SEI seismometer mass position check - Monthly FAMSI 26503
Averaging Mass Centering channels for 10 [sec] ...
2025-07-06 09:20:59.267796
There are 2 STS proof masses out of range ( > 2.0 [V] )!
STS EY DOF X/U = -4.661 [V]
STS EY DOF Z/W = 2.355 [V]
All other proof masses are within range ( < 2.0 [V] ):
STS A DOF X/U = -0.465 [V]
STS A DOF Y/V = -0.711 [V]
STS A DOF Z/W = -0.668 [V]
STS B DOF X/U = 0.173 [V]
STS B DOF Y/V = 0.977 [V]
STS B DOF Z/W = -0.395 [V]
STS C DOF X/U = -0.805 [V]
STS C DOF Y/V = 0.816 [V]
STS C DOF Z/W = 0.606 [V]
STS EX DOF X/U = -0.079 [V]
STS EX DOF Y/V = -0.064 [V]
STS EX DOF Z/W = 0.065 [V]
STS EY DOF Y/V = 1.178 [V]
STS FC DOF X/U = 0.194 [V]
STS FC DOF Y/V = -1.139 [V]
STS FC DOF Z/W = 0.616 [V]
Assessment complete.
--------------------------------------------------------------------------------------
Averaging Mass Centering channels for 10 [sec] ...
2025-07-06 09:21:50.265931
There are 12 T240 proof masses out of range ( > 0.3 [V] )!
ETMX T240 2 DOF X/U = -1.373 [V]
ETMX T240 2 DOF Y/V = -1.269 [V]
ETMX T240 2 DOF Z/W = -0.959 [V]
ITMX T240 1 DOF X/U = -2.0 [V]
ITMX T240 1 DOF Z/W = 0.441 [V]
ITMX T240 3 DOF X/U = -2.121 [V]
ITMY T240 3 DOF X/U = -0.942 [V]
ITMY T240 3 DOF Z/W = -2.559 [V]
BS T240 1 DOF Y/V = -0.349 [V]
BS T240 3 DOF Z/W = -0.431 [V]
HAM8 1 DOF Y/V = -0.521 [V]
HAM8 1 DOF Z/W = -0.843 [V]
All other proof masses are within range ( < 0.3 [V] ):
ETMX T240 1 DOF X/U = -0.124 [V]
ETMX T240 1 DOF Y/V = -0.124 [V]
ETMX T240 1 DOF Z/W = -0.167 [V]
ETMX T240 3 DOF X/U = -0.102 [V]
ETMX T240 3 DOF Y/V = -0.187 [V]
ETMX T240 3 DOF Z/W = -0.11 [V]
ETMY T240 1 DOF X/U = 0.002 [V]
ETMY T240 1 DOF Y/V = 0.097 [V]
ETMY T240 1 DOF Z/W = 0.159 [V]
ETMY T240 2 DOF X/U = -0.132 [V]
ETMY T240 2 DOF Y/V = 0.156 [V]
ETMY T240 2 DOF Z/W = 0.033 [V]
ETMY T240 3 DOF X/U = 0.164 [V]
ETMY T240 3 DOF Y/V = 0.019 [V]
ETMY T240 3 DOF Z/W = 0.062 [V]
ITMX T240 1 DOF Y/V = 0.237 [V]
ITMX T240 2 DOF X/U = 0.161 [V]
ITMX T240 2 DOF Y/V = 0.25 [V]
ITMX T240 2 DOF Z/W = 0.218 [V]
ITMX T240 3 DOF Y/V = 0.106 [V]
ITMX T240 3 DOF Z/W = 0.117 [V]
ITMY T240 1 DOF X/U = 0.033 [V]
ITMY T240 1 DOF Y/V = 0.095 [V]
ITMY T240 1 DOF Z/W = -0.0 [V]
ITMY T240 2 DOF X/U = 0.026 [V]
ITMY T240 2 DOF Y/V = 0.246 [V]
ITMY T240 2 DOF Z/W = 0.079 [V]
ITMY T240 3 DOF Y/V = 0.036 [V]
BS T240 1 DOF X/U = -0.085 [V]
BS T240 1 DOF Z/W = 0.157 [V]
BS T240 2 DOF X/U = 0.067 [V]
BS T240 2 DOF Y/V = 0.156 [V]
BS T240 2 DOF Z/W = 0.017 [V]
BS T240 3 DOF X/U = -0.166 [V]
BS T240 3 DOF Y/V = -0.3 [V]
HAM8 1 DOF X/U = -0.234 [V]
Assessment complete.
