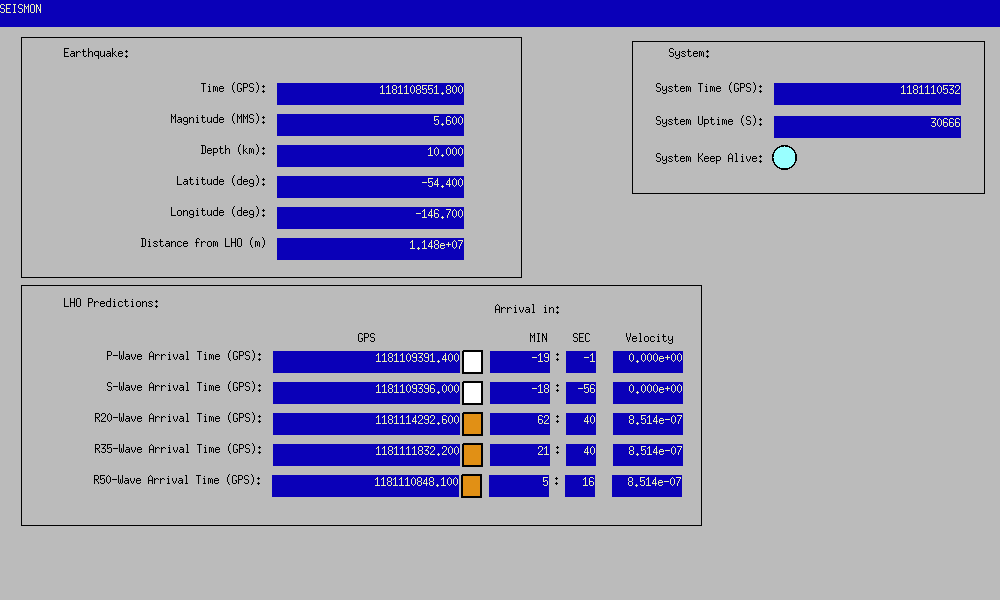
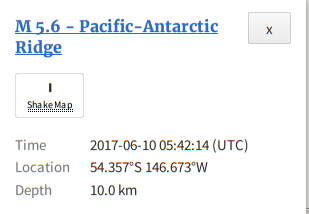
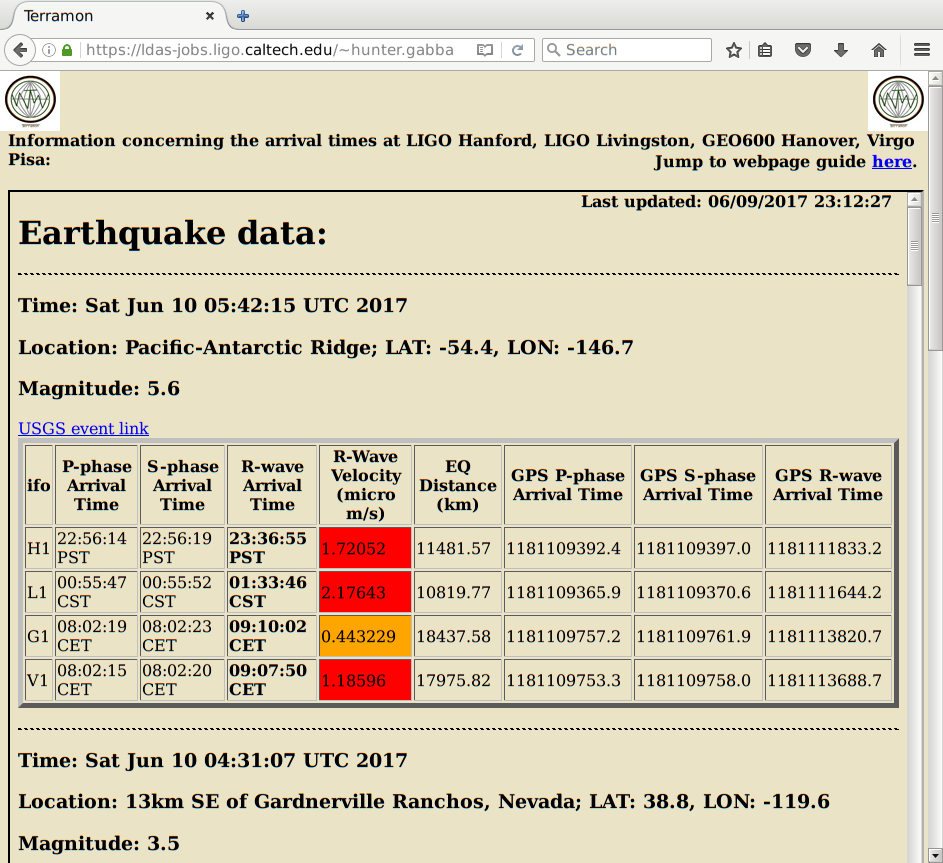
