J. Kissel, J. Warner, J. Driggers, J. Oberling, C. Gray
Executive Summary
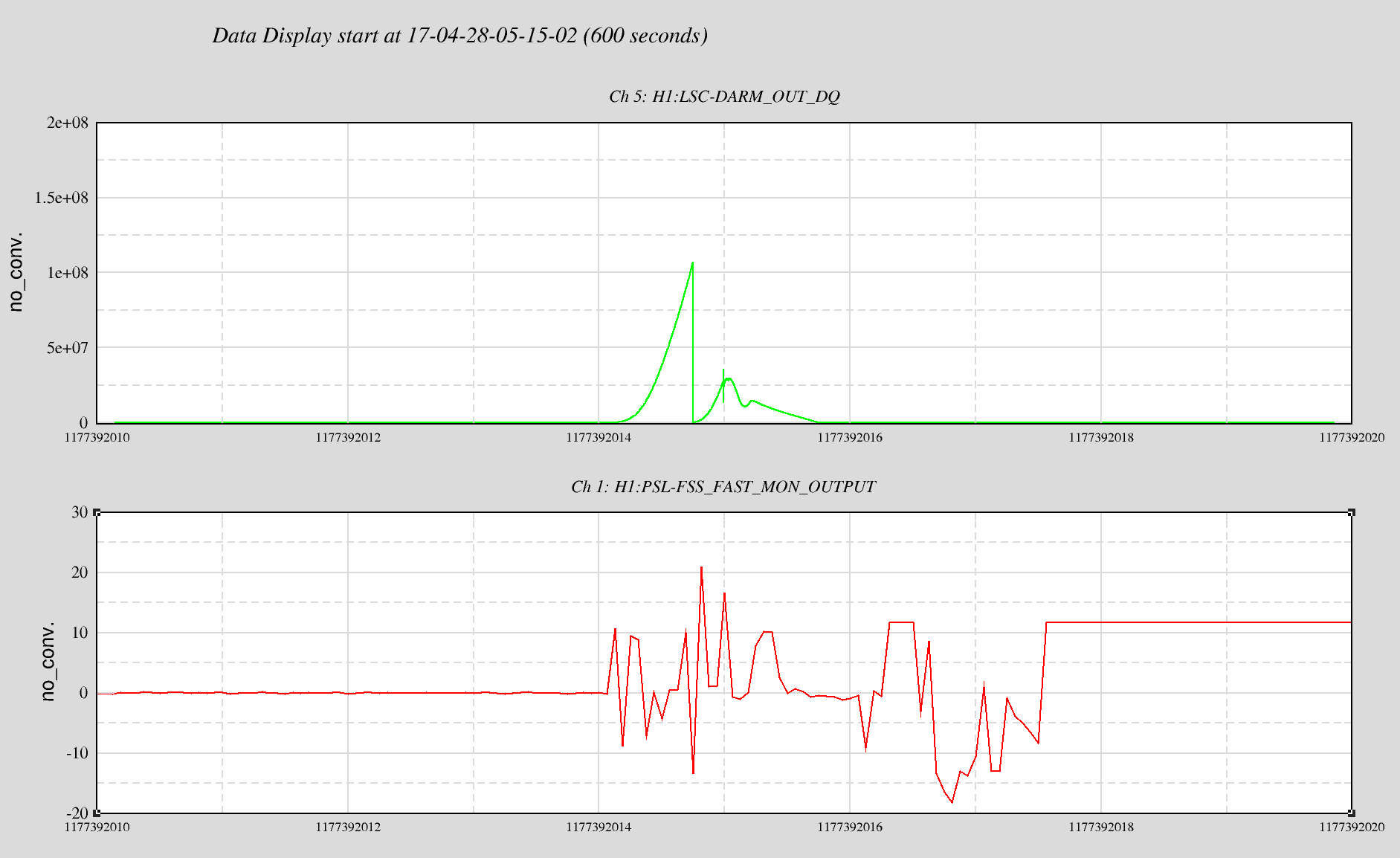
Running an old, infrequently used "ditherAlign" script to recover green spots after gross X arm misalignment (i.e. because of the SEI front-end failure early this morning; see LHO aLOG 35824, 35834) caused more than usual trouble regaining the X ARM ALS angular control. After slowly working / stumbling our way through identifying the problems by performing "the usual" troubleshooting (i.e. G1602280), we were able to return to full initial alignment and lock acquisition and achieved nominal low noise by 20:00 UTC.
Total down time -- 7 hours from 2017-04-27 13:00 to 20:00 UTC.
Lessons Learned
- There are four places any given operator goes for information to diagnose a problem when alone on evening / night shifts:
(1) Jenne's H1 Troubleshooting Presentation: G1602280
(2) The OPS Wiki Troubleshooting Page: Trouble Shooting the IFO
(3) The OPS Wiki Useful Scripts Page: Useful Scripts For Operators
(4) Nutsinee has her own Trouble Shooting Page: Nutsinee's Page
When an operator has just restarted shifting after a month off, and nothing's gone wrong for that operator in a while, you forget even the location of resources let alone which resource to use. It will be a giant effort to merge these documents, but we could at least work to link all of them to the other.
Jim recommends we banish (2), we update and maintain (3), and acknowledge that (4) is not cannon if used by others who are not Nutsinee. Jenne acknowledges that (1) has several pending updates, and will add a few things from today's experience.
- It's important to have such a "ditherAlign" script that rescues us from a gross arm misalignment in which we've lost spots. But we have those events so infrequently that the script suffers from bit rot between uses (e.g. it uses the TDS library, and we just upgraded the control room to Debian8, which doesn't support the TDS library). As such, we should upgrade, debug and fix this script and update the associated documentation. However, after looking at it, it's a beast of a spaghetti monster. Also a giant effort.