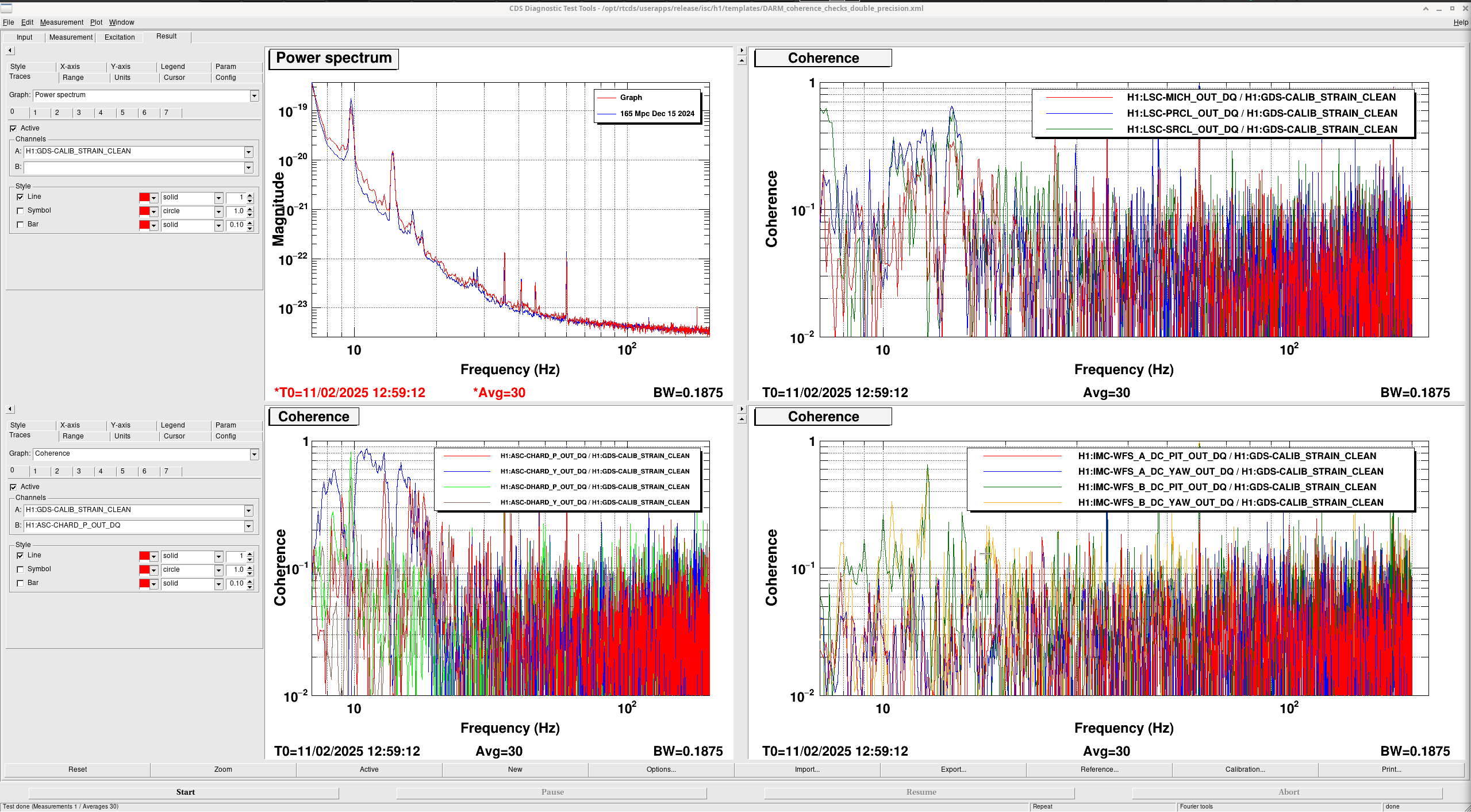
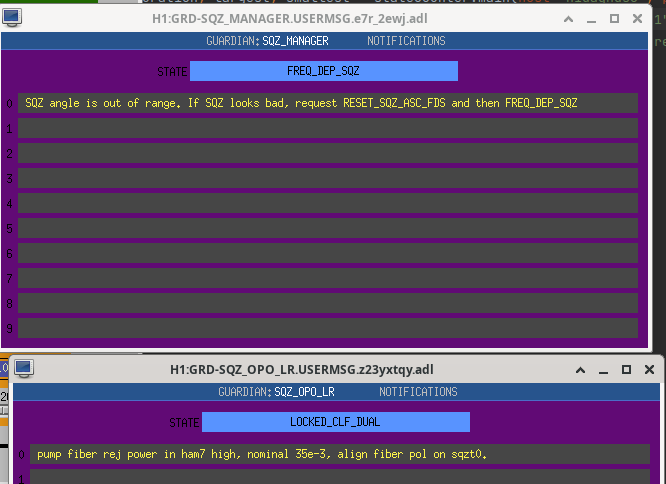