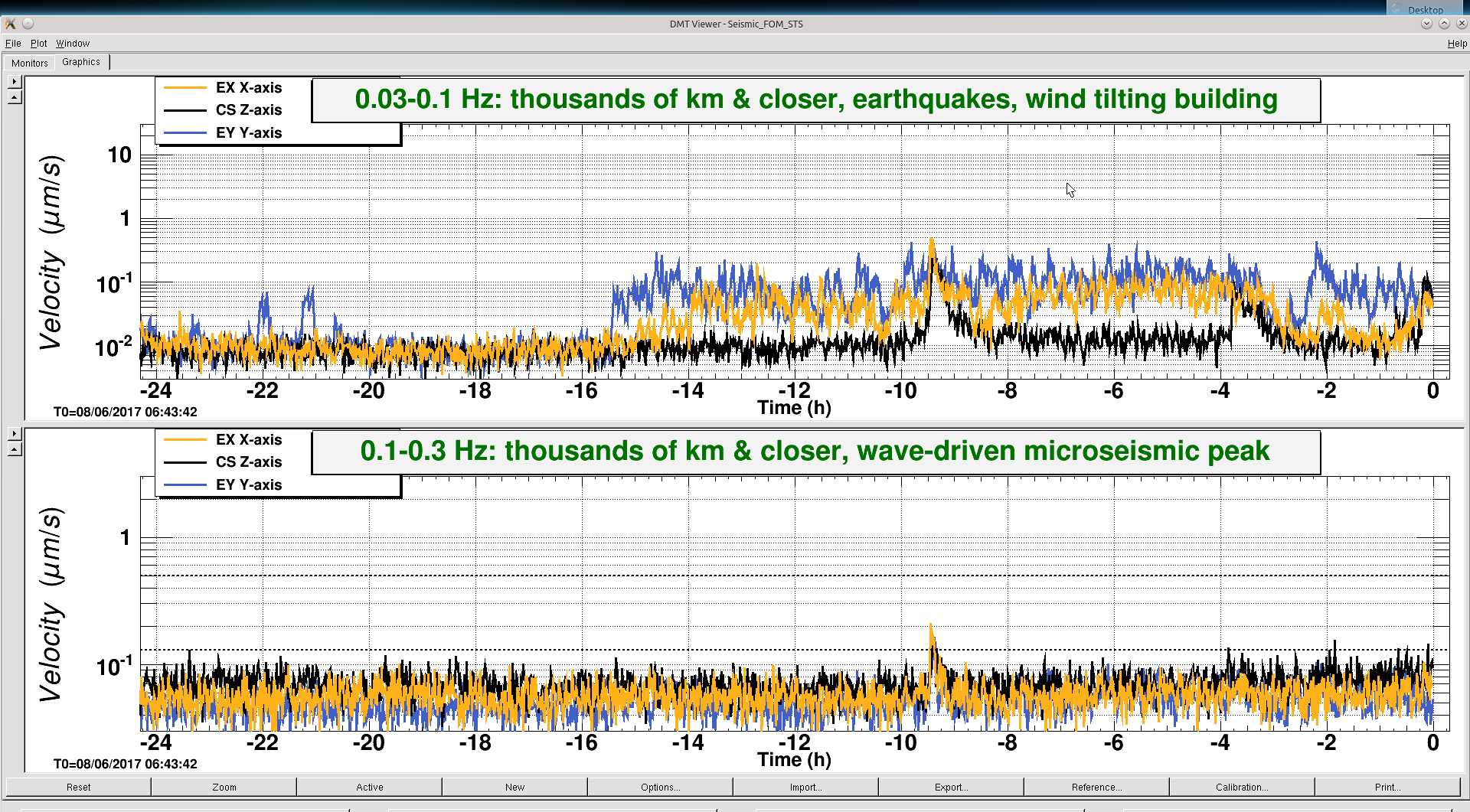
travis.sadecki@LIGO.ORG - posted 15:01, Saturday 10 June 2017 - last comment - 15:11, Saturday 10 June 2017(36777)