- When we get such a gross misalignment, we should not expect *any* operator to be able to fix the problem (let alone diagnose it) quickly or by themselves. It took all of the authors patiently sitting through the problem, picking up clues, trying this and that, looking in 15 different places (only possible with 3-4 pairs of eyes) for us to solved the problem, and later identify it. We should just expect this after we lose a seismic front-end.
- Since we've moved toward the O2 model of "do not call commissioners if you have a problem," operators have, in general, become reticent to call if there's a problem, especially on owl shifts -- and that call list is Keita. Further, in the era of 71 hour locks and 80-90% duty cycle, commissioners and detector engineers are far less regularly in the control room. Yet further, shift changes are also a really tough point in the chain of communication and on the day operator. Not only do they have the stress of a mid-night failure from which they don't have all the information, but the gets compounded with the phones ringing, everyone coming in asking what's wrong and/or is it fixed, and not knowing who can actually stay to help. I make this last statement with no proposed solution, but merely to expose what happens these days during an un-identified mid-night failure mode and to encourage patience and cooperation by all.
Detailed Timeline
- Seismic front-end crashed
- After seismic computer and platform recovery (see LHO aLOG 35824, 35834), we did not see any spot on the ALS X Green camera.
- After some manual tries (unclear if any restoration to slider / oplev / OSEM values was done), an infrequently used script to recover green spots after gross arm misalignment,
/opt/rtcds/userapps/release/asc/h1/scripts/ditherAlign.py
was run on both TMSX (twice) and ITMX. These scripts failed, and left a whole bunch of stuff in a bad alignment state, namely
- all X arm optics (ITMX, ETMX, TMSX) were aligned to a bad location,
- the ITM *misalignment* offsets were changed, and
- The green camera (CAM) Reference OFFSETS were changed.
Some, but not all recovery was made, because the users weren't aware of everything this script touched.
(And before you cry "but the SDF system!" remember that there are lots of DIFFs that appear in down snaps that are usually overlooked because things work out in the end.)
(Corey departs, Jim Arrives)
- After a restoration of the TMSX alignment sliders to the previous observation stretch's OSEM location, we regained spots on the camera. Jim then heroically pushed the ETMX and ITMX alignment around until he recorved *decent* arm cavity transmission.
- As is standard practice, he then went for through an initial alignment of the X ARM (INITIAL ALIGNMENT state on ALS_XARM) which turns on automatic alignment, including green WFS and green Camera (CAM) ITMX spot restoration. However, because the end station alignment was still far enough off that the WFS error signals were too large, and the green CAM references had been errantly changed by the ditherAlign script the WFS and CAM servos blew up after every attempt to automatically close them as normal.
(Jeff Arrives)
- After further efforts to manually increase the transmission to reduce the WFS and CAM error signals without success, we remembered one has to clear WFS / SUS offsets if/when/after they drive optics into the weeds.
(Jenne Arrives)
- Having cleared the weeds, we were able to close the green YAW WFS 1 & 2 loops that control TMSX and ETMX. To do so, we needed to set the ALS_XARM guaridan to ENABLE_WFS, and force the triggering of the alignment servos to be ALWAYS ON, i.e. set
- H1:ALS-X_WFS_TRIG_THRESH_ON and H1:ALS-X_WFS_DOF_FM_TRIG_THRESH_ON to -0.1 (i.e. anything below zero),
- Flip to the master gain switch (H1:ALS-X_WFS_SWITCH) to ON.
However, with the triggering forced ON, that meant that if the arm lost lock, we'd need to quickly turn off the inputs to the WFS loops we had under control so more weeds would not grow. Recall from G1602280, successful closure of these loops was only possible if the error signals were less than ~1000 and preferably better than 500 [ct]. We were using Jenne's premade StripTool template for the WFS error signals,
/ligo/home/jenne.driggers/Templates/Strip/Green_Y_AlignErrorSigs.stp
(Jason Arrives)
- With TMS and ETMX under control in YAW, we tried slowly moving ITMX in yaw (with the green WFS) to reduce the CAM YAW error signal (at this point both were in the 0.7 range, and we want better than 0.1). As we (very slowly) moved the ITM (so that the end-station optics' WFS could follow), we realized that reducing the CAM error signal made MICH fringes on the AS AIR camera look worse, implying that we were doing the wrong thing. So, we reverted the ITM location, and went to close the Pitch loops.
- Closing WFS A / DOF1 / ETMX pitch loop was relatively easy, but even though the error signals were sufficiently small, closing the WFS B / DOF 2 / TMSX loop would start growing weeds and break. After several tries, we realized we may be on the wrong side of the WFS A / DOF1 / ETMX PDH error signal hump, so we pushed the ETM back in the oppposite direction, indeed went over the hump, and began to reduce the error signal again. After that discovery, both PIT DOFs clsoed nicely.
- Now having ALL WFS end X optics controlled DOFS closed, and the green arm transmission up in the high 0.9s to 1, we again went back to ITMX to reduce the CAM error signal. This again made the AS AIR spot / MICH fringes look like crap, and reduced the green arm transmission. We [incorrectly] concluded that the cameras must have moved, and remeasured and set the CAM offsets.
- At this point we were able to resume regular initial alignment. All went well, until SRC_ALIGN, where we saw excess fringing on the AS port camera. Jenne knew this was because some optic was not entirely *misaligned* so we trended the *misalignment offsets* in the M0_TEST bank of ITMX, and found they were wrong by half. Restoring these allowed us to complete initial alignment as normal.
- All the rest of normal lock acquisition worked swimmingly.
- Upon arrival at nominal low noise, we began checking for SDF differences -- and it was only then that we started to put the pieces together that the driveAlign script had messed with everything listed above.





{kind=link}
{kind=link}
{kind=link}