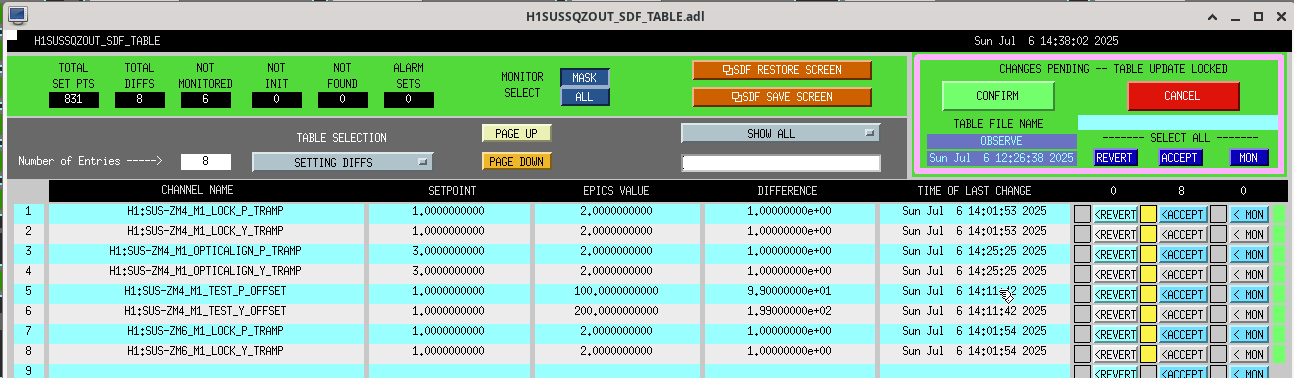
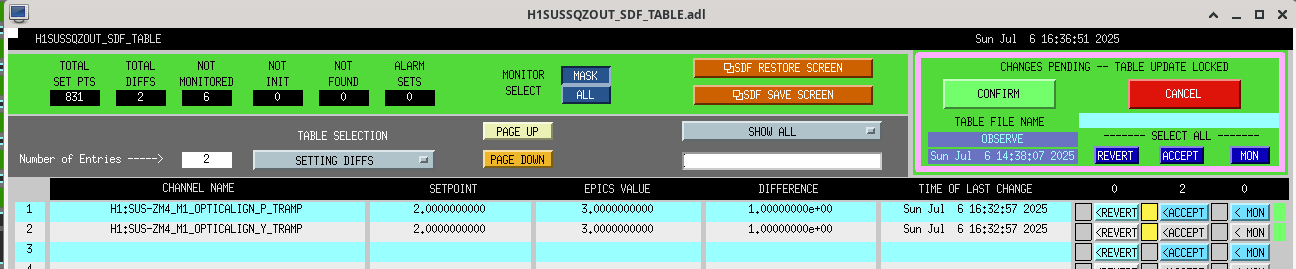


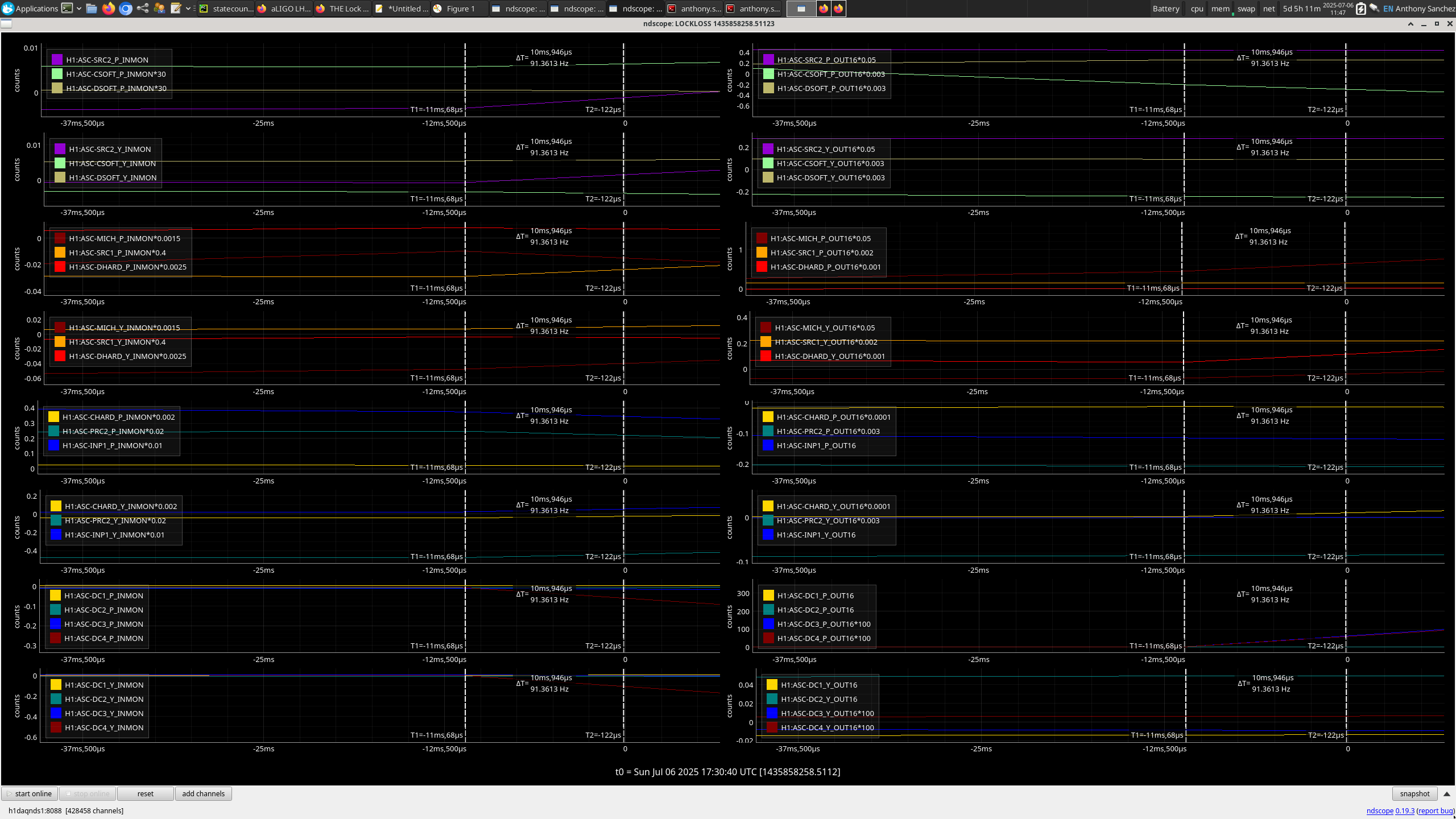
