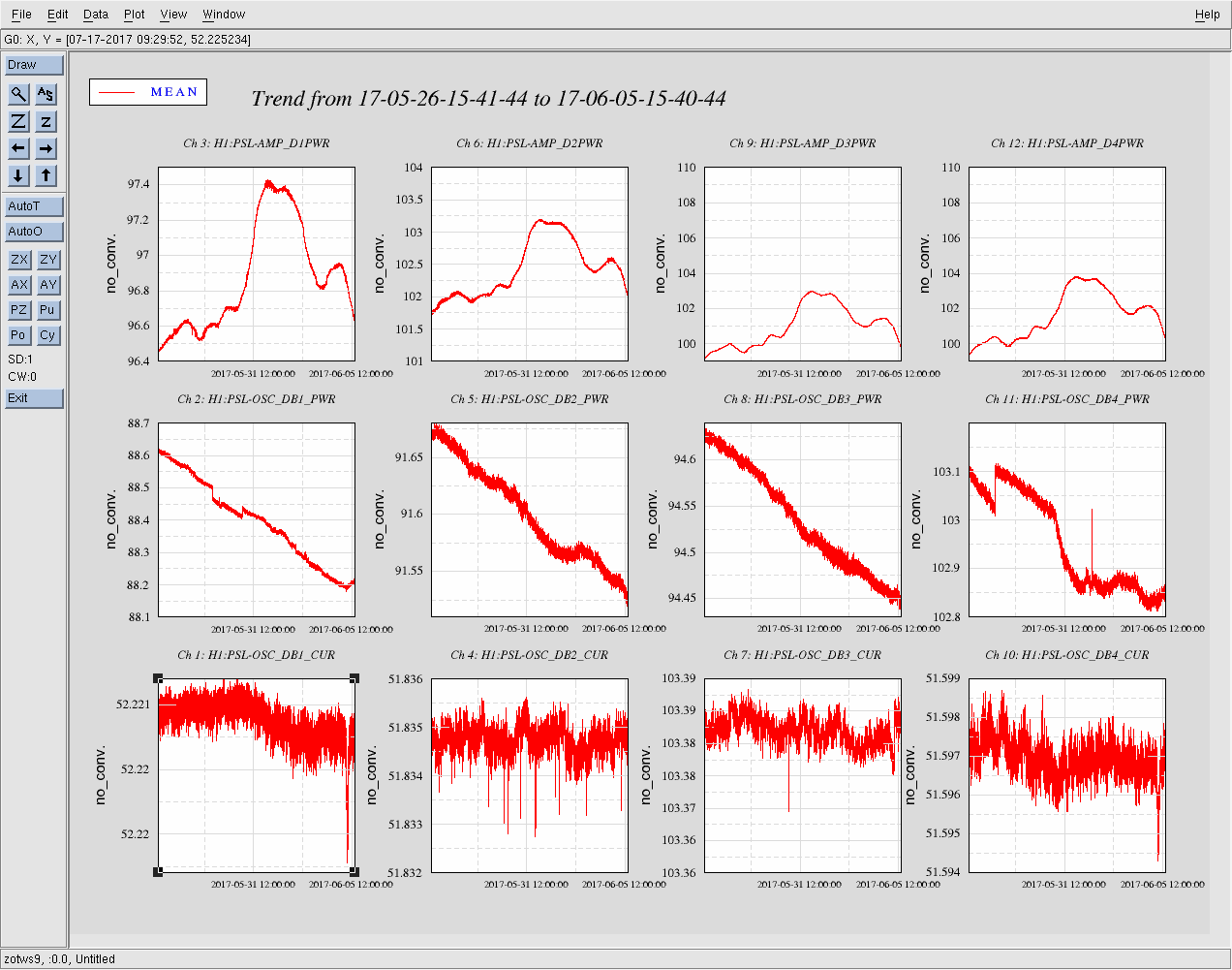
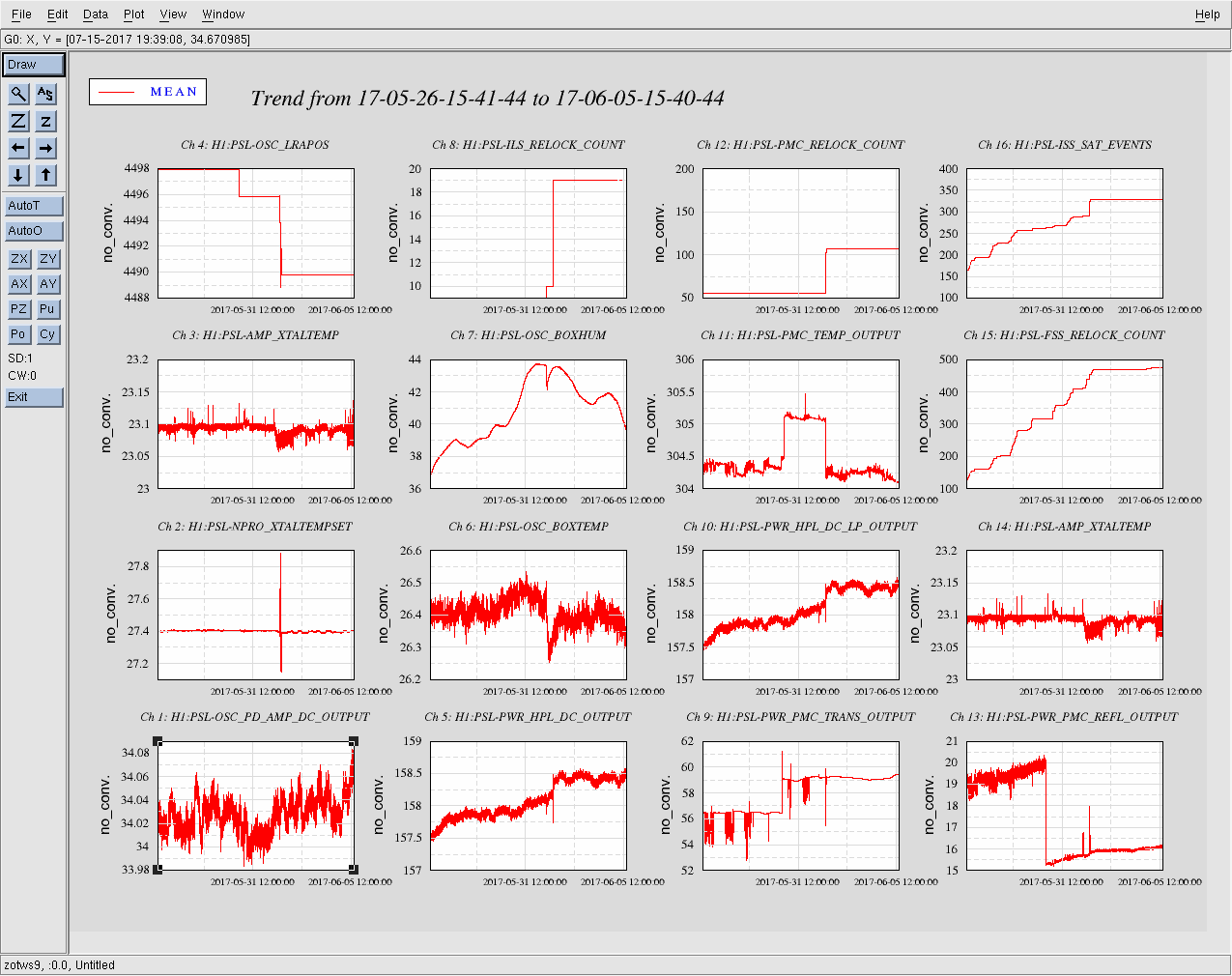
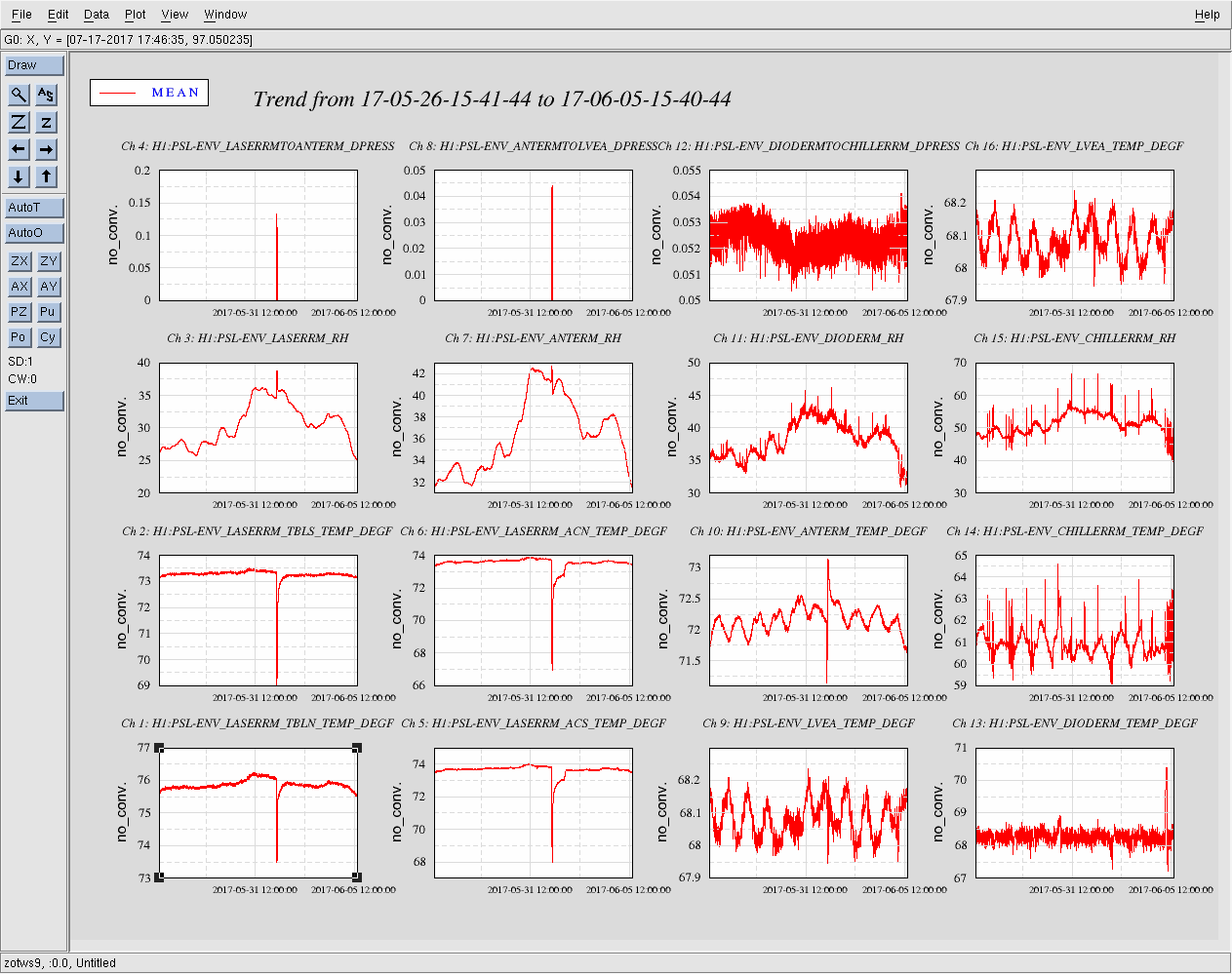
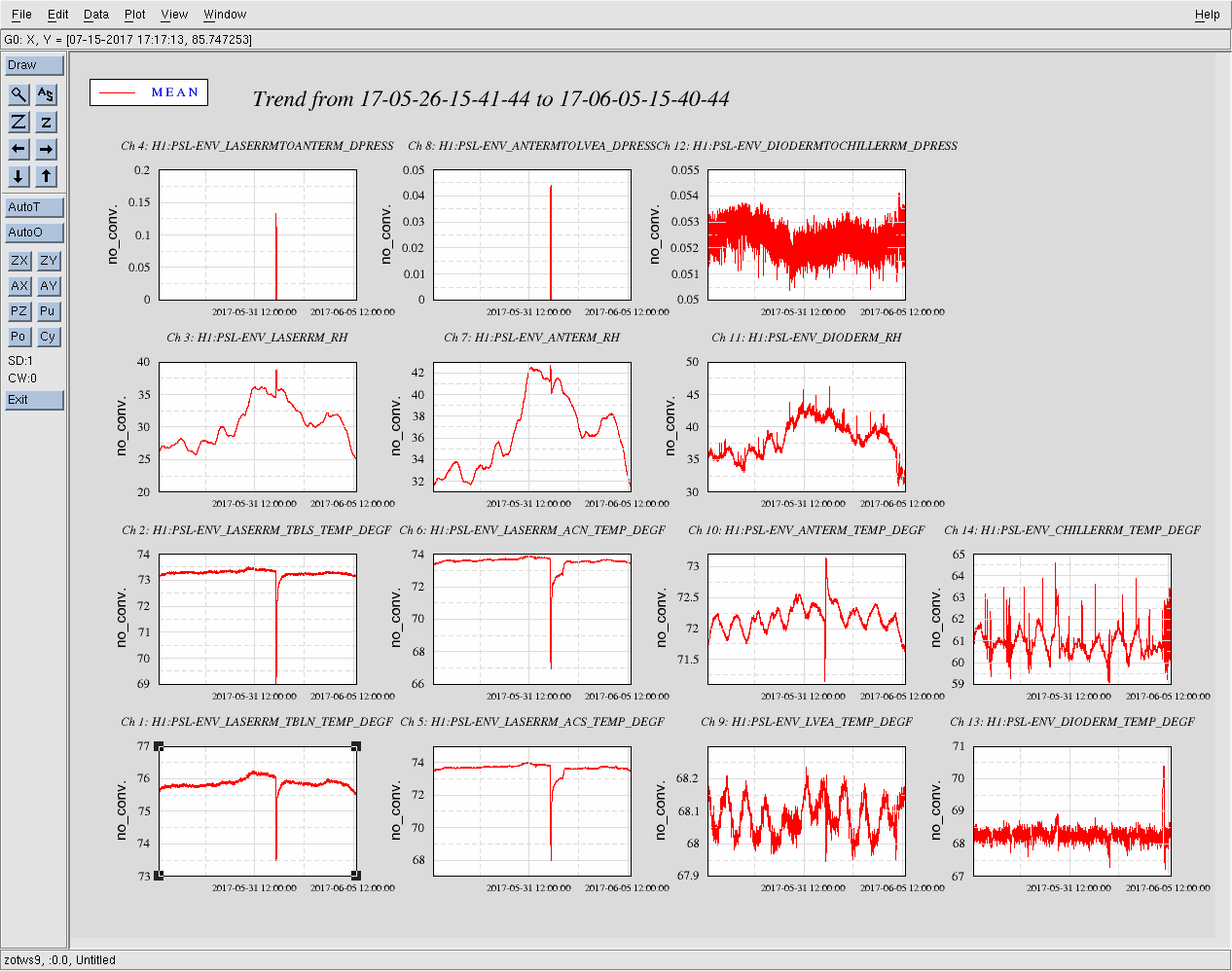
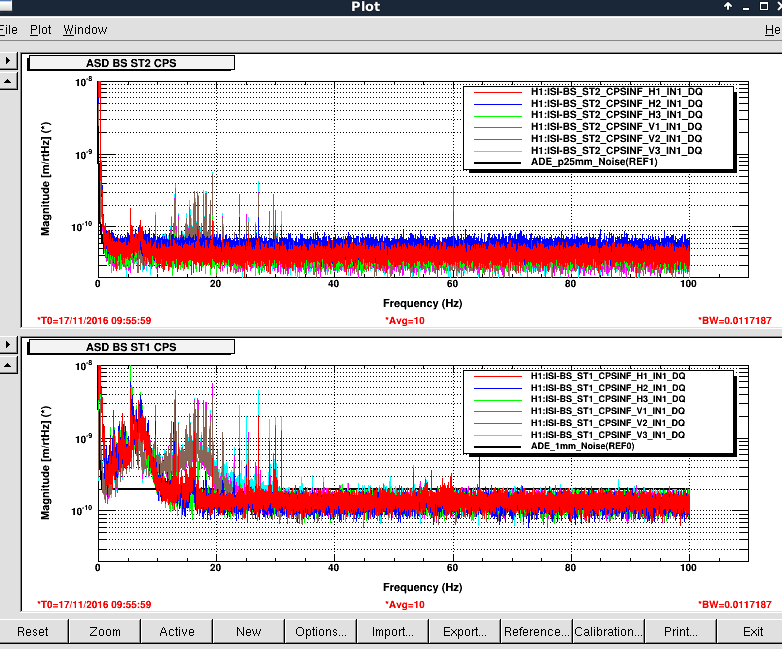
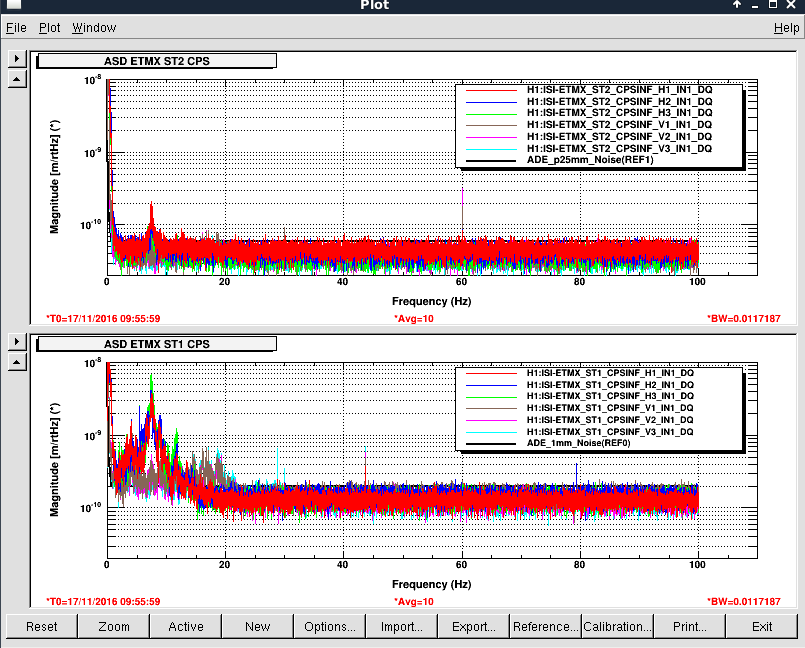
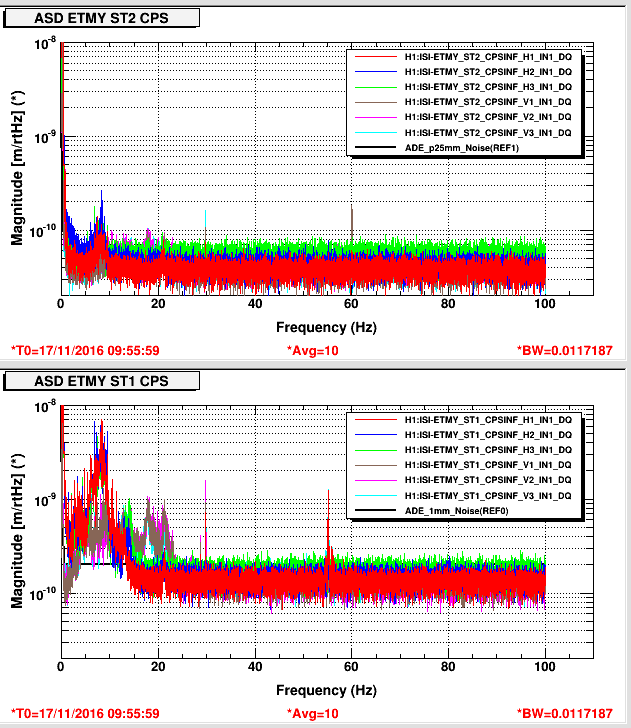
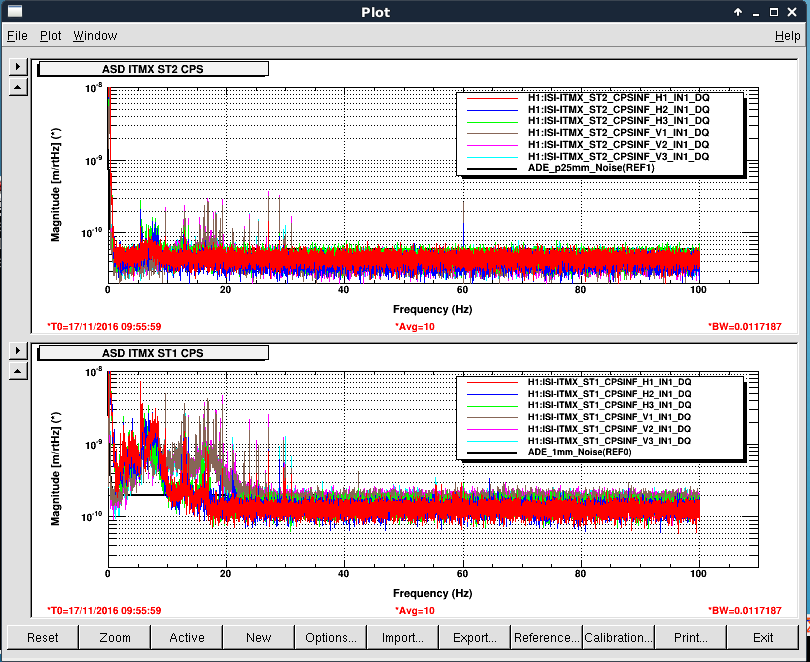
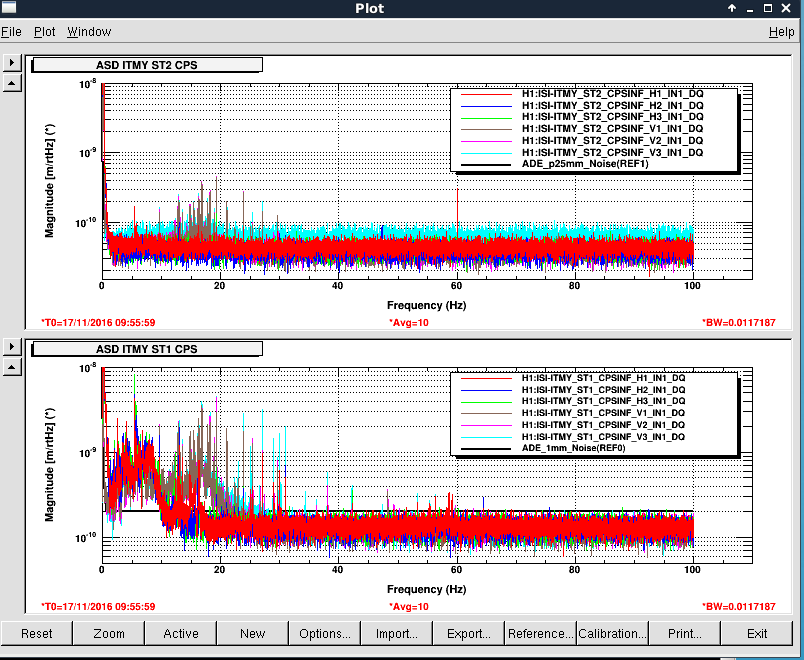
