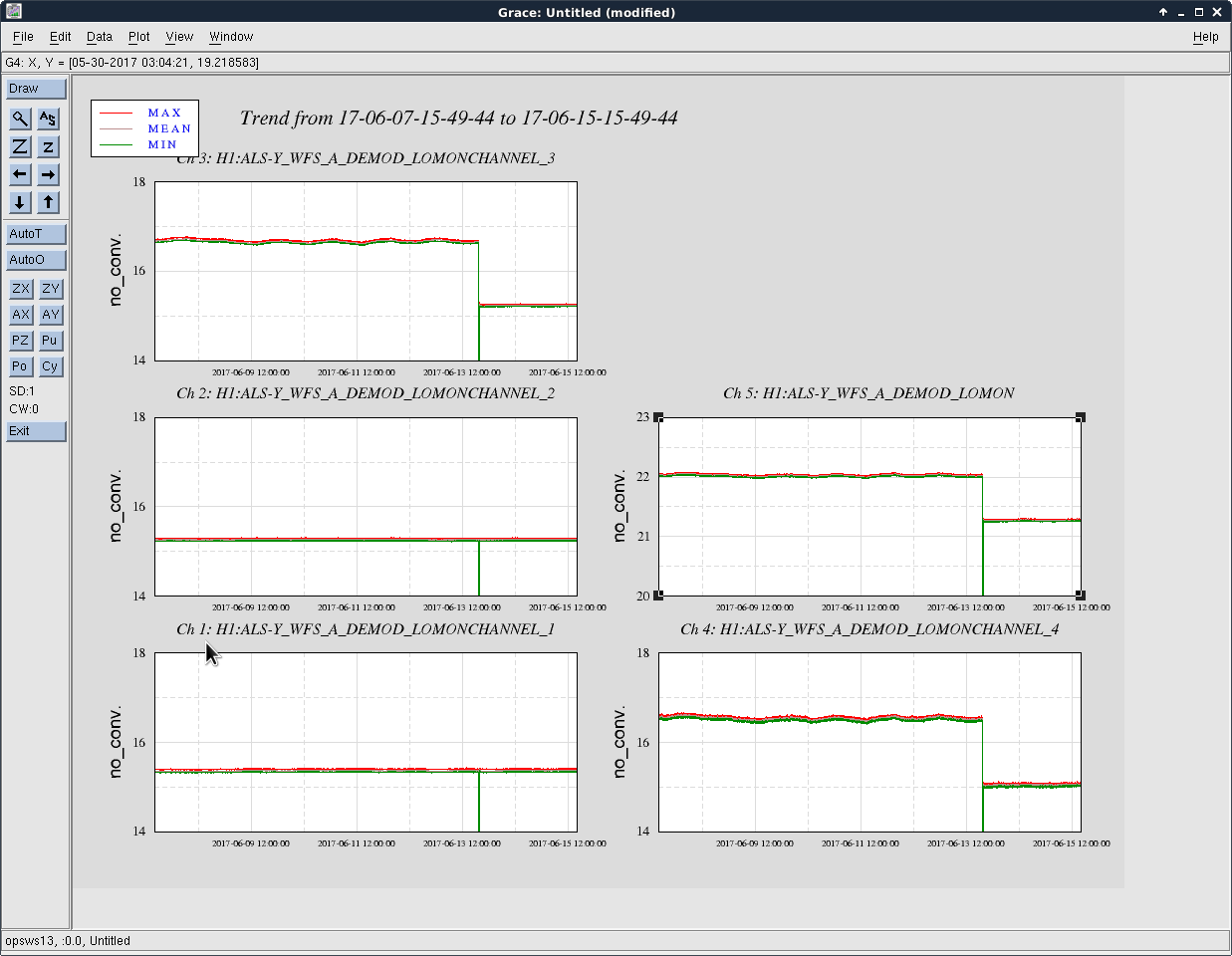
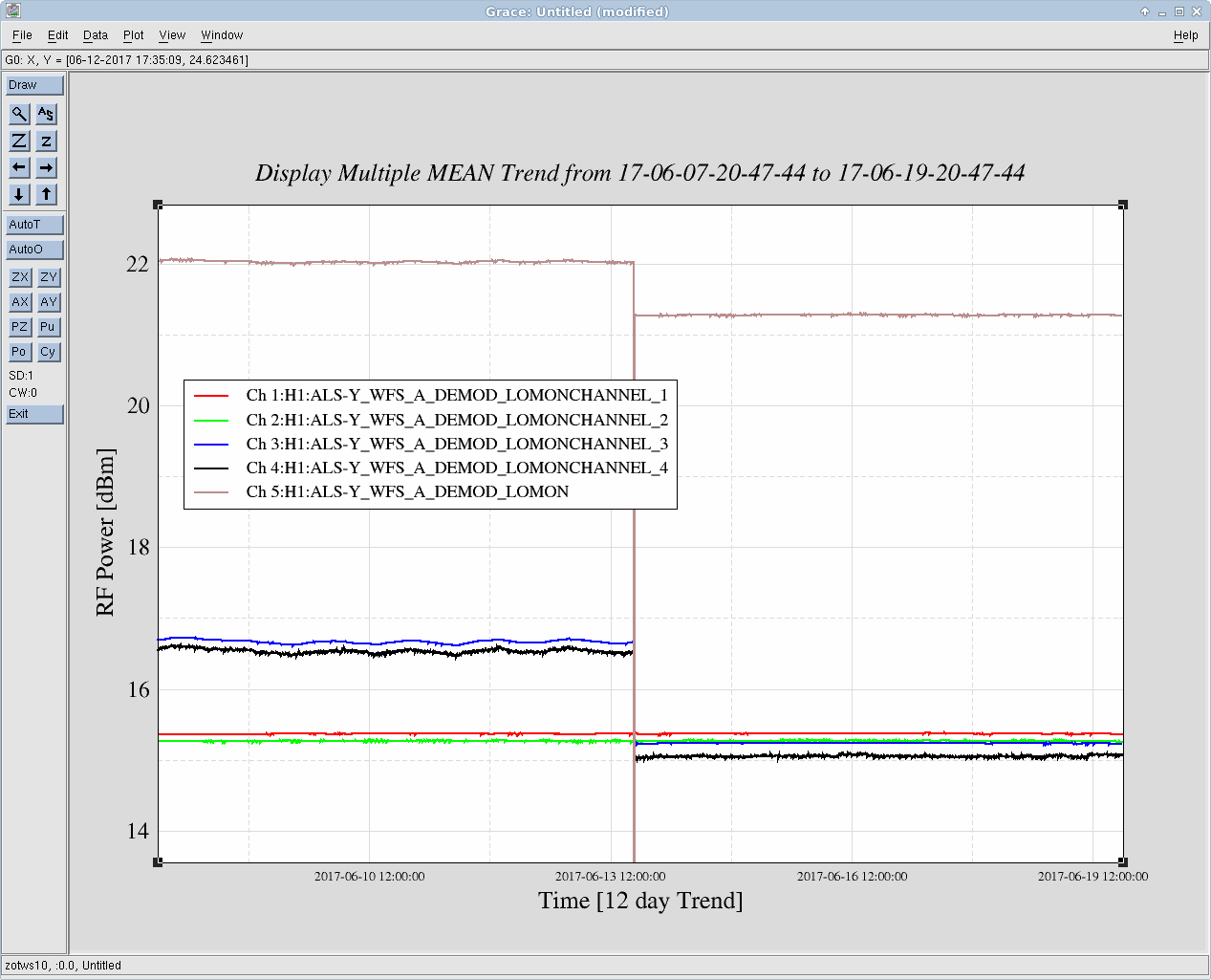
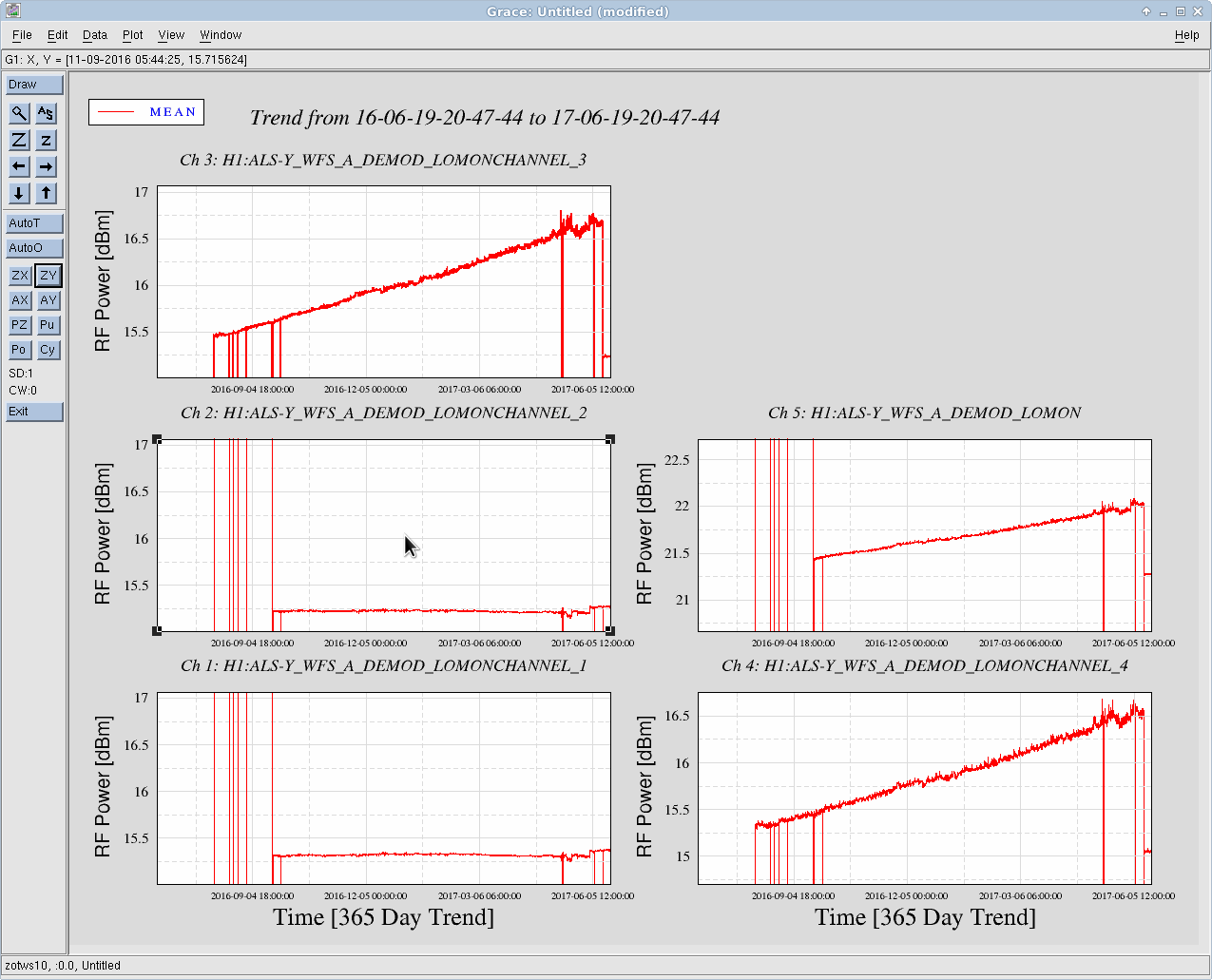
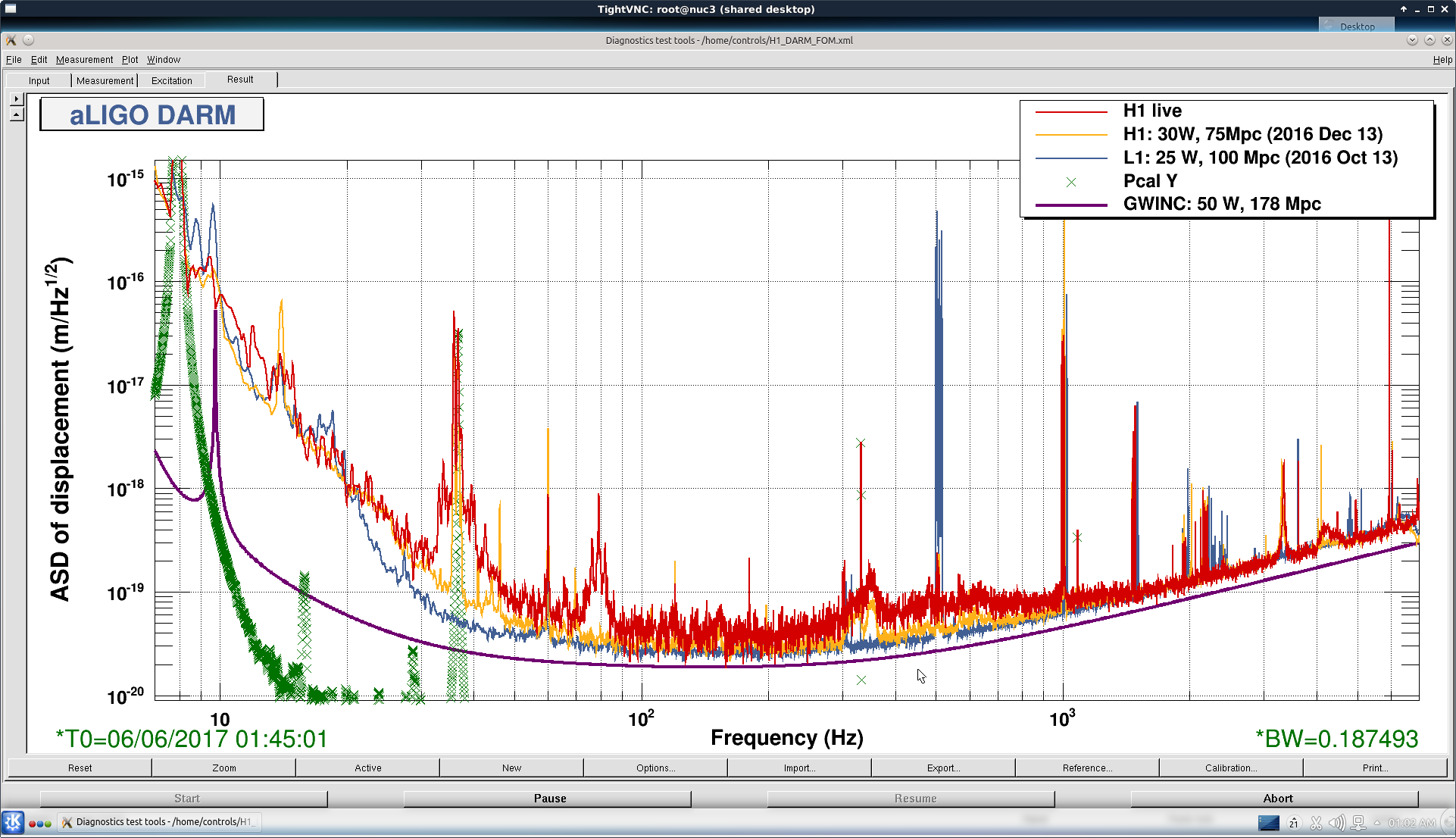