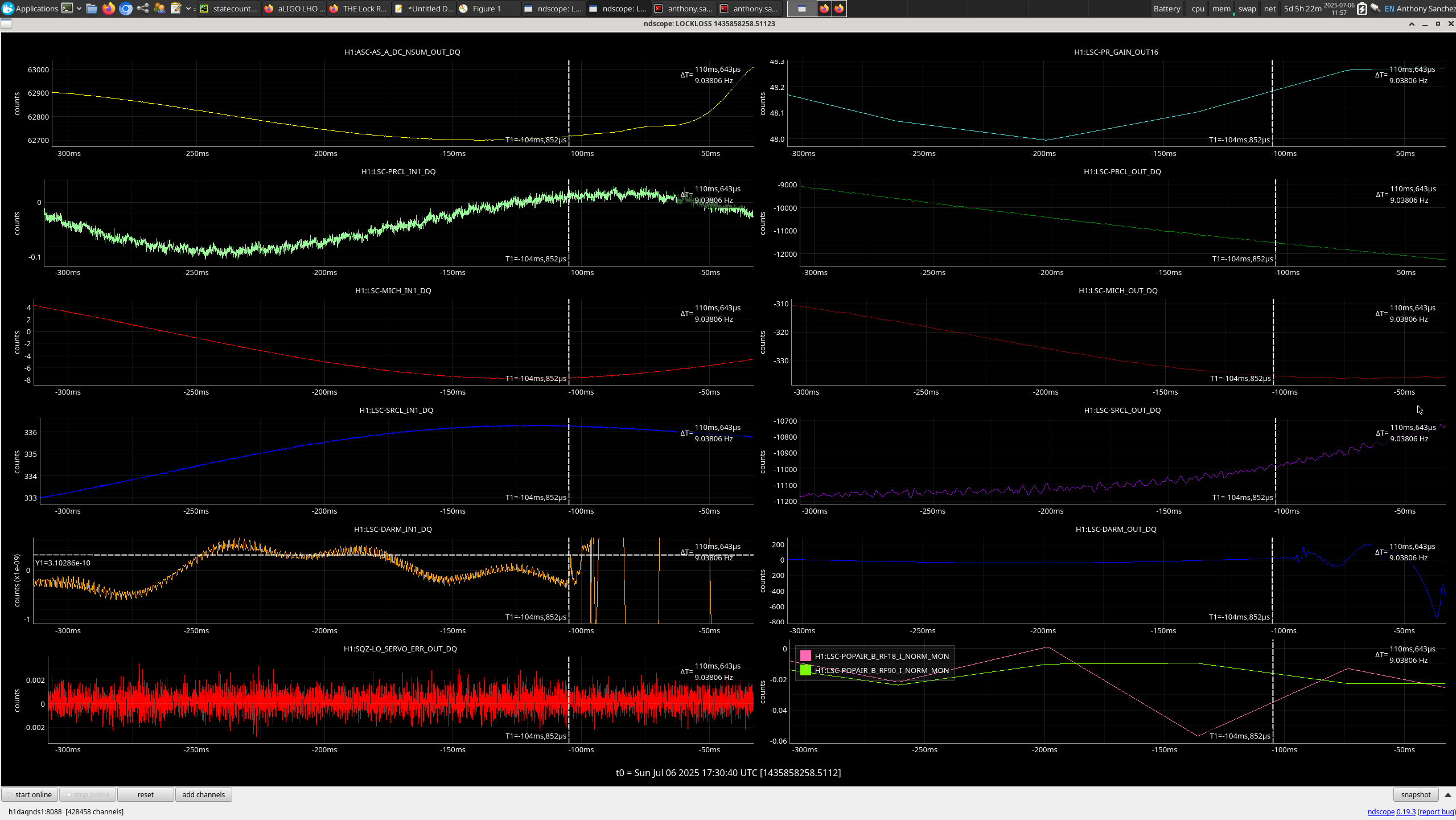
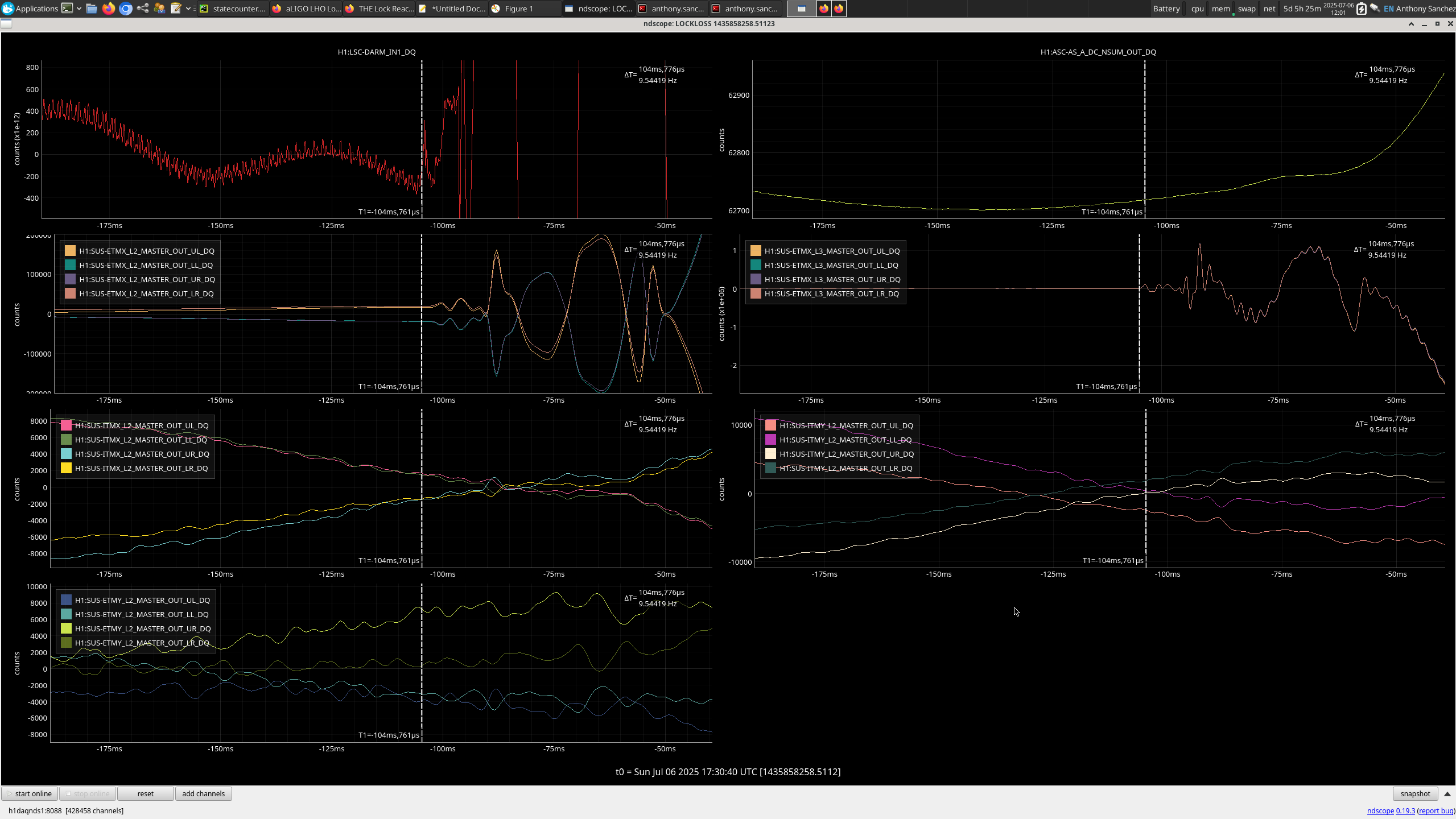

