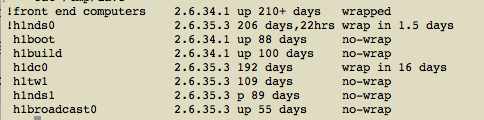
There is a write up of the bug which is possibly causing our front end issues here
I confirmed that our 2.6.34 kernel source on h1boot does have the arch/x86/include/asm/timer.h file with the bug.
To summarize, there is a low level counter in the kernel which has a wrap around bug with kernel versions 2.6.32 - 2.6.38. The bug causes it to wrap around after 208.499 days, and many other kernel subsystems assume this could never happen.
At 06:10 Thursday morning h1seiex partially locked-up. At 05:43 Friday morning h1susex partially locked-up. As of late Wednesday night, all H1 front ends have been running for 208.5 days. The error messages on h1seiex and h1susex consoles show timers which had been reset Wednesday night, within two hours of each other.
We are going on the assumption that the timer wrap-around has put the front end computers in a fragile state where lock-ups may happen. We don't know why only two computers at EX have seen the issue, or why around 6am, or why one day apart. Nothing happened around 6am this morning.
I am filing a work permit to reboot all H1 front end computers and DAQ computers which are running kernels with this bug.
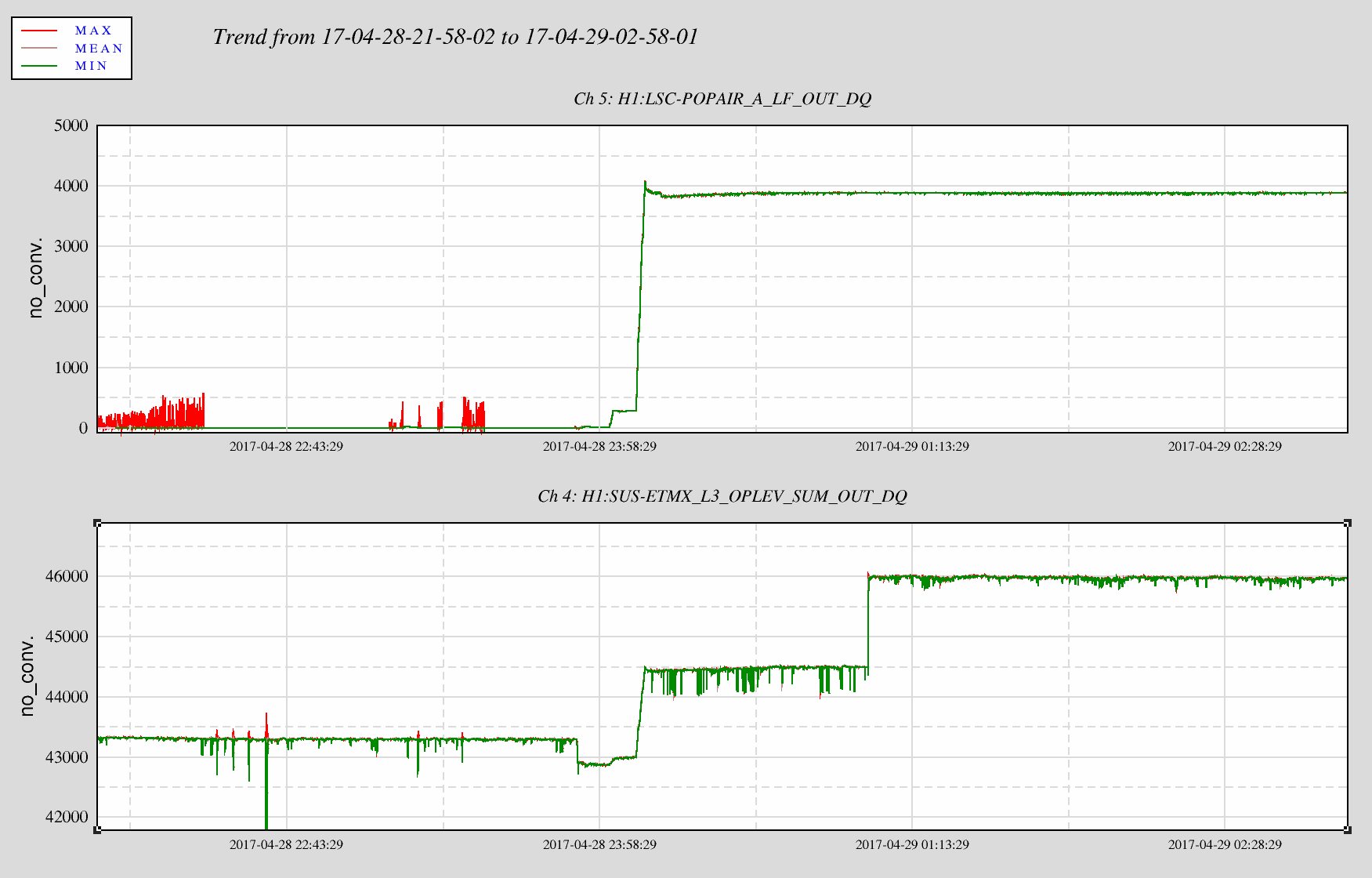
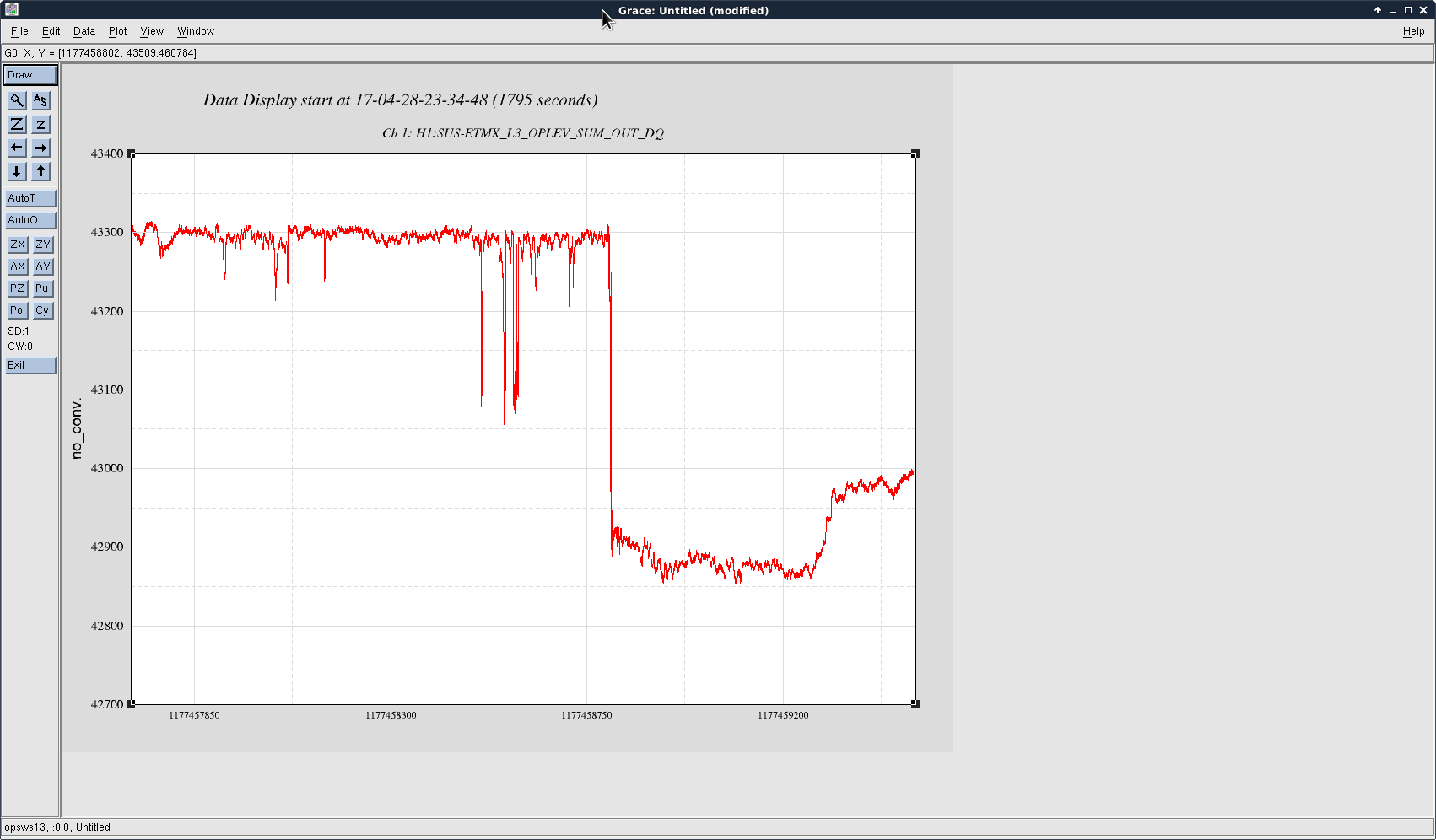
23:03 Intention Bit Undisturbed