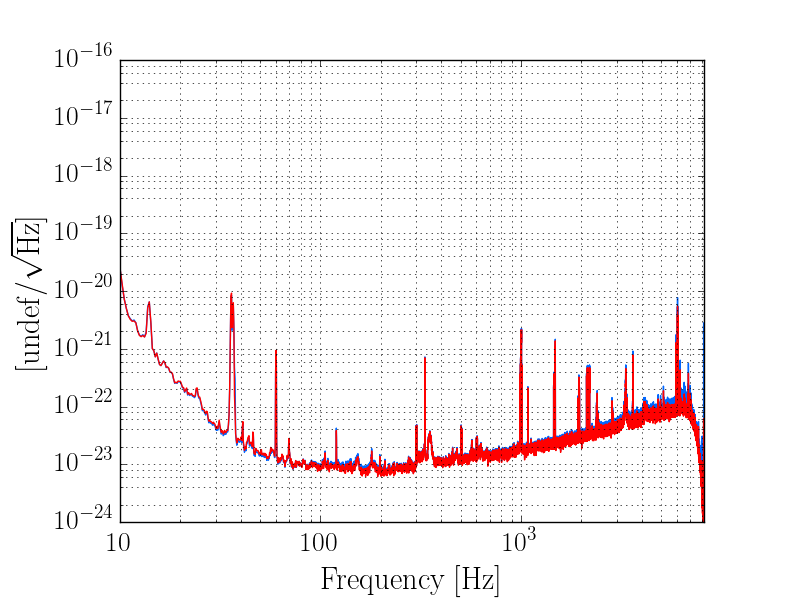
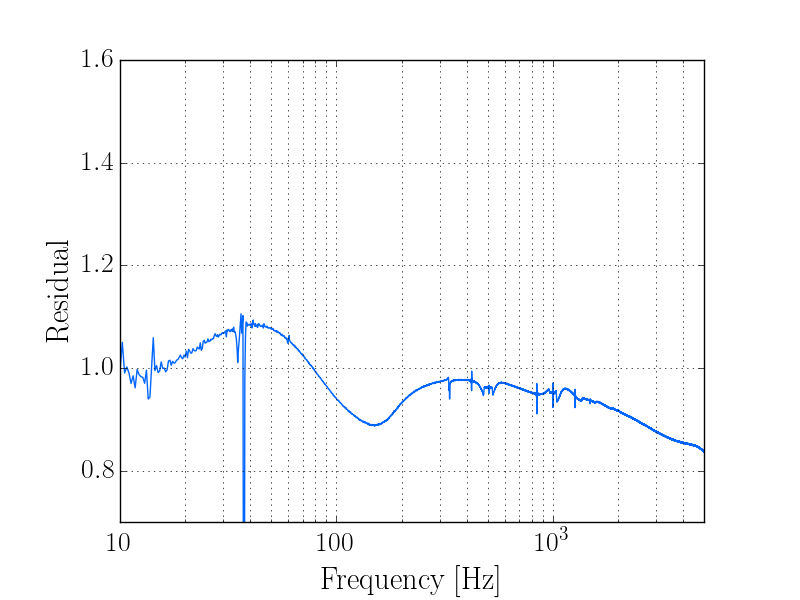
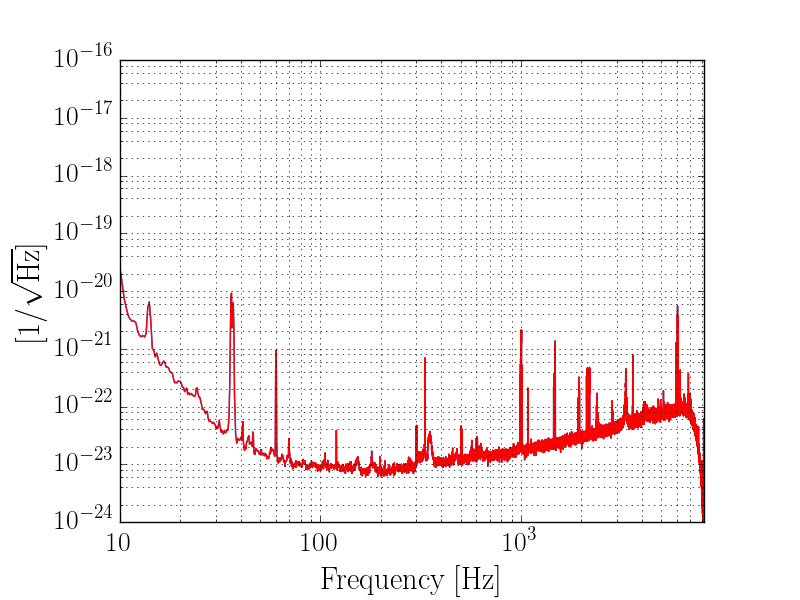
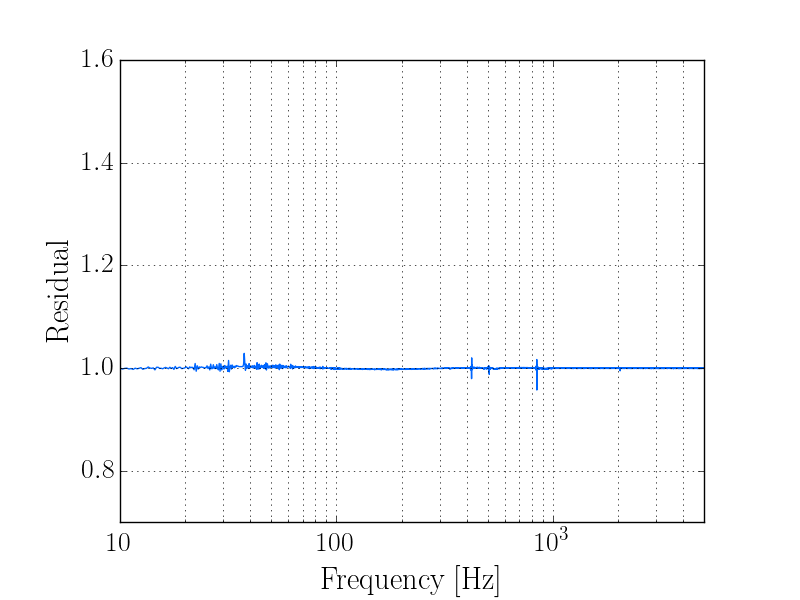
