J. Oberling, P. King, E. Merilh
Today we swapped Diode Box 1 (DB1) for the PSL HPO with a spare shipped up from LLO. The swap was relatively painless, although we did have a delay in attempting to extract a rounded screw from the lid of the "new" diode box. Once that was taken care of the DB was installed in the PSL LDR. We then turned only DB1 on with 20A of current. Using an IR camera we confirmed that none of the fiber connections were overheating (all were <23 °C). The PSL was then restarted.
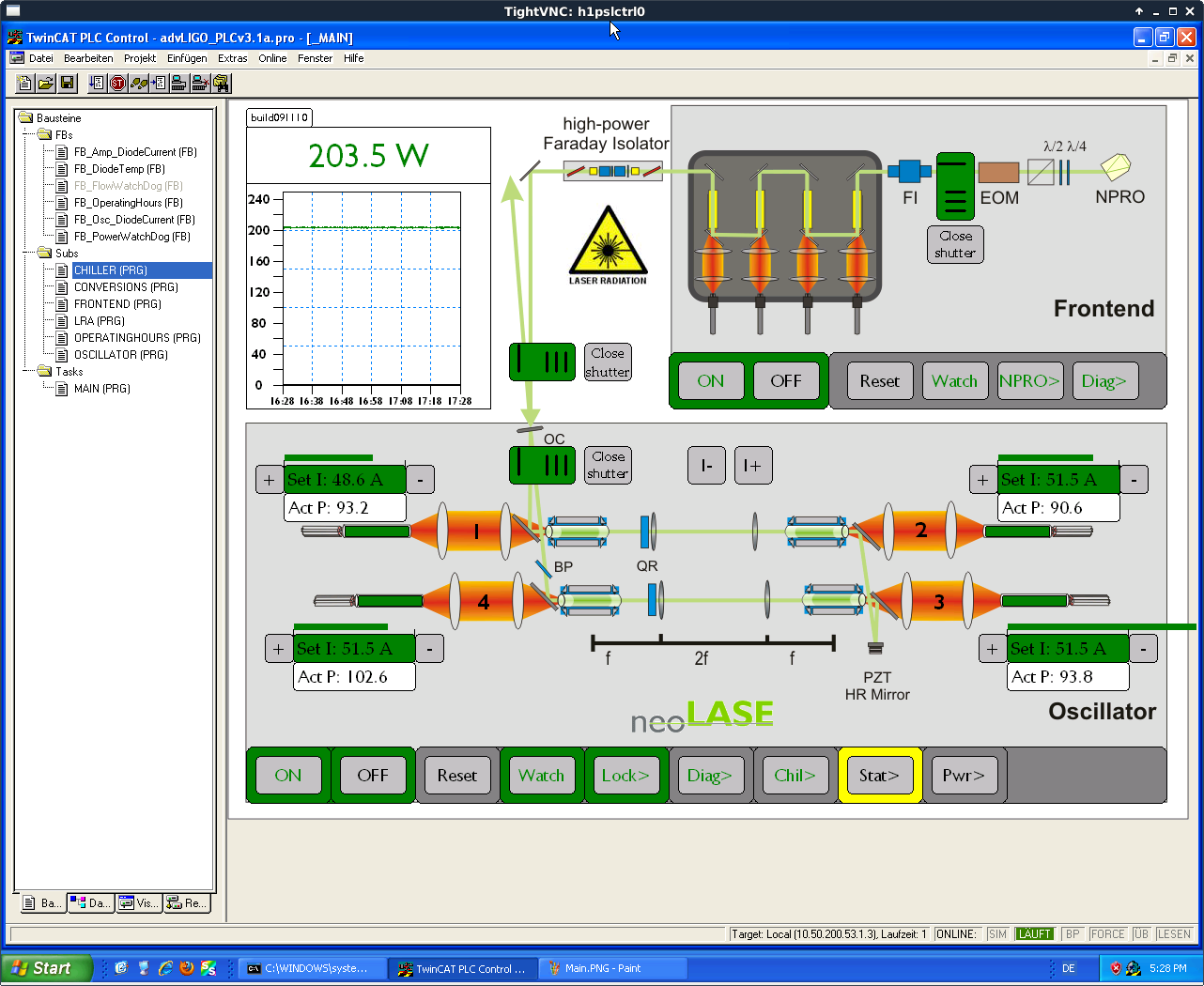
For the new DB, we used an operating current of 49.3 A and set the temperature setpoints for the individual diodes to 29 °C. The HPO came up with zero issues. We then rotated each fiber connecter in the DB to maximize the power output by the HPO (unscrew the connector just enough so the fiber can rotate, rotate to maximize power, re-tighten connector). Once this was done DB1 was closed and we slid it into place in the rack. The 35W FE was restarted and injection locking engaged; the PSL was left to warm up in this configuration for ~1 hour.