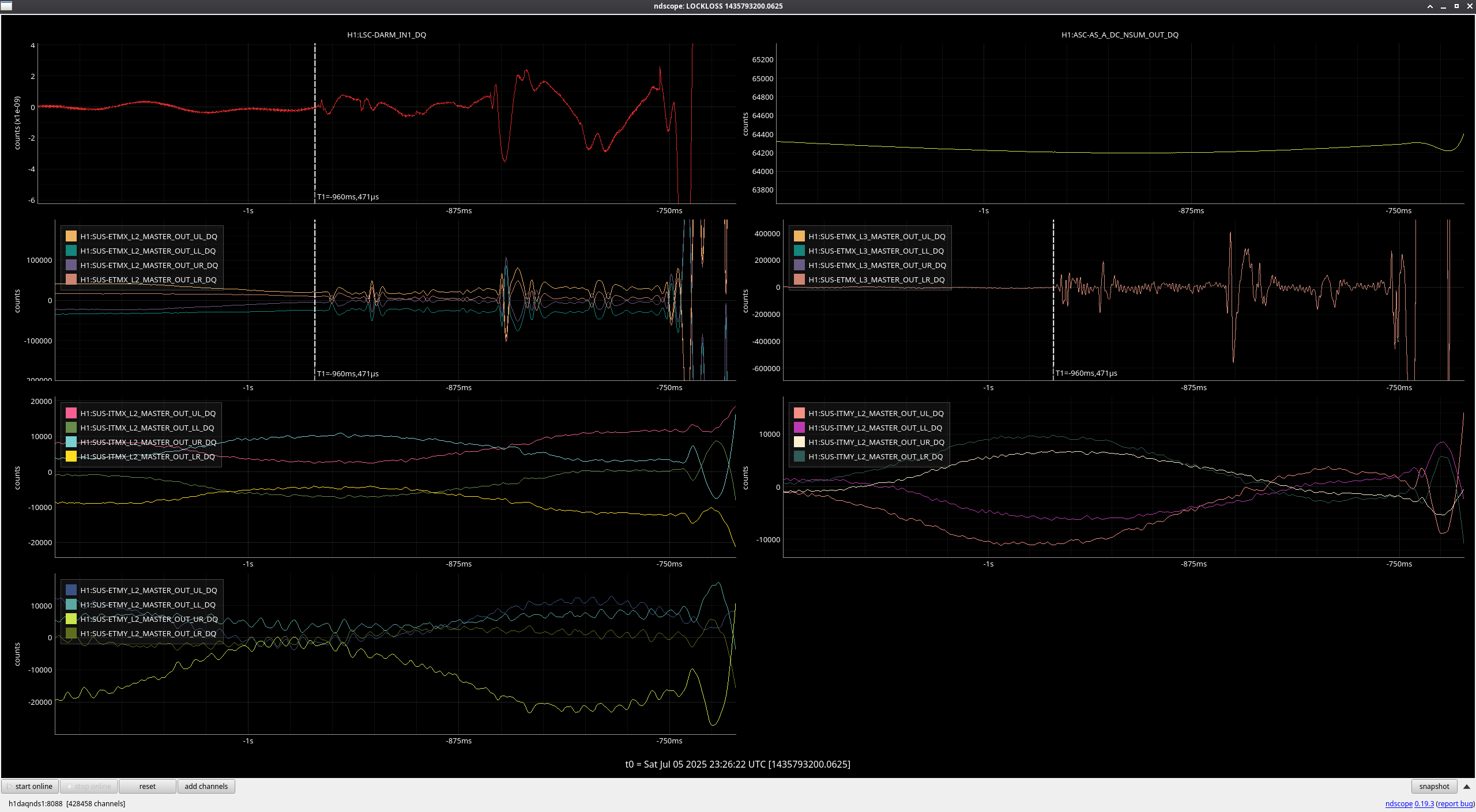

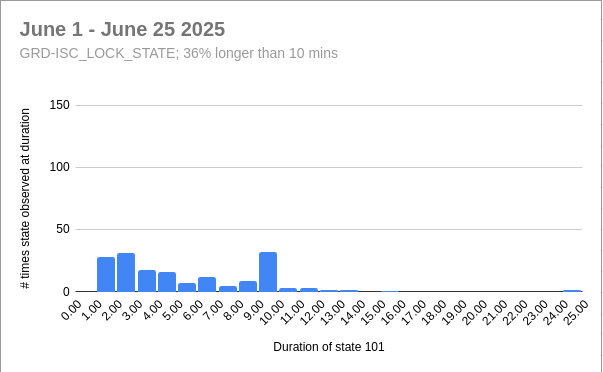
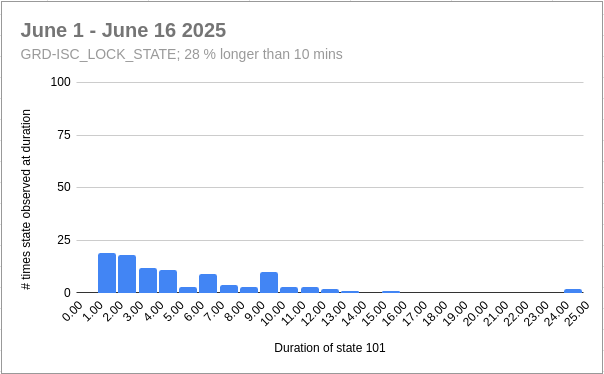