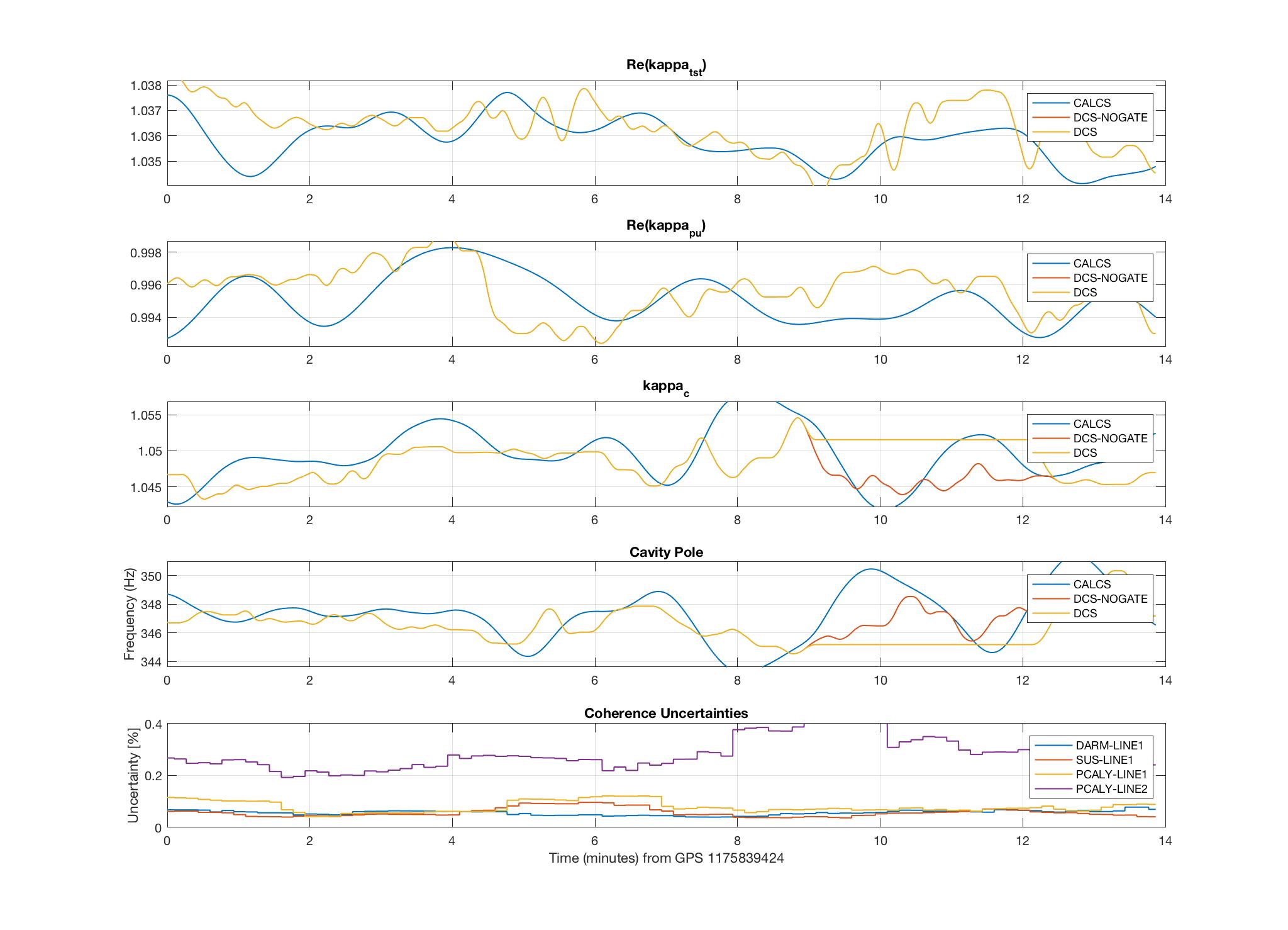
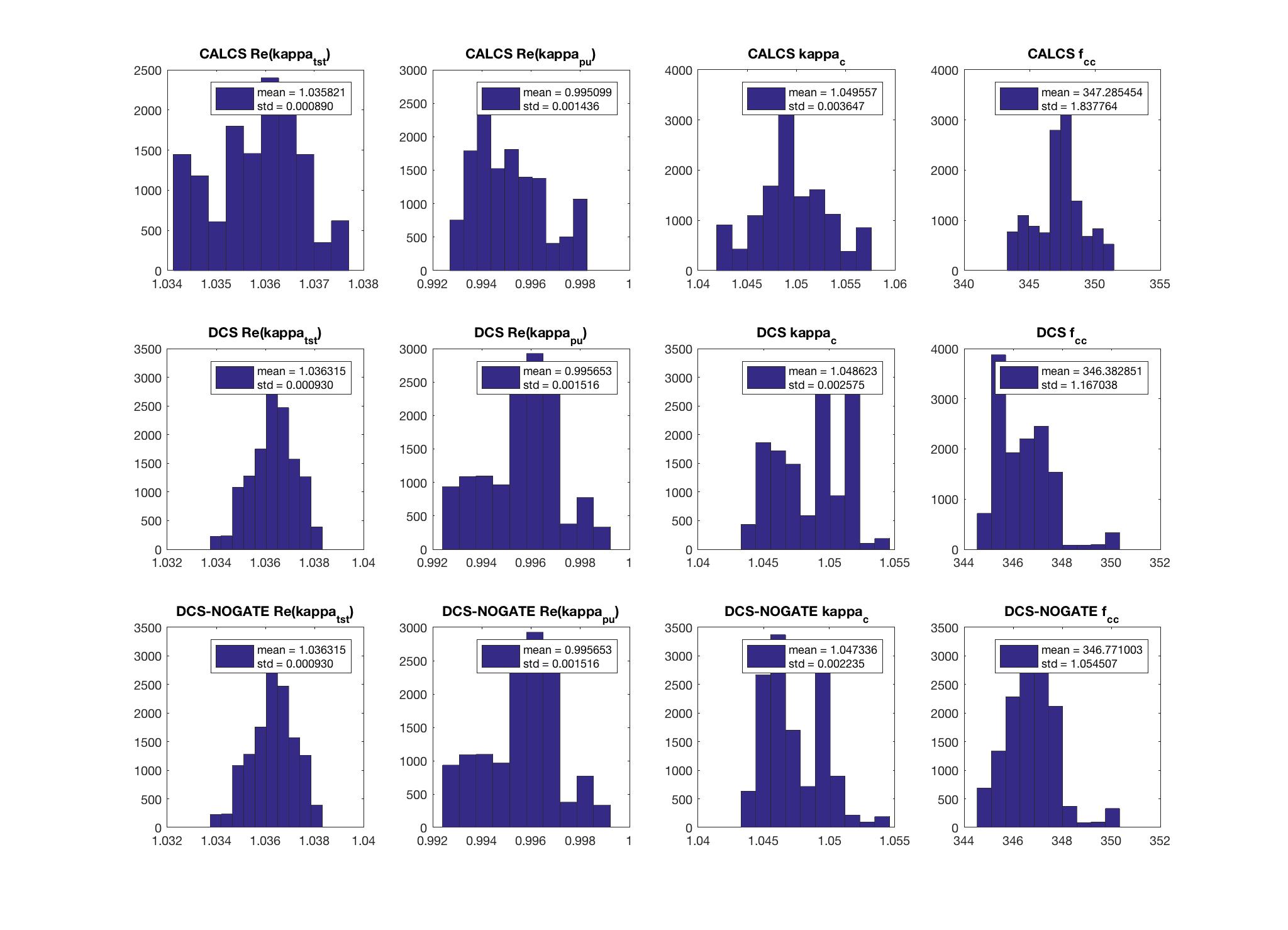
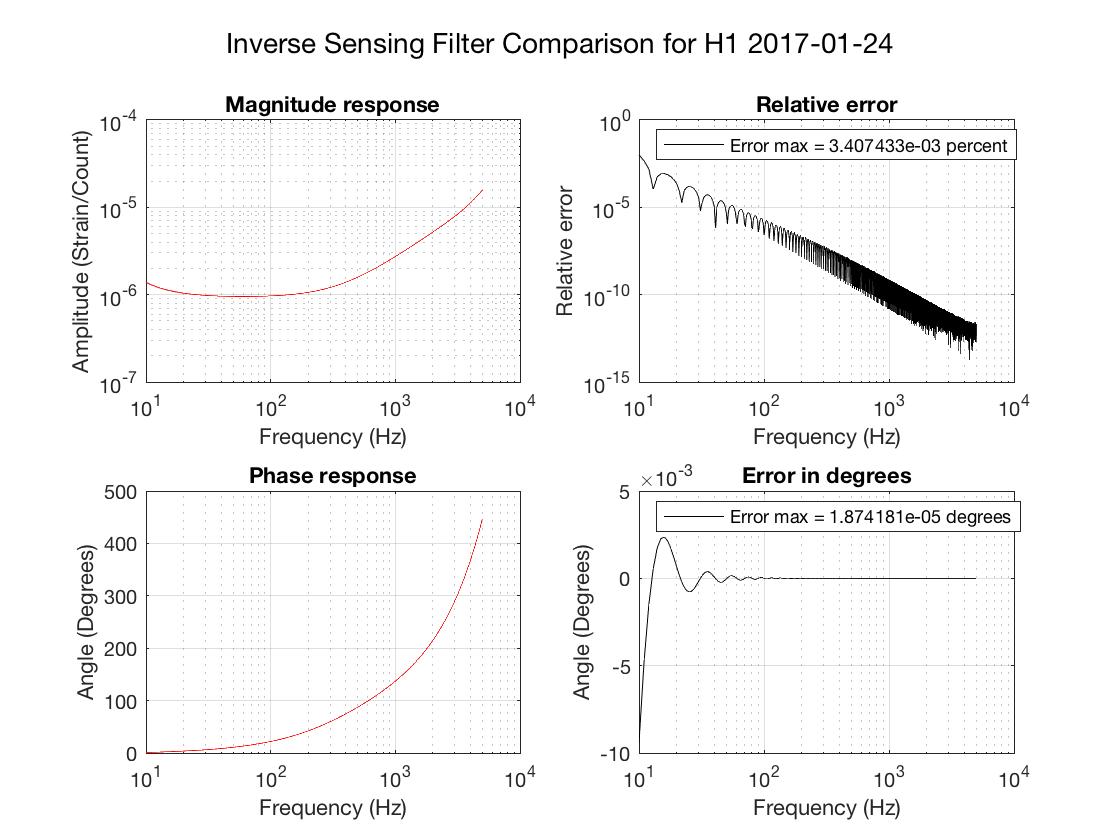
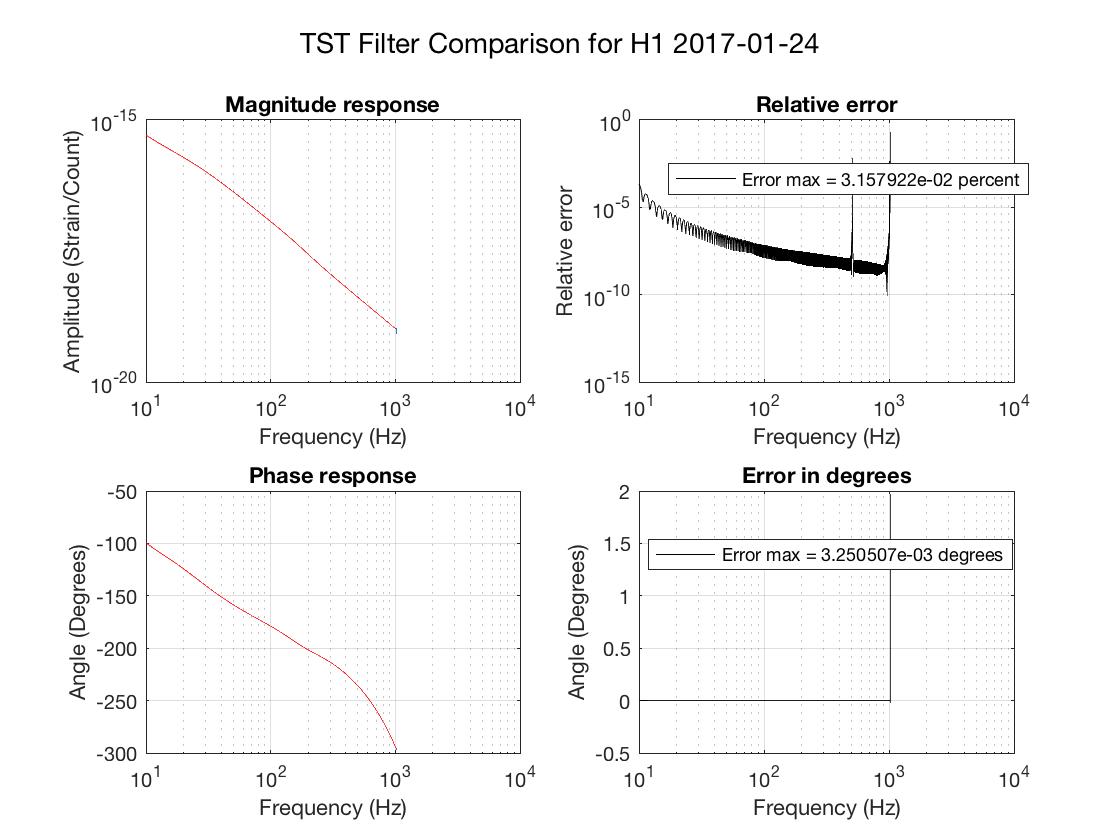
