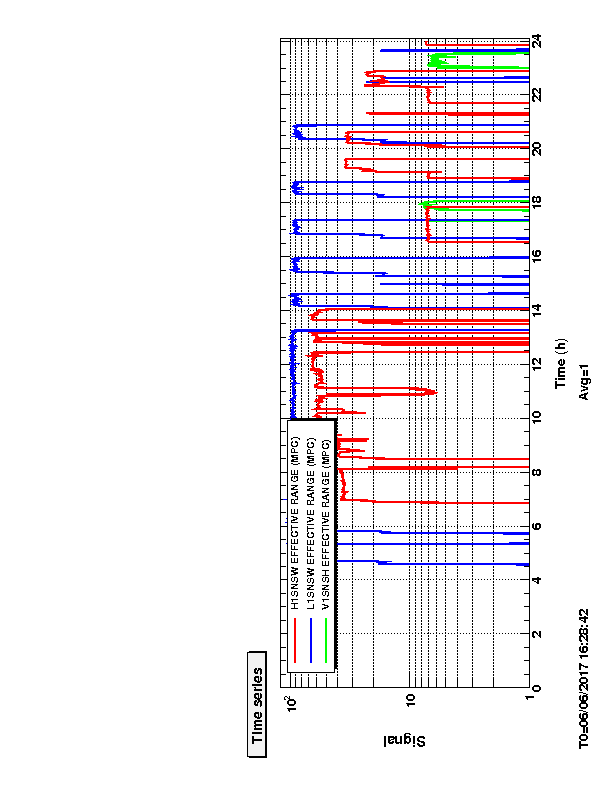
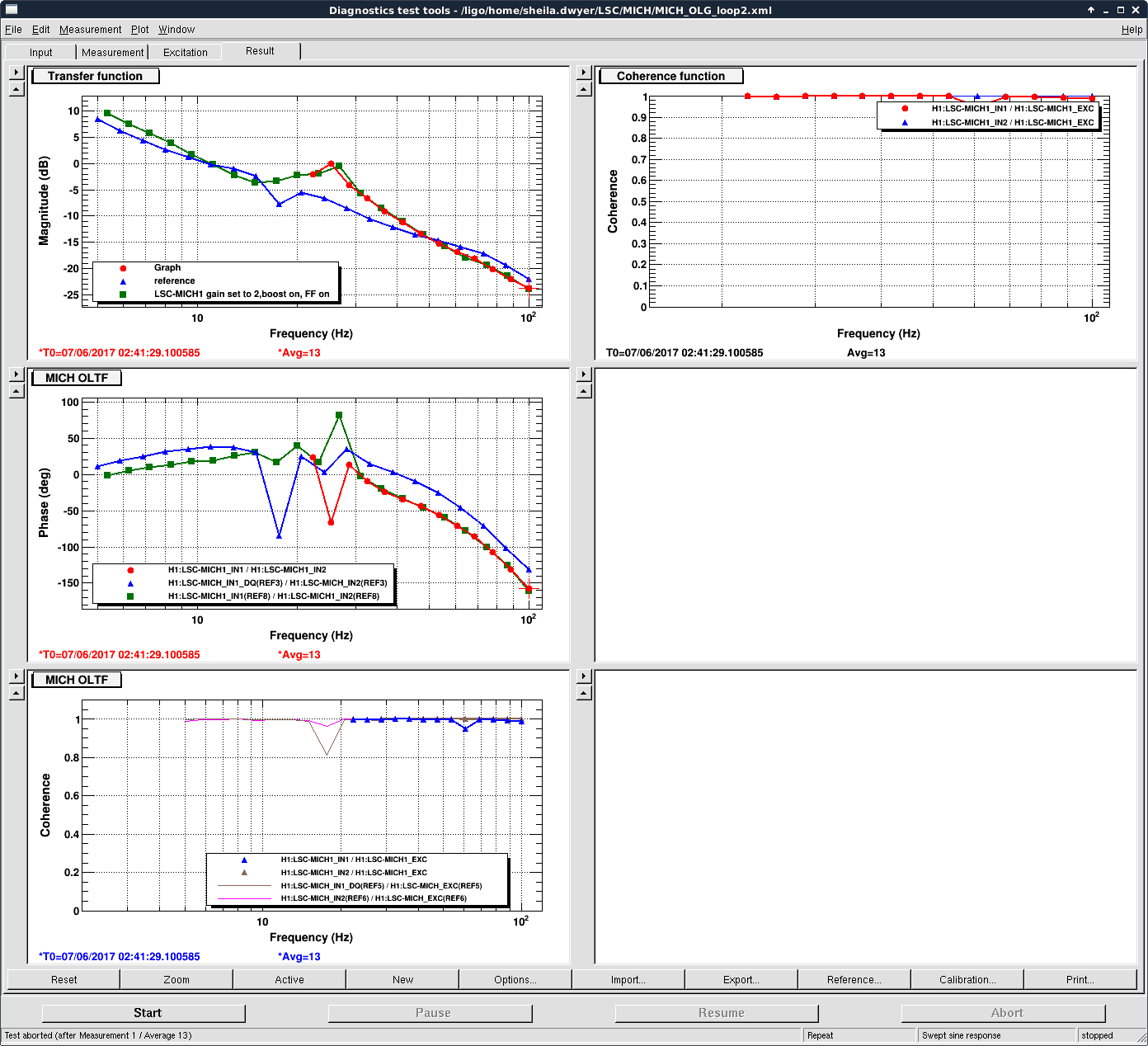
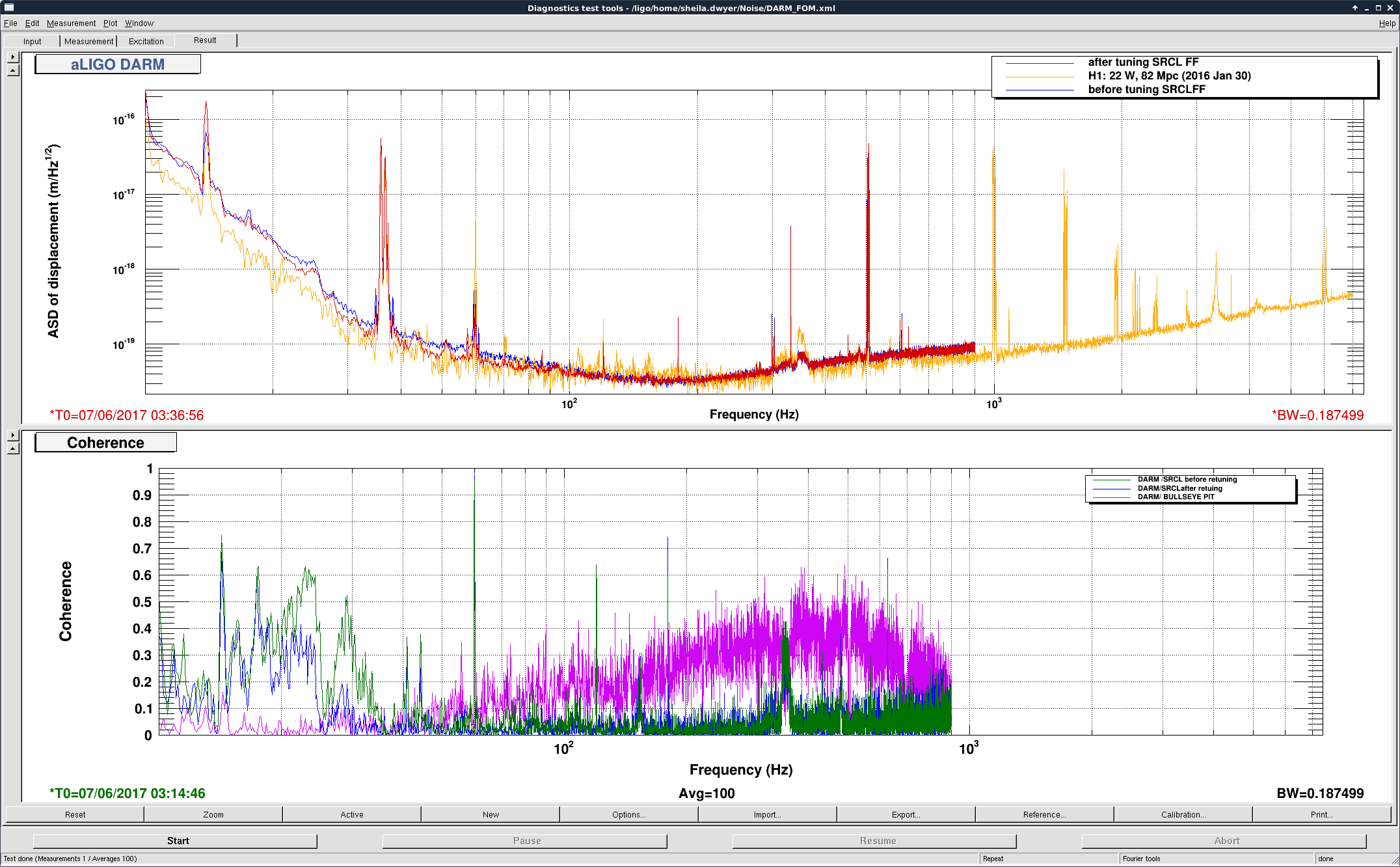
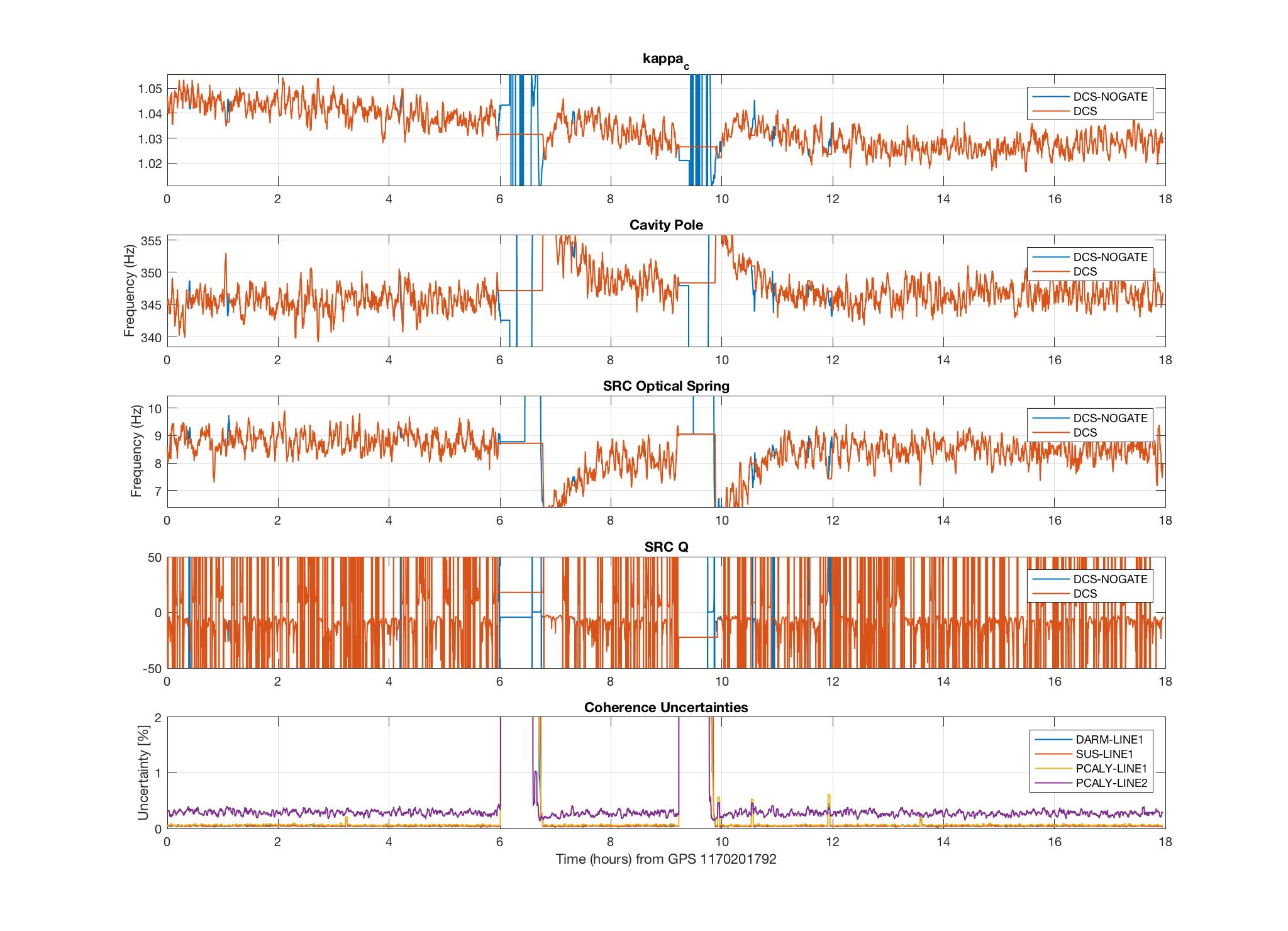
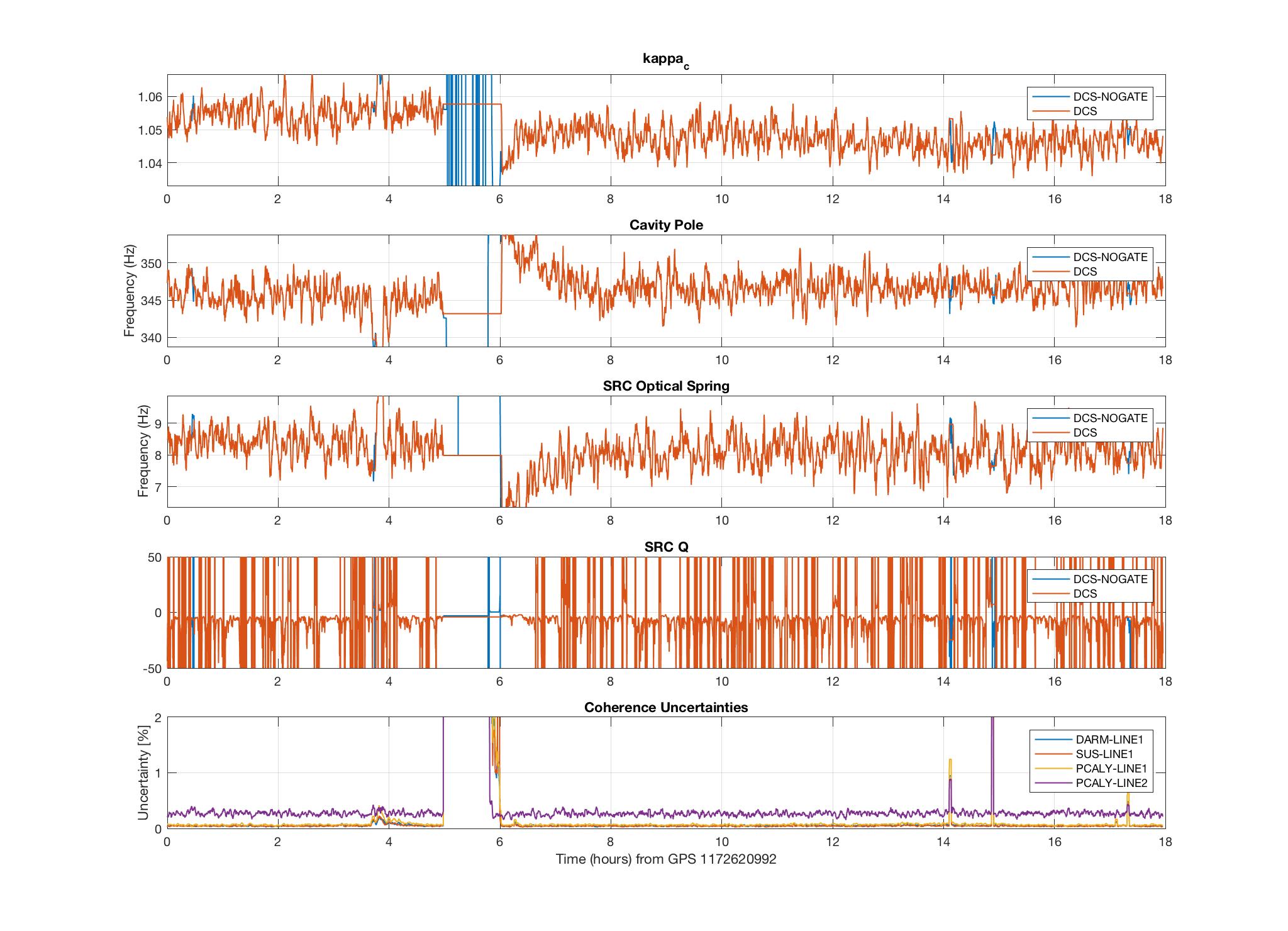
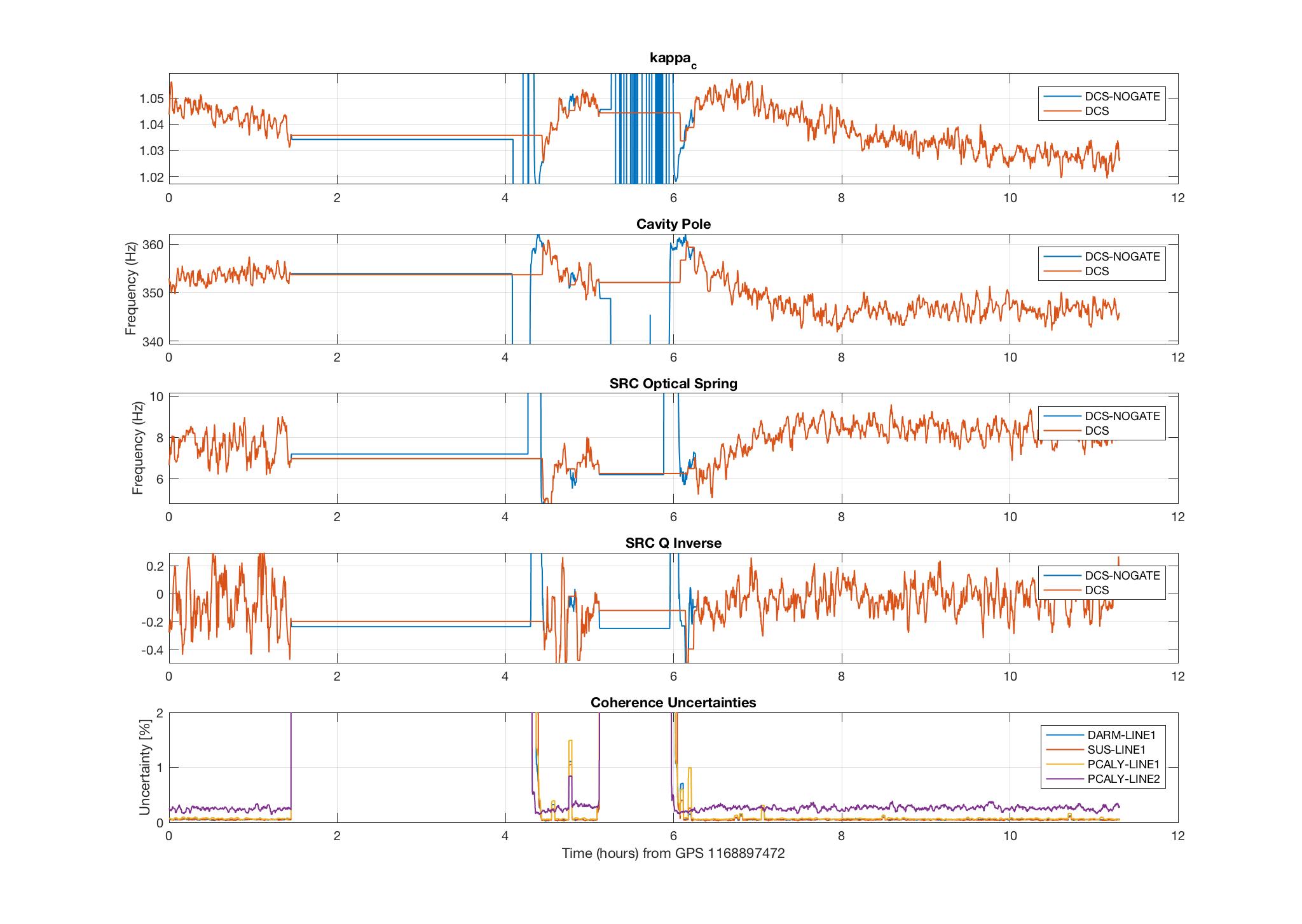
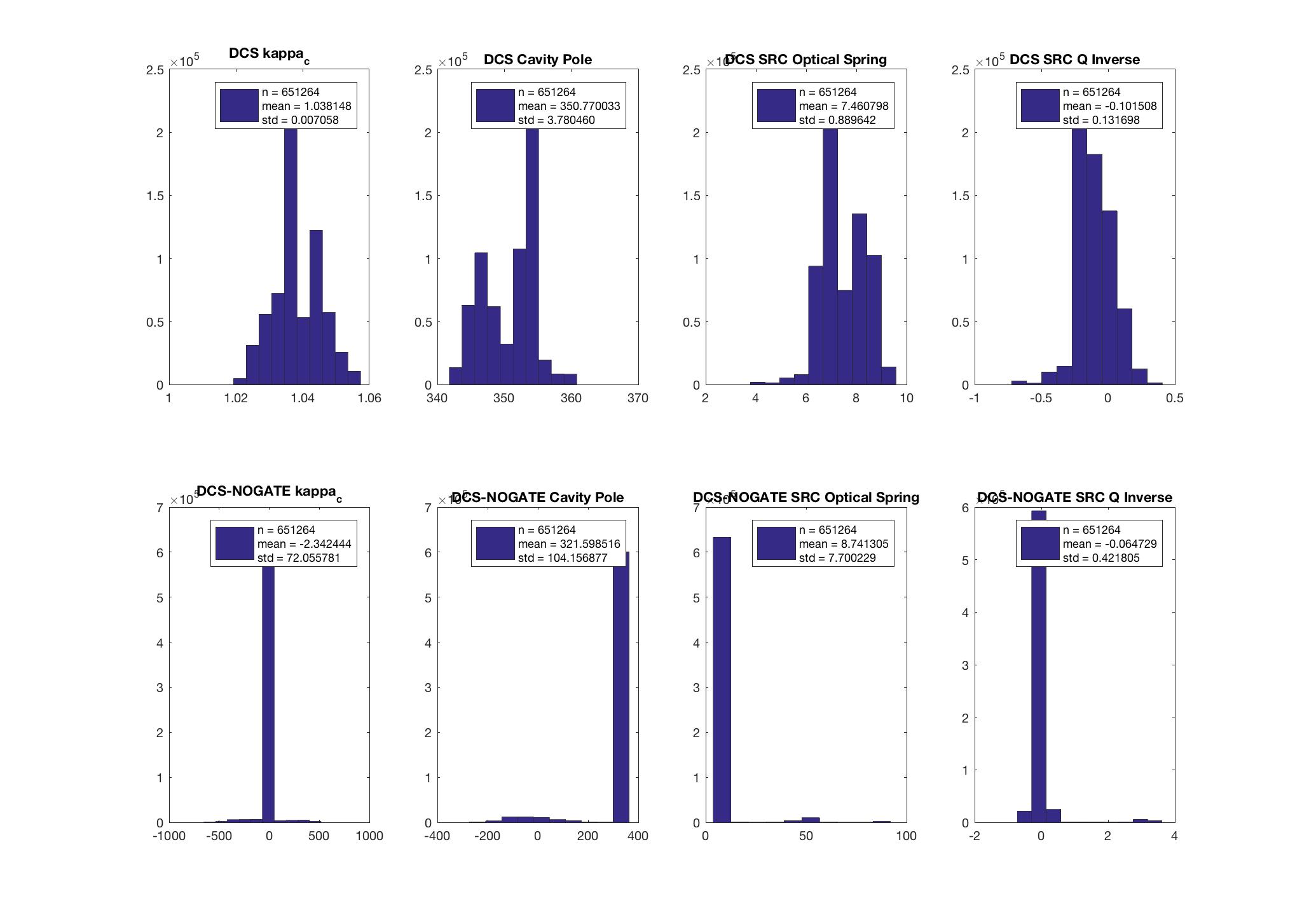