Out of Observing 21:59-22:00 UTC
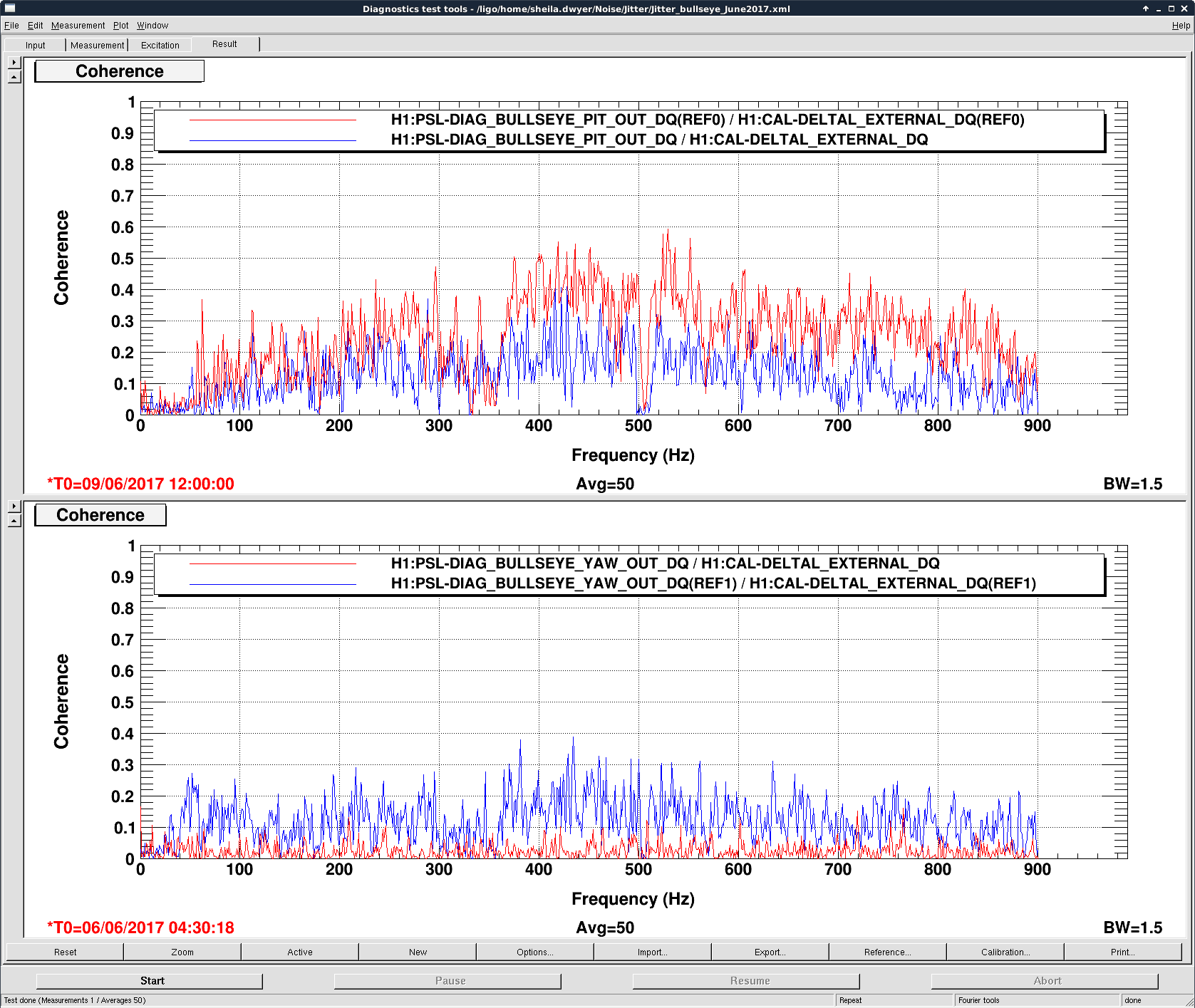
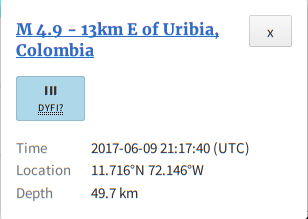
