jeffrey.bartlett@LIGO.ORG - posted 12:46, Friday 16 June 2017 (36942)
Ops Day Mid-Shift Summary
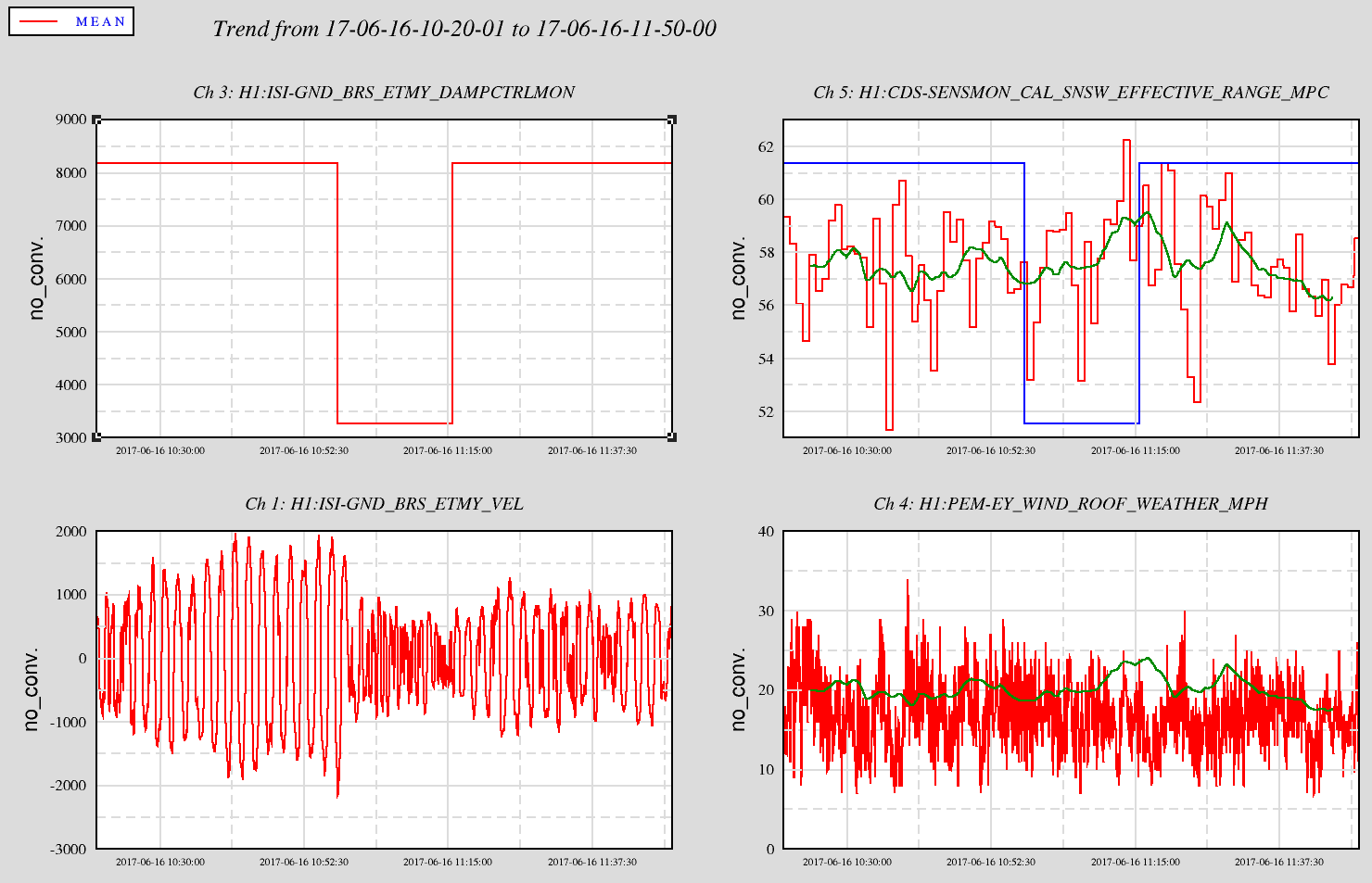
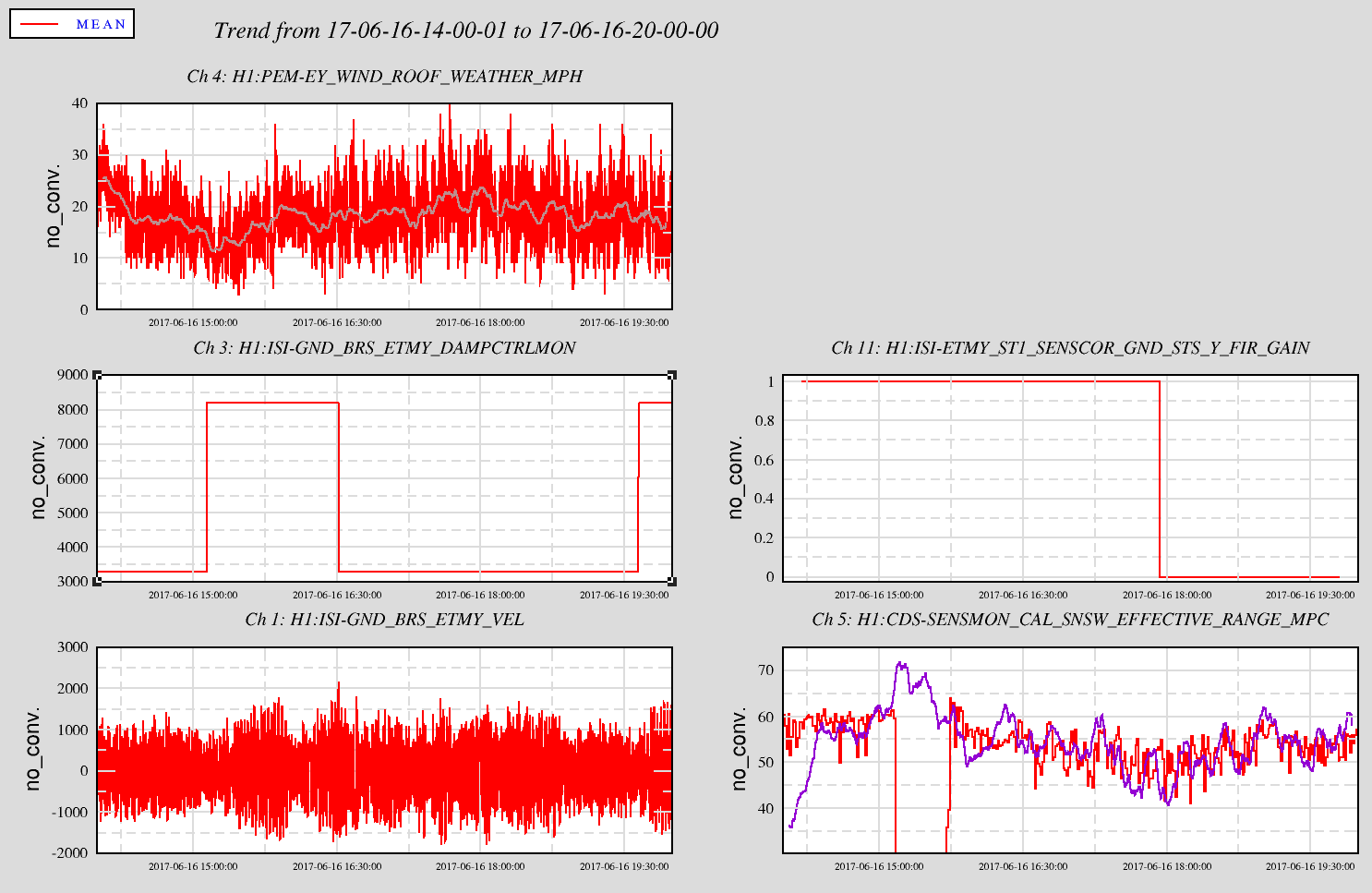
With strong and gusty winds the environmental conditions have not been favorable this morning. There were some glitching issues with the RF45 Mod Depth Stab Contls, which did not help. The range has mostly been in the low to mid 50Mpcs. BRS-Y has been in DAMPING all morning. Sheila switched the SEI_CONFIG state from WINDY to WINDY_NO_BRSY. After switching did not see an improvement in range. There was commissioning work between 15:30 (08:30) and 16:30 (09:30)this morning. The IFO has been in Observing mode after the commissioning work ended.


{kind=link}
{kind=link}