kyle.ryan@LIGO.ORG - posted 14:22, Thursday 20 April 2017 - last comment - 14:33, Thursday 20 April 2017(35690)
~1340 - 1350 hrs. local -> Operated crane at X-mid
Kyle, Chandra Chandra had freed a bird that had got itself stuck in the "sticky mat" used to trap insects at the X-mid earlier today. Unfortunately, it flew into the VEA. Following Keita's Thursday 1 O-clock'ish meeting, we followed up by opening all of the roll-up doors and, with the lights off, persuaded it to exit. We had to "bump" the crane bridge a few times to encourage the bird to leave - which it eventually did. (Don't get me wrong. I'm all for recycling and liberating caught birds etc. but if she next finds a struggling beached whale along the X-arm access road - she's on her own!)
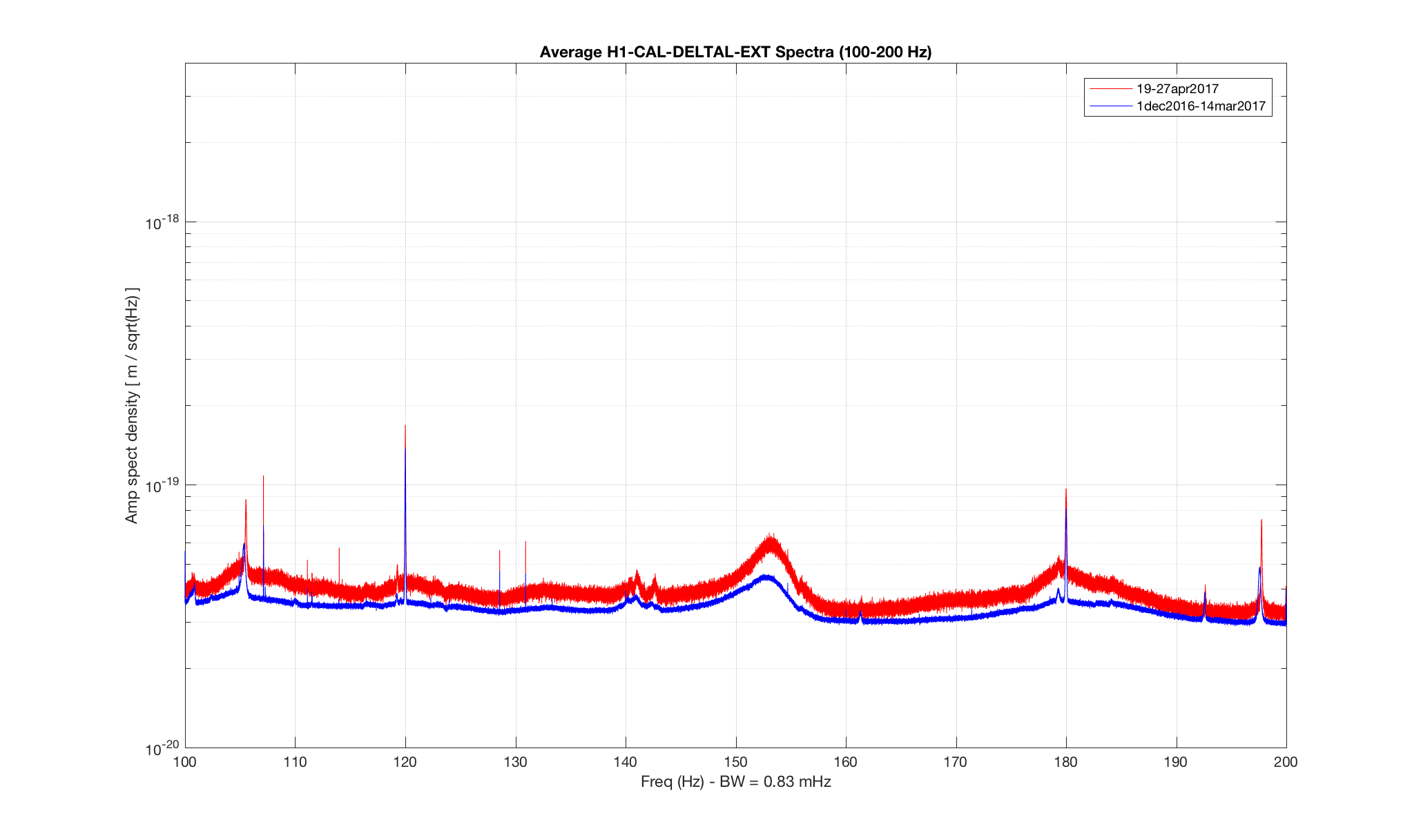
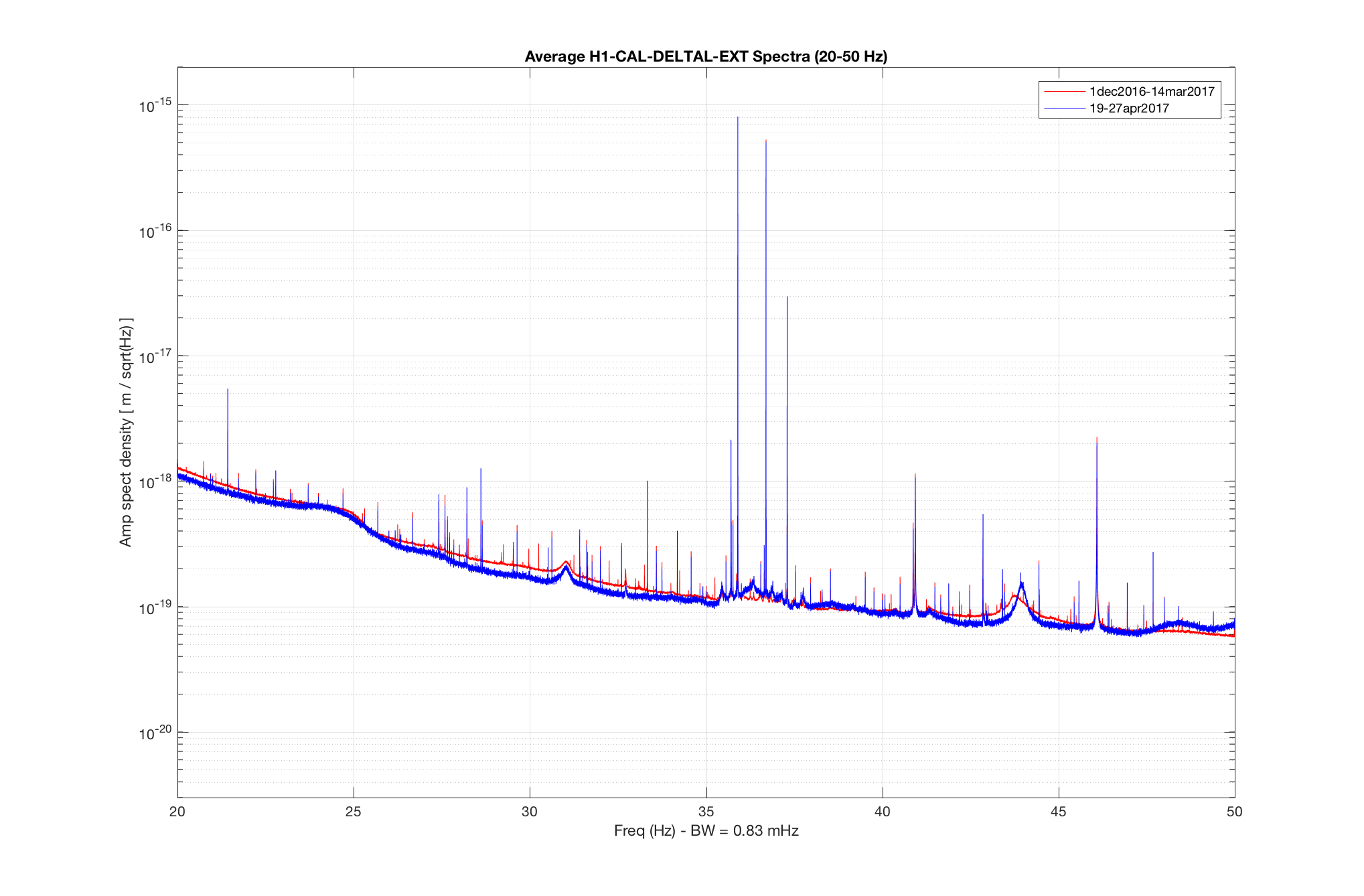