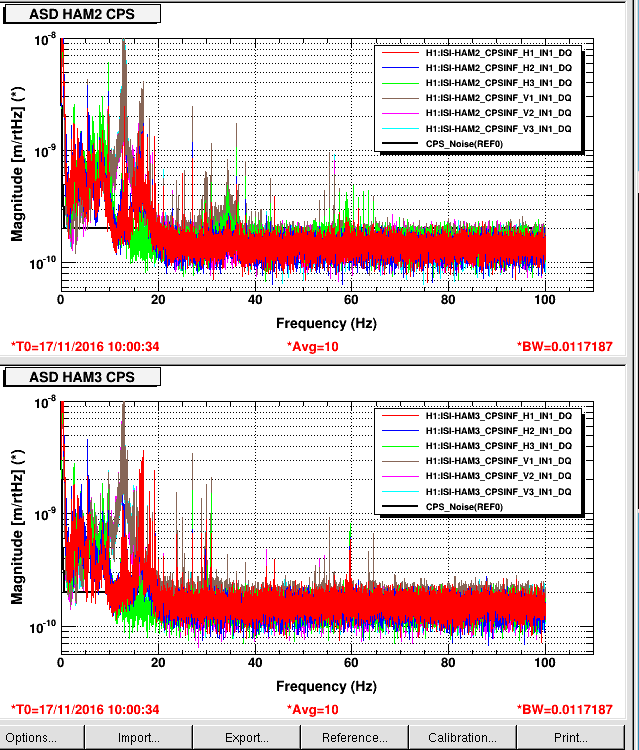
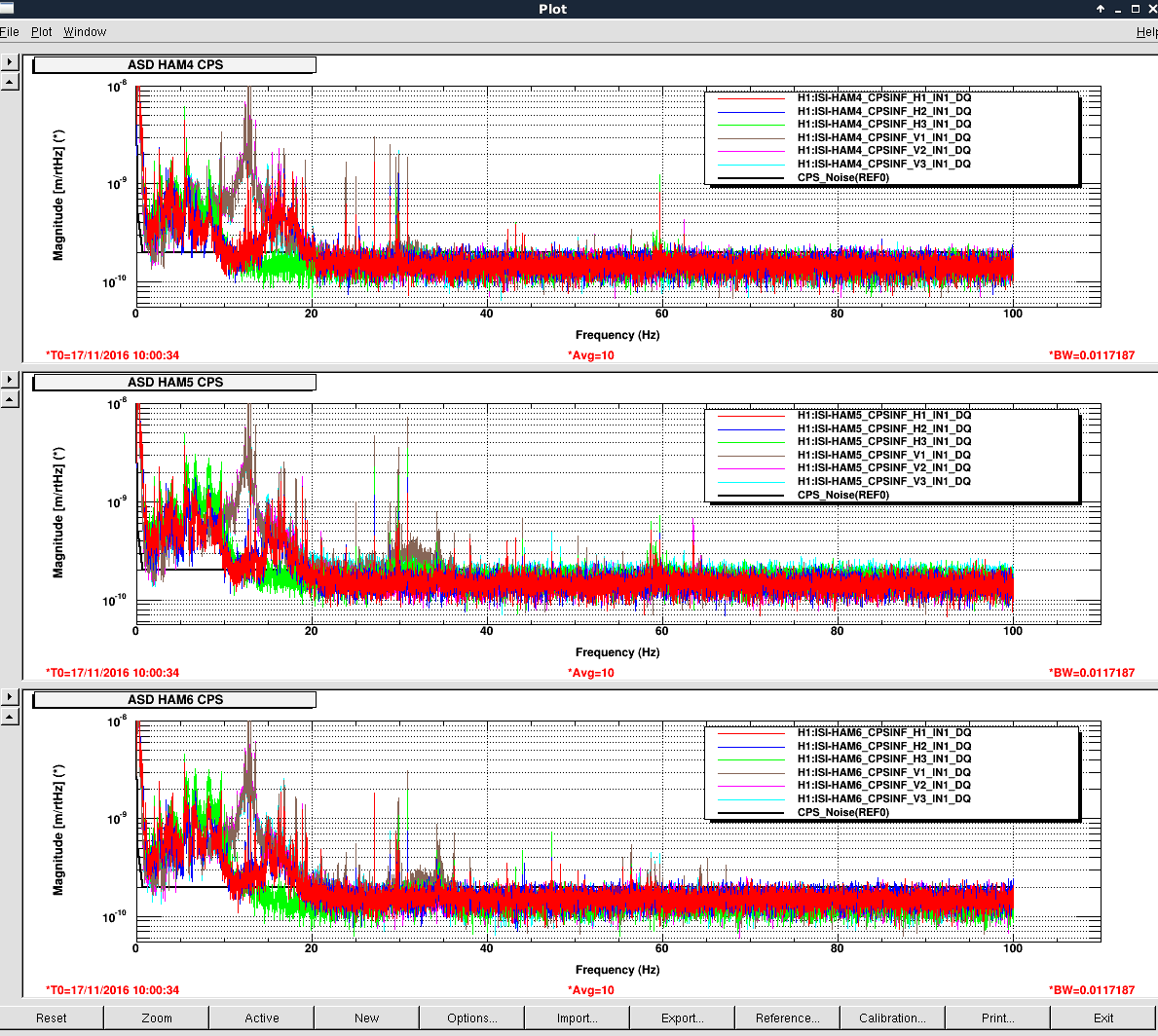
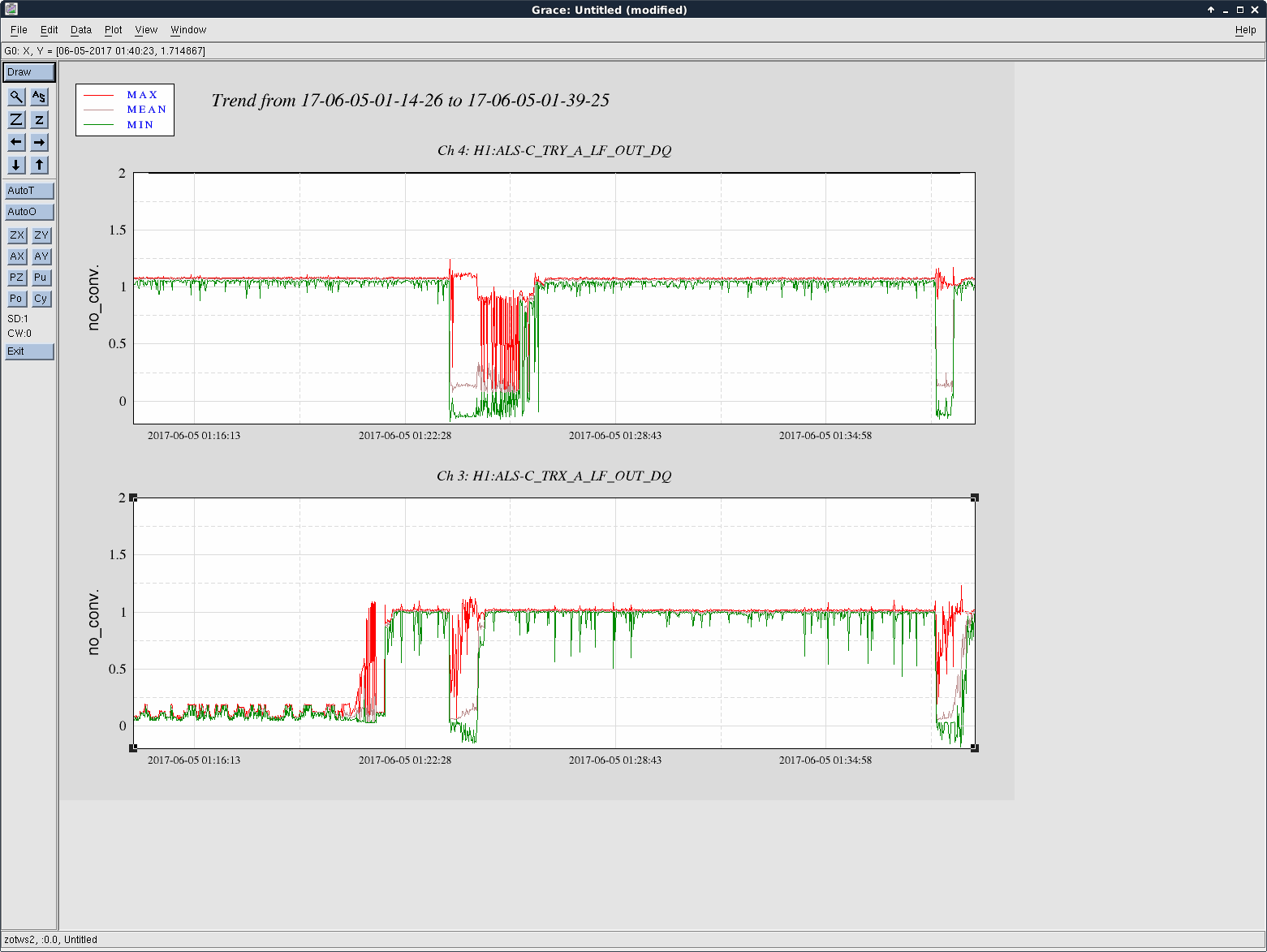
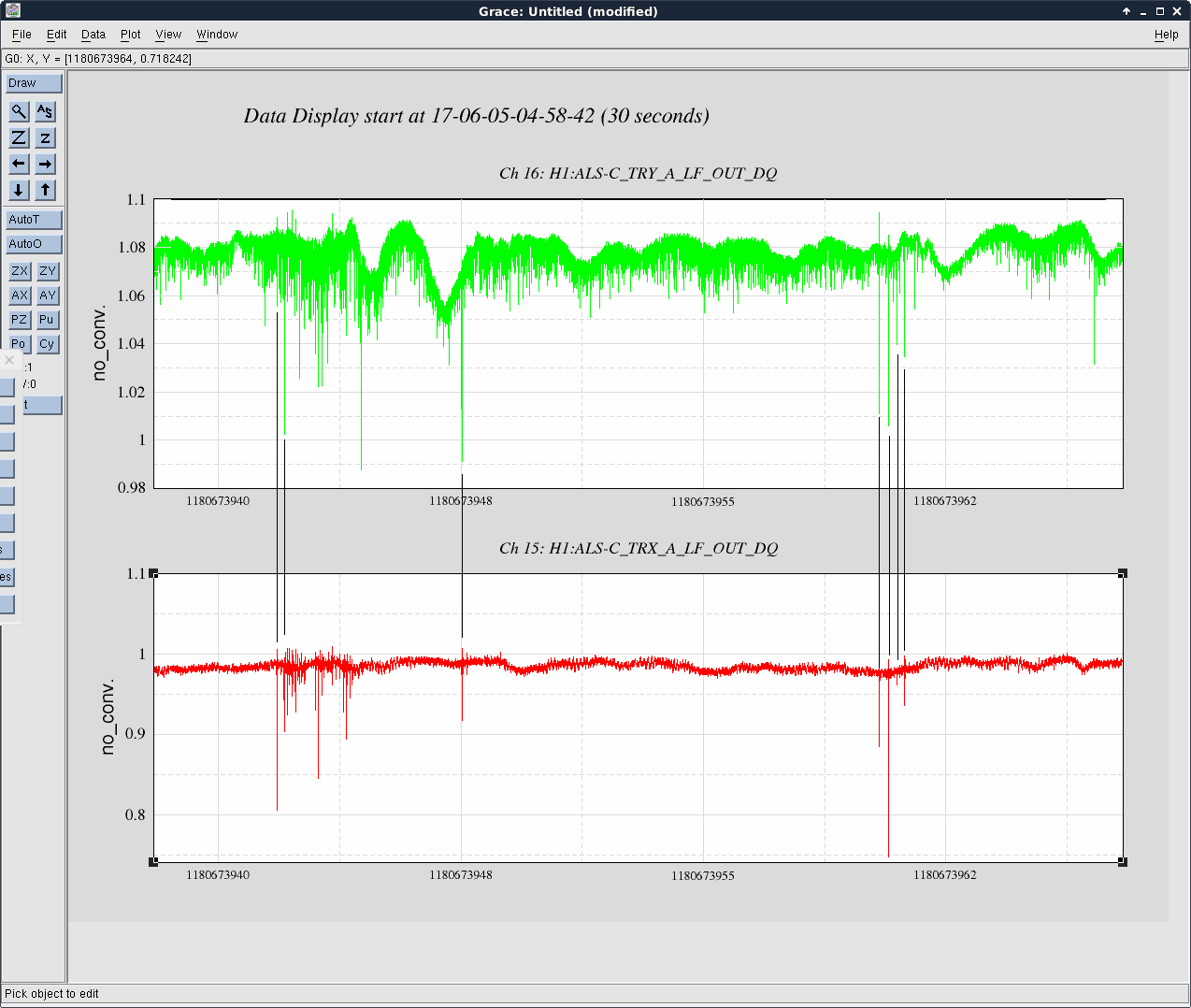
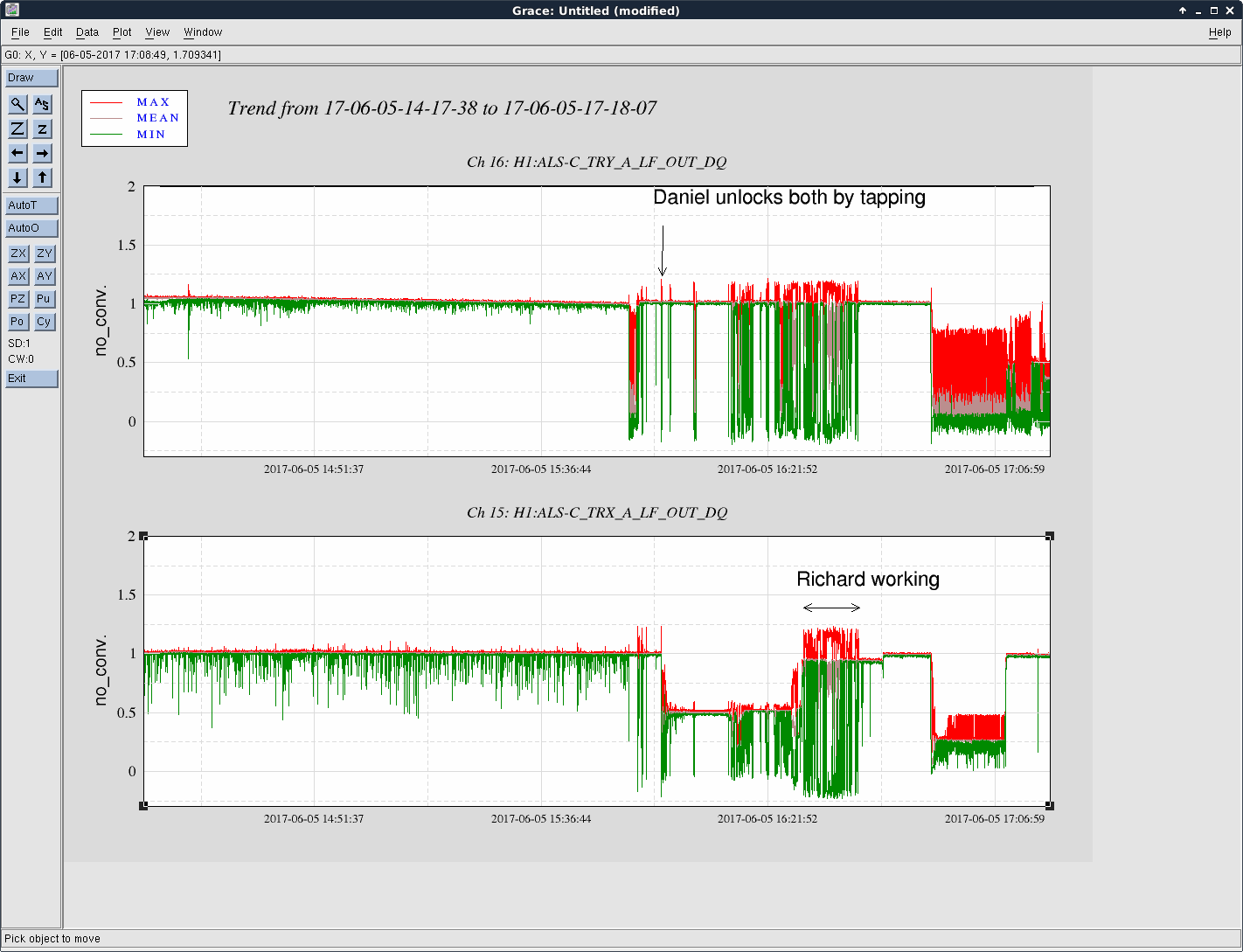
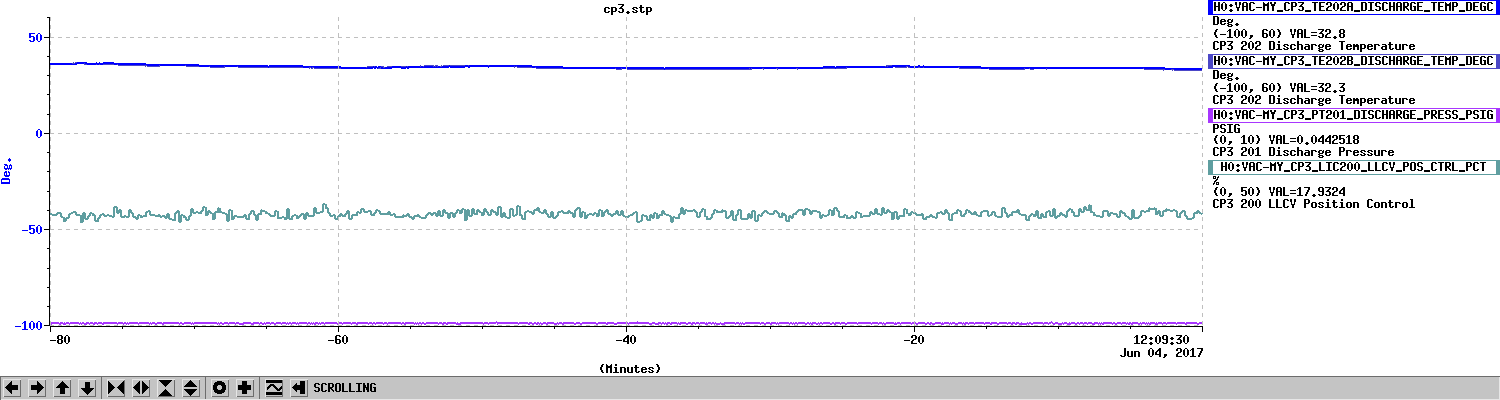
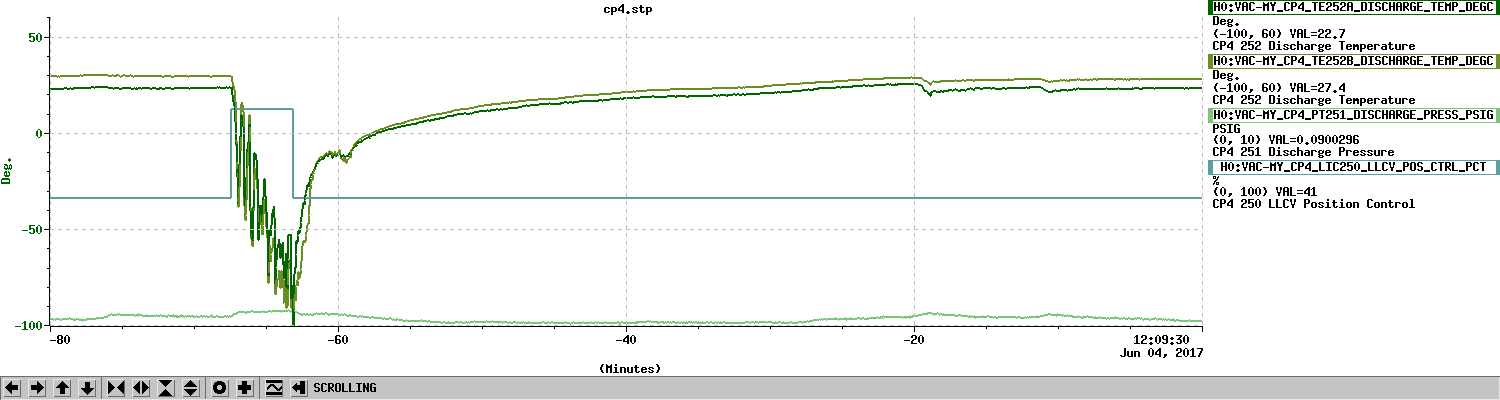
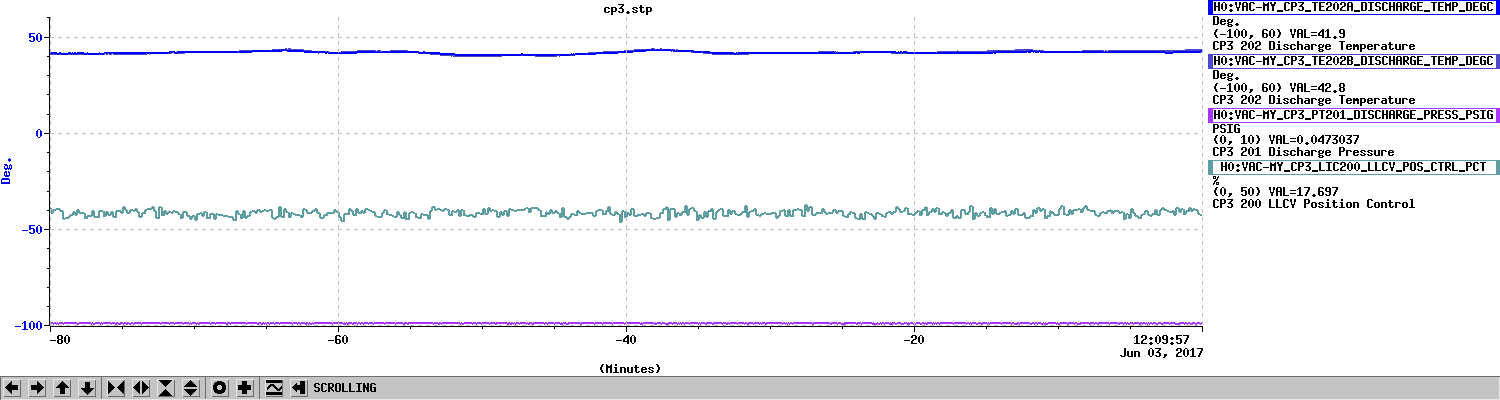
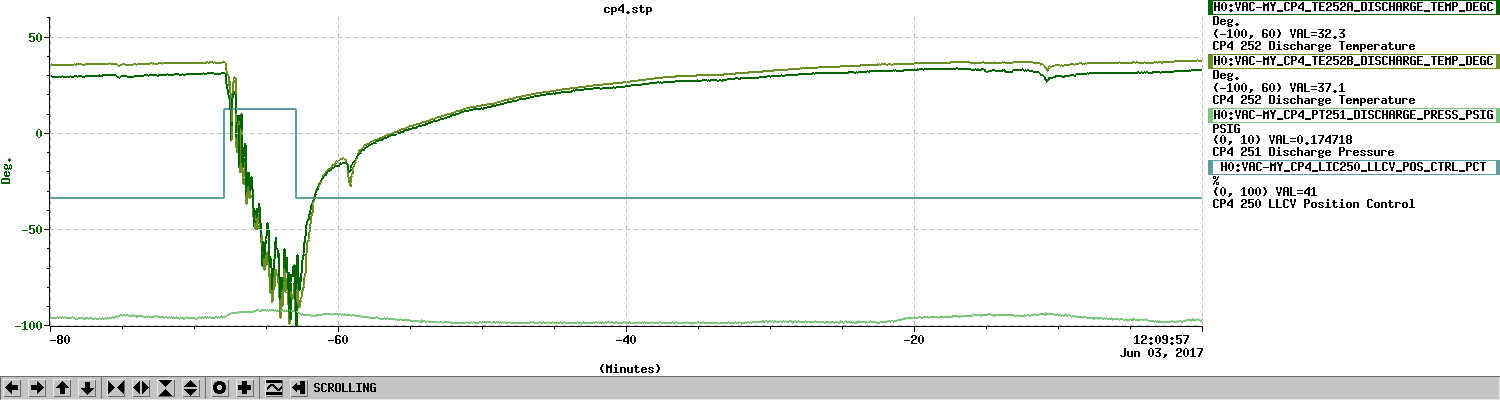