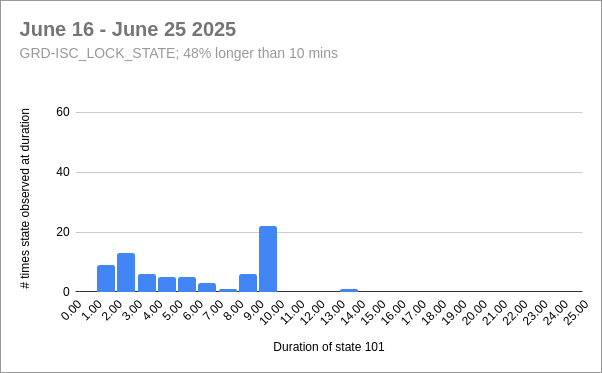
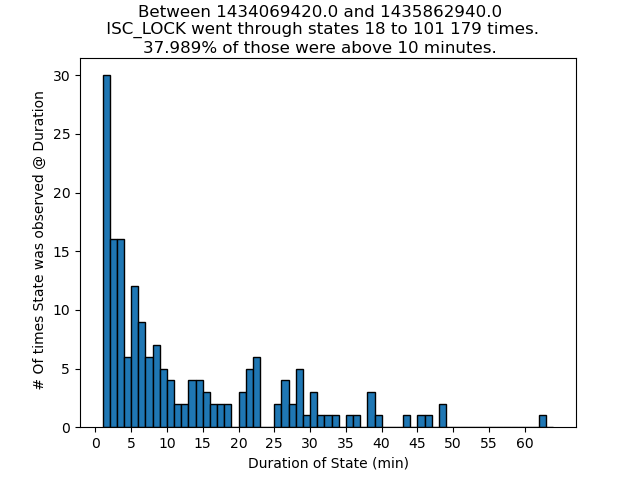