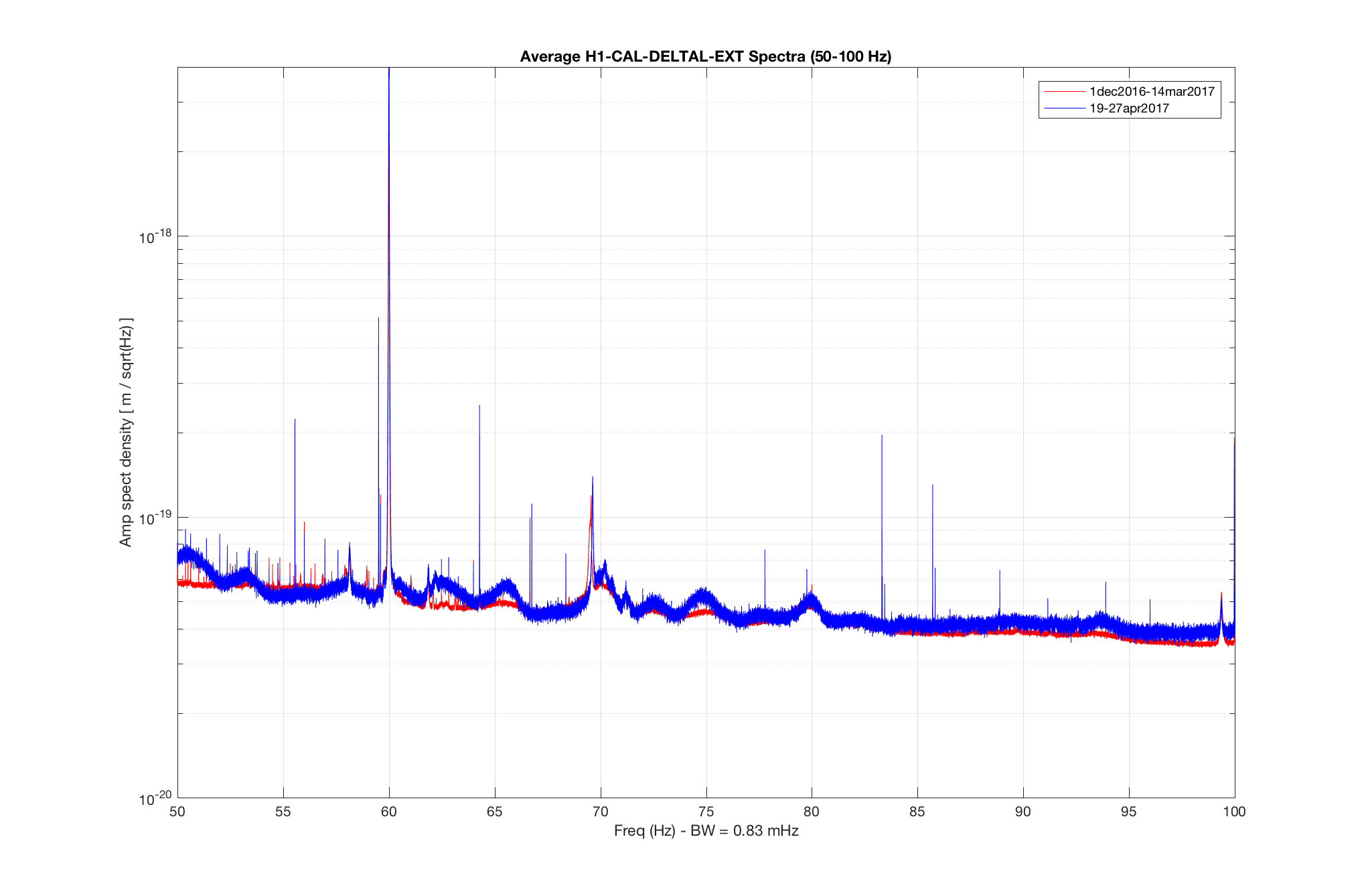
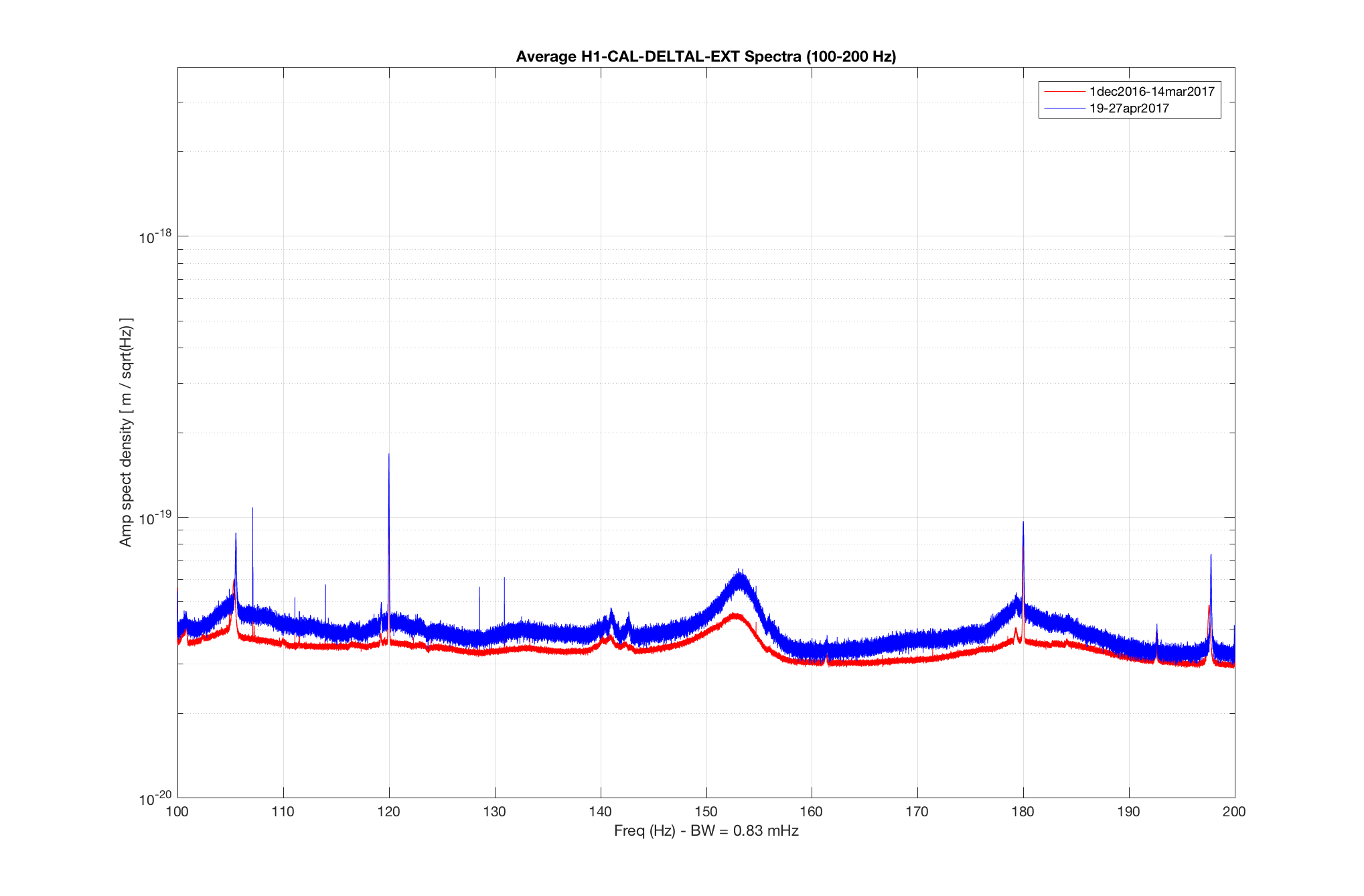


The bird was stuck on the black goo mat on the floor next to roller door, not the white sticky mats that we also use to trap rodents/insects. I was happy to see it fly so well after I peeled its wing and foot off.