Averaging Mass Centering channels for 10 [sec] ...
2017-06-05 10:43:01.360996
There are 5 T240 proof masses out of range ( > 0.3 [V] )!
ETMX T240 2 DOF X/U = -1.017 [V]
ETMX T240 2 DOF Y/V = -0.987 [V]
ETMX T240 2 DOF Z/W = -0.743 [V]
ITMX T240 1 DOF X/U = -0.664 [V]
ITMX T240 3 DOF X/U = -0.685 [V]
All other proof masses are within range ( < 0.3 [V] ):
ETMX T240 1 DOF X/U = -0.064 [V]
ETMX T240 1 DOF Y/V = -0.03 [V]
ETMX T240 1 DOF Z/W = -0.008 [V]
ETMX T240 3 DOF X/U = -0.05 [V]
ETMX T240 3 DOF Y/V = -0.161 [V]
ETMX T240 3 DOF Z/W = -0.052 [V]
ETMY T240 1 DOF X/U = -0.008 [V]
ETMY T240 1 DOF Y/V = 0.18 [V]
ETMY T240 1 DOF Z/W = -0.224 [V]
ETMY T240 2 DOF X/U = 0.147 [V]
ETMY T240 2 DOF Y/V = -0.231 [V]
ETMY T240 2 DOF Z/W = 0.032 [V]