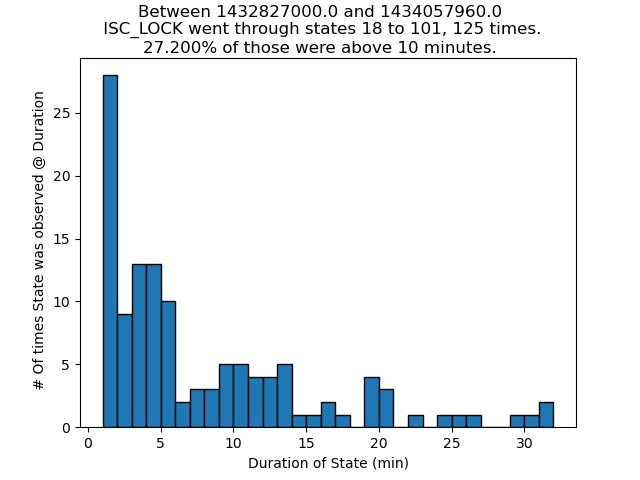
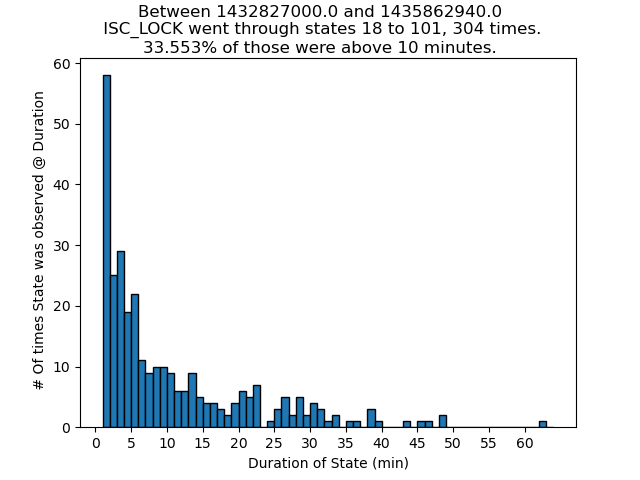