I have added an (unreleased) algorithm into the GDS/DCS pipeline to compute the SRC spring frequency and Q. This algorithm was used to collect 18 hours of data on February 4 (first plot) and 18 hours of data on March 4 (second plot). The plots include kappa_c, the cavity pole, the SRC spring frequency, the SRC Q, and 4 of the coherence uncertainties (uncertainty of the 7.93 Hz line is not yet available).
The derivation this algorithm was based on is similar to what Jeff has posted ( https://dcc.ligo.org/DocDB/0140/T1700106/001/T1700106-v1.pdf ), with differences noted below:
1) The approximation made at the bottom of p4 and top of p5 was only used in the calculation of kappa_c and the cavity pole. So SRC detuning effects were not accounted for in computing S_c. However, kappa_c and the computed cavity pole were used in the calculation of S_s.
2) In eq. 18, I have a minus (-) sign instead of a plus (+) sign before EP6. S_c = S(f_1, t) has been computed this way in GDS/DCS since the start of O2 (I assume during O1 as well).
3) Similarly, in eq. 20, I have a minus sign (-) before EP12.
4) In the lower two equations of 13, I have the terms under the square root subtracted in the opposite order, as suggested by Shivaraj. (Also, I noted that the expression for Q should only depend on S(f_2, t), with no dependence on S(f_1, t). )
The smoothing (128s running median + 10s average) was done on f_s and 1/Q, since that is the way they would be applied to h(t). Therefore, the zero-crossings of 1/Q show up as asymptotes in the plot of Q. I think it would be better to output 1/Q in a channel rather than Q for this reason.
