A TCS guardian just knocked us out of observe again.It has knocked us out of OBSERVE for about ten minutes, while it fiddles with some PZT offsets. I also couldn't find the link to the SDF screen for the ITMY guardian to see what the differences are. It looks like the guardian is having a hard time staying locked.
2017-05-06T07:03:50.60179 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 45.5
2017-05-06T07:03:50.60248 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:03:53.60372 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:03:53.72259 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 49.0
2017-05-06T07:03:53.72295 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:03:56.72339 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:03:56.85062 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 52.5
2017-05-06T07:03:56.85110 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:03:59.86033 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:03:59.95678 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 56.0
2017-05-06T07:03:59.95728 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:04:02.95752 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:04:03.08470 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 59.5
2017-05-06T07:04:03.08496 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:04:06.08646 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:04:06.19308 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 63.0
2017-05-06T07:04:06.19765 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:04:09.19820 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:04:09.30854 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 66.5
2017-05-06T07:04:09.30885 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:04:12.31090 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:04:12.41767 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_PZT_SET_POINT_OFFSET => 70.0
2017-05-06T07:04:12.42090 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] = 3
2017-05-06T07:04:15.42433 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['wait'] done
2017-05-06T07:04:15.51860 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] 3.5, 7.0, 10.5, 14.0, 17.5, 21.0, 24.5, 28.0, 31.5, 35.0, 38.5, 42.0, 45.5, 49.0, 52.5, 56.0, 59.5, 63.0, 66.5, 70.0
2017-05-06T07:04:15.51863 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] 54.8988848698, 54.8350498672, 54.891019514, 55.1177868928, 55.3451070593, 55.5405800837, 55.7137985201, 55.8408840514, 55.6183281204, 55.3447073749, 55.1125390519, 55.0134612237, 55.0977940265, 55.192294462, 55.2613368151, 55.3127282154, 55.3339794561, 55.3309874091, 55.3280875704, 55.2947084872
2017-05-06T07:04:15.61037 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] slopecheckfail 0
2017-05-06T07:04:15.61039 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] slope [-0.01823857 0.01599133 0.06479068 0.06494862 0.05584944 0.04949098
2017-05-06T07:04:15.61040 0.03631015 -0.06358741 -0.07817736 -0.06633381 -0.02830795 0.02409509
