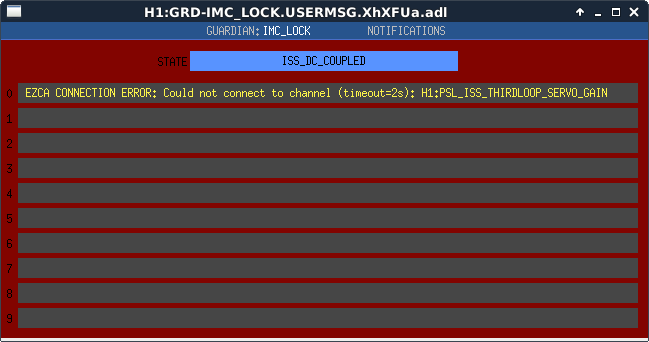
Although it seems to have stopped on its own, and Keita had a look at the code and didn't see any issues, IMC_LOCK went into an error state and reported something like "Cannot connect to ISS_THIRD_LOOP_SERVO_GAIN". Maybe someone in CDS-land can have a look at this and tell me if it was user error or otherwise.
It happened again when we got to NLN. See screenshot.
guardlog --today IMC_LOCK |grep THIRDLOOP_SERVO_GAIN
2017-06-30_03:06:41.523790Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0
2017-06-30_03:06:41.890790Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0.5
2017-06-30_03:25:46.604890Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0
2017-06-30_03:25:46.994710Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0.5
2017-06-30_03:31:43.967770Z IMC_LOCK [ISS_DC_COUPLED.main] USERMSG 0: EZCA CONNECTION ERROR: Could not connect to channel (timeout=2s): H1:PSL_ISS_THIRDLOOP_SERVO_GAIN
2017-06-30_03:50:27.959750Z IMC_LOCK [ISS_DC_COUPLED.main] USERMSG 0: EZCA CONNECTION ERROR: Could not connect to channel (timeout=2s): H1:PSL_ISS_THIRDLOOP_SERVO_GAIN
2017-06-30_03:54:58.400950Z IMC_LOCK [ISS_DC_COUPLED.main] USERMSG 0: EZCA CONNECTION ERROR: Could not connect to channel (timeout=2s): H1:PSL_ISS_THIRDLOOP_SERVO_GAIN
2017-06-30_04:17:24.381530Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0
2017-06-30_04:17:24.765150Z IMC_LOCK [POWER_UP_TR_CLOSED.main] ezca: H1:PSL-ISS_THIRDLOOP_SERVO_GAIN => 0.5
2017-06-30_04:23:40.218410Z IMC_LOCK [ISS_DC_COUPLED.main] USERMSG 0: EZCA CONNECTION ERROR: Could not connect to channel (timeout=2s): H1:PSL_ISS_THIRDLOOP_SERVO_GAIN
Is this a network problem or what? I can read the number using caget almost immediately as of now, though.
This has happened the past 2 brief locks. During these locks, the DARM spectrum is ~ an order of magnitude above the reference traces from ~300Hz to several kHz. The max range reported during these locks was ~30MPc.
Called Dave at Keita's request. He noticed that the error reported contained an typo for the channel name (should be PSL-ISS rather than PSL_ISS). I found the typo in the guardian code, fixed it, and reloaded the IMC_LOCK guardian. Hopefully this fixes it. Thanks Dave!
Was it reported by Terramon, USGS, SEISMON? Yes, Yes, Yes
Magnitude (according to Terramon, USGS, SEISMON): 5.3, 5.3, 5.9
Location: Northern Mid-Atlantic Ridge; LAT: 33.8, LON: -38.5
Starting time of event (ie. when BLRMS started to increase on DMT on the wall): 2:10 UTC
Lock status? H1 lost lock, L1 lost lock
EQ reported by Terramon BEFORE it actually arrived? Not sure.
Due to an 5.3 EQ Northern Mid Atlantic Ridge.
TITLE: 06/29 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Observing at 68Mpc
OUTGOING OPERATOR: Cheryl
CURRENT ENVIRONMENT:
Wind: 12mph Gusts, 9mph 5min avg
Primary useism: 0.05 μm/s
Secondary useism: 0.07 μm/s
QUICK SUMMARY: No issues handed off. Cruising for 2.5 hours on the latest Observing stretch.
TITLE: 06/29 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Observing at 66Mpc
INCOMING OPERATOR: Travis
SHIFT SUMMARY:
LOG:
I accidentally took the interferometer out of observe with an SDF mistake while I was setting up jitter monitor blrms in OAF. We were out of observe for 1 minutes starting at 20:33 UTC

Shifter: Beverly Berger
LHO Fellows: Pep Covas Vidal, Karl Toland
For complete results see https://wiki.ligo.org/DetChar/DataQuality/DQShiftLHO20170626
TITLE: 06/29 Day Shift: 15:00-23:00 UTC (08:00-16:00 PST), all times posted in UTC
STATE of H1: Observing at 69Mpc
OUTGOING OPERATOR: Ed
CURRENT ENVIRONMENT:
Wind: 10mph Gusts, 8mph 5min avg
Primary useism: 0.02 μm/s
Secondary useism: 0.06 μm/s
QUICK SUMMARY:
TITLE: 06/29 Owl Shift: 07:00-15:00 UTC (00:00-08:00 PST), all times posted in UTC
STATE of H1: Observing at 67Mpc
INCOMING OPERATOR: Cheryl
SHIFT SUMMARY:
Quiet shift.
LOG:
14:29 Peter into the optics lab.
12:54UTC Begin 1 hr stand down. Confirmed with LLO.
Observing 09:15 UTC for 1min and 12sec. I did an initial alignment after failing a few times, and that helped, at least till it broke lock a minute in.
Back to Observing at 09:47 UTC