After the warm-up period, the pump diode operating current and temperatures were adjusted to incorporate the new DB. The temperatures of the diodes in DB2, DB3, & DB4 were unchanged; the temperatures of the diodes in DB1 were changed to 28 °C. The operating current of each of the 4 DBs is summarized below (a screenshot is attached for future reference):
- DB1: 48.6 A
- DB2: 51.5 A
- DB3: 51.5 A
- DB4: 51.5 A
The PSL is now outputting ~158 W, and the PMC is transmitting ~60 W. The PSL is now fully recovered from the DB swap and functioning as it was before work began. The SN of the old DB is OBS2-DB1, the SN of the new DB is OBS1-DB1.
This closes LHO WP 7019. Incidentally, this work also completes FAMIS 3653 (Weekly PSL Power Watchdog Reset) and FAMIS 8425 (PSL Weekly HPO Pump Diode Current Adjust).
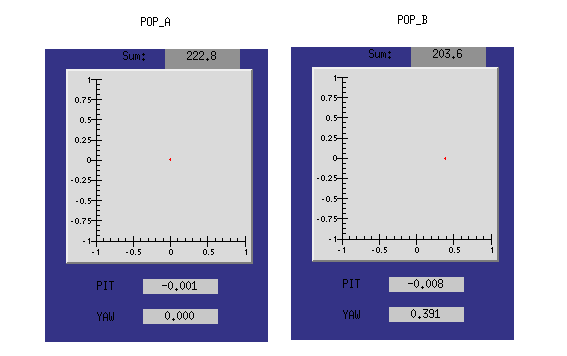
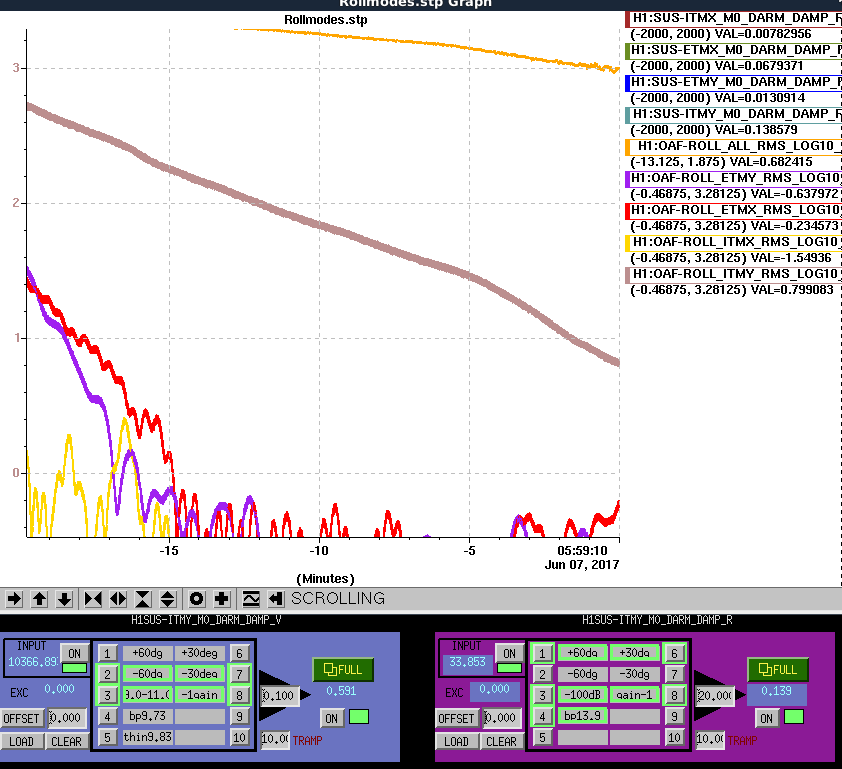
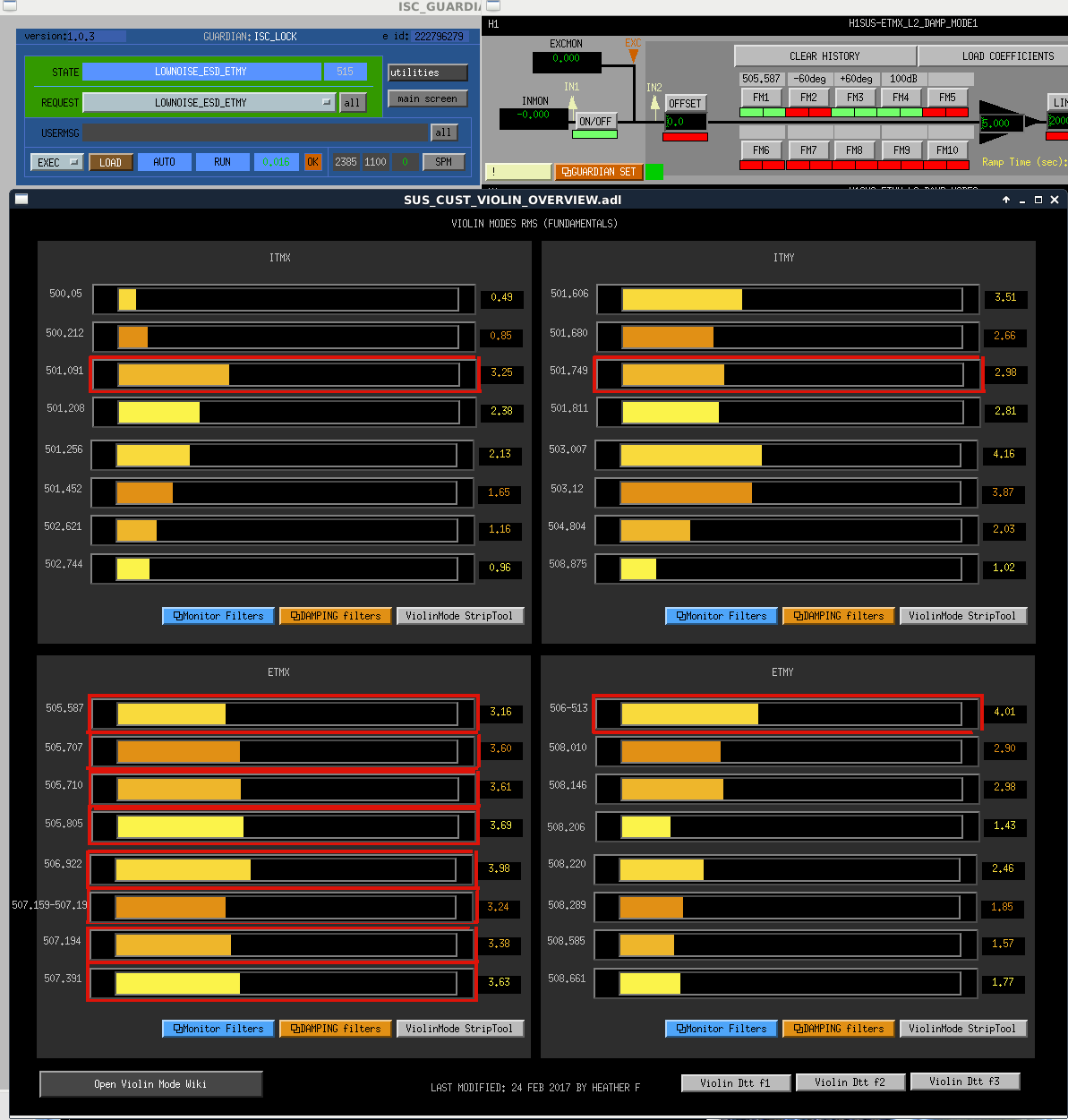
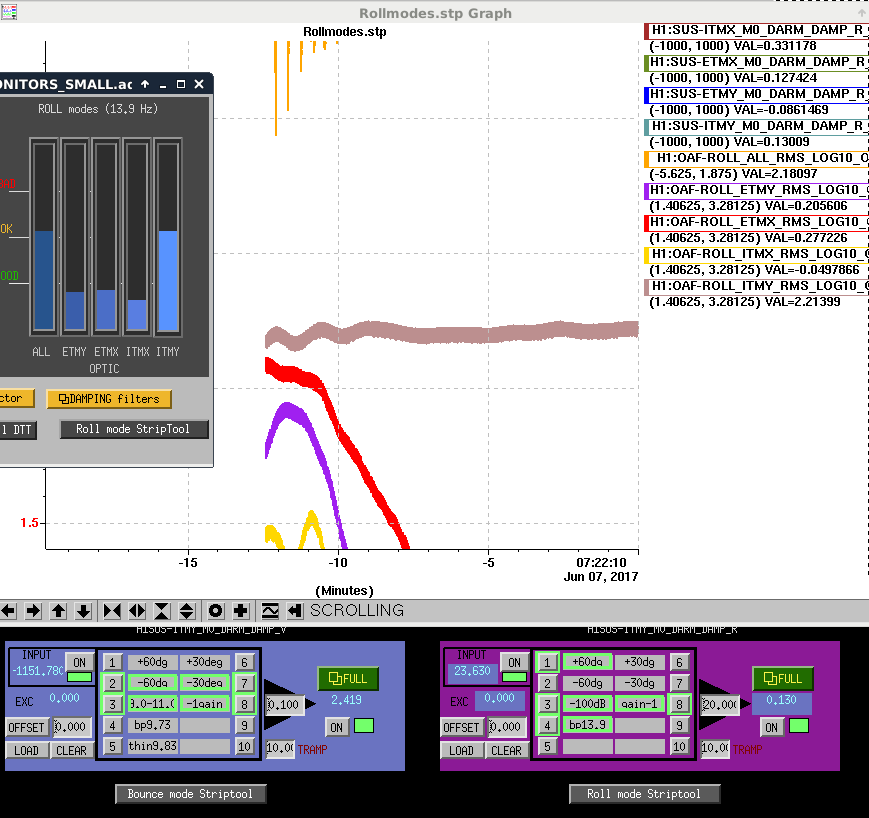
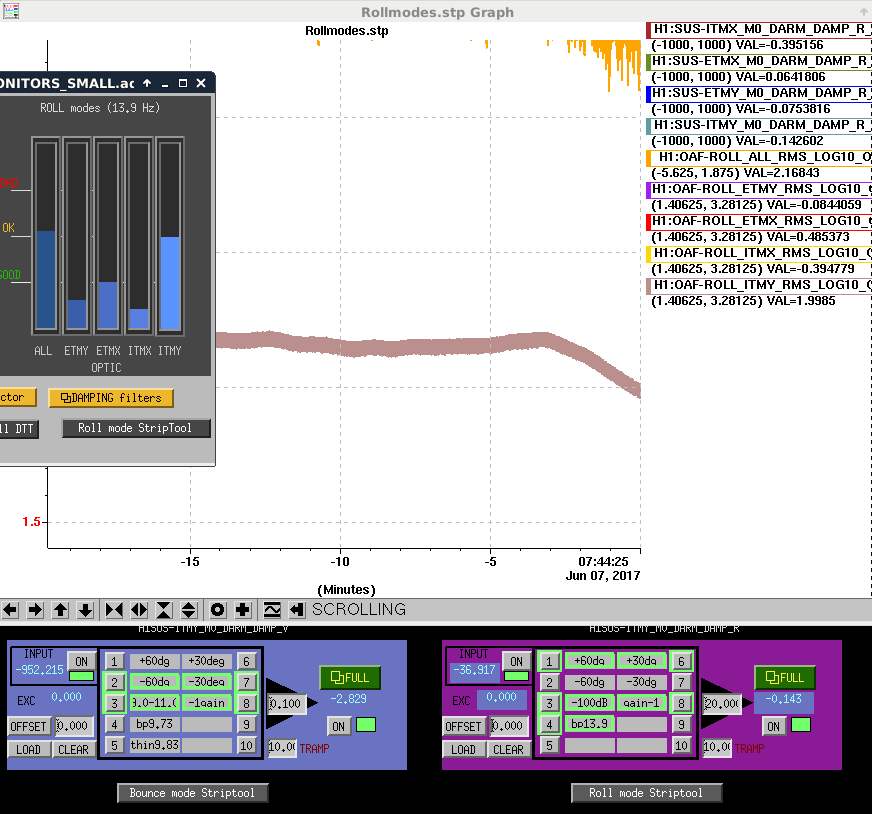


While still at LOWNOISE_ASC, PI Modes started ringing up.
Just making notes of locking this morning, since after the PI Mode lockloss this morning. (it's been a month since I've worked on this machine!) :)
Lock#1
Lock#2: went to DC read out (made it on its own)
Lock#3: went to DC read out (made it on its own)
We confirmed that the problematic peak is at 18040 Hz and that Mode27 has the right BP and PLL Set Freq settings for damping that. I've also (mostly) confirmed that 18040 Hz is still ETMY. I've done this by looking at the frequency drifts over a recent lock, though all locks have been short so there's still some uncertainty.
I've attached a spectrum of the four 18kHz peaks we've had problems with in the past and what Mode they should belong to (I will be able to further verify this with a longer lock/strong temperature change during a lock). Please update BandPasses and PLL set frequencies to match these observed frequencies - this should be checked somewhat regularly for all problematic PI modes (you can use the PI DTT button from the PI medm main screen to generate a current spectrum).