2017-05-06T07:04:15.61041 0.02700012 0.01972639 0.01468326 0.00607178 -0.00085487 -0.00082853
2017-05-06T07:04:15.61041 -0.00953688]
2017-05-06T07:04:15.61042 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] gain setting for servo is -54.8288534565
2017-05-06T07:04:15.61042 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] 0
2017-05-06T07:04:15.61043 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] 3.5
2017-05-06T07:04:15.61043 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] 54.8988848698
2017-05-06T07:04:15.61044 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] current chiller setpoint 20.9
2017-05-06T07:04:15.62412 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_CHILLER_SET_POINT_OFFSET => 21.0
2017-05-06T07:04:15.62907 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] ezca: H1:TCS-ITMY_CO2_CHILLER_TSTEP => 1178089473.0
2017-05-06T07:04:15.62921 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] new chiller setpoint 21.0
2017-05-06T07:04:15.63284 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] timer['chillerstep'] = 240
2017-05-06T07:04:15.63295 TCS_ITMY_CO2 [FIND_LOCK_POINT.run] no setpoint found:stepping chiller temp
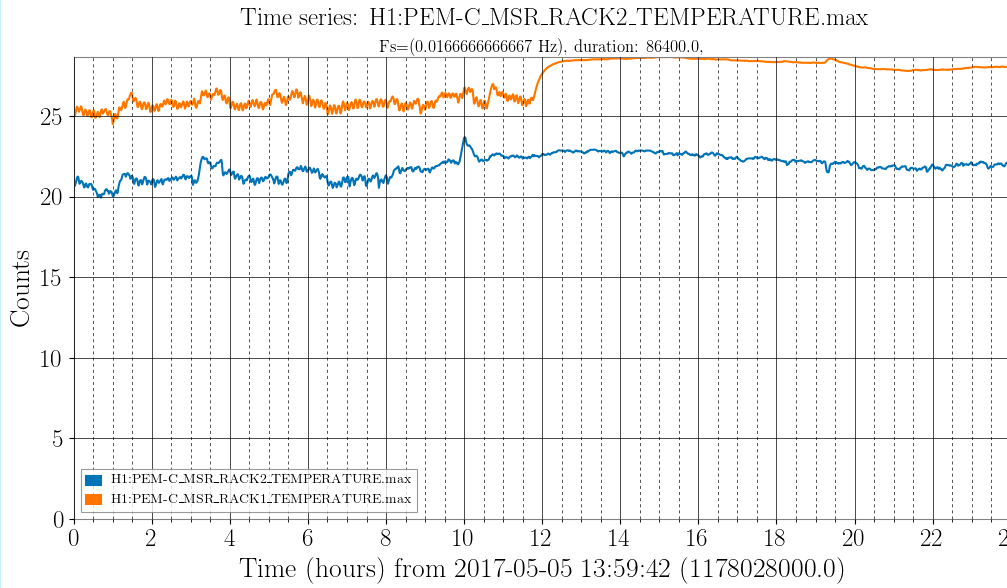
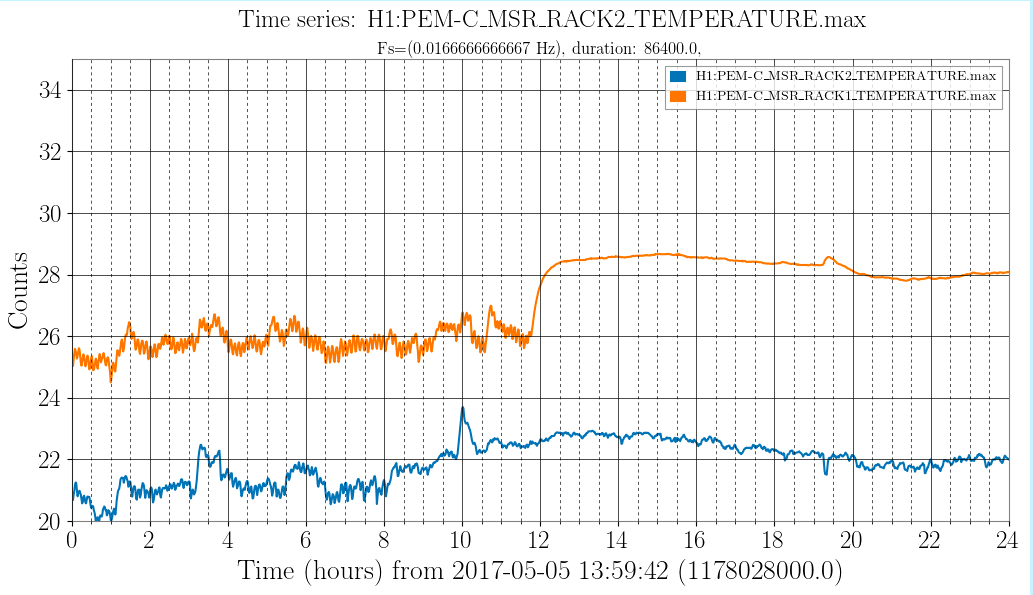

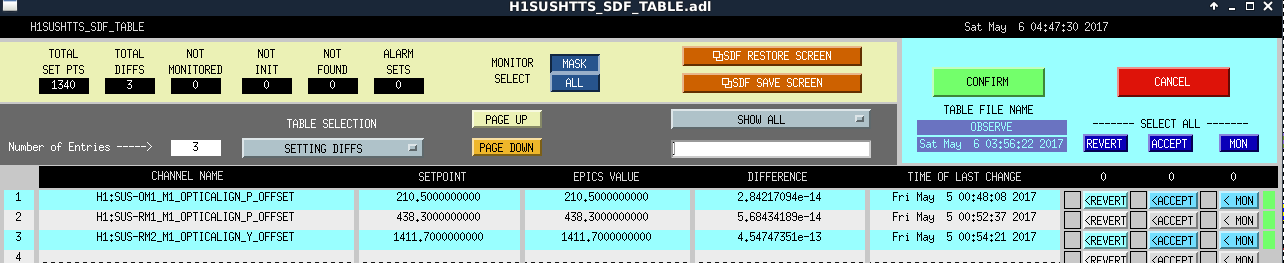
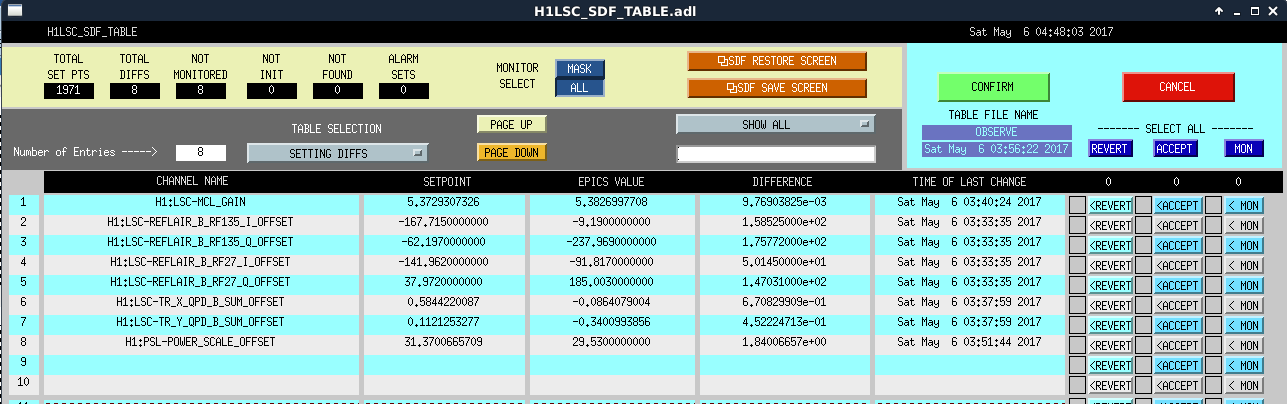

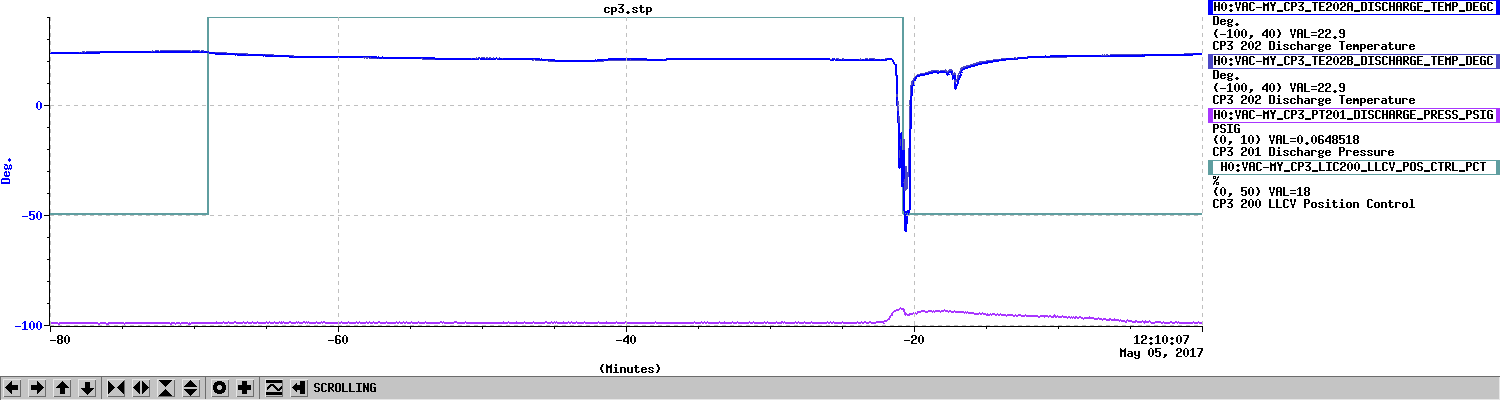
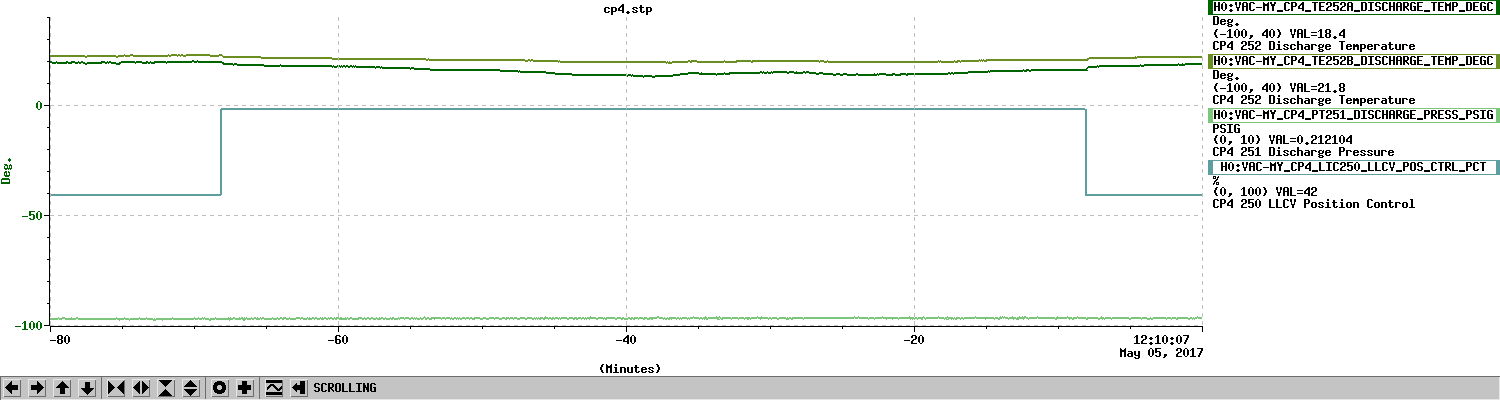
Back to Observing at 22:39UTC