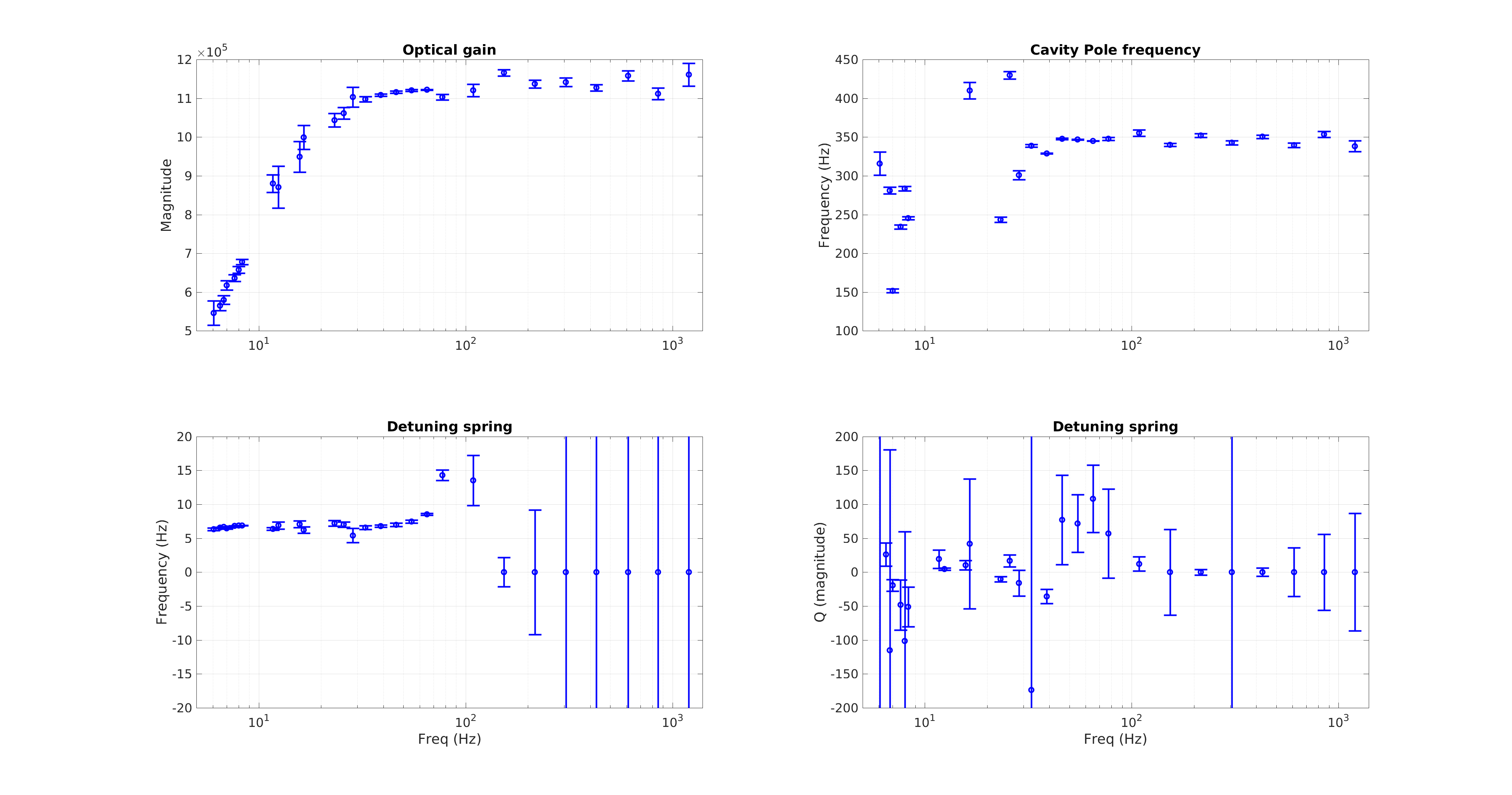
There is a noticeable ramping up of f_s at the beginning of lock stretches, and the range of values agrees with what has been measured previously.
I've noted that it is quite difficult to resolve the value of Q with good accuracy. These are some reasons I suspect:
1) Higher uncertainty of calibration measurements at low frequency can add a systematic error to the EPICS values computed at 7.93 Hz. This may be why the Q is more often negative than positive ??
2) In the calculation of S_s, the actuation strength is subtracted from the ratio of pcal and DARM_ERR. Since this is such a low frequency, the subtracted values are close to the same value in magnitude and phase. Thus, subtracting magnifies both systematic error and uncertainty.
3) The imaginary part of S_s (see eq. 13, bottom equation) in the denominator, is very close to zero, so small fluctuations (about zero, as it turns out) in 1/Q cause large fluctuations in Q.
These reasons make it difficult to measure Q with this method. The effect of these measured-Q fluctuations on S_s, the factor we would actually apply to h(t) (see eq. 22), is not enormous, so long as we apply the smoothing to 1/Q, as I have done here.