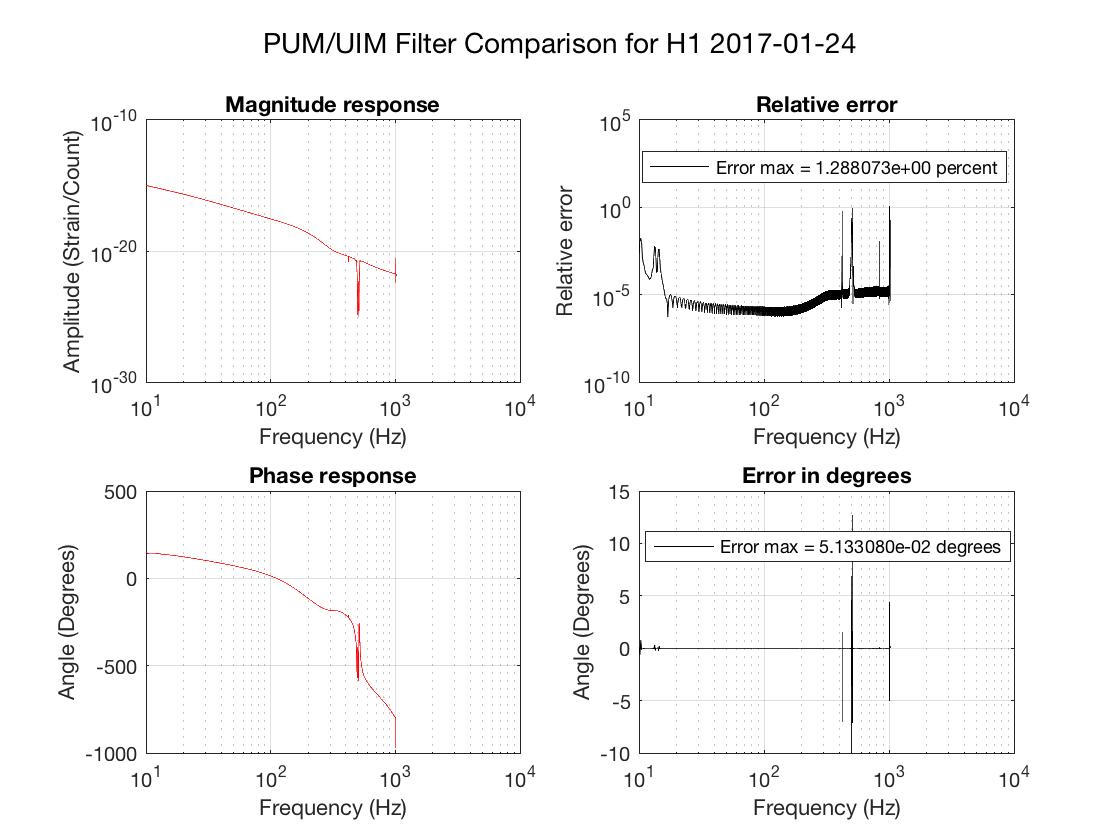
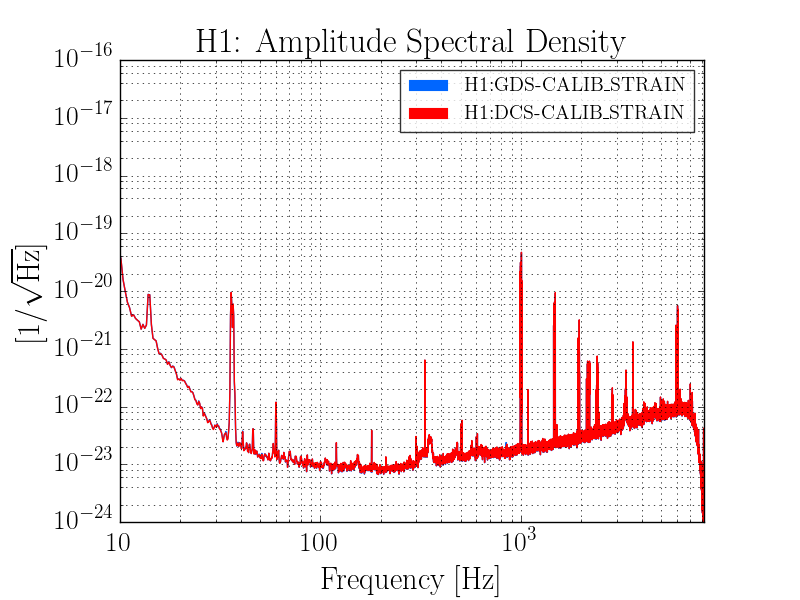
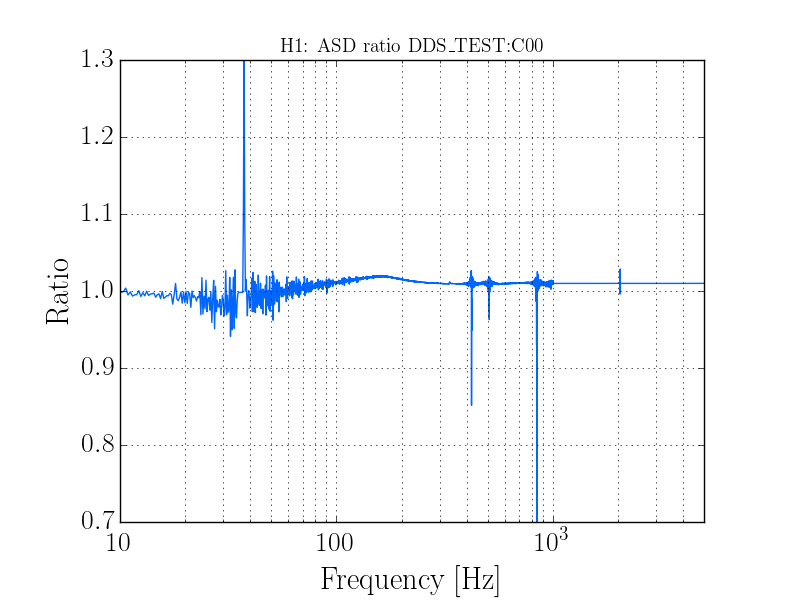
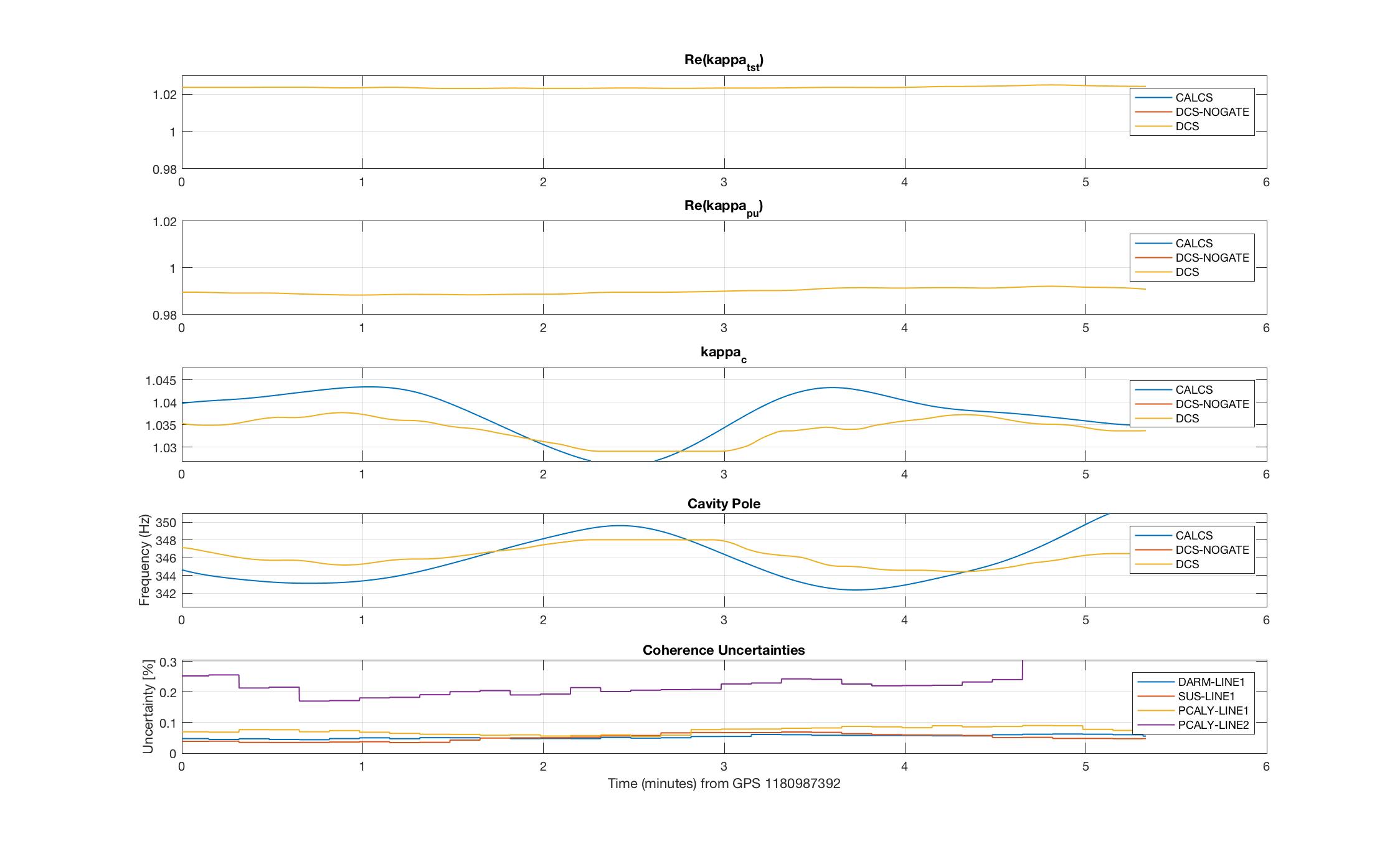