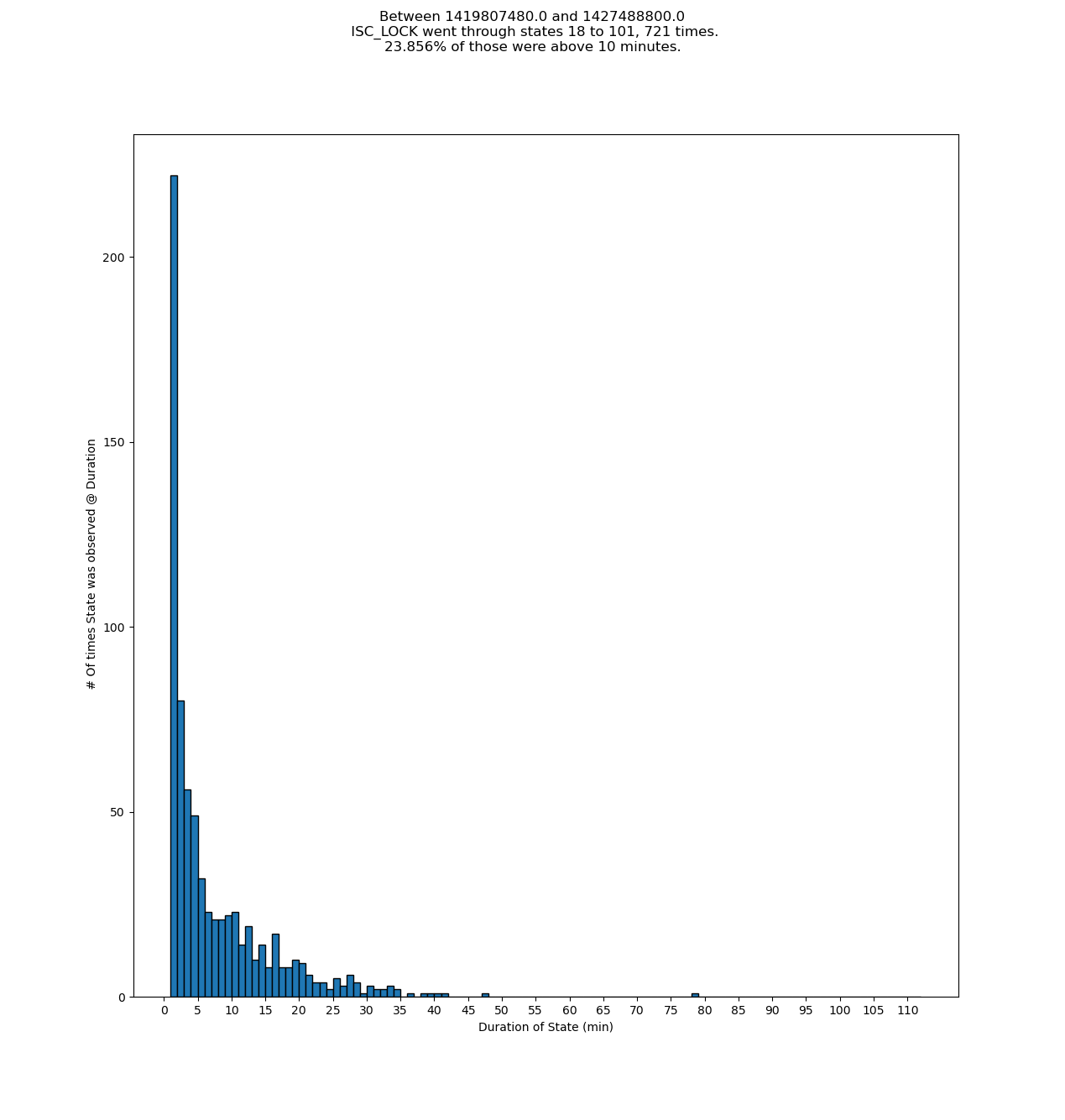
13:52 UTC lockloss at POWER_25Ws from a 6.3 from New Zealand, holding in DOWN