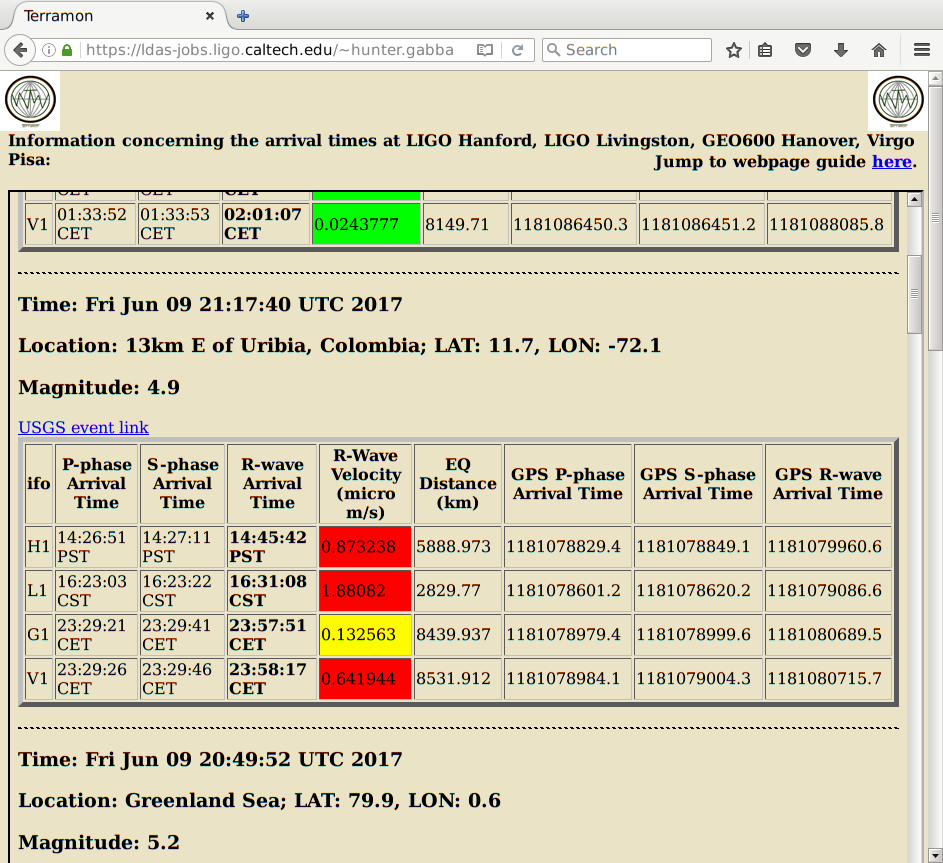
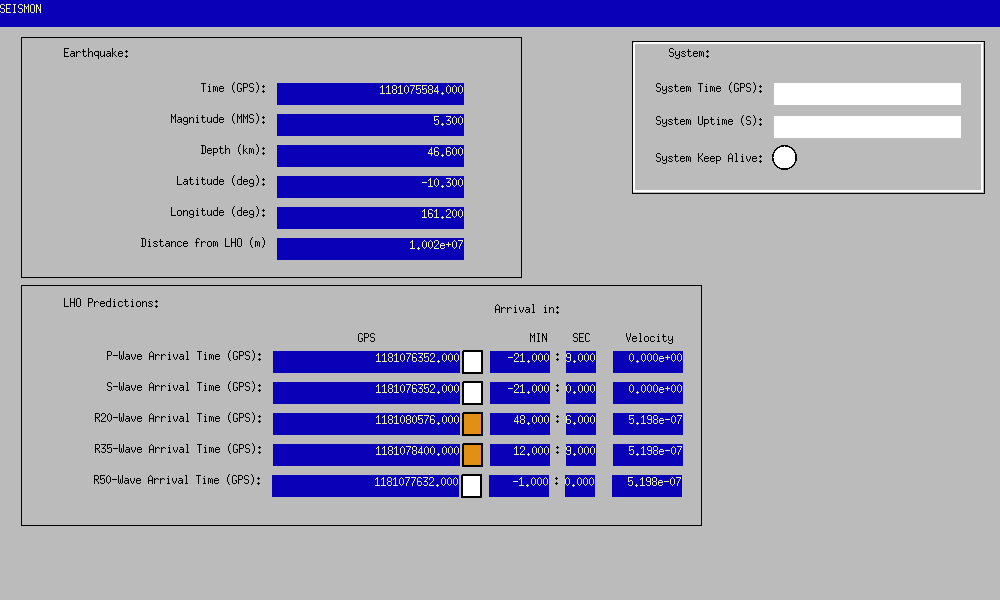
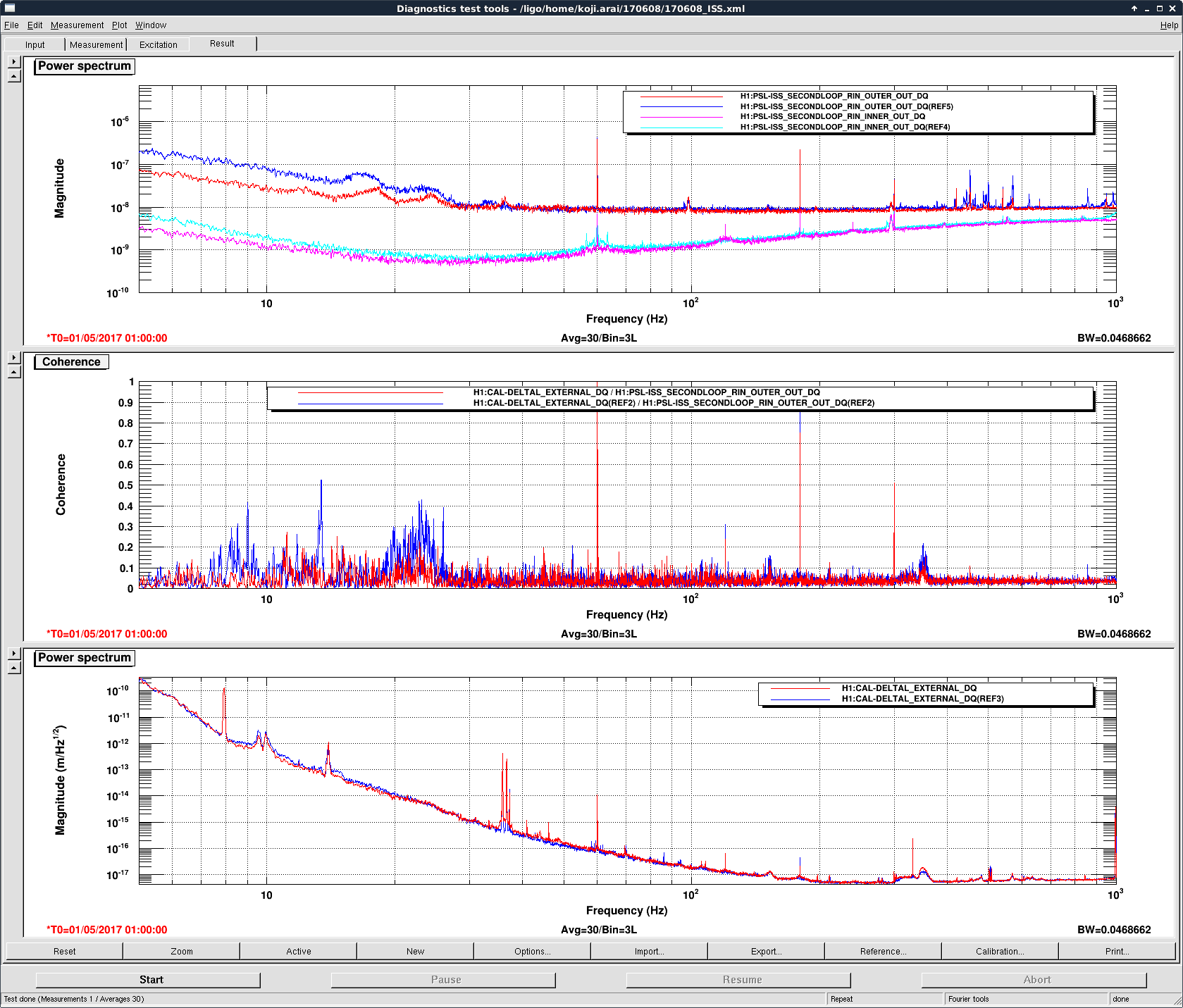
TCS_ITMX_CO2 caused us to drop out of Observing for ~1 minute due to the laser losing lock.
{kind=link}
And again from 22:08-22:11 UTC.