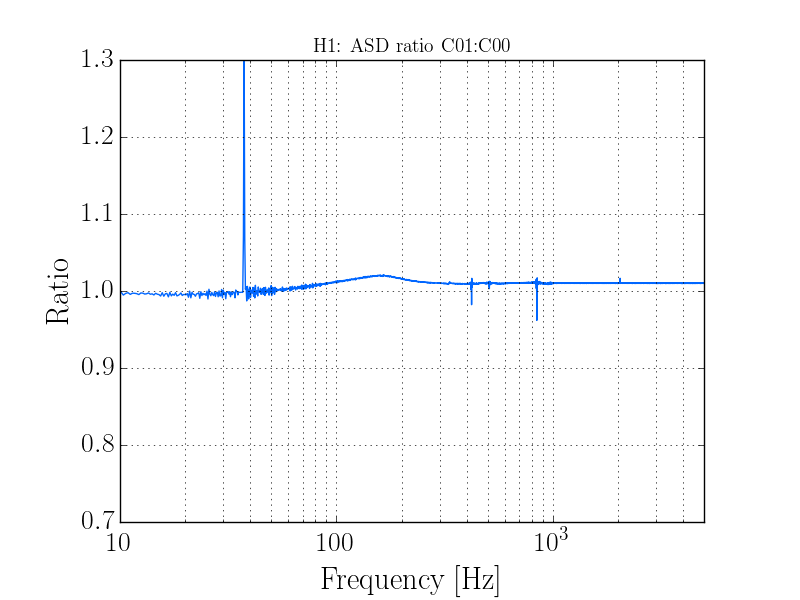
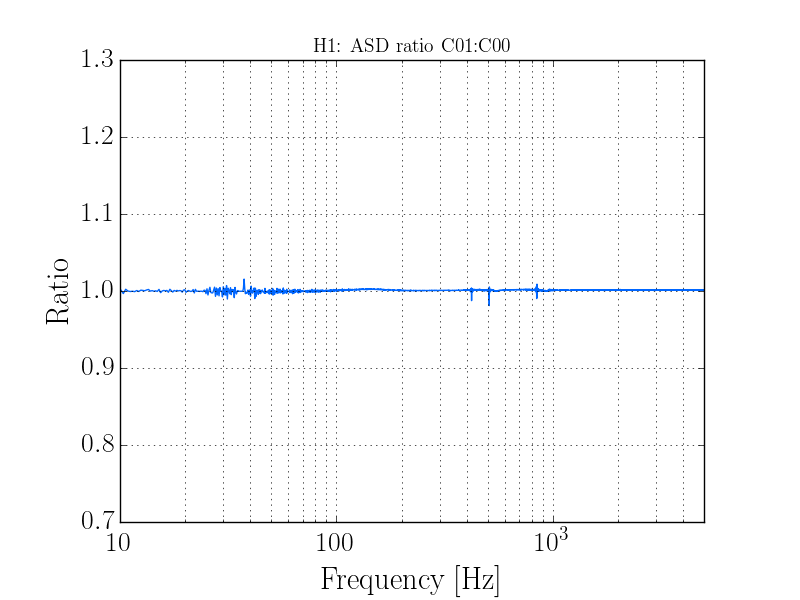
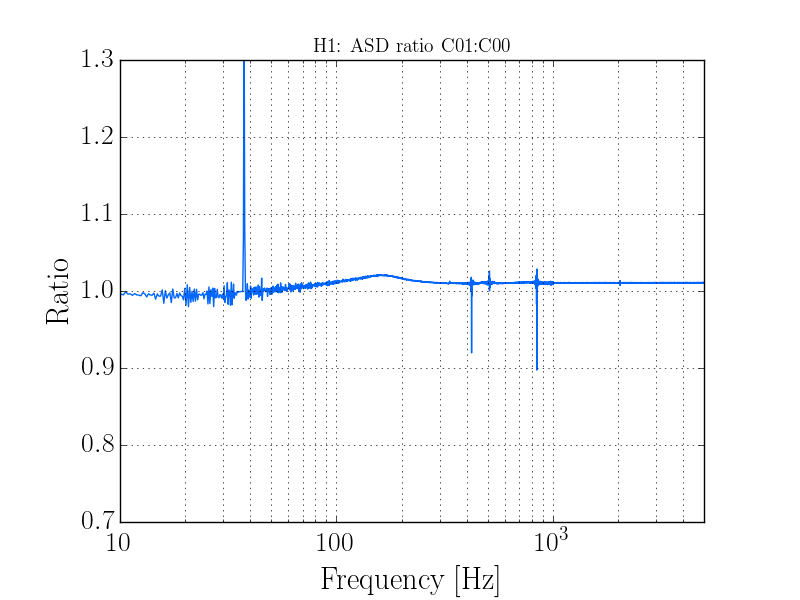
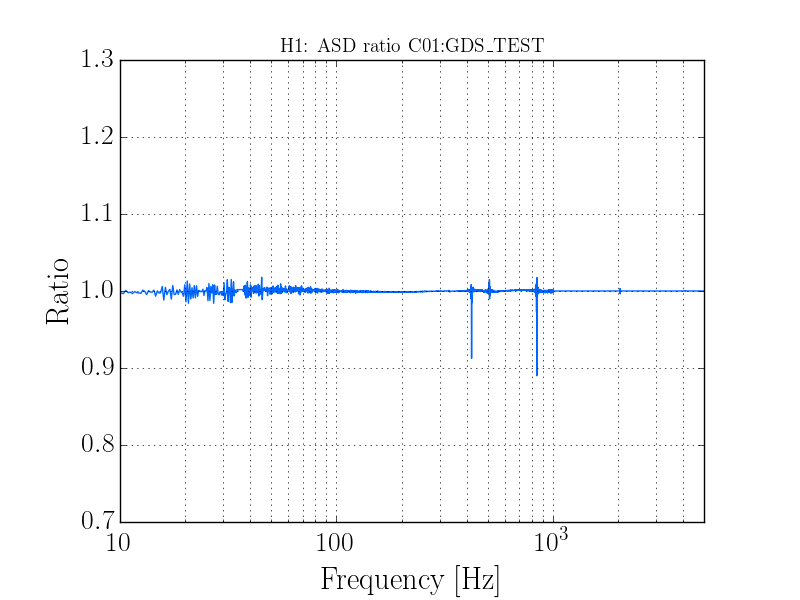
thomas.shaffer@LIGO.ORG - posted 16:04, Tuesday 13 June 2017 (36858)
Ops Eve Shift Transition
TITLE: 06/13 Eve Shift: 23:00-07:00 UTC (16:00-00:00 PST), all times posted in UTC
STATE of H1: Commissioning
OUTGOING OPERATOR: Travis
CURRENT ENVIRONMENT:
Wind: 22mph Gusts, 17mph 5min avg
Primary useism: 0.10 μm/s
Secondary useism: 0.10 μm/s
QUICK SUMMARY: Maintenance/commissioning activies are continueing. Travis got it back up as he handed it off, now I just have to watch PI modes.