ETMY T240 3 DOF X/U = -0.244 [V]
ETMY T240 3 DOF Y/V = -0.019 [V]
ETMY T240 3 DOF Z/W = 0.271 [V]
ITMX T240 1 DOF Y/V = -0.213 [V]
ITMX T240 1 DOF Z/W = -0.15 [V]
ITMX T240 2 DOF X/U = -0.162 [V]
ITMX T240 2 DOF Y/V = -0.135 [V]
ITMX T240 2 DOF Z/W = -0.182 [V]
ITMX T240 3 DOF Y/V = -0.131 [V]
ITMX T240 3 DOF Z/W = -0.075 [V]
ITMY T240 1 DOF X/U = -0.024 [V]
ITMY T240 1 DOF Y/V = -0.046 [V]
ITMY T240 1 DOF Z/W = -0.058 [V]
ITMY T240 2 DOF X/U = 0.125 [V]
ITMY T240 2 DOF Y/V = 0.138 [V]
ITMY T240 2 DOF Z/W = 0.008 [V]
ITMY T240 3 DOF X/U = -0.248 [V]
ITMY T240 3 DOF Y/V = 0.053 [V]
ITMY T240 3 DOF Z/W = -0.263 [V]
BS T240 1 DOF X/U = -0.166 [V]
BS T240 1 DOF Y/V = -0.03 [V]
BS T240 1 DOF Z/W = 0.219 [V]
BS T240 2 DOF X/U = 0.067 [V]
BS T240 2 DOF Y/V = 0.195 [V]
BS T240 2 DOF Z/W = 0.007 [V]
BS T240 3 DOF X/U = 0.028 [V]
BS T240 3 DOF Y/V = -0.068 [V]
BS T240 3 DOF Z/W = -0.118 [V]
Assessment complete.
2017-06-05 10:45:39.355333
All STSs prrof masses that within healthy range (< 2.0 [V]). Great!
Here's a list of how they're doing just in case you care:
STS A DOF X/U = -0.609 [V]
STS A DOF Y/V = 0.203 [V]
STS A DOF Z/W = -0.448 [V]
STS B DOF X/U = 0.492 [V]
STS B DOF Y/V = 0.314 [V]
STS B DOF Z/W = -0.307 [V]
STS C DOF X/U = -0.37 [V]
STS C DOF Y/V = -0.661 [V]
STS C DOF Z/W = 0.497 [V]
STS EX DOF X/U = 0.018 [V]
STS EX DOF Y/V = 0.624 [V]
STS EX DOF Z/W = -0.01 [V]
STS EY DOF X/U = 0.002 [V]
STS EY DOF Y/V = 0.213 [V]
STS EY DOF Z/W = 0.443 [V]
Assessment complete.